����Ŀ¼
- ����
- ����
-
- ����1��
- ����2��
- ����3��
- ��������
-
- �ַ������ַ�����
- �ļ�·��
- ����ʶQString
- ����ʶQTextCodec
- �ļ��ı���
-
- ���д��"һ������"?
- QStringתchar*
- char* ת QString
- �ص���ʼ������
- ���ֽ�/���ֽ�ת��
- Qt��������-����
- ��������
-
- ����C-FILE����
- NotePad++�ڵĿ�
����
һ�������ѣ��ַ������ַ������ʽ���Լ������ǵ��µ������������⣬���������Щ�����ֶΣ���ʼ��û��������������ص���N�ε����⣺Ϊɶ��������鷳�£�ɶʱ����Ҫ���ֽ���խ�ֽڵ�ת������Qt��IDE-Debug����ʱ�������̨�ܽ����ִ�����룿Qt��QString��������ʱ�����ת��Ϊchar*���ܱ�����C-FILE-fopen�ĺ�����ȷ����ʹ�ã���ô����QString��Unicode����ģ��ļ��洢/�ļ��������ַ���������ʲô��ϵ?
����
���������ǽ���Ҫ��fopenΪ����չ����صIJ���������;����ǰ�����ı������⣬��Ҫ���������ļ�·��ת���ϣ�����ѡC-FILE�������������IJ��ԡ�C-FILE�ľ�����ز�����ο���
//C-FILE-fopen DEFINE
FILE *__cdecl fopen(const char * __restrict__ _Filename,const char * __restrict__ _Mode);
���Ÿ���ʼ���⣺fopen���Խ��ܵ�_Filename��������Ա����ʽ����Ҫ��ģ� Let��s start a new journey!
��������
//const char *pFileName = "F:/123.txt";
const char *pFileName = "F:/�����.txt";FILE *outFile = fopen(pFileName, "rb");
if (NULL == outFile)qDebug() << "Can't open specified file absolute path!";
����1��
�½�Qt���̣�cpp�ļ�Ĭ��utf-8���룩��ʹ���������Ĵ��룬��ָ���κ�QTextCodec���ã���Ӣ·������������·�������֣���NotePad�ı�����cpp��ANSI��ʽ����(�ῴ�� ���й����֡� ����� ���?��汉字��, ɾ��������������;��IDE���¼��ش��ļ������Ͻ���ʾ�������ʽΪSystem)���������г�������·���ɴ�
PS:��QtCreator-����-ѡ��-�ı��༭��-��Ϊ-�ļ����� �����Ĵ����ļ���Ĭ�ϱ����ʽ���ĺ��½��ļ���Ч��
����2��
��������cpp�ļ�System��ʽ���䣬��QTextCodec���������ֶ�����QString��������ʹ�ô����const char�ַ����顣QString�����������֮������
QString strTmp("F:/�й�����.txt");//������� - ����ɲ� ����QStringתchar* �½�
//char *pFileName = strTmp.toLocal8Bit().data();char pFileName[256] = {
0}; //{'\0'} �ڴ���һ��
memcpy(pFileName, strTmp.toLocal8Bit().data(),strTmp.toLocal8Bit().size());
qDebug() << strlen(pFileName); //17 //10���Լ�������4������ ���������Ľ��డ ʲô����
��������fopenʧ�ܣ�������֮��ģ��ѵ�"ANSI��ʽ����cpp�ļ�"��**����һ��QString��ת����ȥ���Ͳ����ˣ�**��������±ߵ�QString������������ۡ��ȿ����ԣ����Ǿ����ϱߵIJ�����main���������µ�QTextCodec���á�
QTextCodec::setCodecForLocale(QTextCodec::codecForName("System")); //main.cpp
QTextCodec::setCodecForCStrings(QTextCodec::codecForName("System")); //mian.cpp
...
