�ڶԿ�ѵ���йؼ�������Ҫ�ҵ��Կ�������ͨ���Ƕ�ԭʼ����������һ�����Ŷ������죬Ȼ��Ÿ�ģ��ѵ��������ģ�;�����ʶ��Կ����������������еĹؼ�����������������Ŷ���ʹ��ģ���ڲ�ͬ�Ĺ��������о��ܹ��߱���ǿ��ʶ����
�Կ�ѵ��������˵��������ԭʼ�������� xxx �ϼ���һ���Ŷ� radvr_{adv}radv??������������ʱ��Ϊ ��\delta�������õ��Կ��������������ѵ����2018 �� Madry ��ԶԿ�ѧϰ������һ�� Min-Max �Ĺ�ʽ1����
min��E(x,y)?D[maxradv��SL(��,x+radv,y)]\underset{\theta}{min}\mathbb E_{(x,y)\sim \mathcal D}[\underset{r_{adv\in S}}{max}\ L(\theta,x+r_{adv},y)] ��min?E(x,y)?D?[radv��S?max? L(��,x+radv?,y)]
�ù�ʽ�������֣�
- �ڲ���ʧ����������Կ���˼�뼴����������ʧ�ķ��������Ŷ���SSS ����Ϊ�Ŷ��ռ䣬��ʱ���ǵ�Ŀ�ľ���������ж�ʧ�������Ŷ���������ѵĹ�������
- �ⲿ���յ���С��������ϣ�����Ǹ���������Ŷ�������ֲ����ܹ���ԭ�ֲ���ͬ����ʱ���ǵ�Ŀ�ľ������������������������ҵ���³���ģ�Ͳ���
���潫�ֱ���� NLP ���õ���һЩ���öԿ�ѵ���㷨�����������㷨 FGM��һ���Ŷ���ǿ�ಽ�㷨 PGD�� FreeAT��YOPO��FreeLB �� SMART
�����ע�⣬���ڲ�ͬ���㷨�����п��ܲ����˲�ͬ����ѧ���ţ���ע������
Fast Gradient Method��FGM��
Goodfellow �� 2015 ������� Fast Gradient Sign Method��FGSM)2���������������ݶ�Ϊ
g=��xL(��,x,y)g=\triangledown_xL(\theta, x, y) g=��x?L(��,x,y)
��ô�Ŷ��Ϳ���������ʧ�����ķ����ٽ�һ��
radv=??sgn(��xL(��,x,y))r_{adv}=\epsilon\cdot sgn(\triangledown_xL(\theta, x, y)) radv?=??sgn(��x?L(��,x,y))
Goodfellow ���֣��� ?=0.25\epsilon=0.25?=0.25 ������Ŷ��ܸ�һ�������������� 99.9% �Ĵ����ʡ������ 2017 �� Goodfellow �� FGSM �м����Ŷ��IJ�������һ�����3��ȡ���˷��ź��������ݶȵĵڶ���ʽ����һ�� scale
radv=??g/�O�Og�O�O2xadv=x+radvr_{adv}=\epsilon\cdot g\ /\ ||g||_2\\ x_{adv}=x+r_{adv} radv?=??g / �O�Og�O�O2?xadv?=x+radv?
