论文链接:Learning from Imbalanced Data
一、基本概念
1、类间不平衡 VS. 类内不平衡
类间不平衡:不同类别之间的数据量相差较大。
类内不平衡:某一个类分布成多个小聚类,每个小聚类数据量相差较大。
如下图:
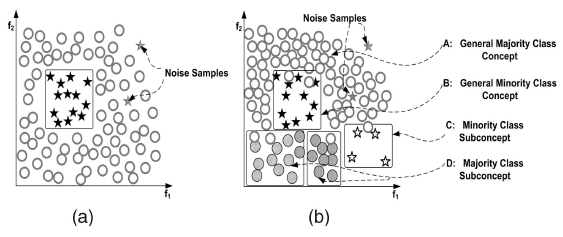
图(a)中圆形和五角星代表2个不同的类,他们的数目量相差较大,因此属于类间不平衡。
图(b)中:A代表圆形类中数量较大的圆形集合,D代表圆形类中数量较小的圆形集合。B代表五角星中数量较大的五角星集合,C代表五角星中数量较小的五角星集合。因此在这个图中,圆形和五角星分别存在类内不平衡,而且圆形和五角星存在类间不平衡。
1、内在不平衡 VS. 外在不平衡
内在不平衡:由于数据本身导致的数据不平衡,即数据本身存在正负样例差。
外在不平衡:除了数据本身之外,因为一些外界元素导致数据不平衡,如:时间、存储。举例:我们需要获取一段时间的持续的数据流,但是在这个时间段内传输出现中断问题,导致中断这个时间的数据缺失。
1、相对不平衡 VS. 绝对不平衡
绝对不平衡:由于正负样例之比较大,例如:正例10000个,负例100个,正负例之比为100:1,这种情况叫做相对不平衡。
相对不平衡:虽然正负样例之比较大,例如:正负样例之比为100:1,但是负样例本身数目很大,如2000个,这种情况叫做相对不平衡。
上图(a)和(b)都存在相对不平衡。
二、存在问题
1、单一的评价指标已经不能满足实际需求,因此需要提供更合适的评估指标,如ROC曲线等。
2、在实际应用中,数据的相对不平衡很常见,数据复杂度会增加训练难度,数据复杂性和数据不平衡互相影响。
3、数据重叠和数据代表性不足问题。如上图中(b)的C集合存在数据重叠问题。
4、样本数目较少。现阶段,比较常见的是数据维度高但是样本数目少,这样便很难使用算法来预测,因为很难从少量的数据中找到规则,目前针对这个问题的处理也有一些方法,如:主成分分析(PCA)。
三、解决方案
一开始使用决策树来解决这个问题,但是由于相对不平衡、绝对不平衡、类间不平衡和高维度的问题,使得决策树性能很差,因此,下面的一些方法被提出。
1、取样方法
取样方法:将不平衡数据通过某些方法变成平衡数据。
(1)随机过采样和欠采样
随机过采样(Random Oversampling):向minority中添加数据,可通过复制minority数据等,使得minority和majority数目相等。 ―-添加重复数据,导致数据过拟合(overfit)
随机欠采样(Random Undersampling):从majority中减掉数据,使得minority和majority数目相等。 ―-可能会丢失一些重要的数据。
(2)Informed Undersampling
Informed Undersampling主要有3种算法:EasyEnsemble、BalanceCascade、K-nearest neighbour(KNN)和one-sided selection(OSS),主要目的是克服传统随机欠采样导致的数据丢失问题。
EasyEnsemble:多次欠采样(放回采样)产生多个不同的训练集,进而训练多个不同的分类器,通过组合多个分类器的结果得到最终的结果。―-EasyEnsemble是非监督学习算法
BalanceCascade:先通过一次欠采样产生训练集,训练一个分类器,对于那些分类正确的majority样本不放回,然后对这个更小的majority样本下采样产生训练集,训练第二个分类器,以此类推,最终组合所有分类器的结果得到最终结果。 ―-BalanceCascade是监督学习算法
KNN:使用K近邻的方法挑选出一些K个样本,至于什么算是邻近的样本,每个算法有不同的定义。
