
�������ߣ�Tyan
���ͣ�noahsnail.com | CSDN | ����
�������Ļ��ܣ�https://github.com/SnailTyan/deep-learning-papers-translation
Going Deeper with Convolutions
ժҪ
������ImageNet���ģ�Ӿ�ʶ����ս��2014��ILSVRC14���������һ�ִ���ΪInception����Ⱦ���������ṹ�����ڷ���ͼ����ȡ�����µ���ý��������ܹ�����Ҫ�ص�������������ڲ�������Դ�������ʡ�ͨ�����ĵ��ֹ���ƣ�������������������Ⱥ�ȵ�ͬʱ�����˼���Ԥ�㲻�䡣Ϊ���Ż��������ܹ�������Ժղ����ۺͶ�߶ȴ���ֱ��Ϊ������������ILSVRC14�ύ��Ӧ�õ�һ����������ΪGoogLeNet��һ��22���������磬�������ڷ���ͼ��ı����½�����������
1. ����
��ȥ�����У��������ѧϰ�;�������ķ�չ[10]�����ǵ�Ŀ�����ͼ�������õ���������ߡ�һ�����˹������Ϣ�ǣ��ֵĽ����������Ǹ�ǿ��Ӳ�����������ݼ�������ģ�͵Ľ��������Ҫ���µ��뷨���㷨������ṹ�Ľ��Ľ�������磬ILSVRC 2014�������ǰ������������ڼ��Ŀ�ĵķ������ݼ�֮�⣬û��ʹ���µ�������Դ��������ILSVRC 2014�е�GoogLeNet�ύʵ��ʹ�õIJ���ֻ������ǰKrizhevsky����[9]��ʤ�ṹ������1/12����������Ը�ȷ����Ŀ����ǰ�أ������ջ���������Խ��Խ����������ļ�Ӧ�ã�������������ȼܹ��;��������Ӿ���Эͬ����Girshick����[6]��R-CNN�㷨������
��һ�����������������ƶ���Ƕ��ʽ�豸���ƶ������ǵ��㷨��Ч�ʺ���Ҫ�������������ǵĵ������ڴ�ʹ�á�ֵ��ע����ǣ����ǰ�����������صĿ��Dzŵó��˱����г��ֵ���ȼܹ���ƣ������ǵ�����Ϊ�����ȷ�ʡ����ڴ����ʵ����˵��ģ�ͱ����Ϊ��һ���ƶ��б���15�ڳ˼ӵļ���Ԥ�㣬�����������Dz��ǵ�����ѧ�������ģ�����������ʵ������Ӧ�ã��������Ժ����Ĵ����ڴ������ݼ���ʹ�á�
�ڱ����У����ǽ���עһ����Ч�ļ�����Ӿ����������ܹ�������ΪInception����������������Lin����[12]���������е�Network�������ġ�we need to go deeper����������[1]�Ľ�ϡ������ǵİ����У����ʡ�deep������������ͬ�ĺ����У����ȣ���ij�������ϣ������ԡ�Inception module������ʽ������һ���²�ε���֯��ʽ���ڸ�ֱ�ӵ��������������������ȡ�һ����˵������Inceptionģ�Ϳ�������[12]��������ͬʱ��Arora����[2]�����۹������ܵ��˹�������������ּܹ��ĺô���ILSVRC 2014����ͼ����ս����ͨ��ʵ��õ�����֤������������Ŀǰ�����ˮƽ��
2. ���ڹ���
��LeNet-5 [10]��ʼ�����������磨CNN��ͨ����һ�����ṹ�����ѵ��ľ����㣨�������ѡ���жԱȹ�һ�������ػ���������һ��������ȫ���Ӳ㡣���������Ƶı�����ͼ������������У�����ĿǰΪֹ��MNIST��CIFAR��������ImageNet������ս����[9, 21]���Ѿ�ȡ������ѽ�������ڸ�������ݼ�����ImageNet��˵����������������Ӳ����Ŀ[12]�Ͳ�Ĵ�С[21, 14]��ͬʱʹ�ö���[7]�������������⡣
