写在前面
网上有很多写布隆过滤器的博客,但是大部分都是只关注一个点,不能非常好的从原理到应用理解,所以这里对布隆过滤器进行了整理。很多思想和例子都来自网上的的一些博客,非常感谢这些可爱哒人儿的付出,这里会尽量整理的比较详细,规整,有头有尾。
一、引例
在提到实现去重功能时,大部分人都会直接选择HashSet,HashSet可以起到去重的效果,并且其时间复杂度为 O ( 1 ) O(1) O(1),但是其存在的最大问题是内存占用比较大。所以我们可以选择使用布隆过滤器。
1、引例1
我们在爬取网页信息时,如果不进行任何设置进行网页信息的爬取,则可能爬取到相同url的内容,因此我们需要去重,可以使用HashSet,但是如果url数量太多,使用HashSet需要占据大量的内存,因此我们可以使用布隆过滤器。
2、引例2
我们在使用新闻网页看新闻时,它会给我们不停的推荐新的内容,但是在每次推荐时都需要进行去重处理,去掉那些用户已经看过的内容,否则就失去了推荐的意义。那么新闻网页是如何完成去重操作的呢?
一种方法是直接进行筛选,也就是记录下用户已经访问过的新闻,每次推荐保证推荐的新闻没有被访问过,但是这种操作下,我们需要记录已经访问的新闻,而且在推荐时也要判断是否新闻已被看过,很多用户的情况下,这需要强大的内存消耗及性能要求。(若将已看过的新闻存储在内存中,则需要消耗大量的内存;若存在的数据库中,则需要频繁的数据库的exist操作;对于前端的一些缓存系统,可能判断机制是若页面在本地,则直接返回本地查询的结果,否则从后端读取,这样就造成了频繁读取缓存系统,使后端压力变大)
在这种情况下,我们可以使用布隆过滤器,判断当前新闻是否已被访问。
二、布隆过滤器功能
- 用于解决去重问题
- 起到去重的同时,空间上能节省90%以上
- 会有很小的误判率(False positive),即BloomFilter判断为不存在的一定不存在,但是其判定为存在也可能不存在(请参见原理部分,更容易理解)
三、Bloom Filter思想
1、基本思想
