2、 使用Hadoop命令行执行jar包详解(生成jar、将文件上传到dfs、执行命令、下载dfs文件至本地)
3、 Hadoop完全分布式集群安装及配置(基于虚拟机)
4、 Eclipse中使用Hadoop集群模式开发配置及简单程序示例(Windows下)
5、 Zookeeper3.4.9、Hbase1.3.1、Pig0.16.0安装及配置(基于Hadoop2.7.3集群)
6、 mysql5.7.18安装、Hive2.1.1安装和配置(基于Hadoop2.7.3集群)
7、 Sqoop-1.4.6安装配置及Mysql->HDFS->Hive数据导入(基于Hadoop2.7.3)
8、 Hadoop完全分布式在实际中优化方案
9、 Hive:使用beeline连接和在eclispe中连接
10、 Scala-2.12.2和Spark-2.1.0安装配置(基于Hadoop2.7.3集群)
11、 Win下使用Eclipse开发scala程序配置(基于Hadoop2.7.3集群)
12、 win下Eclipse远程连接Hbase的配置及程序示例(create、insert、get、delete)
本篇博客主要介绍“Zookeeper3.4.9、Hbase1.3.1、Pig0.16.0安装及配置(基于Hadoop2.7.3集群)”。
一、Hadoop集群环境
安装配置详见:Hadoop完全分布式集群安装及配置(基于虚拟机)
Ubuntu镜像版本: ubuntu-16.04.2-server-amd64.iso
JDK版本: jdk1.8
hadoop版本: hadoop-2.7.3
启动集群,进行下面Zookeeper3.4.9、Hbase1.3.1安装及配置。
Hadoop版本对应可用的Hbase版本参见: http://hbase.apache.org/book.html#configuration
已安装的Hadoop集群中主机名和对应的IP如下:
| 主机名 | IP |
|---|---|
| hadoop2m | 192.168.163.131 |
| hadoop2_s1 | 192.168.163.132 |
| hadoop2_s2 | 192.168.163.133 |
二、Zookeeper3.4.9安装配置
1、下载
下载地址: http://mirror.bit.edu.cn/apache/zookeeper/
下载版本: zookeeper-3.4.9.tar.gz
压缩包存放目录: /home/lina/Software/Hadoop/zookeeper-3.4.9.tar.gz
强调:以下2-5步骤只需要在其中一个节点操作即可(我是在主节点上操作的),然后第6步我们会将zookeeper安装和配置文件整个复制到剩下的节点中。
2、解压
将目录切换到压缩包存放的目录,我们这里将其解压到(安装到)/opt/Hadoop/文件夹下,命令如下:
cd /home/lina/Software/Hadoop