""" ����ÿ��x:1.����x��ǰ��loss�������õ��ݶ�2.����embedding������ݶȼ����r�����ӵ���ǰembedding�ϣ��൱��x+r3.����x+r��ǰ��loss�������õ��Կ����ݶȣ��ۼӵ���һ�����ݶ���4.��embedding�ָ�Ϊ��һ��ʱ��ֵ5.���ݵ��������ݶȶԲ������и��� """
import torch
class FGM():def __init__(self, model):self.model = modelself.backup = {
}def attack(self, epsilon=1., emb_name='emb.'):# emb_name�������Ҫ������ģ����embedding�IJ�����for name, param in self.model.named_parameters():if param.requires_grad and emb_name in name:self.backup[name] = param.data.clone()norm = torch.norm(param.grad)if norm != 0 and not torch.isnan(norm):r_at = epsilon * param.grad / normparam.data.add_(r_at)def restore(self, emb_name='emb.'):# emb_name�������Ҫ������ģ����embedding�IJ�����for name, param in self.model.named_parameters():if param.requires_grad and emb_name in name: assert name in self.backupparam.data = self.backup[name]self.backup = {
}# ��Ҫʹ�öԿ�ѵ����ʱ��ֻ��Ҫ�������д���
# ��ʼ��
fgm = FGM(model)
for batch_input, batch_label in data:# ����ѵ��loss = model(batch_input, batch_label)loss.backward() # �������õ�������grad# �Կ�ѵ��fgm.attack() # ��embedding�����ӶԿ��Ŷ�loss_adv = model(batch_input, batch_label)loss_adv.backward() # ����������������grad�����ϣ��ۼӶԿ�ѵ�����ݶ�fgm.restore() # �ָ�embedding����# �ݶ��½������²���optimizer.step()model.zero_grad()
Project Gradient Descent��PDG��
PGD1 ��һ�ֵ����������������ͨ�� FGM ��һ����λ��PGD ѡ��С���ߣ���ε���ÿ����һС����ÿ�ε������Ὣ�Ŷ�Ͷ�䵽�涨��Χ�ڡ���������߳����Ŷ��뾶Ϊ epsilonepsilonepsilon �Ŀռ䣬��ӳ��������ϣ��Ա�֤�Ŷ���Ҫ����
radvt+1=���O�Oradv�O�OF��?(radvt+��?g(radvt)/�O�Og(radvt)�O�O2)g(radvt)=��radvL(f��(x+radvt),y)r^{t+1}_{adv}=\Pi_{||r_{adv}||_F\leq\epsilon}(r^t_{adv}+\alpha\cdot g(r^t_{adv})\ /\ ||g(r^t_{adv})||_2)\\ g(r^t_{adv})=\triangledown_{r_{adv}}L(f_{\theta}(x+r^t_{adv}), y) radvt+1?=���O�Oradv?�O�OF?��??(radvt?+��?g(radvt?) / �O�Og(radvt?)�O�O2?)g(radvt?)=��radv??L(f��?(x+radvt?),y)
�O�Oradv�O�OF��?||r_{adv}||_F\leq\epsilon�O�Oradv?�O�OF?��? ���Ŷ���Լ���ռ䣬���O�Oradv�O�OF��?\Pi_{||r_{adv}||_F\leq\epsilon}���O�Oradv?�O�OF?��?? ���� ?\epsilon?-ball �ϵ�ͶӰ�����Ŷ����ȹ���ʱ�����ǽ� origin �������ص��߽����ͶӰ������β������������ڵĶ�ε���

""" ����ÿ��x:1.����x��ǰ��loss�������õ��ݶȲ����ݶ���ÿ��t:2.����embedding������ݶȼ����r�����ӵ���ǰembedding�ϣ��൱��x+r(������Χ��ͶӰ��epsilon��)3.t�������һ��: ���ݶȹ�0������x+r����ǰ���õ��ݶ�4.t�����һ��: �ָ���һ�����ݶȣ���������x+r�����ݶ��ۼӵ���һ����5.��embedding�ָ�Ϊ��һ��ʱ��ֵ6.���ݵ��IJ����ݶȶԲ������и��� """
import torch
class PGD():def __init__(self, model):self.model = modelself.emb_backup = {
}self.grad_backup = {
}def attack(self, epsilon=1., alpha=0.3, emb_name='emb.', is_first_attack=False):# emb_name�������Ҫ������ģ����embedding�IJ�����for name, param in self.model.named_parameters():if param.requires_grad and emb_name in name:if is_first_attack:self.emb_backup[name] = param.data.clone()norm = torch.norm(param.grad)if norm != 0 and not torch.isnan(norm):r_at = alpha * param.grad / normparam.data.add_(r_at)param.data = self.project(name, param.data, epsilon)def restore(self, emb_name='emb.'):# emb_name�������Ҫ������ģ����embedding�IJ�����for name, param in self.model.named_parameters():if param.requires_grad and emb_name in name: assert name in self.emb_backupparam.data = self.emb_backup[name]self.emb_backup = {
}def project(self, param_name, param_data, epsilon):r = param_data - self.emb_backup[param_name]if torch.norm(r) > epsilon:r = epsilon * r / torch.norm(r)return self.emb_backup[param_name] + rdef backup_grad(self):for name, param in self.model.named_parameters():if param.requires_grad:self.grad_backup[name] = param.grad.clone()def restore_grad(self):for name, param in self.model.named_parameters():if param.requires_grad:param.grad = self.grad_backup[name]# ʹ�õ�ʱ��Ҫ�鷳һ��
pgd = PGD(model)
K = 3
for batch_input, batch_label in data:# ����ѵ��loss = model(batch_input, batch_label)loss.backward() # �������õ�������gradpgd.backup_grad()# �Կ�ѵ��for t in range(K):pgd.attack(is_first_attack=(t==0)) # ��embedding�����ӶԿ��Ŷ�, first attackʱ����param.dataif t != K-1:model.zero_grad()else:pgd.restore_grad()loss_adv = model(batch_input, batch_label)loss_adv.backward() # ����������������grad�����ϣ��ۼӶԿ�ѵ�����ݶ�pgd.restore() # �ָ�embedding����# �ݶ��½������²���optimizer.step()model.zero_grad()