若想判断一个元素是不是在一个集合里,一般想到的是将所有元素保存起来,然后通过比较确定。链表、树等等数据结构都是这种思路。但是随着集合中元素的增加,我们需要的存储空间越来越大,检索速度也越来越慢。我们可以使用一种叫作散列表(又叫哈希表,Hash table)的数据结构。它可以通过一个Hash函数将一个元素映射成一个位阵列(Bit Array)中的一个点。这样一来,我们只要看看这个点是不是 1 就知道可以集合中有没有它了。这就是布隆过滤器的基本思想。
2、举例说明
布隆过滤器是一个bit向量或者说是bit数组,假设我们的Bloom Filter是一个8位的bit向量,初始元素为0,假设有3个哈希函数,则其结果示意图如下:
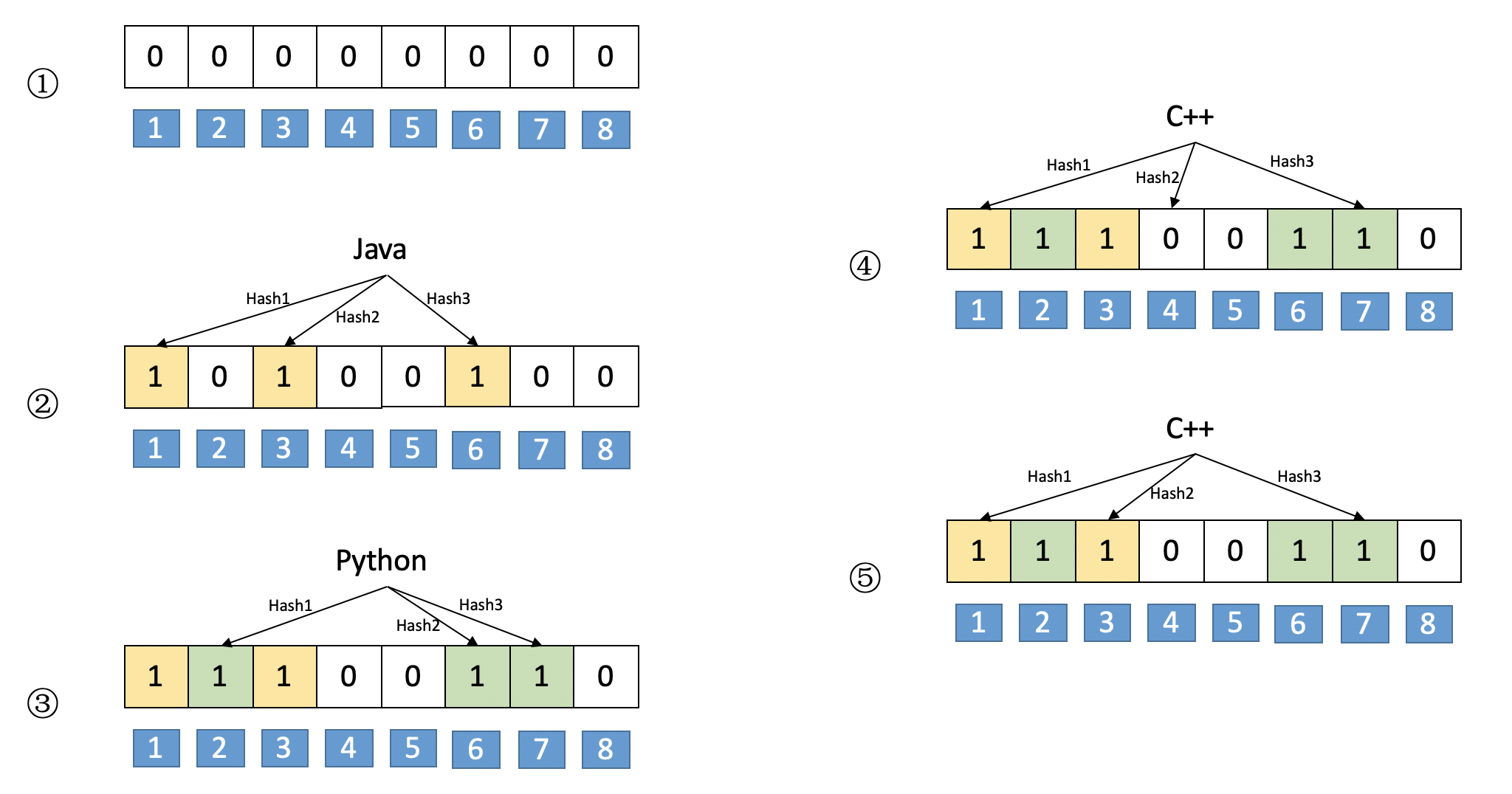
①如上图所示,第①步是布隆过滤器的初始结果,在这一步中,所以bit位都初始化为0
②现在如果有一个词“Java”,其hash值为1,3,6,则将其对应的bit位置1,如图②所示
③现在有另外一个词“Python”,其hash值为2,6,7,则将其对应的bit位置1,如果③所示,注意:6位置的1被覆盖
④如果现在需要查询“C++”是否存在,若“C++”对应的hash值是1,4,7,则bit为1和7对应元素是1,但是bit4位置元素是0,所以可以判断“C++”现在不存在。
判断方法: 当需要查询的词的所有bit位所有都为1时,说明待查询词可能已经存在。但是只要有一个为0,则可以说明,待查询词一定不存在。
⑤如果现在需要查询“C++”是否存在,若“C++”对应的hash值是1,6,7,则hash位置对应的元素都是1,所以可以判断“C++”可能存在。
注意: 为什么强调可能存在,是因为,当已存在的单词较多的时候,很多hash位置都为1,这时候待查询词对应的hash位置可能都为1,但是其并不存在。比如“C++”对应的hash位置是1,6,7,且对应值全部为1,所以我们判断“C++”存在,但其实在此之前我们并没有加入“C++”这个单词到BloomFilter。
3、BloomFilter可以支持的操作
- 支持插入操作
从上述例子可以知道,如果想要插入一个元素到布隆过滤器,只需要将其对应hash对应元素置1 - 支持查询操作
上述例子中已经提到,可以支持查询操作,也就是判断其是否已经存在。当需要查询的词的所有bit位所有都为1时,说明待查询词可能已经存在。但是只要有一个为0,则可以说明,待查询词一定不存在。 - 支持删除操作么?