���ܵ������ػ��������ȷ�ռ���Ϣ����ʧ������[9]��ͬ�ľ�������ṹҲ�Ѿ��ɹ���Ӧ���ڶ�λ[9, 14]��Ŀ����[6, 14, 18, 5]��������̬����[19]��
���鳤���Ӿ�Ƥ����ѧģ�͵�������Serre����[15]ʹ����һϵ�й̶��IJ�ͬ��С��Gabor�˲�����������߶ȡ�����ʹ��һ�������ƵIJ��ԡ�Ȼ������[15]�Ĺ̶���2�����ģ���෴��Inception�ṹ�����е��˲�����ѧϰ���ġ����⣬Inception���ظ��˺ܶ�Σ���GoogleNetģ���еõ���һ��22������ģ�͡�
Network-in-Network��Lin����[12]Ϊ��������������������������һ�ַ����������ǵ�ģ���У������������˶����1 �� 1�����㣬�������������ȡ����ǵļܹ��д�����ʹ����������������ǣ������ǵ������У�1 �� 1����������Ŀ�ģ���ؼ����ǣ�������Ҫ��������Ϊ��άģ�����Ƴ�����ƿ��������������������Ĵ�С���ⲻ����������ȵ����ӣ�����������������Ŀ������ӵ�û�����Ե�������ʧ��
���Ŀǰ��õ�Ŀ������Girshick����[6]�Ļ�������ľ��������磨R-CNN��������R-CNN�������������ֽ�Ϊ���������⣺���õͲ�ε��ź�������ɫ�������Կ����ķ�ʽ������Ŀ��λ�ú�ѡ����Ȼ����CNN��������ʶ����Щλ���ϵĶ����������һ�������εķ��������˵Ͳ������ָ�߽���ȷ�ԣ�Ҳ������Ŀǰ��CNN�dz�ǿ��ķ������������������ǵļ���ύ�в��������Ƶķ�ʽ����̽����ǿ�������Σ�������ڸ��ߵ�Ŀ��߽���ٻ�ʹ�ö��[5]Ԥ�⣬���ں��˸��õı߽���ѡ����������
3. �����߲�˼��
������������������ֱ�ӵķ�ʽ���������ǵijߴ硣�ⲻ������������ȡ��������ε���Ŀ����Ҳ�������Ŀ��ȣ�ÿһ��ĵ�Ԫ��Ŀ������һ��ѵ����������ģ�������Ұ�ȫ�ķ������������ڿɻ�ô�����ע��ѵ�����ݵ�����¡��������������������Ҫ��ȱ�㡣����ijߴ�ͨ����ζ�Ÿ���IJ��������ʹ����������������ϣ���������ѵ�����ı�ע������������¡�����һ����Ҫ��ƿ������ΪҪ���ǿ��ע���ݼ���ʱ�����Ҵ��۰�������Ҫר����ί�ڸ���ϸ���ȵ��Ӿ����������֣�����ͼ1����ʾ��ImageNet�е����������1000��ILSVRC���Ӽ�����

ͼ1: ILSVRC 2014������ս����1000����������ͬ�����������Щ�����Ҫ����֪ʶ��
ͳһ��������ߴ����һ��ȱ���Ǽ�����Դʹ�õ��������ӡ����磬��һ������Ӿ������У�����������������������ǵ��˲�����Ŀ���κ�ͳһ���Ӷ������������ƽ��ʽ�����ӡ�������ӵ�����ʹ��ʱЧ�ʵ��£����磬��������Ȩ�ؽ���ʱ�ӽ���0������ô���˷Ѵ����ļ������������ڼ���Ԥ���������ģ�������Դ����Ч�ֲ���ƫ���ڳߴ��������ӣ���ʹ��ҪĿ�����������ܵ�������
��������������һ�������ķ�ʽ��������ϡ���Բ���ȫ���Ӳ��滻Ϊϡ���ȫ���Ӳ㣬�����Ǿ����㡣����ģ������ϵͳ֮�⣬����Arora����[2]�Ŀ����Թ�������Ҳ���и���̵����ۻ������ơ����ǵ���Ҫ�ɹ�˵��������ݼ��ĸ��ʷֲ�����ͨ��һ������ϡ�������������ʾ�������ŵ��������˽ṹ����ͨ������ǰһ�㼤��������ͳ�ƺ;���߶���ص���Ԫ��һ���Ĺ�������Ȼ�ϸ����ѧ֤����Ҫ�ں�ǿ�������£�����ʵ����������������ĺղ����۲�������������Ԫһ����һ�����ӡ���ʵ�������������������������ڲ��ϸ�������¡�
�ź����ǣ��������ڷǾ��ȵ�ϡ�����ݽṹ�Ͻ�����ֵ����ʱ�����ڵļ���ܹ�Ч�ʷdz����¡���ʹ�㷨�������������100������ѯ�ͻ��涪ʧ�ϵĿ�����ռ������λ���л���ϡ���������Dz����еġ������ȶ������߶ȵ�������ֵ���Ӧ�ã�������ڽ�һ��������ֵ��Ҫ�ȿ����ܼ��ľ���˷������õײ��CPU��GPUӲ��[16, 9]��Сϸ�ڡ��Ǿ��ȵ�ϡ��ģ��ҲҪ�����ĸ��ӹ��̺ͼ�������ṹ��Ŀǰ����������Ӿ��Ļ���ѧϰϵͳͨ�����þ������ŵ������ÿ����ϡ���ԡ�Ȼ����������ʵ��Ϊ����һ�����ܼ����ӵļ��ϡ�Ϊ�˴��ƶԳ��ԣ����ѧϰˮƽ��������[11]��ʼ��ConvNetsϰ����������ά��ʹ�������ϡ�����ӱ���Ȼ��Ϊ�˽�һ���Ż����м��㣬����[9]�������ڱ��ȫ���ӡ�Ŀǰ���µļ�����Ӿ��ܹ���ͳһ�Ľṹ��������˲������������СҪ���ܼ��������Чʹ�á�
���������һ���м䲽���Ƿ���ϣ�������⣺һ���ܹ��������˲���ˮƽ��ϡ���ԣ��������������������������ͨ�������ܼ������������������Ŀǰ��Ӳ����ϡ�����˷��Ĵ������ף�����[3]����Ϊ����ϡ�����˷�����ϡ��������Ϊ����ܼ����Ӿ�����и��ѵ����ܡ��ڲ��õĽ������������Ƶķ��������зǾ������ѧϰ�ܹ����Զ��������������뷨�ƺ�����ǣǿ��
Inception�ܹ���ʼ����Ϊ�����о�����������һ�������������˹����㷨�ļ�����������㷨��ͼ����[2]����ʾ���Ӿ������ϡ��ṹ����ͨ���ܼ��ġ�����õ���������Ǽ�������������һ���dz�Ͷ�������飬�������[12]�IJο�������ȣ����ڿ��Թ۲�ʶȵ����档����һ�������ӿ���࣬��Ϊ[6]��[5]�Ļ������磬Inception��֤���ڶ�λ�����ĺ�Ŀ�������������á���Ȥ���ǣ���Ȼ���������ļܹ�ѡ���ѱ����ɲ����뿪����ȫ����ԣ������֤�������Ǿֲ����ŵġ�Ȼ���������������Inception�ܹ��ڼ����������ȡ�óɹ��������Ƿ���Թ����ڹ�����ܹ���ָ��ԭ�����������ʵġ�ȷ����һ�㽫��Ҫ�����ķ�������֤��
4. �ܹ�ϸ��
Inception�ܹ�����Ҫ�뷨�ǿ����������ƾ����Ӿ����������ϡ��ṹ��������õ��ܼ�������и��ǡ�ע�����ת�������ԣ�����ζ�����ǵ����罫�Ծ���������Ϊ��������������Ҫ�������ҵ����ŵľֲ����첢�ڿռ����ظ�����Arora����[2]�����һ����νṹ������Ӧ�÷������һ������ͳ�Ʋ������Ǿۼ��ɾ��и�����Եĵ�Ԫ�顣��Щ�����γ�����һ��ĵ�Ԫ����ǰһ��ĵ�Ԫ���ӡ����Ǽ��������ÿ����Ԫ����Ӧ������ijЩ��������Щ��Ԫ���ֳ��˲����顣�ڽϵ͵IJ㣨�ӽ�����IJ㣩��ص�Ԫ�����ھֲ�������ˣ���[12]��ʾ���������ջ���������༯���ڵ����������ǿ���ͨ����һ���1��1�����㸲�ǡ�Ȼ��Ҳ����Ԥ�ڣ������ڸ�С��Ŀ���ڸ���ռ�����չ�ľ��࣬����Ա�������ϵľ������ǣ���Խ��Խ��������Ͽ�����������½���Ϊ�˱����У�������⣬ĿǰInception�ܹ���ʽ���˲����ijߴ������1��1��3��3��5��5���������������ǻ��ڱ����Զ����DZ�Ҫ�ԡ���Ҳ��ζ������ļܹ���������Щ�����ϣ�������˲��������ӳɵ�����������γ�����һ�ε����롣���⣬���ڳػ���������Ŀǰ��������ijɹ�������Ҫ����˽�����ÿ�������Ľ�����һ������IJ��гػ�·��Ӧ��ҲӦ�þ��ж��������Ч������ͼ2(a)����
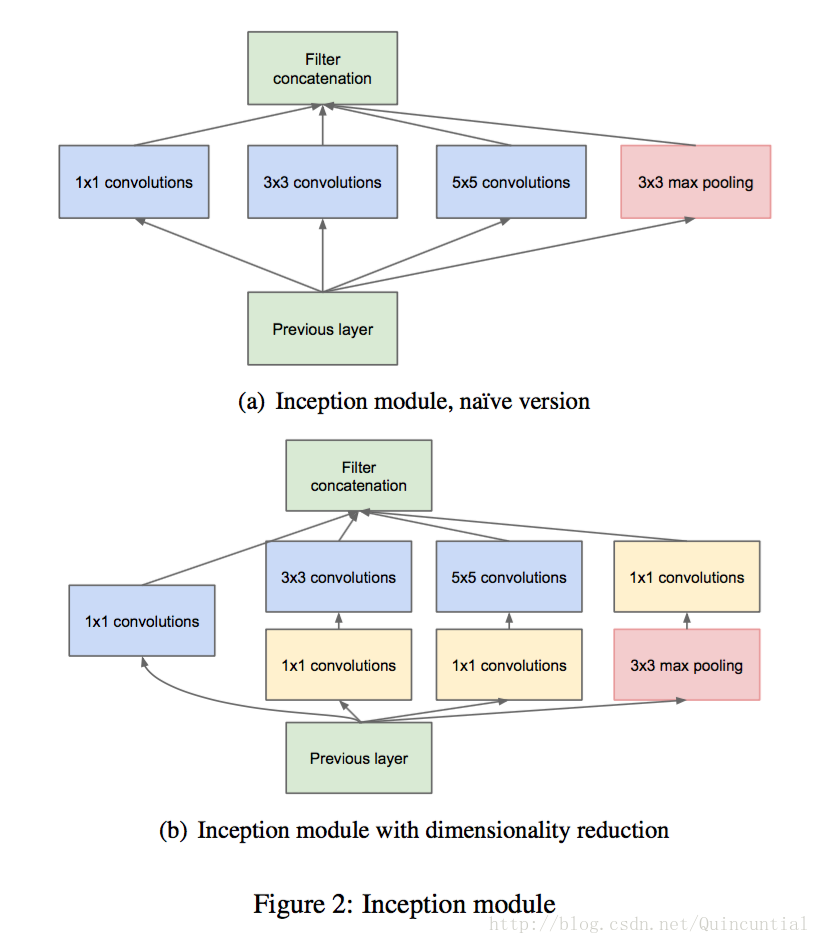
������Щ��Inceptionģ�顱�ڱ˴˵Ķ����ѵ�����������ͳ�Ʊ�Ȼ�б仯�����ڽϸ߲�Ჶ��ϸߵij�����������ռ伯�ж�Ԥ�ƻ���١����������ת�Ƶ����߲㣬3��3��5��5�����ı���Ӧ�û����ӡ�
����ģ���һ�����������ھ��д����˲����ľ�����֮�ϣ���ʹ������5��5����Ҳ�����Ƿdz�����ģ�����������������ʽ����������⡣һ���ػ���Ԫ���ӵ�����У���������������ø����ԣ�����˲�������������ǰһ���˲������������ػ�������;���������ĺϲ��ᵼ����һ�ε���һ������������ɱ�������ӡ���Ȼ���ּܹ����ܻḲ������ϡ��ṹ��������dz���Ч�������ڼ������ڼ�������ը��
�����Inception�ܹ��ĵڶ����뷨���ڼ���Ҫ�������̫��ĵط������ǵؼ���ά�ȡ����ǻ���Ƕ��ijɹ���������άǶ����ܰ����������ڽϴ�ͼ������Ϣ��Ȼ��Ƕ�����ܼ���ѹ����ʽ��ʾ��Ϣ����ѹ����Ϣ���Ѵ��������ֱ�ʾӦ���ڴ�����ط�����ϡ�裨����[2]��������Ҫ�����ҽ������DZ������ʱ��ѹ���źš�Ҳ����˵���ڰ����3��3��5��5����֮ǰ��1��1�����������㽵ά������������ά֮�⣬����Ҳ����ʹ������������Ԫʹ�����á����յĽ����ͼ2(b)��ʾ��
ͨ����Inception������һ�����������͵�ģ�黥��ѵ���ɵ����磬ż�����в���Ϊ2�����ػ��㽫����ֱ��ʼ��롣���ڼ���ԭ��ѵ���������ڴ�Ч�ʣ���ֻ�ڸ��߲㿪ʼʹ��Inceptionģ����ڸ��Ͳ��Ա��ִ�ͳ�ľ�����ʽ�ƺ�������ġ��ⲻ�Ǿ��Ա�Ҫ�ģ�ֻ�Ƿ�ӳ������Ŀǰʵ���е�һЩ�����ṹЧ�ʵ��¡�
�üܹ���һ�����õķ�������������������ÿ���εĵ�Ԫ�������������ں���Ľγ��ּ��㸴�ӶȲ��ܿ��Ƶı�ը�������ڳߴ�ϴ�Ŀ���а���ľ���֮ǰͨ���ձ�ʹ�ý�άʵ�ֵġ����⣬�����ѭ��ʵ��ֱ�������Ӿ���ϢӦ���ڲ�ͬ�ij߶��ϴ���Ȼ��ۺϣ�Ϊ������һ�ο��ԴӲ�ͬ�߶�ͬʱ����������
������Դ�ĸ���ʹ����������ÿ���εĿ��Ⱥͽε����������������������������������Inception�ܹ������Բ�һЩ������ɱ����͵İ汾�����Ƿ������п��õĿ�������������Դ���ܿ�ƽ�⣬���������û��Inception�ṹ������ִ�������3��10������������һ������Ҫ��ϸ���ֶ���ơ�
5. GoogLeNet
ͨ����GoogLeNet��������֣������ᵽ����ILSVRC 2014�������ύ��ʹ�õ�Inception�ܹ�������������Ҳʹ����һ�������ʵĸ��������Inception���磬��������뵽������ƺ�ֻ������˽�������Ǻ����˸������ϸ�ڣ���Ϊ����֤�ݱ���ȷ�мܹ��IJ���Ӱ����Խ�С����1˵���˾�����ʹ�õ������Inceptionʵ����������磨�ò�ͬ��ͼ����������ѵ���ģ�ʹ�������������7��ģ���е�6����
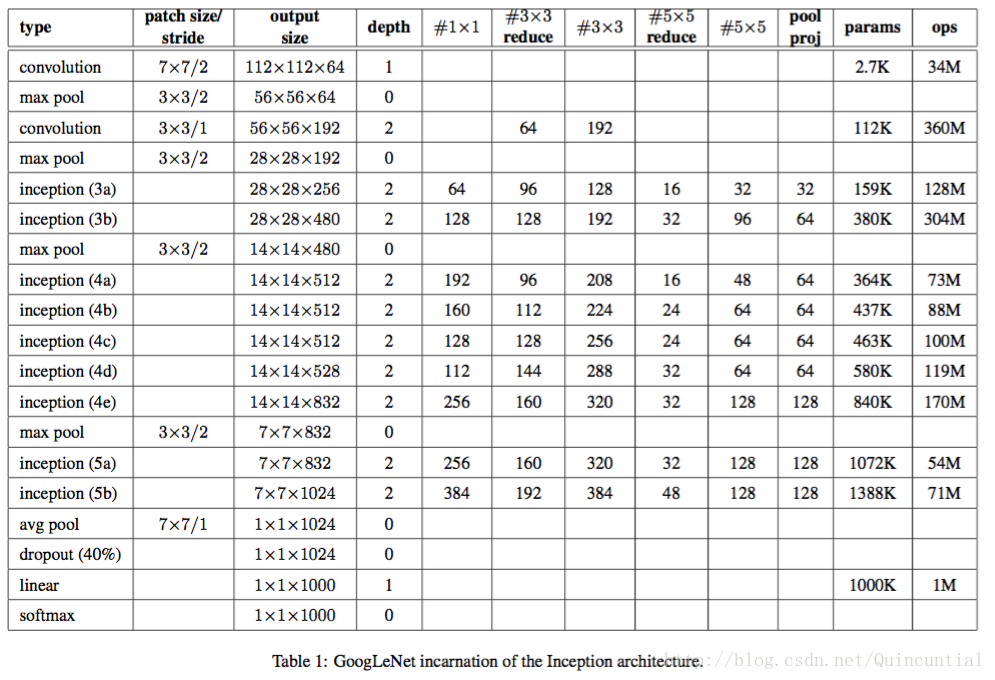
���еľ�����ʹ�����������Լ������Inceptionģ���ڲ��ľ����������ǵ������и���Ұ���ھ�ֵΪ0��RGB��ɫ�ռ��У���С��224��224����#3��3 reduce���͡�#5��5 reduce����ʾ��3��3��5��5����֮ǰ����ά��ʹ�õ�1��1�˲�������������pool proj�п��Կ������õ����ػ�֮��ͶӰ����1��1�˲��������������е���Щ��ά/ͶӰ��Ҳ��ʹ���������������
�������ƿ����˼���Ч�ʺ�ʵ���ԣ�����ƶϿ��Ե������豸�����У�����������Щ������Դ�����豸�������ǵ��ڴ�ռ�õ��豸����ֻ�����в����IJ�ʱ��������22�㣨�������Ҳ����ػ�����27�㣩�����������ȫ���㣨���������飩����Ŀ��Լ��100��ȷ�е�����ȡ���ڻ���ѧϰ������ʩ�Բ�ļ��㷽ʽ��������֮ǰ��ƽ���ػ��ǻ���[12]�ģ��������ǵ�ʵ����һ����������Բ㡣���Բ�ʹ���ǵ������ܺ�������Ӧ�����ı�ǩ����������Ҫ��Ϊ�˷���ʹ�ã����Dz����������ش��Ӱ�졣���Ƿ��ִ�ȫ���Ӳ��Ϊƽ���ػ�������˴�Լtop-1 %0.6��ȷ�ʣ�Ȼ����ʹ���Ƴ���ȫ���Ӳ�֮��ʧ��ʹ�û��DZز����ٵġ�
���������Խϴ�����磬��Ч�����ݶȷ���ͨ�����в��������һ�����⡣����������ϣ���dz�����ǿ�����ܱ��������в������������Ӧ���Ƿdz���ʶ�����ġ�ͨ�����������������ӵ���Щ�м�㣬���������ϵͽη��������б������ⱻ��Ϊ�����ṩ����ͬʱ�˷��ݶ���ʧ���⡣��Щ���������ý�С�����������ʽ��������Inception (4a)��Inception (4b)ģ������֮�ϡ���ѵ���ڼ䣬���ǵ���ʧ���ۿ�Ȩ�أ�������������ʧ��Ȩ����0.3���ӵ������������ʧ�ϡ����ƶ�ʱ����Щ�������类����������Ŀ���ʵ��������������Ӱ����Խ�С��Լ0.5����ֻ��Ҫ����һ������ȡ��ͬ����Ч����
�����������������ڵĸ�������ľ���ṹ���£�
- һ���˲�����С5��5������Ϊ3��ƽ���ػ��㣬����(4a)�ε����Ϊ4��4��512��(4d)�����Ϊ4��4��528��
- ����128���˲�����1��1���������ڽ�ά���������Լ��
- һ��ȫ���Ӳ㣬����1024����Ԫ���������Լ��
- ����70%����Ķ����㡣
- ʹ�ô���softmax��ʧ�����Բ���Ϊ����������Ϊ��������Ԥ��ͬ����1000�࣬�����ƶ�ʱ�Ƴ�����
���յ�����ģ��ͼ��ͼ3��ʾ��
ͼ3�����е����нṹ��GoogLeNet���硣
6. ѵ������
GoogLeNet����ʹ��DistBelief[4]�ֲ�ʽ����ѧϰϵͳ����ѵ������ϵͳʹ��������ģ�ͺ����ݲ��С��������ǽ�ʹ��һ������CPU��ʵ�֣������ԵĹ��Ʊ���GoogLeNet��������ø��ٵĸ߶�GPU��һ��֮��ѵ������������Ҫ���������ڴ�ʹ�á����ǵ�ѵ��ʹ���첽����ݶ��½�����������Ϊ0.9[17]���̶���ѧϰ�ʼƻ���ÿ8�α����½�ѧϰ��4%����Polyakƽ��[13]���ƶ�ʱ�����������յ�ģ�͡�
ͼ����������ڹ�ȥ�����µľ����з������ش�仯��������������ģ��������ѡ���Ͻ�����ѵ������ʱ������ų������ĸı䣬���綪����ѧϰ�ʡ���ˣ����Ѷ�ѵ����Щ���������Ч�ĵ�һ��ʽ������ȷָ��������������ӵ��ǣ���[8]��������һЩģ����Ҫ������Խ�С�IJü�ͼ�����ѵ��������ģ����Ҫ������Խϴ�IJü�ͼ���Ͻ���ѵ����Ȼ����һ��������֤�ķ����ھ��������غܺã��������ֳߴ��ͼ���IJ��������ijߴ���ȷֲ���ͼ�������8%����100%֮�䣬���������Ϊ [34,43] [ 3 4 , 4 3 ] ֮�䡣���⣬���Ƿ���Andrew Howard[8]�Ĺ��Ť�����ڿ˷�ѵ�����ݳ��������Ĺ���������õġ�
7. ILSVRC 2014������ս�����úͽ��
ILSVRC 2014������ս��������ͼ����ൽImageNet�㼶��1000��Ҷ�ӽ����������ѵ��ͼ���Լ��120���ţ���֤ͼ����5���ţ�����ͼ����10���š�ÿһ��ͼ����һ��ʵ���������������ܶ������ڷ�����Ԥ�����߷֡�ͨ�������������֣�top-1ȷ�ʣ��Ƚ�ʵ�����͵�һ��Ԥ�����top-5�����ʣ��Ƚ�ʵ�������ǰ5��Ԥ��������ͼ��ʵ�������top-5�У�����Ϊͼ�������ȷ����������top-5�е���������ս��ʹ��top-5������������������
���DzμӾ���ʱû��ʹ���ⲿ������ѵ�������˱�����ǰ���ᵽ��ѵ������֮�⣬�����ڻ�ø������ܵIJ����в�����һϵ�м��ɣ��������¡�
- ���Ƕ���ѵ����7���汾����ͬ��GoogLeNetģ�ͣ�����һ�����㷺�İ汾�����������ǽ���������Ԥ�⡣��Щģ�͵�ѵ��������ͬ�ij�ʼ��������������ͬ�ij�ʼȨ�أ����ڼල����ѧϰ�ʲ��ԡ����ǽ��ڲ����������������ͼ��˳���治ͬ��
- �ڲ����У����Dz��ñ�Krizhevsky����[9]�������IJü�������������˵�����ǽ�ͼ���һ��Ϊ�ĸ��߶ȣ����н϶�ά�ȣ��߶Ȼ���ȣ��ֱ�Ϊ256��288��320��352��ȡ��Щ��һ����ͼ������У��ҷ��飨��Ф��ͼƬ�У����Dz��ö��������ĺ͵ײ����飩������ÿ�����飬���ǽ�����4�����Լ�����224��224�ü�ͼ���Լ�����ߴ��һ��Ϊ224��224���Լ����ǵľ���汾�����ÿ��ͼ���õ�4��3��6��2 = 144�IJü�ͼ��ǰһ��������У�Andrew Howard[8]���������Ƶķ�������������ʵ֤��֤���䷽���Բ�����������ķ���������ע�����ʵ��Ӧ���У����ֻ����ü������Dz���Ҫ�ģ���Ϊ���ں��������IJü�ͼ�����ü�ͼ��ĺô����ú�С���������Ǻ���չʾ����������
- softmax�����ڶ���ü�ͼ���Ϻ����е����������Ͻ���ƽ����Ȼ��������Ԥ�⡣�����ǵ�ʵ���У����Ƿ�������֤���ݵ��������������ü�ͼ���ϵ����ػ��ͷ�������ƽ�����������DZȼ�ƽ����������ѷ��
�ڱ��ĵ����ಿ�֣����Ƿ����������������ύ�������ܵĶ�����ء�
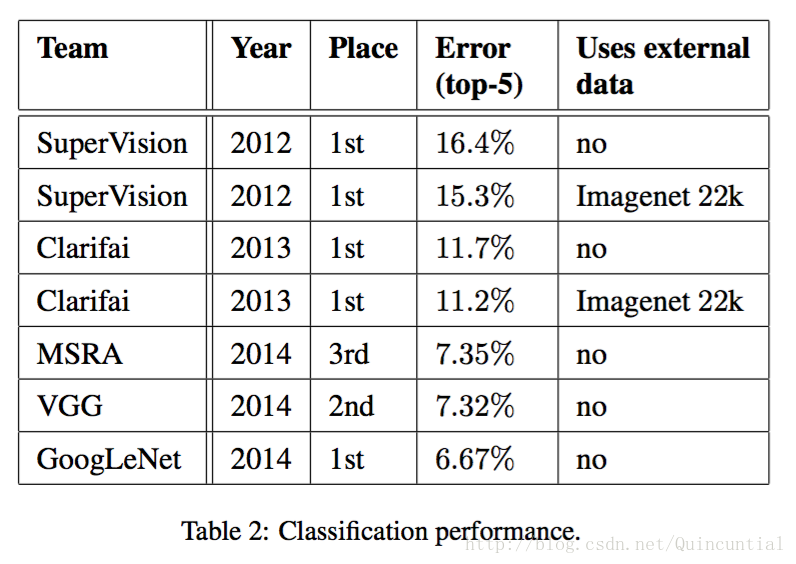
���������ǵ������ύ����֤���Ͳ��Լ��ϵõ���top-5 6.67%�Ĵ����ʣ��������IJ�������������һ����2012���SuperVision���������Լ�����56.5%����ǰһ�����ѷ�����Clarifai�������Լ�����Լ40%�������ַ�����ʹ�����ⲿ����ѵ������������2��ʾ�˹�ȥ������һЩ������õķ�����ͳ�ơ�
����Ҳ���������˶��ֲ���ѡ������ܣ���Ԥ��ͼ��ʱͨ���ı��3��ʹ�õ�ģ����Ŀ�Ͳü�ͼ����Ŀ��
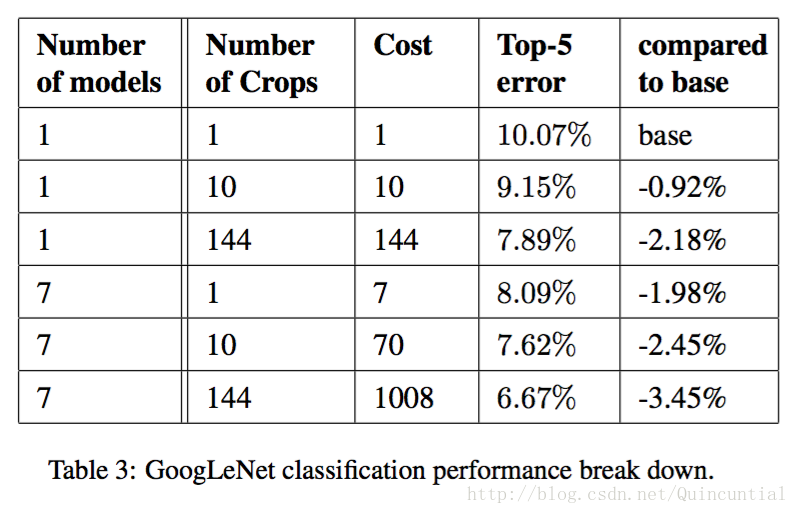
8. ILSVRC 2014�����ս�����úͽ��
ILSVRC���������Ϊ����200�����ܵ����������ͼ����Ŀ��ı߽��������Ķ���ƥ�������ʵ����������ǵı߽���ص�����50%��ʹ��Jaccard�����������Ķ����Ϊ��ȷ���صļ���Ϊ�������ұ��ͷ�������������෴��ÿ��ͼ����ܰ�����������û�ж��������ǵij߶ȿ����DZ仯�ġ�����Ľ��ʹ��ƽ�����Ⱦ�ֵ��mAP����GoogLeNet�����õķ���������R-CNN[6]������Inceptionģ����Ϊ�����������������ǿ�����⣬Ϊ�˸��ߵ�Ŀ��߽���ٻ��ʣ�ͨ��ѡ������[20]�����Ͷ���[5]Ԥ�����ϸĽ����������ɲ��衣Ϊ�˼��ټ����Ե����������ֱ��ʵijߴ�������2�����⽫ѡ�������㷨���������ɼ�����һ�롣�����ܹ�������200�����Զ�н�����������ɣ���Լ60%��������������[6]��ͬʱ�������ʴ�92%��ߵ�93%�������������ɵ����������Ӹ����ʵ�����Ӱ���Ƕ��ڵ���ģ�͵����ƽ�����Ⱦ�ֵ������1%����ȷ��������ʱ������ʹ����6��GoogLeNets����ϡ����ȷ�ʴ�40%��ߵ�43.9%��ע�⣬��R-CNN�෴������ȱ��ʱ������û��ʹ�ñ߽��ع顣
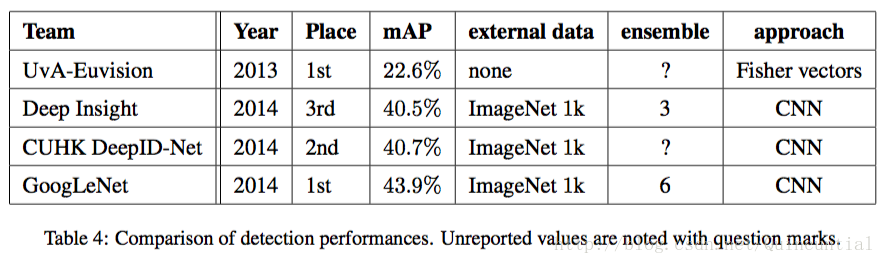
�������ȱ�������ü����������ʾ�˴ӵ�һ�������������Ľ�չ����2013��Ľ����ȣ�ȷ�ʼ�������һ�������б�����õ��ŶӶ�ʹ���˾������硣�����ڱ�4�б����˹ٷ��ķ�����ÿ������ij������ԣ�ʹ���ⲿ���ݡ�����ģ�ͻ�������ģ�͡��ⲿ����ͨ����ILSVRC12�ķ������ݣ�����Ԥѵ��ģ�ͣ������ڼ�����ݼ��Ͻ��и��ơ�һЩ�Ŷ�Ҳ�ᵽʹ�ö�λ���ݡ����ڶ�λ����ı߽��ܴ�һ���ֲ��ڼ�����ݼ��У����Կ����ø�����Ԥѵ��һ��ı߽��ع������������Ԥѵ���ķ�ʽ��ͬ��GoogLeNet����û��ʹ�ö�λ���ݽ���Ԥѵ����
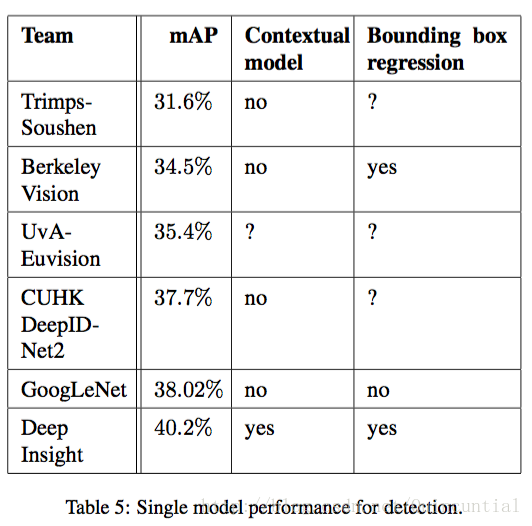
�ڱ�5�У����ǽ��Ƚ��˵���ģ�͵Ľ�����������ģ����Deep Insight�ģ����˾��ȵ���3��ģ�͵ļ��Ͻ������0.3���㣬��GoogLeNet��ģ�ͼ���ʱ���Ի���˸��õĽ����
9. �ܽ�
���ǵĽ��ȡ���˼�ʵ��֤�ݣ���ͨ����õ��ܼ����������������������ϡ�����Ǹ��Ƽ�����Ӿ��������һ�ֿ��з���������ڽ�dz�ҽ�խ�ļܹ��������������Ҫ�������ڼ��������ʶ����ӵ���������������������档
���ǵ�Ŀ�������Ȼû�����������ģ�Ҳû��ִ�б߽��ع飬����Ȼ���о����������һ����ʾ��Inception�ܹ����Ƶ�֤�ݡ�
���ڷ���ͼ�⣬Ԥ��ͨ���������������ȺͿ��ȵķ�Inception�����������ʵ�����������Ľ����Ȼ�������ǵķ���ȡ���˿ɿ���֤�ݣ���ת���ϡ��Ľṹһ����˵�ǿ������õ��뷨�������δ���Ĺ�������[2]�Ļ��������Զ�����ʽ������ϡ�����ϸ�Ľṹ���Լ���Inception�ܹ���˼��Ӧ�õ���������
�����
[1] Know your meme: We need to go deeper. http://knowyourmeme.com/memes/we-need-to-go-deeper. Accessed: 2014-09-15.