�����У����߸���������ͼ��ʾ�ĶԱȣ����Է������е�һ�Կ����ܵõ�һ���dz����Ҽ��е���ʧֵ�ֲ�����ˣ��������У����߳� PGD Ϊһ����ǿ�Կ���Ҳ����˵��ֻҪ�ܸ㶨 PGD �Կ������һ�Կ��Ͳ��ڻ���

Free Adversarial Training��FreeAT��
�� FGSM �� PGD����Ҫ���Ż��Կ��Ŷ��ļ��㣬��Ȼȡ���˸��õ�Ч������������Ҳһ��������
��ͨ�� PGD �������ڼ���һ�� epoch ��һ�� batchʱ��
- �ڲ�ѭ������ K ��ǰ�����Ĵ������õ� K ������������ݶ�
- ���ѭ������ 1 ��ǰ����Ĵ����õ����ڲ������ݶȸ�������
�����ļ���ɱ���ʮ�ָ߰��ģ���ʵ��������������������е�һ�������ݶ�ʱ���ܹ������ɱ��ĵõ�����һ�����ݶȡ������ Free Adversarial Training ��˼�룬��һ�μ��������ø������Ϣ���ٶԿ���ѧϰ��ѵ��
FreeAT4 �ĺ�����ͬ�������Ŷ���ģ�Ͳ���������ͼ��ʾ
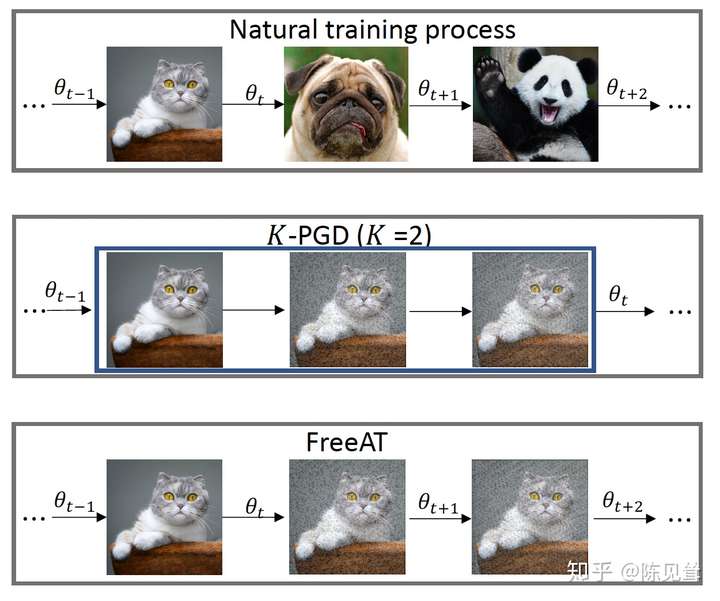
FreeAT ��ÿ���������������ظ��� mmm ��ѵ����Ϊ�˱�֤�ܵ��ݶȼ����������ͨѵ�����ݶȴ���һ������ԭ���� epoch ���� mmm���������㷨��������ͼ��ʾ

���⣬���Կ������ǣ���һ�� minibatch ����ʱ��ʹ����һ�� minibatch ���Ŷ���һ��Ԥ��
YOPO
YOPO5 �ij�����������������Ľṹ�������ݶȼ���ļ��������Ӽ���ֵԭ��PMP��Pontryagin��s maximum principle���������Կ��Ŷ�ֻ������ĵ� 0 ���йأ����� embedding ���������Ŷ����ټ�֮����֮���ǽ���ϵģ��ǾͲ���Ҫÿ�ζ�����������ǰ����
��������뷨�����߾��븴�ú��漸����ݶȣ����ٷDZ�Ҫ����������������ͼ��ʾ�����Խ� PGD �� rrr �ι������ m��nm\times nm��n ��
- ������ mmm ���У�ÿ��ֻ����һ��ǰ�����
- ÿ�ִ����У�����������ǰ�����ڽ������ķ����е��� 1 ���ֹͣ���� ppp ��¼�·����Ľ���������ٵ� 0 ���Ͻ��� nnn �ι��������� YOPO ֻ����� mmm �ε�������������ȴʵ���� m��nm\times nm��n ���Ŷ��ĸ���

������������һ�� gradient based YOPO �ľ�������

��ͼ���������㷨����

Free Large Batch Adversarial Training�� FreeLB��
YOPO ���ź����������Ǻþ��������ܿ� FreeLB6 ��ָ�� YOPO �ļ������ ReLU-based ������˵�Dz������ģ���Ϊ YOPO Ҫ����ʧ�����ο���
���⣬FreeLB ��Ϊ FreeAT �� PGD �ڻ�ȡ�����Ŷ�ʱ�ļ��㶼�������⡣���ǣ�FreeLB �� FreeAT �Ļ����Ͻ�ÿ�� inner-max �и���ģ�Ͳ�����һ�������������� KKK ��֮���ۻ��IJ����ݶȽ��и��£��������㷨�еĵ� 8��13 ����ʾ�����������������Ŀ�꺯���ͼ�Ϊ
min��E(Z,y)?D[1K��t=0K?1max��t��ItL(f��(X+��t),y)]It=BX+��0(��t)��BX(?)\underset{\theta}{min}\mathbb E_{(Z,y)\sim \mathcal D}\left[\frac{1}{K}\sum_{t=0}^{K-1}\underset{\delta_t\in\mathcal I_t}{max}\ L(f_\theta(X+\delta_t),y)\right]\\ \mathcal I_t=\mathcal B_{X+\delta_0}(\alpha t)\cap\mathcal B_X(\epsilon) ��min?E(Z,y)?D?[K1?t=0��K?1?��t?��It?max? L(f��?(X+��t?),y)]It?=BX+��0??(��t)��BX?(?)