tar -zxvf zookeeper-3.4.9.tar.gz -C /opt/Hadoop解压之后的目录文件为/opt/Hadoop/zookeeper-3.4.9
3、配置环境变量
因为之前在安装Hadoop时已经配置过jdk和hadoop的环境变量,所以这里只需要将zookeeper的环境变量添加即可,添加内容在下图使用红框圈起来了(没圈的地方是之前已经配置过的环境变量,这里不需要变动),使用命令sudo vi ~/.bashrc打开配置文件,配置如下:
export ZOOKEEPER_INSTALL=/opt/Hadoop/zookeeper-3.4.9
export PATH=.:$ZOOKEEPER_INSTALL/bin如图:

即:
(1)添加了ZOOKEEPER_INSTALL这个变量,其对应的值是zookeeper的安装路径(解压路径)
(2)将zookeeper下的bin目录添加至PATH中。
4、配置zoo.cfg
配置文件存放在$ZOOKEEPER_INSTALL$/conf下,即/opt/Hadoop/zookeeper-3.4.9/conf下,因为只有zoo_sample.cfg,因此将其复制一份并命名为zoo.cfg,使用下面的命令:
cd /opt/Hadoop/zookeeper-3.4.9/conf
cp zoo_sample.cfg zoo.cfg使用sudo vi zoo.cfg将此文件打开,改变dataDir,并添加通信设置,如下,更改和添加的内容已经使用方框圈起来:
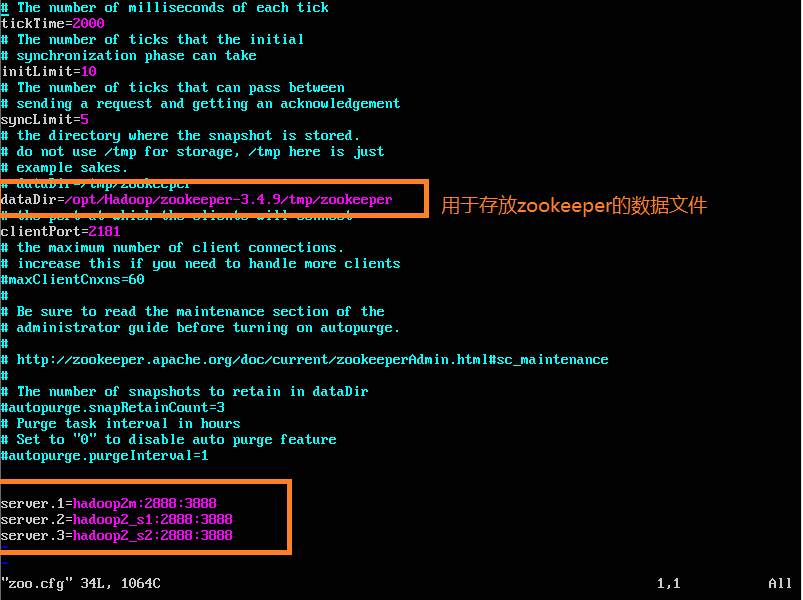
对于下面一个框起来的内容是为了通信,格式如下:
server.X=A:B:C 其中X是一个数字, 表示这是第几号server. A是该server所在的IP地址. B配置该server和集群中的leader交换消息所使用的端口. C配置选举leader时所使用的端口. 若配置的是伪集群模式, 各个server的B, C参数必须不同.若配置的是完全分布模式,因为各server的ip,端口本身不一致,因此各server的B,C可以设置的完全一致。我的配置如上图。hadoop2m,hadoop2_s1,hadoop2_s2是3个server的主机名。
5、建立zookeeper数据文件夹
因为在上一步中设置了存放data的目录,这里需要手动建立目录:
Step1:在上面提到的地址/opt/Hadoop/zookeeper-3.4.9中建立一个tmp文件夹,在tmp下建一个zookeeper文件夹。
Step2:在zookeeper中建立一个myid的文件,添加内容“1”,注意:myid中需要写入一个数字, 该数字表示这是第几号server. 该数字必须和zoo.cfg文件中的server.X中的X一一对应,即对于上图的设置,hadoop2m中的myid添加数字“1”,hadoop2_s1中的myid添加数字“2”,hadoop2_s2中的myid添加数字“3”。
命令如下:
cd /opt/Hadoop/zookeeper-3.4.9
sudo mkdir tmp