原则上BloomFilter不支持删除操作,因为其置1操作是覆盖式的,如果现在需要删除“Python”这个词,则需要将其对应的hash值位置恢复为0,即将2,6,7位置恢复为0,这种方法会使得“Java”中的6位置处的1失踪。
当然可以采用一种方法就是计数法,比如现在BloomFilter中6位置处已经为1,再次插入时,不是覆盖1,而是进行+1操作。当进行删除操作时,不进行置0操作,而是执行减1操作。但是这种方法需要对每个bit位增加一个存储操作,会增加内存占用。
四、Bloom Filter公式推导
1、误判率推导
假设 m m m是该bit数组的大小, k k k是哈希函数的个数, n n n是插入的元素的个数。
假设hash函数以等概率条件选择并设置bit位为“1”,则其概率为 1 m \frac{1}{m} m1?,因此bit数组中某一特定的位在进行元素插入时的hash操作中没有被置为1的概率是 1 ? 1 m 1- \frac{1}{m} 1?m1?
在经过 k k k个哈希函数之后,该位仍然没有被置“1”的概率是: ( 1 ? 1 m ) k (1- \frac{1}{m})^k (1?m1?)k.
若插入了 n n n个元素,该位仍然没有被置“1”的概率是: ( 1 ? 1 m ) k n (1- \frac{1}{m})^{kn} (1?m1?)kn.
因为该位被置“1”的概率是: 1 ? ( 1 ? 1 m ) k n 1-(1- \frac{1}{m})^{kn} 1?(1?m1?)kn.
现在检测某一元素是否在该集合中,则表明需要判断是否所有hash值对应的位都置1,但是该方法可能会错误的认为原本不在集合中的元素是在BloomFilter中的,即导致误判率的发生,其概率为:
[ 1 ? ( 1 ? 1 m ) k n ] k ≈ ( 1 ? e ? k n m ) k [1-(1- \frac{1}{m})^{kn}]^k \approx ( 1- e^{-\frac{kn}{m}})^k [1?(1?m1?)kn]k≈(1?e?mkn?)k
≈ \approx ≈是因为使用了近似公式: lim ? x ? > ∞ ( 1 ? 1 x ) ? x = e \lim_{x->\infty }(1-\frac{1}{x})^{-x}=e limx?>∞?(1?x1?)?x=e
从上式可以看出,当 m m m增大时,误判率减小;当 n n n增大时,误判率增大。
2、最佳哈希函数个数推导
k k k为何值时,误判率可以最小呢?
误判率函数:
f ( k ) = ( 1 ? e ? k n m ) k f(k) = ( 1- e^{-\frac{kn}{m}})^k f(k)=(1?e?mkn?)k
令 b = e n m b = e^{\frac{n}{m}} b=emn? ,则简化为 f ( k ) = [ ( 1 ? b ? k ) ] k f(k)=[(1-b^{-k})]^k f(k)=[(1?b?k)]k
两边取对数得:
l n f ( k ) = k l n ( 1 ? b ? k ) lnf(k) = kln(1-b^{-k}) lnf(k)=kln(1?b?k)
两边对 k k k求导得:
1 f ( k ) ? f ′ ( k ) = l n ( 1 ? b ? k ) + k b ? k l n b 1 ? b ? k \frac{1}{f(k)} \cdot f'(k) = ln(1-b^{-k}) + \frac{kb^{-k}lnb}{1-b^{-k}} f(k)1??f′(k)=ln(1?b?k)+1?b?kkb?klnb?