X+��tX+\delta_tX+��t? ���Կ���������������Ľ��Ͼֲ����Ľ��ơ�ͬʱ��ͨ���ۻ������ݶȵIJ��������ǿ��Կ����������� [X+��0,?,X+��K?1][X+\delta_0,\cdots,X+\delta_{K-1}][X+��0?,?,X+��K?1?] ����һ������� KKK ����С�� batch
�������湫ʽ����һ�㣬input subwords �� one-hot representations ��Ϊ ZZZ��embedding matrix ��Ϊ VVV��subwords embedding ��Ϊ X=VZX=VZX=VZ��
���������㷨�е���ѧ���ţ�PGD ��Ҫ���� Nep?(K+1)N_{ep}\cdot(K+1)Nep??(K+1) ���ݶȼ��㣬FreeAT ��Ҫ���� NepN_{ep}Nep? �Σ�FreeLB ��Ҫ Nep?KN_{ep}\cdot KNep??K �Ρ���Ȼ��FreeLB ��Ч���ϲ�û���ر������ƣ�������Ч��ʮ�ֲ���

���⣬������ָ���Կ�ѵ���� dropout ����ͬʱʹ�ã����� dropout �൱�ڸı�������Ľ����Ӱ���Ŷ��ļ��㡣���һ��Ҫ���� dropout ��������Ҫ�� KKK ���ж�ʹ��ͬһ�� mask
SMoothness-inducing Adversarial Regularization��SMART��
֮ǰ���ǿ��������в����������ǻ��� Min-Max ��Ŀ�꺯�� �������� SMART7 ��ȴ������ Min-Max ��ʽ��ѡ��ͨ�������� Smoothness-inducing Adversarial Regularization ��ɶԿ�ѧϰ��Ϊ�˽������µ�Ŀ�꺯��������������Ż��㷨 Bregman Proximal Point Optimization������� SMART ��������Ҫ����
SMART ����Ҫ�뷨��ǿ��ģ���� neighboring data points ���������Ƶ�Ԥ�⣬������������Ŀ�꺯��������ʾ
min��F(��)=L(��)+��sRs(��))L(��)=1n��i=1n?(f(xi;��),yi)Rs(��)=1n��i=1nmax�O�Ox~i?xi�O�Op��??s[f(x~i;��),f(xi;��)]\underset{\theta}{min}\ \mathcal F(\theta)=\mathcal L(\theta)+\lambda_s\mathcal R_s(\theta))\\ \mathcal L(\theta)=\frac{1}{n}\sum_{i=1}^{n}\ell\left(f(x_i;\theta),y_i\right)\\ \mathcal R_s(\theta)=\frac{1}{n}\sum_{i=1}^{n}\underset{||\tilde x_i-x_i||_p\leq\epsilon}{max}\ \ell_s\left[f(\tilde x_i;\theta),f(x_i;\theta)\right] ��min? F(��)=L(��)+��s?Rs?(��))L(��)=n1?i=1��n??(f(xi?;��),yi?)Rs?(��)=n1?i=1��n?�O�Ox~i??xi?�O�Op?��?max? ?s?[f(x~i?;��),f(xi?;��)]
?\ell? �Ǿ����������ʧ������x~i\tilde x_ix~i? �� generated neighbors of training points ��?s\ell_s?s? �ڷ���������ʹ�öԳƵ� KL ɢ�ȣ��� ?s(P,Q)=DKL(P�O�OQ)+DKL(Q�O�OL)\ell_s(P,Q)=\mathcal D_{KL}(P||Q)+D_{KL}(Q||L)?s?(P,Q)=DKL?(P�O�OQ)+DKL?(Q�O�OL)���ڻع�������ʹ��ƽ����ʧ��?s(p,q)=(p?q)2\ell_s(p,q)=(p-q)^2?s?(p,q)=(p?q)2
��ʱ���Կ����Կ��������������ϣ��Կ���Ŀ��������Ŷ�ǰ������
Bregman Proximal Point Optimization Ҳ���Կ�����һ���������Ŀ������ģ���µ�����һ�㣬���仰˵���Ƿ�ֹ���µ�ʱ�� ��t+1\theta_{t+1}��t+1? ��ǰ��� ��t\theta_t��t? �仯�����ڵ� t+1t+1t+1 �ε���ʱ������ vanilla Bregman proximal point (VBPP) method
��t+1=argmin��F(��)+��DBreg(��,��t)(2)\theta_{t+1}=argmin_{\theta}\mathcal F(\theta)+\mu\mathcal D_{Breg}(\theta,\theta_t)\tag{2} ��t+1?=argmin��?F(��)+��DBreg?(��,��t?)(2)
���� DBreg\mathcal D_{Breg}DBreg? ��ʾ Bregman divergence ����Ϊ
DBreg(��,��t)=1n��i=1n?s(f(xi;��),f(xi;��t))\mathcal D_{Breg}(\theta,\theta_t)=\frac{1}{n}\sum_{i=1}^n\ell_s\left(f(x_i;\theta),f(x_i;\theta_t)\right) DBreg?(��,��t?)=n1?i=1��n??s?(f(xi?;��),f(xi?;��t?))
