Ŀ¼
һ������
���������������PCS����PMA��
2.1 PCS�����
2.2 PMA�����
2.3 ���ﶨ��
2.3 8B/10B������
2.4 �ַ�������Ǻ�
2.5 ���в�һ�£�Running Disparity��
2.6 8B/10B����
2.7 ����˳��
2.8 8B/10B����
2.9 �����ַ�������
����ʹ�ô���������
3.1 �˿ڳ�ʼ������
3.2 ��������
3.3 ��������
3.4 1x����RapidIO��·�ϵ�������
3.5 4x����RapidIO��·�ϵ�������
�ġ��ܽ�
�塢�ο�����
һ������
����ǰ��ƪ�����Ѿ�̸��RapidIO��Э�飬��������������Ʒ��š�
����RapidIOЭ�����������NREAD����д����NWRITE������д����SWRITE��������Ӧ��д����NWRITE_R����ԭ�Ӳ�����ATOMIC����ά��������MAINTENANCE������������DOORBELL������Ϣ��MESSAGE���⼸�֡�
����RapidIO�Ĵ����������ǻ���SERDES�ģ�����SERDES�漰��һЩ��ؼ������Ķ���SERDES�ؼ������ܽᡷ�����ӣ�https://www.cnblogs.com/liujinggang/p/10125727.html����ƪ���¡�SERDES��ΪPCS�����������Ӳ㣩��PMA������ý�鸽���Ӳ㣩���㣬����PCS���ɴ����ֵ�·��ɣ�������������ʵ�֣���PMA��Ȱ��������ֵ�·��Ҳ������ģ���·�������ô���ʵ�֡�
�������Ʒ����DZ�������·�˿���ʹ�õ���Ϣ��Ԫ������������������·�����ĸ������ܣ�������·ά�������綨����Ӧ�𣬴���ʹ���ָ��ȡ�
��������ǰ��Ļ����Ժ�������̸һ̸RapidIO������������Ĵ�����̡�
���������������PCS����PMA��
�������������Ӳ�(PCS)������ý�鸽���Ӳ�(PMA)�ṩSERDES�ܹ����и��ٴ������ݴ���Ļ�������(����PCS��PMA����IEEE 802.3 )����Ҫ����8B/10B���롢�ַ���ʾ�����������ķֶΡ�����(Code Group)������(Column)����·�������������(Idle Sequence)����·��ʼ����
����ͨ���ĸ���������������RapidIO�˵�Ŀ��ȡ�ͨ������Ϊÿ�������ϵĵ����ֶԡ�Ŀǰ����RapidIO�涨��������·���ȣ� 1x��·Ϊ1ͨ����·�� 4x��·Ϊ4ͨ����·����������·Ҳ�ǿ��ܵ�, ����Ŀǰ��û��֪����
������ͼչʾ��һ�����͵�RapidIO�˵�Ľṹ����ͼ���ϲ��Ǹ����������RapidIO��������ʹ���㡣����Щ����������ŵ��Ǵ���Э��㣬�ò㸺������ʹ������Ʒ��Ų�ͨ����·����Э�������·������Э���������PCS�㡣��·Э��������PCS��֮��ı߽�ͨ��Ҳ��ʱ�Ӵ������ڲ�ʱ��ת��Ϊ RapidIO�˵㱾��ʱ�ӵ�ת��߽硣PCS�㸺��ͨ���ֶ�(Striping)�������������в����ַ�ת��Ϊ��Ӧ��8B/10B�����K���D�롣PCS��������PMA�㣬�ò㸺�����������νӡ�PMA�㻹����ȷ����ͬͨ����˴���ȷ���롣�����������ͬ����������������֮��ĵ������ӡ�

2.1 PCS�����
�������������Ӳ�(PCS)�Ĺ����Ǹ�������������С�ͨ���ֶΡ����ͱ��롢���롢ͨ��������ڽ���ʱ���ֶκϲ���PCSʹ��8B/10B������������·�Ϸ������ݡ�8B/10B���뷽�������IBM���������ڹ�ҵ��㷺���ڽ����ݺ�ʱ����Ϣ�ϲ�Ϊһ���������źš�
����PCS�㻹�ṩ���ж��˿ڵIJ���ģʽ��4ͨ������1ͨ���Ļ��ƺͼ�����·״̬�ķ������ò������ڷ����ߺͽ�����֮�����ʱ�Ӳ���������������ơ�
����PCS��ִ�����з����ܣ�
����1�� ���ڶ����еȴ����͵İ��Ͷ�����Ʒ�����ȡ��������ַ�����
����2�� �ڿ���ͨ���Ϸֶη����ַ�����
����3�� ��û�д����͵İ��Ͷ�����Ʒ���ʱ�������������в�������뵽ÿ��ͨ�����͵��ַ����С�
����4�� ��ÿ��ͨ�����ַ�����������Ϊ10λ�������顣
����5�� ���γɵ�10λ�������鴫�ݸ�PMA�㡣
����PCS��ִ�����н��չ��ܣ�
����1�� ����10λ��������Ľ�����Ϊ��ͨ�������ķ��š�
����2�� ������Ч�������õ����ַ����Ϊ��Ч��
����3�� �����·ʹ�ö���һ����ͨ���������ַ���������ͨ�����ƫ�Ʋ���ÿ��ͨ���ϵ��ַ���������װΪһ���������ַ�����
����4�� �������ַ����õ��İ��Ͷ�����Ʒ��ŵ��͵����߲㡣
2.2 PMA�����
�����������ʸ�����(PMA)�Ĺ�������ͨ����10λ�������鴮�л�Ϊ���б����������б�����ת��Ϊ10λ�������顣�ڽ�������ʱ�� PMA��Ĺ����ǽ����յ��ı�������ͨ���ֱ���뵽10λ����߽硣���Ÿò���PCS���ÿ��ͨ���ṩһ����������������10λ�����PCS�����ϵĸ����Dz��ɼ��ġ�
2.3 ���ﶨ��
����������PCS��PMA��ʱʹ�õ����ﶨ�����£�
����1���ֽ�(Byte)�� һ��8λ��Ϣ�gԪ,�ֽ���ÿλ��ֵΪ0��1��
����2���ַ�(Character)������Ϣ�ֽں�һ������λ��ɵ�9λʵ�塣����λָʾ��Ϣ�ֽڰ����������ݻ��ǿ�����Ϣ������λ��ֵΪD��K���ֱ�ָʾ��Ϣ�ֽڰ������ݻ������Ϣ��
����3��D�ַ���D- Character��������λΪD���ַ���Ҳ��Ϊ�����ַ���
����4��K�ַ���K- Character��������λΪK���ַ�,Ҳ��Ϊ�����ַ���
����5�����飨Code-group�������ַ�����8B/10B����õ���10λʵ�塣
����6�����У�Column����ͬʱ��4x(4ͨ��)��·�ϴ��͵���4���ַ���ɵ���Ⱥ��
����7��Comma��8B/10B����������Ψһ��ֻ����7�����ص��ַ����������������ж�����߽硣
����8���������У�Idle Sequence�����������Ͱ����߿��Ʒ���ʱ���͵��ַ�(����������) ���У��������������շ�˫������ͬ��������֤�ڰ�֮�䡢���Ʒ���֮���Լ�������Ʒ���֮���������롣
����9��ͨ�����루Lane Alignment��������4ͨ��������·ͨ����ƫ�ƵĹ��̡��ɷ����������У�Column�����͵������ɽ����ߵĶ���������������������ͨ�����룬�����з��͵��ַ����ܻᱻ��ɢ���ɽ�������������������ϡ��������ʹ����Ϊ�������е�һ���ִ��͵���������ַ���
����10���ֶΣ�Striping��: 4x��·��ʹ�õ���4��ͨ����ͬʱ�������ݵķ����������ַ������ַ���ɢ�����ͨ���ϡ���1����4���ַ����ֶδ����քe���䵽ͨ��0��ͨ��3�ϣ���5���ַ���ѭ�����䵽ͨ��0�ϣ��Դ����ơ�
2.3 8B/10B������
����PCS�ڷ�������ʱʹ��8B/10B�����뽫9λ�ַ�(8λ��Ϣ��1λ����λ)����Ϊ10λ���飬��������ʱ������෴�IJ�����256�������ַ���12������(����)�ַ��������˱��롣
����8B/10B��ʹ�õ������У���0���͡�1���ĸ������(ƽ��)�����2(��ƽ��)�����ѡ�����鱣֤����ÿһ���������ٴ����������䣬��0��1��1��0��ʹά��ƽ��������ü��ַ�������Ϊһ��������ƽ�������һ�Բ�ƽ�����顣����Եij�Ա��������Է���������������������ѡ���ƽ������ʱ������ά�ֱ����������������0/1ƽ�����������ѡ��һ������1���϶��0���϶�ķ�ƽ�����顣
����8B/10B�������������ԣ�
����1�������λ�����ܶ�(ÿ��������3~8������)�����������ն˽���ʱ�ӻָ���
����2��ʹ���������齨�������߶�10λ����߽��ͬ����������Ʒ��Ų�ά�ֽ�����λ������ı߽�ͬ����
����3��ֱ��ƽ��(��0���͡�1���ĸ���������ͬ)��
����4���ɼ��ijЩ�����ػ����ش���
2.4 �ַ�������Ǻ�
����8B/10B����ͽ���ʹ�����мǺ������ַ�����������ǵ�λ��
����δ�����ַ�����Ϣλ[0-7]����ĸA��H��ǣ�H��ǵ��������Ϣλ��RapidIO��0λ����A��ǵ��������Ϣλ��RapidIO��7λ��������ͼ��ʾ
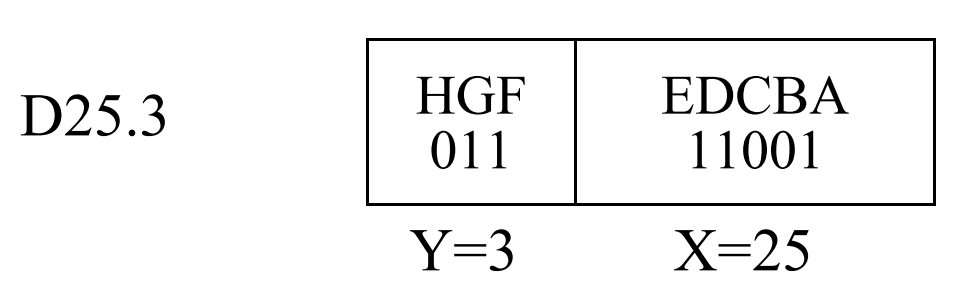
ÿ�������ַ�����һ��Dx.y��ʽ�ı�ʾ��������x�����5����ϢλEDCBA��ʮ����ֵ��y�����3����ϢλHGF��ʮ����ֵ��ͬʱ��ÿ�������ַ�Ҳ����һ����֮���Ƶ�Kx.y��ʽ�ı�ʾ����
����8B/10B��������������10λ���飬����ĸa��j��������λ�������λ������ȵ���Ҫ�ԣ�û�����λ�����λ������λ�Ĵ�������ͼ��ʾ
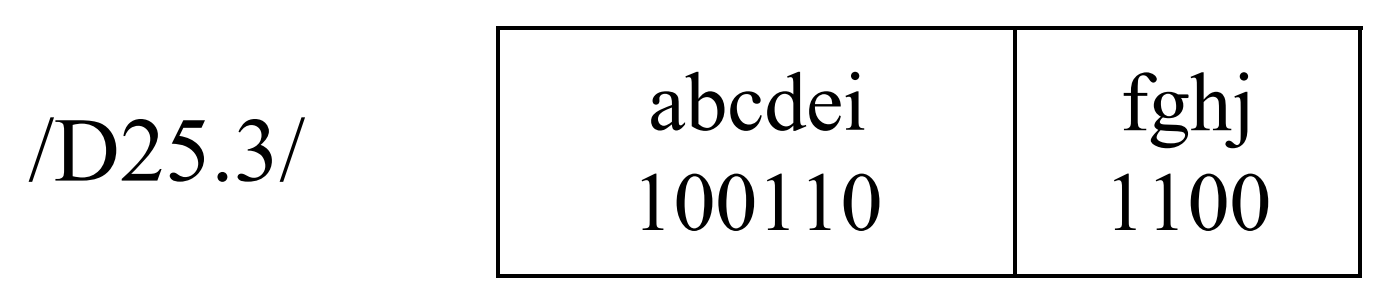
�����������ַ�Dx.y��8-bit����Ӧ��������/Dx.y/��10-bit����ʾ���������ַ�Kx.y��8-bit����Ӧ��������/Kx.y/��10-bit����ʾ��
2.5 ���в�һ�£�Running Disparity��
����8B/10B����ͽ��빦��ʹ��һ����Ϊ���в�һ�µĶ����Ʊ������ñ���ֵ��Ϊ��(RD+)��(RD-)��ʵ���ϣ����в�һ�±�����ʾ�ľ���10-bit�����С�0���ĸ����͡�1���ĸ����IJ�ֵ������0���ĸ������ڡ�1���ĸ���ʱ�����в�һ�±�����ֵΪ��������0���ĸ���С�ڡ�1���ĸ���ʱ�����в�һ�±�����ֵΪ������ʵҪ��ֱ֤��ƽ����ķ�ʽ��ʹ10-bit�����е�0��1�ĸ�����ͬ��Ҳ����10-bit�����С�0���͡�1���ĸ�������5��������10-bit�����м�Ҫ����ֱ��ƽ�⣬��Ҫ���㹻�����䣨3~8�����䣩ʹ�ý��շ��ܹ��ָ���ʱ���źţ���ô����Ҫ��ġ�0���͡�1��������ͬ��10-bit���������Dz����ģ����Ա�������һЩ��0���͡�1���ĸ�������ȵ����飬����������ͨ����������в�һ�±�����ֵ��ѡ����һ��Ҫ���͵���������֤������·��ֱ��ƽ�⡣
����ÿ��ͨ���ı������ͽ���������һ�����в�һ�±���������4x��·����ͨ�����в�һ�µ�ֵ�������
�����ڱ�����������в�һ�µ���Ҫ��;�Ǹ��ٽ������Ƿ�����˽϶��1��϶��0�����ַ�������Ҫ��������ƽ���������ѡ��һ������ʱ��ʹ�ñ༭����ǰ�����в�һ��ѡ�������һ����ƽ�����顣
�������ϵ��Ͷ˿ڿɲ���ǰ��������(������)�ͽ�����(������)�����뽨�����в�һ�µĵ�ǰֵ��������ʹ�ø�ֵ��Ϊÿ��ͨ�����в�һ�µij�ʼֵ�������߿���ʹ�ø�ֵ����ֵ��Ϊÿ��ͨ�������в�һ�±����ij�ʼֵ��
����ʹ�������㷨�����ͨ�������в�һ��ֵ���ڱ������У����㷨���ɱ�������������������в������ڽ��շ������㷨�Խ��յ����ɽ������������������в�����
����ÿ�����鱻��Ϊ�����ӿ飬����ͼ��ʾ��ǰ6λ(abcdei)�γ�һ���ӿ�(6λ�ӿ�)������4λ(fghi)�γ���һ���ӿ�(4λ�ӿ�)��6λ�ӿ�ͷ�������в�һ��ֵ��ǰһ������β�������в�һ��ֵ��4λ�ӿ�ͷ�������в�һ��ֵ��6λ�ӿ�β�������в�һ��ֵ������ĩβ�����в�һ��ֵ��4λ�ӿ�β�������в�һ��ֵ��
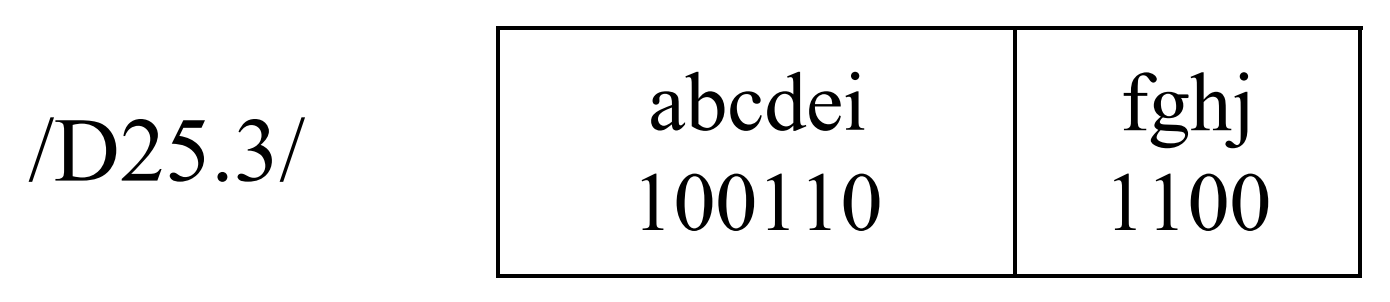
�����ӿ����в�һ��ֵ�ļ��㷽������:
����1������ӿ������1���ĸ������ڡ�0���ĸ�������ô�κ��ӿ�β�������в�һ��ֵ�������ġ����4λ�ӿ�ֵΪ0b0011����β�������в�һ��ֵҲ�����ġ����6λ�ӿ�ֵΪ0b000111����β�������в�һ��ֵҲ�����ġ�
����2������ӿ������0���ĸ������ڡ�1���ĸ�������ô���κ��ӿ�β�������в�һ��ֵ���Ǹ��ġ����4λ�ӿ�ֵΪ0b1100����β�������в�һ��ֵҲ�Ǹ��ġ����6λ�ӿ�ֵΪ0b111000����β�������в�һ��ֵҲ�Ǹ��ġ�
����3���������κ�����£��ӿ�β�������в�һ��ֵ�������ӿ�ͷ�������в�һ��ֵ��ͬ��
2.6 8B/10B����
����8B/10B���빦�ܽ�9λ�ַ�����Ϊ10λ���顣RapidIO�淶����256�������ַ�(Dx.y)��12����������(Kx.y)�ı��롣��Щ���뼸����ȫ����IEEE 802.3��������10Gλ��̫��(XAUI)����ӿڱ��ж���ı��롣�����������һ��9λ�ַ��������б��룬һ�м�ΪRD-�������в�һ�£�����һ�м�ΪRD+�������в�һ�£������ַ�����ʱ�������ǰ�����������в�һ��ֵΪ������ѡ��RD-���е�������Ϊ�������������ǰ�����������в�һ��ֵΪ������ѡ��RD+���е�������Ϊ����������ÿ���ַ������������Ӧ���������в�һ�¹���ʹ�ñ���õ���������������в�һ��ֵ�� .
2.7 ����˳��
���������������10λ�������龭���л����ԡ�abcdeifghj����λ�����ͣ����С�a��λ���ȷ��͡�����ͼ��ʾ����ͼ������һ���ַ��������롢����ת�������͡�����ת���ͽ�����������̡�ͼ�������ʾ�ķ�������ʹ��8B/10B������ַ��������10λ����ת�����̡��ұ���ʾ���ǽ����߶Խ��յ���������д���ת����8B/10B����Ĺ��̡��㻮���Dz���10λ�����PCS��ʹ��л������PMA��Ĺ��ֽܷ��ߡ�
������ͼ����ʾ���ڽ��շ�������ʹ�ð���Comma���е������ַ�������10λ����ı߽���롣

2.8 8B/10B����
����8B/10B���빦�ܽ����յ���10λ�������Ϊ9λ�ַ��������յ���δ�����������鲢��ǽ���������еõ�����Ӧ�ַ�Ϊ��Ч�ַ���INVALID����
�������빦��ʹ����8B/10B�����෴�Ľ�����ͽ�������ǰ�����в�һ��ֵ�������������յ���������������ѡ������е��������Ƚϡ�����ҵ�ƥ�䣬����ͱ�����Ϊ��Ӧ�ַ�������Ҳ���ƥ�䣬����ͱ�����Ϊһ����ij�ַ�ʽ���Ϊ��Ч���ַ����ڽ���ÿ���������������Ӧ�������в�һ�¹���ʹ�ý���õ�����������½����������в�һ��ֵ��
�����±���һ���������ַ���Dx.y���Ľ�����������Ľ������鿴�ο�����1��492ҳ��499ҳ
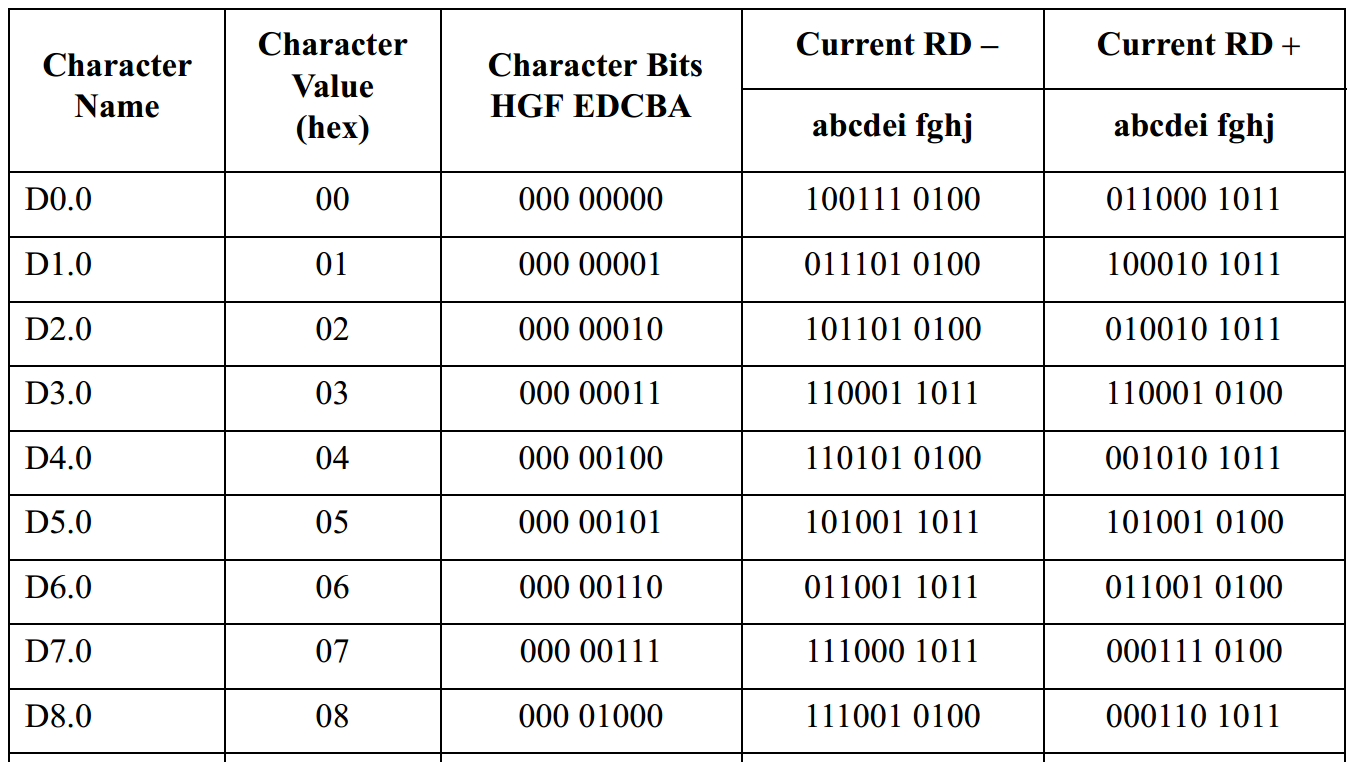
�����±���12�������ַ���Kx.y���Ľ����
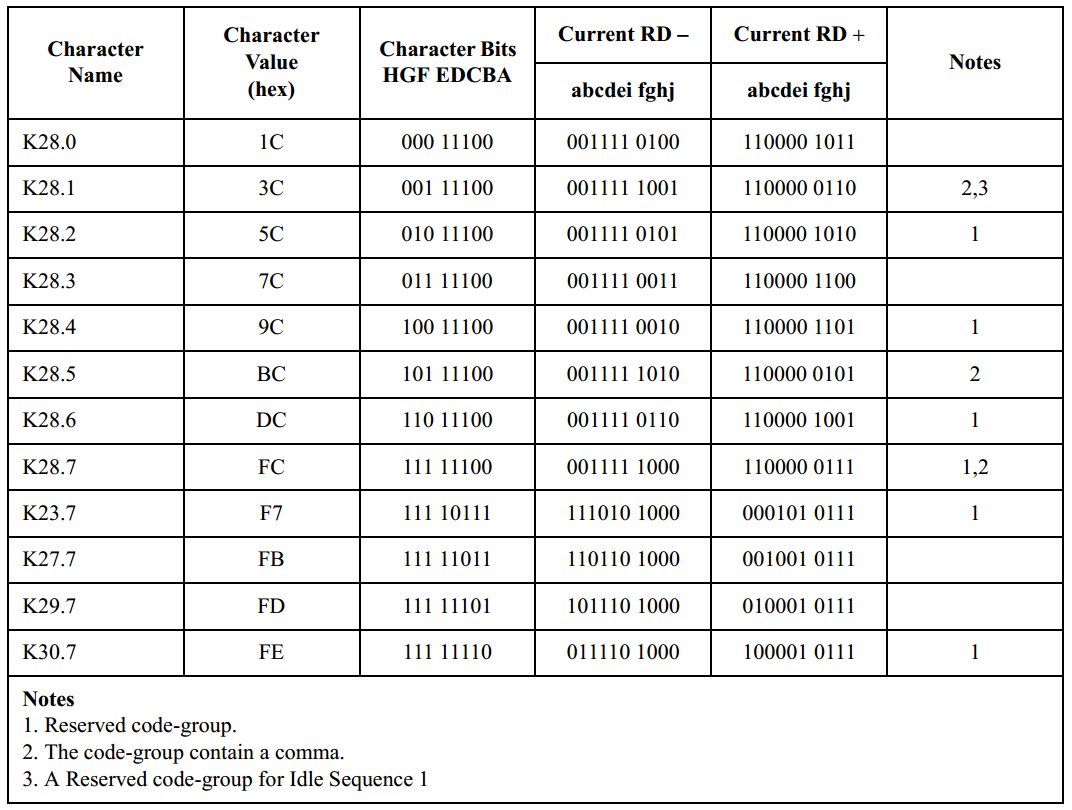
����Comma��8B/10B������зdz���Ҫ��һ����Ԫ����ֻ��7��bit��������·��������Commaʵ������ı߽���롣8B/10B��һ������������Comma���ֱ�Ϊ0b0011111��Comma+����0b1100000��Comma-����������Comma�ֱ��Ӧ��������/K28.1/��/K28.5/��/K28.7/��abcdeifλ��������ת������Ժ���û�д��������������£�Comma�����ܳ����������е��κ�λ�ã�Ҳ��������������������ı߽������������һ��������⣺
��������������/K28.7/���洫�������������/D3.y/��/D11.y/��/D12.y/��/D19.y/��/D20.y/��/D28.y/��/K28.y/��y��ȡֵ��Χ��0~7���������е�����һ��ʱ���п��ܵ���comma����������ı߽������ȡ�������в�һ�µ�ֵ�����������������ı߽������comma����ô������·���п��ܸı�10-bit����Ķ���λ�á���ˣ���������/K28.7/�����������Ի�����ϵ�Ŀ�ġ�
2.9 �����ַ�������
�����±�������RapidIO�����������е������ַ������У�ʹ�������ַ�����������¹��ܣ�
����1�� ��ͨ���������飨10λ���߽硣
����2�� ����ͨ���ĸ�ͨ���Ľ���������
����3�� ���IDLE2 Sequence ��CS�����ʼλ�ã�CS = Command and Status��
����4�� �����ߺͷ������ʱ�����ʲ���
����5�� ���Ʒ��Ž綨
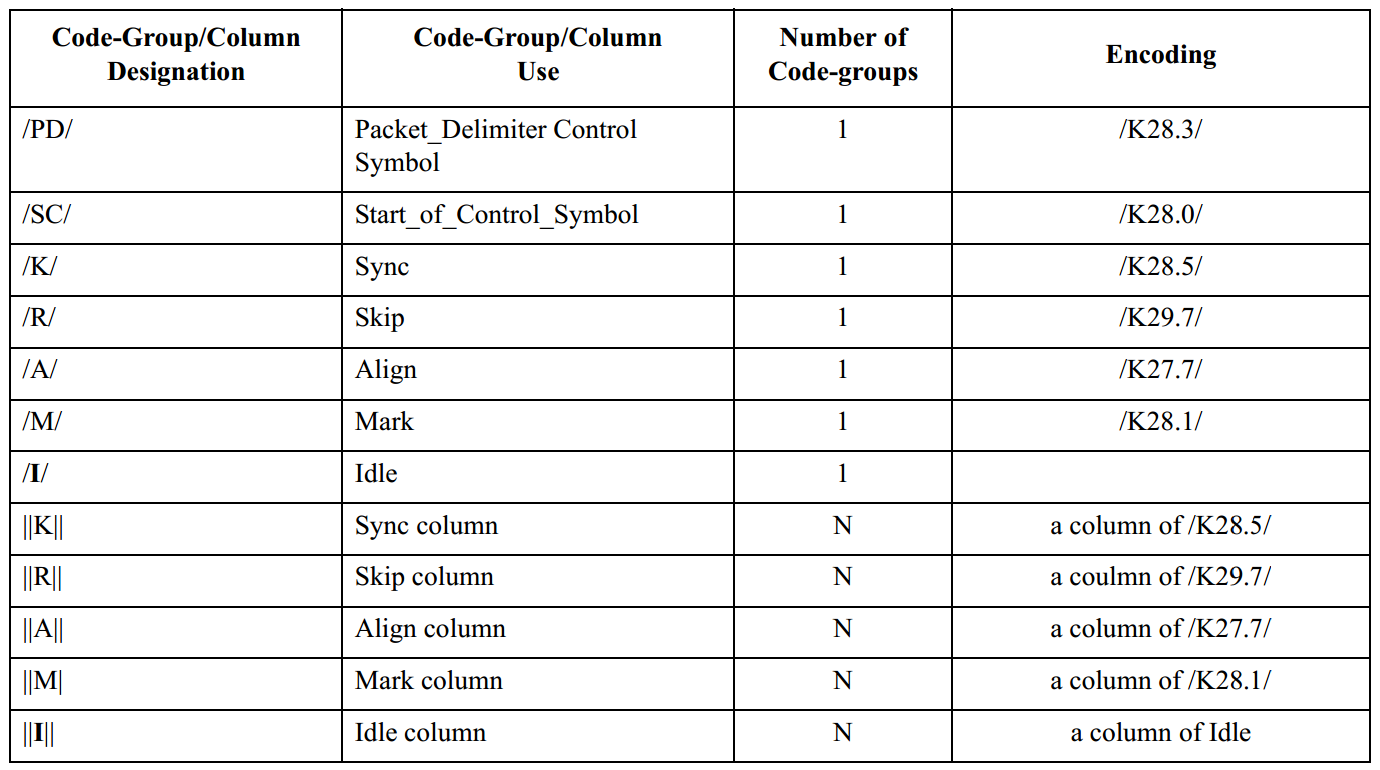
����������ϱ��еĸ��������ַ�������Ĺ��ܽ��зֱ�˵����
�������ֽ���Ʒ��ţ�/PD/����
����PD��/PD/�ֱ���K28.3�ַ���/K28.3/����ı��������ڶ��������������Ŀ��Ʒ��ŵĿ�ʼ
�������Ʒ��ŵĿ�ʼ��/SC/����
����SC��/SC/�ֱ���K28.0�ַ���/K28.0/����ı��������ڶ��粻������������Ŀ��Ʒ��ŵĿ�ʼ
����ͬ����/K/����
����K��/K/�ֱ���K28.5�ַ���/K28.5/����ı�������������ʹ�ø��ַ���������������ṩ��������Ҫ��ò�ά�ֵ�λ��10λ����ı߽�ͬ����Ϣ��ѡ��/K28.5/������Ϊͬ���ַ���ԭ�����£�
����1�� ������ġ�abcdeif��λ�а���Comma���С�Comma���п�������������������ҵ����������߽�
����2�� ��ghj��λ�ṩ�����������λ���䣨��101��010��
�����Թ���/R/��
����R��/R/�ֱ���K29.7�ַ���/K29.7/����ı����������ڿ������к�ʱ�Ӳ���������ʹ��
�������루/A/��
����A��/A/�ֱ���K27.7�ַ���/K27.7/����ı����������ڿ���������ʹ�ò����ڶ���4xͨ����
������ǣ�/M/��
����M��/M/�ֱ���K28.1�ַ���/K28.1/����ı����������ڿ�������2��Idle Sequence 2����ʹ�ò���������·�ṩ����10λ����߽�ͬ������Ϣ��ͬʱ��ǿ���֡��CS���λ�á�
����||K||��||R||��||A||��||M||��||I||
����||K||��||R||��||A||��||M||��||I||�ֱ������ͨ������µ������ַ��������������Ӧ���ַ�������ͬ��
����ʹ�ô���������
�����˽���ɴ����������ͷ��λ�����ڹ����˿ڼ�ͨ�ŵĿ��Ʒ��ź�ʹ��8B/10B������ͬһ�ź��д���ʱ�Ӻ�DCƽ�����ݵı��������뼼�����������ǿ����о���·�������˵�䷢�����ݵ�ʵ�ʹ��������ˡ�
3.1 �˿ڳ�ʼ������
�˿ڳ�ʼ����RapidIO������ʼ����ͬ��һ��ͨ�Ŷ˿ڵĹ��̡�������̰��������·����һ���Ƿ����һ����·������λͬ������������߽��Լ��ڶ˿���ͬʱ֧��1x��4xģʽ��1x/4x�˿ڣ�����£�������·�����Ƿ���֧��4x����ģʽ��ѡ��1x��4x����ģʽ�����ѡ��1xģʽ����ѡ��ͨ��0����ͨ��2��Ϊ��·����ͨ����
����״̬�������˳�ʼ�����̡�RapidIO�淶��ϸ��������״̬���Ľṹ��״̬��������������ȡ���ڶ˿ڽ�֧��1xģʽ��1x�˿ڣ�����ͬʱ֧��1x��4xģʽ��1x/4x�˿ڣ�������������¶���һ����״̬����һ��������״̬����ʹ�ö��״̬��ʹ������Ƹ�Ϊ���������Ԥ�ڵ�������1x�˿ڵij�ʼ�����̱�1x/4x�˿ڵij�ʼ�����̼�1x�˿ڵij�ʼ������ʹ1x/4x�˿ڳ�ʼ�����̵��Ӽ���
3.2 ��������
һ���˿ڳ�ʼ����ɣ��Ϳ��Կ�ʼ���Ľ������Ѿ�������һ��Э��������������RapidIO�˵�֮��İ�ͨ�š�ʹ�ÿ��Ʒ��Ź���ͨ����·�İ��������ɿ��Ʒ��Ŷ����ȷ�ϡ��������Ҳ����ͨ�����Ʒ���ͨ�š����Ʒ��Ż�����֧����������Э�顣
���Ʒ��ţ�
�������Ʒ������ɴ�����·���ӵĶ˿���ʹ�õ���Ϣ���֡����Ʒ���������·ά���������硢��ȷ�ϣ�����ʹ���ָ���
����ʱ���Ʒ�����һ��������8B/10B����(����)�ַ����硣�����ַ���ǿ��Ʒ��ŵĿ�ʼ�������ڿ��Ʒ��ŵ���λ֮ǰ��Ϊ��ͨ���ֶ�(�������)��8B/10B���룬�ڽ����Ʒ��Ŵ��ݵ�PCS�Ӳ�ǰ�����ڶ�����Ƶ������ַ�������Ʒ��š���Ϊ�̿��Ʒ��ŵij����ǹ̶���24λ�����Կ��Ʒ��Ų���Ҫβ���������������Ϳ��Ʒ��������һ�𣬳�Ϊ������Ʒ��š�
����ʹ�����������ַ��е�һ�ֶ�����Ʒ��š�������Ʒ��Ű���һ�������������ʹ��ר���ַ�PD(K28.3 )��������Ʒ��Ų����������������ʹ��ר���ַ�SC(K28.0)�����ʹ�������ַ���������ṩ��һ�����Ʒ������ݵġ�Ԥ����Early Warning�����źš�
�����κβ�������������Ŀ��Ʒ��Ŷ��ɱ�Ƕ�뵽���С�Ƕ��Ŀ��Ʒ��ſ��ܰ����κ��Ѷ����stype0����͡��ಥ�¼�����NOP��֮���stype1���롣���ܽ�stype1��Ϊ����ʼ�������������������ش�����������·������Ʒ���Ƕ�뵽���У���Ϊ���ǻ���ֹ����
��������·Ƕ����Ʒ��ŵķ�ʽ�ͳ̶Ȼ�Ӱ����·��ϵͳ�����ܡ����磬Ƕ��ಥ�¼����Ʒ����������ǵĴ�����ʱ��ͨ������������������ʱ�ӱ仯��С(ijЩ�ಥ�¼�Ӧ��������ҪǶ��ಥ�¼����Ʒ���)����һ���棬Ƕ�����еİ�ȷ�Ͽ��Ʒ��Ŷ����ǰ����Ǿ����ܶ�����������Ʒ�����ϵ����������˿����ڰ����͵���·��������������������ϣ���ġ�
����
�������� RapidIO���ڷ���ʱ�ɿ��Ʒ��Ž��ж��硣���ڰ������DZ仯�ģ�����ͬʱ��Ҫ����ʼ�Ͱ��������������ǰ��Ľ���(����ֹ)�Ŀ��Ʒ��Ÿ��ڰ�β��Ƕ��Ŀ��Ʒ��ŵĺ��档
�����������а�����Ŀ��Ʒ������£�
����1�� ����ʼ
����2�� ������
����3�� ����
����4�� ���ش�������
����5�� ������·����
�����ɰ���ʼ���Ʒ��ű�ǰ��Ŀ�ʼ��
���������������ַ�ʽ֮һ��ֹ��
����1�� �ð��������Ʒ��ű�ǰ�β��
����2�� �ð���ʼ���Ʒ��ű�ǰ�β������ʼ���Ʒ��ű���°��Ŀ�ʼ��
����3�� �ô��ش�����������������·������Ʒ���ȡ������
����ÿ��������Ҫһ����ʶ����Ψһ�ı�ʶ����ȷ�Ͽ��Ʒ��š��ñ�ʶ������RapidIO����ʽ�е�ackID�ֶΣ���RapidIO����������İ���˵��ackID�ֶεij�����5λ�������������ڴ������������1��32��δ��ɵĴ�ȷ�ϵ��������Ӧ������ֻ����ͬʱ�������31��δ��ɵĴ�ȷ�ϰ���
������λ������ackID �ij�ʼֵ�� 0b00000��ackID�ĺ���ֵ�����������(������˳�����ӣ��ﵽ�����ʱ���ص�0)������ָʾ���ķ��ʹ���ȷ�ϱ����ɿ��Ʒ�����ɡ�
��������RapidIO��·Э��ʹ���ش��Ӱ����ʹ����лָ���Ϊ֧�ְ��ش������Ͷ˿ڱ���ÿ��ͨ��������·����İ���һ��������ֱ���յ����ն˿ڷ����Ľ��հ��İ�ȷ�Ͽ��Ʒ��Ż���ֱ���˿��ж��ð��Ѿ������˲��ɻָ��Ĵ����������ȷ�Ͽ��Ʒ���ָʾ���ն˿����յ�������û�м�����ͬʱ�Ѿ����նԸð����д��������Ρ����˿��ܵĴ�������˿��ڽ��յ��İ������ȼ���û���㹻�Ŀ������뻺�����ռ䣬��˿�Ҳ���ܾܾ�����
�����������Ķ˵㴦������Ϊÿ��������һ�����ȼ��������ȼ������ڰ����������ֶ����ȼ�(PRIO)�в����ĸ����ܵ�ֵ: 0��1��2��3���������ȼ������ȼ�ֵ�����Ӷ����;������ȼ�Ϊ 0; ������ȼ�Ϊ3��ʹ�ð����ȼ���Ŀ���ж��, �����������������Ԥ����
3.3 ��������
��������������һ���������С�����·���跢�Ͱ�����Ʒ���ʱ����ÿ��������·Э��(LP- Serial)��·ͨ���������ط��Ϳ������С��������в��ܲ��뵽���С���Ϊ�˿ڳ�ʼ�����̵�һ����, ��ÿ��ͨ���ϴ��Ϳ������С����Ƕ˿ڳ�ʼ��Э������Ҫ�ġ�
����1x��������������/K/��/A/��/R/ (��������)���ɵ�α���������ɣ��ɲ���ģʽΪ1x�Ķ˿�ʹ�á�4x��������������llKll��llAll��llRll(��������)���ɵ�α���������ɣ��ɲ���ģʽΪ4x�Ķ˿�ʹ�á�Э��Կ������г���û��Ҫ�������п��������ⳤ�ȡ�
�������������ж������α���ѡ���¿������е�Ƶ����û����ɢ���ߡ��������С�����������в����ĵ�Ÿ���(EMI)��
�����������з�Ϊ��������1��Idle1 Sequence���Ϳ�������2��Idle2 Sequence����
������������1��Idle1 Sequence����
������������1��һ����A��K��R�����ַ���ɵ����У����������ڴ�����·�Ϸ���֮ǰ�����Ⱦ���8B/10B���������б��������Ӧ��10-bit��������/A/��/K/��/R/֮���������·�Ϸ��͡�
����������������1�Ƽ�ʹ������7�ı�ԭ����ʽ��������Ӧ��α������У����磺
X7+X6+1 �� X7+X3+1
������������7�ױ�ԭ����ʽ�����ӣ�������������������ʽ������һ����Ϊ��������1��α����������ɶ���ʽ����ͼ��һ��������������1α������еĿ�ͼ
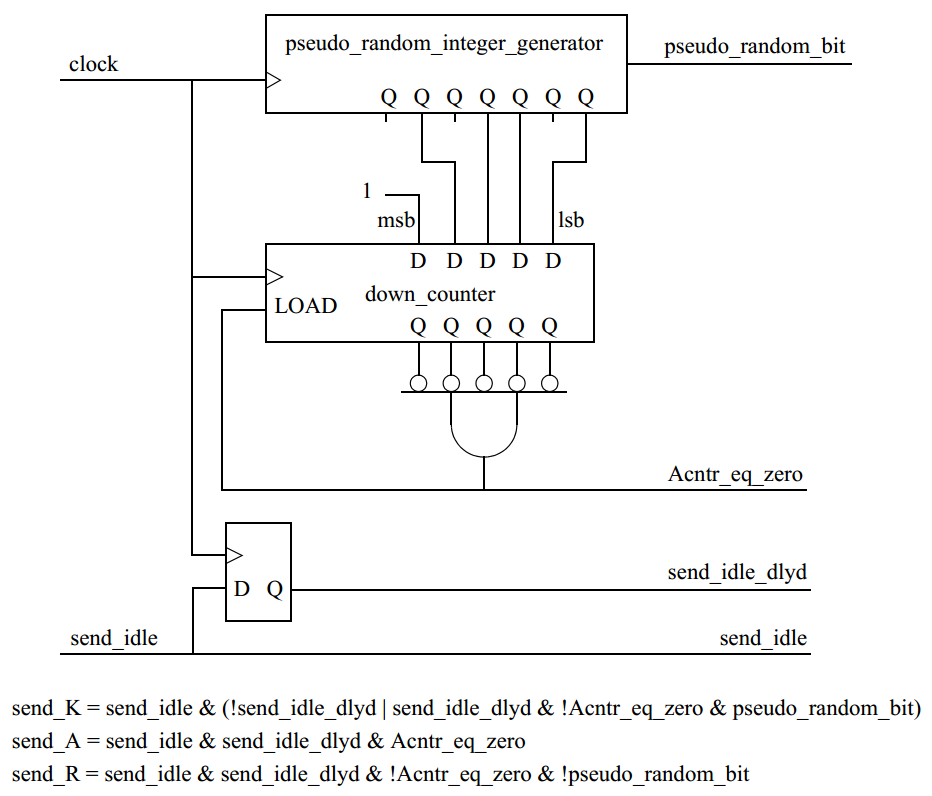
������������2��Idle2 Sequence����
������������2��һ���������ַ��������ַ�A��K��M��R��ɵ����С����������ڴ�����·�Ϸ���֮ǰ�����Ⱦ���8B/10B���������б��������Ӧ��10-bit��������/A/��/K/��/M/��/R/֮���������·�Ϸ��͡�
������������2�Ŀ���֡�Ľṹ������ʾ

������509-515���ַ������������8���ַ���CS�����Լ�32���ַ��ı���CS������������������α��������ַ���A��M�����ַ���CS�����ֶ�ָ���������״̬��CS = Command and Status�������ʼλ�ã������ṩ����·���ԣ���·���Ⱥ���·�ŵ���Ϣ��CS����˿��ṩ��һЩ״̬��Ϣ�Ϳ��Ʒ��Ͷ˿ڵ�Ԥ�������á�
�����������е�ѡ��
������������·ÿ��ͨ������������5.5Gbps����ʱֻ��ѡ���������2��IDLE2 Sequence������ÿͨ���������ʵ���5.5Gbpsʱ�ȿ���ѡ���������1��IDLE1 Sequence����Ҳ����ѡ���������2��IDLE2 Sequence���������ڶ˿ڳ�ʼ���Ĺ�����ѡ��������е��㷨��鿴�ο�����1��516ҳ��
�������ڿ������еIJ����Լ�������ϸ�Ľ�����鿴�ο�����1��503ҳ��517ҳ��
3.4 1x����RapidIO��·�ϵ�������
����1x����RapidIO�˿�ͨ��8B/10B������������ϲ㣨����ʹ���㣩���δ������ķֽ���Ʒ���������ַ����������Ʒ���������ɻ��ʱ���������н�������8B/10B���������б��벢���ͣ��Ա�֤�����շ���·����ͬ��״̬��
�������ڽ�����·��˵��10-bit��������������8B/10B���������н��룬Ȼ��ѽ���õ��Ŀ��Ʒ���������ս��յ�˳�����δ����ϲ㣨�����봫��㣩��
���������·�Ŀ�������Ϊ��������2�����Ʒ��źͰ������ַ��ڷ���֮ǰ��Ҫ���룬����֮ǰ��Ҫ���š�
������ͼ��ʾ�˶̿��Ʒ�����1x����RapidIO��·�ϵı���ͷ���˳��ʾ��ͼ
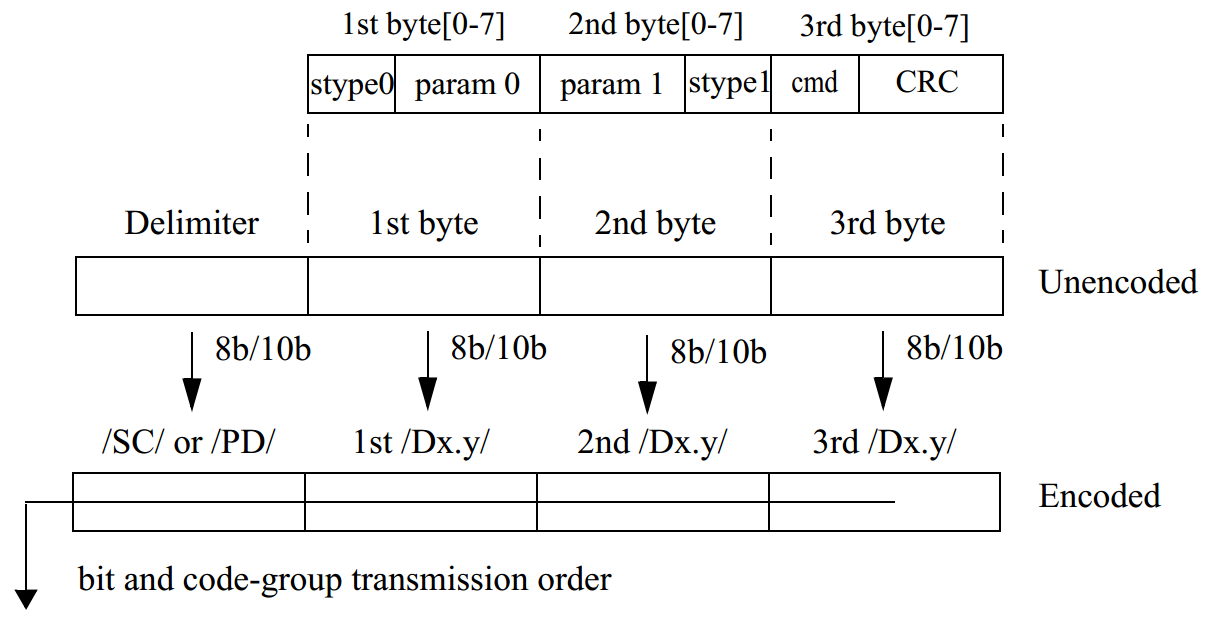
��ͼ��ʾ��RapidIO����1x����RapidIO��·�ϵı���ͷ���˳��ʾ��ͼ