(3)Synthetic Sampling with Data Generation
synthetic minority oversampling technique(SMOTE)算法,算法在minority中,基于特征空间相似度,人工创造一些数据。如下图是SMOTE的过程:
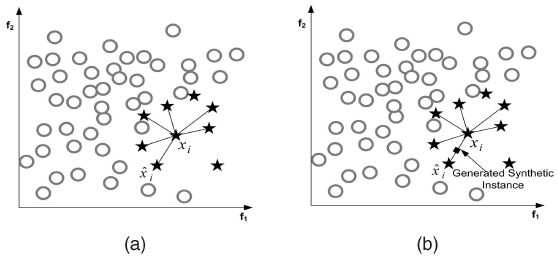
图(a)表示对于这个不平衡数据,找出了x_i的K近邻(K=6),根据某个特定的公式,可以将需要创造的数据定位下来,如图(b)中的菱形即表示添加的数据。
但是,SMOTE容易出现过泛化和高方差的问题,而且,容易制造出重叠的数据。
(4)Adaptive Synthetic Sampling
为了克服SMOTE的缺点,Adaptive Synthetic Sampling方法被提出,主要包括:Borderline-SMOTE和Adaptive Synthetic Sampling(ADA-SYN)算法。
Borderline-SMOTE:对靠近边界的minority样本创造新数据。其与SMOTE的不同是:SMOTE是对每一个minority样本产生综合新样本,而Borderline-SMOTE仅对靠近边界的minority样本创造新数据。如下图,只对A中的部分数据进行操作:
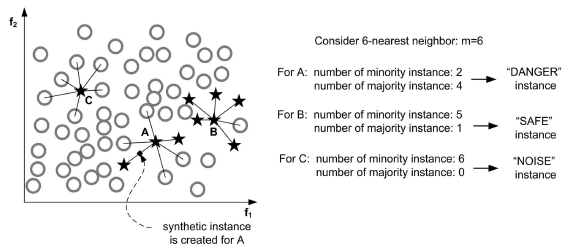
ADA-SYN:根据majority和minority的密度分布,动态改变权重,决定要generate多少minority的新数据。
(5)Sampling with Data Cleaning Techniques
Tomek links用于去除重叠数据,其主要思想是:找出最近距离的2个样本(这2个样本属于不同的类),然后将这2个样本都去除,直到某一样本周围的近邻都是属于同一类。如下图:

图(a)表示原始数据,在原始数据中有数据重叠的现象;图(b)表示SMOTE之后的数据,比(a)中新添加了一些数据;图(a)表示Tomek links被找出;图(d)是删除Tomek links后的数据,可以看出,不同的聚类可以比较明显的分辨出。
(6)Cluster-based Sampling Method
基于聚类的采样算法(cluster-based sampling method,CBO)用来解决类内和类间数据的不平衡问题。其利用K-means技术,如下图,可以很好地解释CBO的原理:
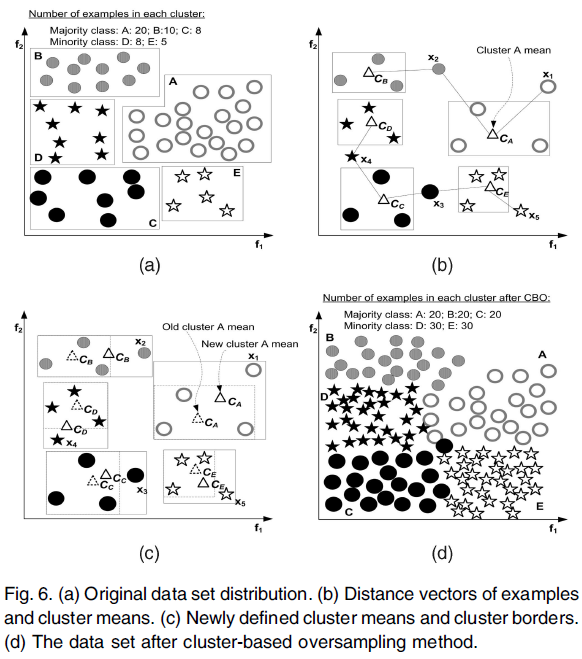
图(a)表示原始数据;图(b)中C_A,…,C_E表示初始的聚类中心;图(c)中新的C_A,…,C_E表示更新过的聚类中心(根据欧氏距离);图(d)中,基于图(c)我们知道最大数目的聚类是A,有20个样本,有圆形有3个聚类,所以圆形样本共20*3=60个,因此五角星每个聚类的样本数为60/2=30个。从图(d)最后的结果可以看出,相比较于原始数据,图(d)能更好地展现出少数类的分布。
(7)Integration of Sampling and Boosting
SMOTEBoost:基于SMOTE和Adaboost.M2的算法,其在boosting的每次迭代中都引入了SMOTE的方法,因此生成的每个分类器都集中于minority类,因为最后集成而得的分类器性能较好。
DataBoost-IM:其将数据生成技术和Adaboost.M1结合,在没有牺牲majority类准确度的情况下,提高minority的预测率。DataBoost-IM根据类间difficult-to-learn比率去生成综合样本。这种方法在解决强不平衡数据方面有很好的性能,但是可能依赖于较适合的数据生成方法。
2、代价敏感方法
采样方法主要考虑正负例的分布,而代价敏感方法主要考虑误分类样本的代价,通过代价矩阵来度量。