[2] S. Arora, A. Bhaskara, R. Ge, and T. Ma. Provable bounds for learning some deep representations. CoRR, abs/1310.6343, 2013.
[3] U. V. C ?atalyu ?rek, C. Aykanat, and B. Uc ?ar. On two-dimensional sparse matrix partitioning: Models, methods, and a recipe. SIAM J. Sci. Comput., 32(2):656�C683, Feb. 2010.
[4] J. Dean, G. Corrado, R. Monga, K. Chen, M. Devin, M. Mao, M. Ranzato, A. Senior, P. Tucker, K. Yang, Q. V. Le, and A. Y. Ng. Large scale distributed deep networks. In P. Bartlett, F. Pereira, C. Burges, L. Bottou, and K. Weinberger, editors, NIPS, pages 1232�C1240. 2012.
[5] D. Erhan, C. Szegedy, A. Toshev, and D. Anguelov. Scalable object detection using deep neural networks. In CVPR, 2014.
[6] R. B. Girshick, J. Donahue, T. Darrell, and J. Malik. Rich feature hierarchies for accurate object detection and semantic segmentation. In Computer Vision and Pattern Recognition, 2014. CVPR 2014. IEEE Conference on, 2014.
[7] G. E. Hinton, N. Srivastava, A. Krizhevsky, I. Sutskever, and R. Salakhutdinov. Improving neural networks by preventing co-adaptation of feature detectors. CoRR, abs/1207.0580, 2012.
[8] A. G. Howard. Some improvements on deep convolutional neural network based image classification. CoRR, abs/1312.5402, 2013.
[9] A. Krizhevsky, I. Sutskever, and G. Hinton. Imagenet classification with deep convolutional neural networks. In Advances in Neural Information Processing Systems 25, pages 1106�C1114, 2012.
[10] Y. LeCun, B. Boser, J. S. Denker, D. Henderson, R. E. Howard, W. Hubbard, and L. D. Jackel. Backpropagation applied to handwritten zip code recognition. Neural Comput., 1(4):541�C551, Dec. 1989.
[11] Y. LeCun, L. Bottou, Y. Bengio, and P. Haffner. Gradient-based learning applied to document recognition. Proceedings of the IEEE, 86(11):2278�C2324, 1998.
[12] M. Lin, Q. Chen, and S. Yan. Network in network. CoRR, abs/1312.4400, 2013.
[13] B. T. Polyak and A. B. Juditsky. Acceleration of stochastic approximation by averaging. SIAM J. Control Optim., 30(4):838�C855, July 1992.
[14] P. Sermanet, D. Eigen, X. Zhang, M. Mathieu, R. Fergus, and Y. LeCun. Overfeat: Integrated recognition, localization and detection using convolutional networks. CoRR, abs/1312.6229, 2013.
[15] T. Serre, L. Wolf, S. M. Bileschi, M. Riesenhuber, and T. Poggio. Robust object recognition with cortex-like mechanisms. IEEE Trans. Pattern Anal. Mach. Intell., 29(3):411�C426, 2007.
[16] F. Song and J. Dongarra. Scaling up matrix computations on shared-memory manycore systems with 1000 cpu cores. In Proceedings of the 28th ACM Interna- tional Conference on Supercomputing, ICS ��14, pages 333�C342, New York, NY, USA, 2014. ACM.
[17] I. Sutskever, J. Martens, G. E. Dahl, and G. E. Hinton. On the importance of initialization and momentum in deep learning. In ICML, volume 28 of JMLR Proceed- ings, pages 1139�C1147. JMLR.org, 2013.
[18] C.Szegedy,A.Toshev,andD.Erhan.Deep neural networks for object detection. In C. J. C. Burges, L. Bottou, Z. Ghahramani, and K. Q. Weinberger, editors, NIPS, pages 2553�C2561, 2013.
[19] A. Toshev and C. Szegedy. Deeppose: Human pose estimation via deep neural networks. CoRR, abs/1312.4659, 2013.
[20] K. E. A. van de Sande, J. R. R. Uijlings, T. Gevers, and A. W. M. Smeulders. Segmentation as selective search for object recognition. In Proceedings of the 2011 International Conference on Computer Vision, ICCV ��11, pages 1879�C1886, Washington, DC, USA, 2011. IEEE Computer Society.
[21] M. D. Zeiler and R. Fergus. Visualizing and understanding convolutional networks. In D. J. Fleet, T. Pajdla, B. Schiele, and T. Tuytelaars, editors, ECCV, volume 8689 of Lecture Notes in Computer Science, pages 818�C833. Springer, 2014.