cd tmp
sudo mkdir zookeeper
cd zookeeper
sudo vi myid
接下来,写入数字1,保存退出即可
强调:第6步骤只需要另外两个节点hadoop_s1和hadoop_s2上进行操作
6、使用scp将文件分发到其他节点并更改相应配置
(1)使用scp将文件(这里指zookeeper的安装及配置文件)/opt/Hadoop/zookeeper-3.4.9复制到另外两个节点hadoop_s1和hadoop_s2,命令如下:
scp -r /opt/Hadoop/zookeeper-3.4.9 hadoop_s1:/opt/Hadoop
scp -r /opt/Hadoop/zookeeper-3.4.9 hadoop_s2:/opt/Hadoop执行完上述命令之后,你会发现hadoop_s1和hadoop_s2的/opt/Hadoop下面了zookeeper-3.4.9文件夹。
(2)更改hadoop_s1和hadoop_s2的myid文件,将其myid文件分别改为2,3
(3)设置hadoop_s1和hadoop_s2的环境变量,设置方法同第三步3、配置环境变量
强调:第7步骤需要在全部节点上进行操作
7、服务的启动与验证
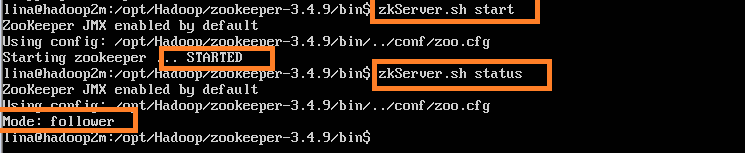
(1)在全部节点上执行下面的操作开启服务,在相应安装目录的bin目录下:
cd /opt/Hadoop/zookeeper-3.4.9/bin
zkServer.sh start //启动进程
zkServer.sh status //查看进程及其扮演的角色注意:必须所有节点进程全部启动完毕之后,才可以使用zkServer.sh status 命令查询状态。
我的其中一个节点的执行结果如下:
(2)若想要停止此进程,进入/opt/Hadoop/zookeeper-3.4.9/bin目录下,执行zkServer.sh stop命令即可。
三、Hbase1.3.1安装配置
1、下载
下载地址:http://mirror.bit.edu.cn/apache/hbase/
下载版本: hbase-1.3.1-bin.tar.gz
压缩包存放目录: /home/lina/Software/Hadoop/hbase-1.3.1.tar.gz
强调:以下2-5步骤只需要在其中一个节点操作即可(我是在主节点上操作的),然后第6步我们会将hbase安装和配置文件整个复制到剩下的节点中。
2、解压
将目录切换到压缩包存放的目录,我们这里将其解压到(安装到)/opt/Hadoop/文件夹下,命令如下:
cd /home/lina/Software/Hadoop
tar -zxvf hbase-1.3.1-bin.tar.gz -C /opt/Hadoop解压之后的目录文件为/opt/Hadoop/hbase-1.3.1
3、配置环境变量
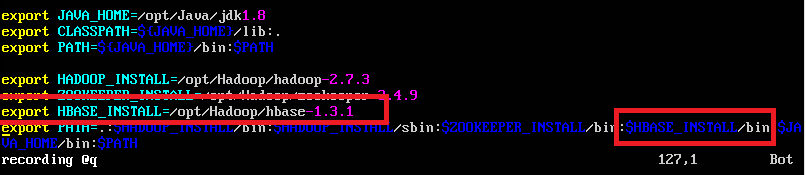