(1)代价矩阵
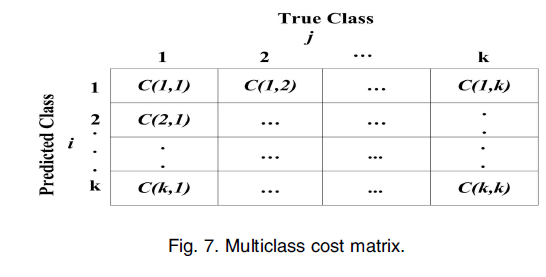
如上图:C(i, j)表示j类的样本被误分类为i类的代价。
在二元分类中,C(Min, Maj)表示Majority类的样本被误分类到Minority的代价,C(Maj, Min)表示Minority类的样本被误分类到Majority类的代价,因此C(Maj, Min)>C(Min, Maj)。
最终,判断的标准是使得所有样本的代价和尽可能小。(若被正确分类,则代价为0)。
(2)Cost-Sensitive Dataspace Weighting with Adaptive Boosting
3个代码敏感的Boosting函数,AdaC1、AdaC2、AdaC3。
AdaBoost.M1的主要思想是迭代更新训练集的分布。有几种不同的算法,它们的区别是将一个参数变量设置在指数外面、指数里面等。
(3)Cost-Sensitive Decision Trees
代价敏感的决策树应用主要有三种形式:(i)代价敏感调整可以用于决策阈值,使用ROC刻画性能取值范围,ROC曲线的特征点用作最后的阈值。(ii)对于每个节点的拆分标准,可以作为代价敏感的考虑因素。(iii)可以在决策树上应用代价敏感的剪枝。在不平衡数据,直接移除掉概率低于某一特定阈值的节点,会发现移除的数据大多都是minority的数据,因此,应将重点放在概率估计上,使得剪掉的是positive的数据。
Cost-Sensitive Neural Networks
代价敏感性在神经网络上的应用主要有4个方面:(i)代价敏感变更可以应用到概率评估上(ii)神经网络的输出也可以是代价敏感的(iii)代价敏感变更适用于学习参数(iv)最小误差函数可以用来预期代价。
3、基于核的算法和不平衡数据的积极学习算法
(1)基于核函数的采样算法:这里主要讲GSVM-RU(Granular Support Vector Machines-Repetitive Undersampling)算法,在此之前,先看GSVM算法的思想:(i)通过观察本地子集重要性和全局关联的trade-off分析内部数据的分布。(ii)通过使用平行计算提高计算效率。
GSVM-RU算法通过在欠采样过程中迭代学习步骤,充分利用了GSVM。因为在不平衡数据中,minority的数据认为是positive的,而线性SVM通过postive的sample和一些其他的sample训练。SVM将negative的sample标记为支持向量(因此叫做NLSVs),为了使训练集更小,这些negative的数据被移除。基于这个变小了的数据集,一个新的线性SVM和NLSV产生,并且NLSV形成的negative被移除,如此循环,得到多个negative的granular,最后,考虑全局关联的聚集操作被用来从这些迭代的negative granular中选择特定的样本集,将这些负样本和正样本组成训练集训练SVM模型。这样,GSVM-RU模型使用SVM去欠采样,形成多个信息颗粒,这些granular最后组合在一起训练SVM。
(2)有一些已有的对解决不平衡数据的基于核函数的算法的成果,和积极学习算法进行了论述。
4、关于不平衡学习的其他算法
一些文章概述。
四、不平衡数据评估指标
(1)单一评估指标、ROC曲线和PR曲线见机器学习:准确率(Precision)、召回率(Recall)、F值(F-Measure)、ROC曲线、PR曲线
(2)除此之外,Cost Function也可以作为一个指标。
(3)对于多分类,可以使用n个ROC曲线,即将其中一类当做正例,其余类当做负例。
参考文章:
easy ensemble 算法和balance cascade算法
如何解决机器学习中数据不平衡问题