若 f ( k ) f(k) f(k)取最值,则 f ′ ( k ) = 0 f'(k) = 0 f′(k)=0,则:
l n ( 1 ? b ? k ) + k b ? k l n b 1 ? b ? k = 0 = > ( 1 ? b ? k ) ? l n ( 1 ? b ? k ) = ? k b ? k l n b = > ( 1 ? b ? k ) ? l n ( 1 ? b ? k ) = b ? k l n ( b ? k ) = > 1 ? b ? k = b ? k = > b ? k = 1 2 = > e ? k n m = 1 2 = > k n m = l n 2 = > k = l n 2 ? m n = 0.7 ? m n \begin{array}{lcl} &&ln(1-b^{-k}) + \frac{kb^{-k}lnb}{1-b^{-k}} = 0 \\ &&=>(1-b^{-k}) \cdot ln(1-b^{-k}) = -kb^{-k}lnb \\ &&=>(1-b^{-k}) \cdot ln(1-b^{-k}) = b^{-k}ln(b^{-k}) \\ &&=>1-b^{-k} = b^{-k} \\ &&=> b^{-k} = \frac{1}{2} \\ &&=> e^{\frac{-kn}{m}} = \frac{1}{2} \\ &&=>\frac{kn}{m} = ln2 \\ &&=>k=ln2 \cdot \frac{m}{n} = 0.7 \cdot \frac{m}{n} \end{array} ??ln(1?b?k)+1?b?kkb?klnb?=0=>(1?b?k)?ln(1?b?k)=?kb?klnb=>(1?b?k)?ln(1?b?k)=b?kln(b?k)=>1?b?k=b?k=>b?k=21?=>em?kn?=21?=>mkn?=ln2=>k=ln2?nm?=0.7?nm??
也就是当 k = 0.7 ? m n k=0.7 \cdot \frac{m}{n} k=0.7?nm?时,误判率最低, k k k为最佳哈希函数的个数。此时误判率为:
P ( e r r o r ) = f ( k ) = ( 1 ? e ? k n m ) k = 2 ? l n 2 ? m n ≈ 0.6158 ? m n \begin{array}{lcl} P(error) = f(k) &=& ( 1- e^{-\frac{kn}{m}})^k \\ &=& 2^{-ln2 \cdot \frac{m}{n}} \\ &\approx& 0.6158 \cdot \frac{m}{n} \end{array} P(error)=f(k)?==≈?(1?e?mkn?)k2?ln2?nm?0.6158?nm??
3、Bloom Filter内存占用
在实际应用时,用户需要决定需要插入的元素数 n n n和期望的误差率 P P P,也就是 n n n和 P P P这两个值是已知的,则:
(1)首先需要计算需要占用的内存大小 m m m
P = 2 ? l n 2 ? m n l n P = l n 2 ? ( ? l n 2 ) m n m = ? n ? l n P ( l n 2 ) 2 \begin{array}{lcl} && P = 2^{-ln2 \cdot \frac{m}{n}} \\ && lnP = ln2 \cdot (-ln2)\frac{m}{n} \\ && m = - \frac{n \cdot ln P}{ (ln2)^2 } \end{array} ??P=2?ln2?nm?lnP=ln2?(?ln2)nm?m=?(ln2)2n?lnP??
于是,我们知道内存占用为 m = ? n ? l n P ( l n 2 ) 2 m = - \frac{n \cdot ln P}{ (ln2)^2 } m=?(ln2)2n?lnP?bit,现在已知变量为 n n n, m m m和 P P P
(2)求得哈希函数的个数 k = l n 2 ? m n = 0.7 ? m n k = ln2 \cdot \frac{m}{n} = 0.7 \cdot \frac{m}{n} k=ln2?nm?=0.7?nm?