因为之前在安装Hadoop时已经配置过jdk,hadoop和zookeeper的环境变量,所以这里只需要将hbase的环境变量添加即可,添加内容在下图使用红框圈起来了(没圈的地方是之前已经配置过的环境变量,这里不需要变动),使用命令sudo vi ~/.bashrc打开配置文件,配置如下:
export HBASE_INSTALL=/opt/Hadoop/hbase-1.3.1
export PATH=.:$HBASE_INSTALL/bin如图:
即:
(1)添加了HBASE_INSTALL这个变量,其对应的值是hbase的安装路径(解压路径)
(2)将hbase下的bin目录添加至PATH中。
4、配置hbase-site.xml
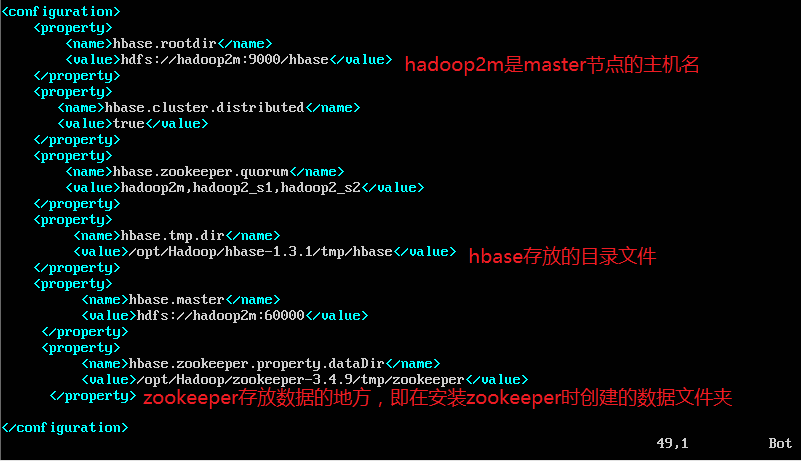
配置文件存放在$HBASE_INSTALL$/conf下,即/opt/Hadoop/hbase-1.3.1/conf下,修改hbase-site.xml,使用下面的命令打开文件:
cd /opt/Hadoop/hbase-1.3.1/conf
sudo vi hbase-site.xml添加如下内容:
5、建立hbase数据文件夹
因为在上一步中设置了hbase.tmp.dir的目录,这里需要手动建立目录:在上面提到的地址/opt/Hadoop/hbase-1.3.1中建立一个tmp文件夹,在tmp下建一个hbase文件夹。
命令如下:
cd /opt/Hadoop/hbase-1.3.1
sudo mkdir tmp
cd tmp
sudo mkdir hbase
强调:第6步骤只需要另外两个节点hadoop_s1和hadoop_s2上进行操作
6、使用scp将文件分发到其他节点并更改相应配置
(1)使用scp将文件(这里指hbase的安装及配置文件)/opt/Hadoop/hbase-1.3.1复制到另外两个节点hadoop_s1和hadoop_s2,命令如下:
scp -r /opt/Hadoop/hbase-1.3.1 hadoop_s1:/opt/Hadoop
scp -r /opt/Hadoop/hbase-1.3.1 hadoop_s2:/opt/Hadoop执行完上述命令之后,你会发现hadoop_s1和hadoop_s2的/opt/Hadoop下面了hbase-1.3.1文件夹。
(2)设置hadoop_s1和hadoop_s2的环境变量,设置方法同第三步3、配置环境变量
强调:第7步骤需要在主节点上进行操作
7、服务的启动与验证
(1)在主节点上执行下面的操作开启服务,在根目录下(需要保证hdfs和zookeeper服务已开启):
start-hbase.sh使用jps查看已开启的服务,主节点的执行结果如下:

(2)可通过访问http://192.168.163.131:16010/master-status在web端访问,如下图:
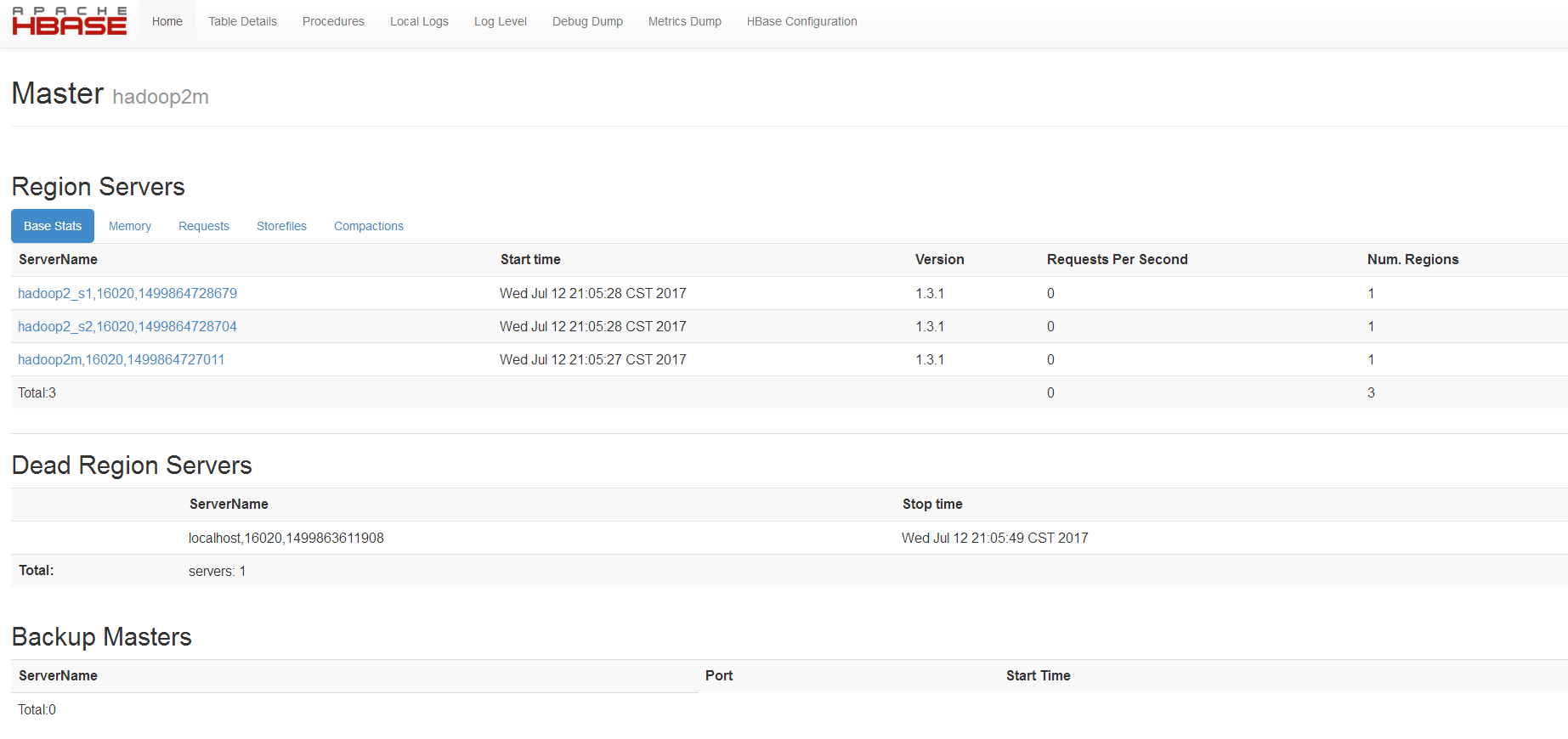
(3)若想要停止此进程,在根目录下,执行stop-hbase.sh命令即可。
四、Pig0.16.0安装配置