������ͼ��ʾ��һ����1x������·�ϴ��Ϳ��Ʒ��š����Ϳ������е�ʵ�������͵ĵ�һ�������Ǵ������Ʒ��ſ�ʼ��/SC/, �������������24λ���Ʒ�����Ϣ���������顣�ÿ��Ʒ��ŵĹ���û����ʾ�����Ʒ��ź�������ĸ������ַ������ĸ������ַ�֮����һ���������ʼ��/PD/���顣����������������Ŀ��Ʒ�����Ϣ���������������Ϣ�������ʾRapidIO�������ڸ÷�����Ϣ֮������Ϊ28�ֽڡ���֮����һ�����������Ʒ���,������������Ʒ���֮������һ������ʼ���Ʒ��ź���һ�����ݰ����ڴ��ش����������Ʒ�����ֹ��ǰ,�ð��ܹ�����16�ֽ���Ϣ���ð��������������������Ʒ���, ���������Ʒ��ŷֱ�����������еĵ�8�������ֽں͵�12�������ֽ�֮����RapidIOЭ����,������������ʱ�̽����Ʒ��Ų��뵽ͨ���ŵ���, ����ȵ���������ȫ��ɼ��ɲ�����Ʒ��š��ڷ��ʹ��ش����������Ʒ���֮��, ��һ���������͵���·�ϡ��ð���ȷ����ɺ���·��Ϊ����״̬��
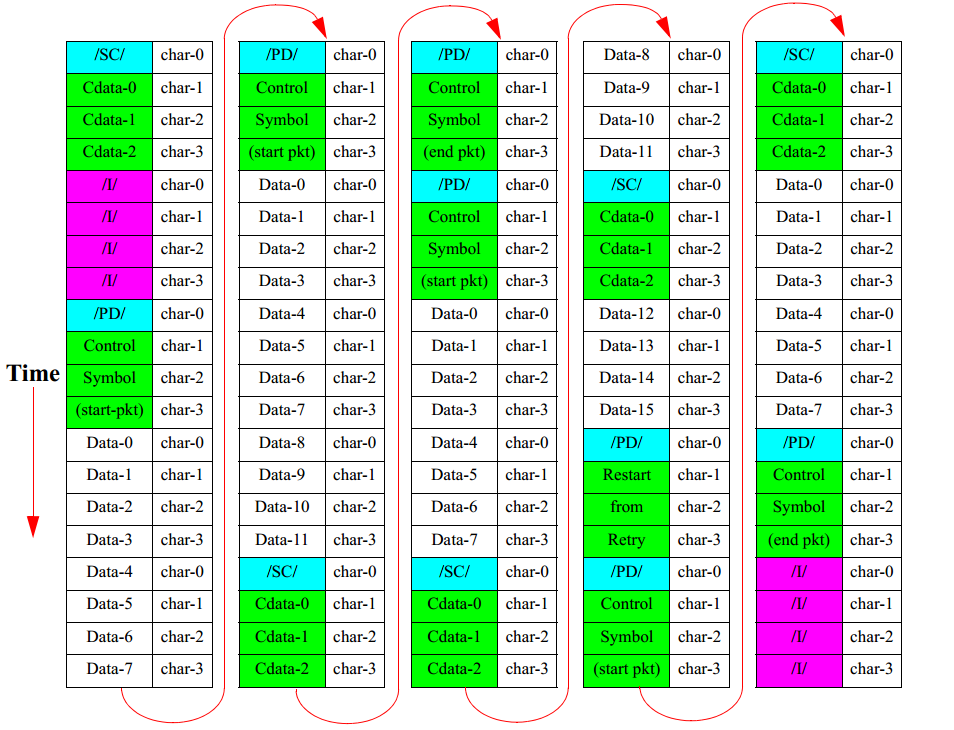
3.5 4x����RapidIO��·�ϵ�������
������4x����ģʽ�µĴ��ж˿���8B/10B����֮ǰ�����·�ʽ��������Ʒ��ź���ɰ����ַ����ֶε��ĸ�ͨ���ϡ�
�������Ͷ�����ƴ��Ž�����ͨ��0��ʼ�ֶε��ĸ�ͨ���ϡ�ÿ�����ĵ�һ���ַ�����Ʒ��ű��ŵ�ͨ��0,�ڶ����ַ����ŵ�ͨ��1 ,�������ַ����ŵ�ͨ��2,���ĸ��ַ����ŵ�ͨ��3��������ַ��ֱ��ŵ�ͨ��0,���ѭ����
�������ڿ��Ʒ��ŵij����ǹ̶���24λ����Ҫ����ij��ȱ�����32λ��������, �ֶκ���Ʒ��ŵ������ܱ��ŵ�ͨ��0�����а����γ����������������С��ڷֶκ�, 4���ַ�����ÿһ�������������ؽ���8B/10B����ͷ��͡�
�����ڽ��շ���ÿ��ͨ�����н��롣�����, �ַ���������4��ͨ������Ϊ4x�������е�һ���ַ��͵�llAll�����ṩִ�ж����������Ϣ���ڶ���֮�����б��ϲ�Ϊ�������ַ���, Ȼ���ݵ��ϲ� ��
����ͨ���������������ͨ�����ƫ��,�����ںϲ�(destriping)����յ����ַ������ַ���˳�����ڷֶκͷ���ǰ�ַ���˳����ͬ�� ����||A||����֮����С�ķ�llAll��������Ϊ16, ���Կ�����ȷ���������ͨ��ƫ������һ��ͨ���ϴ���7�������ʱ�� ����ͼ��ʾ��һ����4x��·�ϴ��Ϳ������С����Ͷ�����Ʒ��ŵ�ʵ���� ��ʵ��ʹ�õİ�������1x��·��ʵ����ͬ��
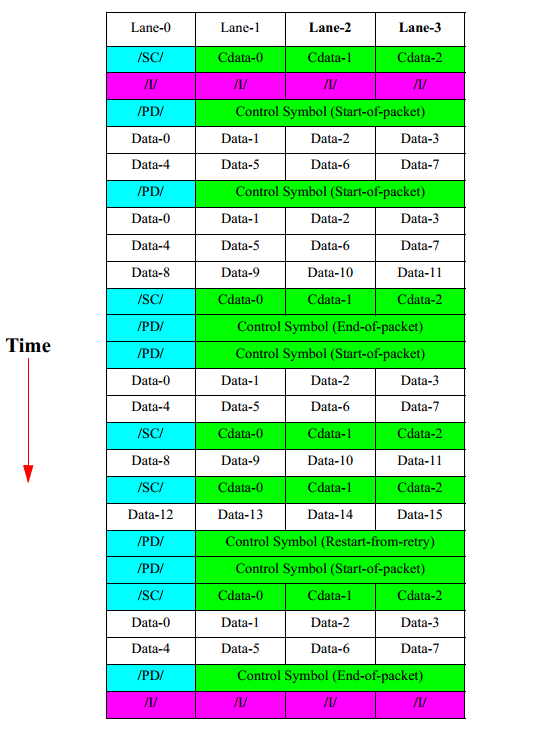
�ġ��ܽ�
RapidIO�����������8B/10B�����ԭ���������������ص����ݵ��˽�����ϣ�������ϸ���������Ķ��ο�����1�ĵ�485ҳ��560ҳ��Ϊ�˱��ڴ���Ժ�IJ��ģ�����ѿ��Ʒ�����K����صĶ���ȫ���е�һ��
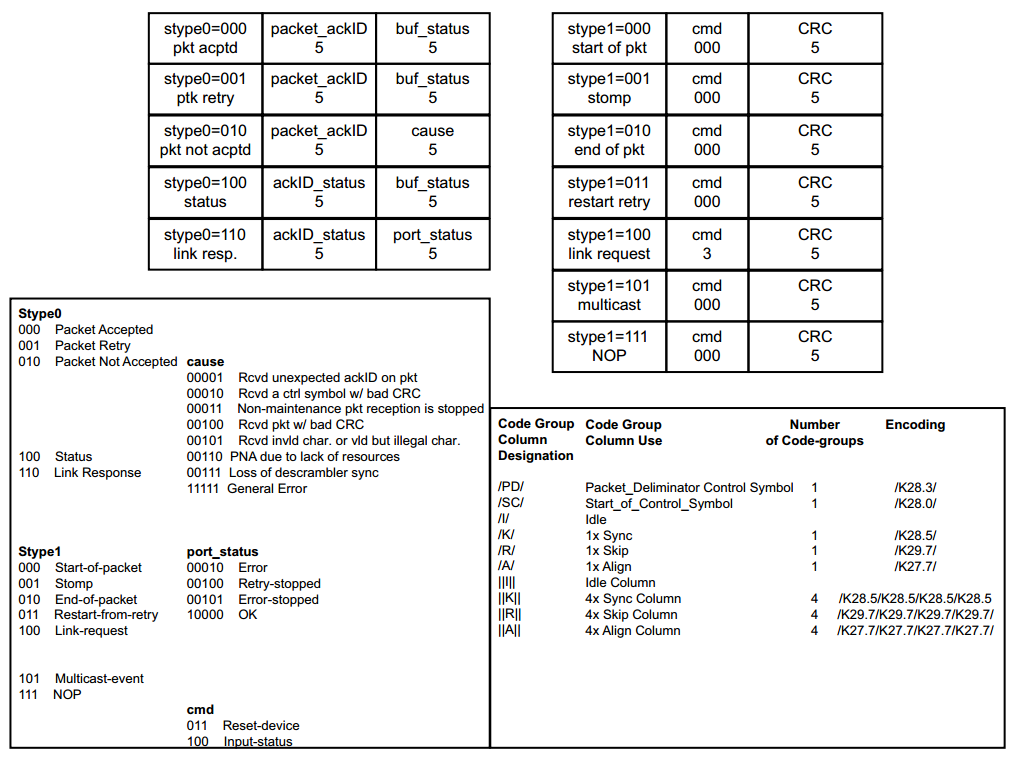
ע�⣺��ͼ�г����Ƕ̿��Ʒ��ŵĶ��塣�����Ʒ����ܳ���Ϊ48λ���̿��Ʒ��ŵ��ܳ���Ϊ24λ��
���ˣ�����RapidIO���۲���ȫ��������ϣ���������дXilinx RapidIO�˵�������ݡ�
�塢�ο�����
����1��RapidIO? Interconnect Specification���������� https://pan.baidu.com/s/1ek-3AAhetLAcxTuOE2IyMg
����2��RapidIOǶ��ʽϵͳ���������ӹ�ҵ������
����3��Xilinx��pg007_srio_gen2�����ص�ַ https://china.xilinx.com/support/documentation/ip_documentation/srio_gen2/v4_0/pg007_srio_gen2.pdf
ת�ص�ַ��https://www.cnblogs.com/liujinggang/p/10005431.html