?s\ell_s?s? ����������ĶԳ� KL ɢ��
���ǿ���ʹ�ö��������� VBPP����ʱ���� ��\beta�� Ϊ�������� ��~=(1?��)��t+�¦�~t?1\tilde\theta=(1-\beta)\theta_t+\beta\tilde\theta_{t-1}��~=(1?��)��t?+����~t?1? ��ʾָ���ƶ�ƽ������ô momentum Bregman proximal point (MBPP) method �Ϳ��Ա�ʾΪ
��t+1=argmin��F(��)+��DBreg(��,��~t)(3)\theta_{t+1}=argmin_{\theta}\mathcal F(\theta)+\mu\mathcal D_{Breg}(\theta,\tilde\theta_t)\tag{3} ��t+1?=argmin��?F(��)+��DBreg?(��,��~t?)(3)
������ SMART �������㷨����
""" ע��һ�� Algorithm 1���� t �ֵ��������� theta����Ϊ Bregman divergence ����� theta_t����ÿһ�� batch��ʹ����̬�ֲ������ʼ���Ŷ������ x �õ� x_tildeѭ�� m С���������Ŷ��µ��ݶ� g_tilde���� g_tilde ��ѧϰ�ʸ��� x_tilde���� x_tilde ���¼����ݶȣ����²��� theta���� theta_t """

Reference
��������
- һ�ĸ㶮NLP�еĶԿ�ѵ��FGSM/FGM/PGD/FreeAT/YOPO/FreeLB/SMART
- NLP �� >�Կ�ѧϰ����FGM, PGD��FreeLB
- �����Ķ����Կ�ѵ����adversarial training��
- ��μ��ٶԿ�����������
- SMART: Robust and Efficient Fine-Tuning for Pre-trained Natural Language��
- SMART: ͨ�öԿ�ʽѵ��
��������
Madry A, Makelov A, Schmidt L, et al. Towards deep learning models resistant to adversarial attacks[J]. arXiv preprint arXiv:1706.06083, 2017. ?? ??
Goodfellow I J, Shlens J, Szegedy C. Explaining and harnessing adversarial examples[J]. arXiv preprint arXiv:1412.6572, 2014. ??
Miyato T, Dai A M, Goodfellow I. Adversarial training methods for semi-supervised text classification[J]. arXiv preprint arXiv:1605.07725, 2016. ??
Shafahi A, Najibi M, Ghiasi A, et al. Adversarial training for free![J]. arXiv preprint arXiv:1904.12843, 2019. ??
Zhang D, Zhang T, Lu Y, et al. You only propagate once: Accelerating adversarial training via maximal principle[J]. arXiv preprint arXiv:1905.00877, 2019. ??
Zhu C, Cheng Y, Gan Z, et al. Freelb: Enhanced adversarial training for natural language understanding[J]. arXiv preprint arXiv:1909.11764, 2019. ??
Jiang H, He P, Chen W, et al. Smart: Robust and efficient fine-tuning for pre-trained natural language models through principled regularized optimization[J]. arXiv preprint arXiv:1911.03437, 2019. ??