1、下载
下载地址:https://mirrors.tuna.tsinghua.edu.cn/apache/pig/
下载版本: pig-0.16.0.tar.gz
压缩包存放目录: /home/lina/Software/Hadoop/pig-0.16.0.tar.gz
强调:所有步骤只需要在其中主节点操作即可
2、解压
将目录切换到压缩包存放的目录,我们这里将其解压到(安装到)/opt/Hadoop/文件夹下,命令如下:
cd /home/lina/Software/Hadoop
tar -zxvf pig-0.16.0.tar.gz -C /opt/Hadoop解压之后的目录文件为/opt/Hadoop/pig-0.16.0
3、配置环境变量
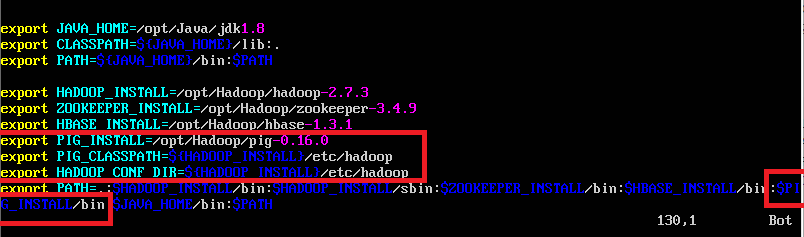
因为之前在安装Hadoop时已经配置过jdk,hadoop,zookeeper和hbase的环境变量,所以这里只需要将pig的环境变量添加即可,添加内容在下图使用红框圈起来了(没圈的地方是之前已经配置过的环境变量,这里不需要变动),使用命令sudo vi ~/.bashrc打开配置文件,配置如下:
export PIG_INSTALL=/opt/Hadoop/pig-0.16.0
export PIG_CLASSPATH=${HADOOP_INSTALL}/etc/hadoop
export HADOOP_CONF_DIR=${HADOOP_INSTALL}/etc/hadoop
export PATH=.:$PIG_INSTALL/bin如图:
即:
(1)添加了PIG_INSTALL,PIG_CLASSPATH和HADOOP_CONF_DIR这三个变量。PIG_INSTALL对应的值时pig文件的解压目录,PIG_CLASSPATH和HADOOP_CONF_DIR对应的值是Hadoop的安装目录中hadoop的配置文件所在目录。
(2)将pig下的bin目录添加至PATH中。
4、服务的启动与验证
(1)在根目录下(若未配置全局环境变量,则需要进入pig安装目录的bin文件夹下),执行pig命令,若出现grunt >的提示符说明安装成功,如图:
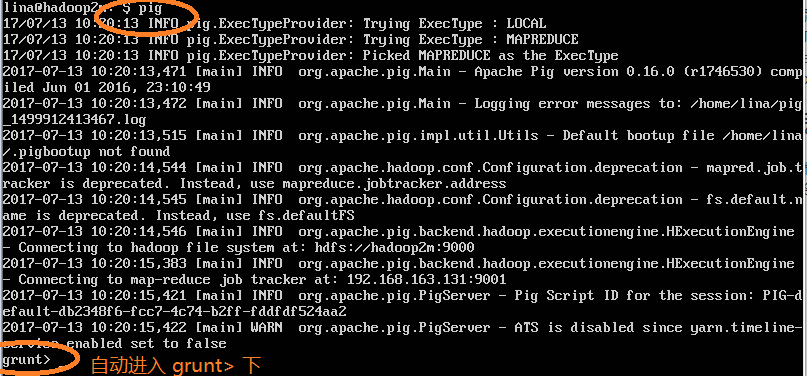
注:示例可参见《Hadoop权威指南》的11.2节的示例。
说明:在使用grunt shell进行LOAD操作时,若pig是本地模式,则可以加载本地文件夹,若pig是分布式模式,则要先将需要加载的文件上传至HDFS。
*************************
2017-08-22更新:
推荐一个zookeeper讲的比较详细的系列网站:http://www.cnblogs.com/sunddenly/category/620563.html
*************************
**附:**Hadoop入门基础及简单实例代码:https://github.com/Nana0606/Hadoop_Introduction