至此 n n n, m m m, P P P和 k k k都已经知道。
(3)求内存占用
当 k k k最优时: P ( e r r o r ) = 2 ? l n 2 ? m n P(error) = 2^{-ln2 \cdot \frac{m}{n}} P(error)=2?ln2?nm? = 2 ? k =2^{-k} =2?k.
P ( e r r o r ) = 2 ? k = > l o g 2 P = ? k = > k = l o g 2 1 P = > l n 2 ? m n = l o g 2 1 P = > m n = 1 l n 2 ? l o g 2 1 P = > m n = 1.44 ? l o g 2 1 P \begin{array}{lcl} &&P(error) = 2^{-k} \\ && => log_2P = -k \\ &&=> k = log_2 \frac{1}{P} \\ && =>ln2 \cdot \frac{m}{n} = log_2 \frac{1}{P} \\ && => \frac{m}{n}=\frac{1}{ln2} \cdot log_2 \frac{1}{P} \\ && => \frac{m}{n} = 1.44 \cdot log_2 \frac{1}{P} \end{array} ??P(error)=2?k=>log2?P=?k=>k=log2?P1?=>ln2?nm?=log2?P1?=>nm?=ln21??log2?P1?=>nm?=1.44?log2?P1??
因此,若我们设置 P = 1 % P=1\% P=1%,则存储每个元素需要 m n = 1.44 ? l o g 2 1 0.01 = 9.57 \frac{m}{n}= 1.44 \cdot log_2 \frac{1}{0.01}=9.57 nm?=1.44?log2?0.011?=9.57bits的空间(9.57是bit位置为0和置为1的总bit位数),此时 k = 0.7 ? m n = 0.7 ? 9.57 = 6.7 k=0.7 \cdot \frac{m}{n} =0.7 \cdot 9.57=6.7 k=0.7?nm?=0.7?9.57=6.7bits(6.7是bit位置为1的bit位数);若我们想将误判率降低为原来的 1 10 \frac{1}{10} 101?,则存储每个元素需要增加 1.44 ? ( l o g 2 10 a ? l o g 2 a ) = 1.44 ? l o g 2 10 = 4.78 1.44 \cdot (log_2 {10a}-log_2 a)=1.44 \cdot log_2 10 = 4.78 1.44?(log2?10a?log2?a)=1.44?log2?10=4.78bits的空间。
当 k = 0.7 ? m n k=0.7 \cdot \frac{m}{n} k=0.7?nm?时,误判率 P P P最低,此时 P ( e r r o r ) = ( 1 ? e ? k n m ) k P(error) = ( 1- e^{-\frac{kn}{m}})^k P(error)=(1?e?mkn?)k, e ? k n m = 1 2 e^{\frac{-kn}{m}} = \frac{1}{2} em?kn?=21?,也就是 ( 1 ? 1 m ) k n = 1 2 (1- \frac{1}{m})^{kn}=\frac{1}{2} (1?m1?)kn=21?,此公式意义为:若插入了 n n n个元素,该位仍然没有被置“1”的概率,也就是说想保持错误率低,布隆过滤器的空间使用率需为50%。
五、Bloom Filter优缺点
1、优点
- 布隆过滤器本质上是一种数据结构,是一种比较巧妙的概率型数据结构
- 插入和查询非常高效,占用空间少(只需要m个bit位)
2、缺点
- 其具有一定概率的误判性(False Positive),即Bloom Filter认为存在的东西很有可能不存在。
- 若不进行计数操作,BloomFilter无法进行删除操作。
六、参考文章
[1] 详解布隆过滤器的原理、使用场景和注意事项
[2] 应用 5:层峦叠嶂――redis布隆过滤器
[3] 布隆过滤器(Bloom Filter)详解
[4] 【原】布隆过滤器 (Bloom Filter) 详解