qDebug() << strlen(pFileName); //15 //Every chinese character use 2 byte
����ִ�в��Գ�����ֿɳɹ�������·�����ļ����ڽ���QTextCodec����ǰ�����Ե�һ�д���ʱ��strTmp�Լ��������룬��˵�����ڹ���ʱ�ͳ������⣬����QStringʹ��const char*���й���ʱ��Ĭ�ϰѴ���128���ַ�����Latin-1�ַ����μ�����ʶQString�½ڣ��������ǵ�ϵͳ�����Dz�һ���ģ��������ִ˲����У�CodecForLocale������Ҳû��ϵ������toLocal8Bit�İ����п���get������Ϊ����ʵĬ��ʹ����"System"��codec��
����3��
�����е�cpp�ļ��ı����ʽ���Ļ�ϵͳĬ�ϵ�utf-8�������������±༭���롣���Դ��븴�ò���2������QTextCodec������һ�����⣬����û����������������������IJ���������������QTextCodec���ã�û��ɾ������
fopenִ��ʧ��������֮�еģ���ʱstrlen(pFileName)==19 ÿ������ռ����3���ֽڡ�(��������⣺cpp�ļ������ʽ�����õ�CodecForCStrings����Ӧ��������һ�������Ĵ������ݣ�ͨ�������룬ֻ����ʾ����ȷ�������ǶԵģ���������̾����������ģ���utf-8���ļ�����"System"��codec������������һ��unicode��strTmp����������У������������л���������ʲô��д��仰��ʱ����Ҳû��������ף��������ɡ�)����ȴ�������������ķ������ˣ������±ߵ�QTextCodec���ã�����ʹ�øò����е�fopenִ�гɹ���
QTextCodec::setCodecForCStrings(QTextCodec::codecForName("UTF-8"));
QTextCodec::setCodecForLocale(QTextCodec::codecForName("System"));
��������
��Ҫ�ش�ʲô���ַ������ַ������ʽ��������ʲô����ϵ��ʲô��QString�ڱ��봦���ϵ�����ʲô�ر���һ�ѵ�������йصĽӿڣ�զ����˼���ǣ���ѡ�������� ANSI/ASCII/UNICODE/UTF-8 etc. ����ɶ��
�ַ������ַ�����
�ַ������ַ������ʽ��ʲô��������ã��ַ������ַ������������Ҫ�ο�������ƪ���£���������ɶ���ַ������ַ����룬�Լ����ǵ����𣬶�Unicode��UTF-8�Ĺ�ϵ�������µ���ʶ������ANSI��ASCII��GBK��etc. �ɲΰٿơ�
�ַ�������д/��ʾϵͳ���ַ�(��ĸ�����֡����š����֡�)�ļ��ϣ����ַ��������ǽ��ַ�ӳ��Ϊ�ض����ֽڻ��ֽ����У���һ�ֹ���ͨ���ض��ַ��������ض��ı��뷽ʽ����һ���ַ�����Ӧһ���ַ����룬���磺ASCII��IOS-8859-1��GB2312��GBK�����Ǽ���ʾ���ַ����ֱ�ʾ�˶�Ӧ���ַ����룬��ʱ�����ɽ�������Ϊͬ��ʡ���Unicode���ǣ��������ִ���ģ�ͣ�UNICODE�ַ������ж�����뷽ʽ���ֱ���UTF-8��UTF-16��UTF-32���롣
��UTF-8�£�������ַ����ģ����ĺͺ����ַ���������3���ֽڵģ���������CJK�ַ���������ŵ�ͨ����4�ֽڱ��롣BOM��Byte Order Mark���ֽ����ֽ�˳��ı�ʶ������ʵ�����ô�˻���С�ˡ���UTF-8����洢���܌š�������{E5BE88, E5B18C}����ʾʱ����GBK�������չʾ��ͨ��������ǻ��������Ϣ��E5BE{�} 88E5{��} B18C{��}�������ַ�������Ӳ�����Ľ����3�������ַ���
�����ĺ����ַ������룺
- GB2312���룺1981��5��1�շ����ļ������ĺ��ֱ�����ұ���GB2312�Ժ��ֲ���˫�ֽڱ��룬��¼7445��ͼ���ַ������а���6763�����֡�
- BIG5���룺̨������������ı��ַ���������˫�ֽڱ��룬����¼13053�������֣�1984��ʵʩ��
- GBK���룺1995��12�·����ĺ��ֱ�����ұ����Ƕ�GB2312��������䣬�Ժ��ֲ���˫�ֽڱ��롣GBK�ַ�������¼21003�����֣��������ұ�GB13000-1�е�ȫ�����պ����֣���BIG5�����е����к��֡�GBK ����������չ�淶�������
- GB18030���룺2000��3��17�շ����ĺ��ֱ�����ұ����Ƕ�GBK��������䣬�������ġ����ġ���������й������������֣�������¼27484�����֡�GB18030�ַ������õ��ֽڡ�˫�ֽں����ֽ����ַ�ʽ���ַ����롣����GBK��GB2312�ַ�����
- Unicode���룺���ʱ��ַ�������������������Ե�ÿ���ַ�����һ��Ψһ�ı��룬����������ԡ���ƽ̨���ı���Ϣת����
�ļ�·��
д��ǰ�ߣ���Ҫ�ô�Ŀ¼�ָ���Ŷ�����Dz���Գ�ڽ����ļ�����ʱ�ij������⣺��Ҫ�ǻ�����win�ϵ�Ŀ¼�ָ���/��б����\��б�ܶ����ԣ�����б�ܵ�ʹ�����漰����ת���ַ���
PS:·���ָ����ŵ�����
- ��UNIX�����£�Ŀ¼�еļ��������б�� / ��
- ��Windowsƽ̨�ϣ�Ŀ¼�еļ��������б��/�ͷ�б��\�����ԡ�
- ��window��Դ�������У��鿴Ŀ¼·��ʱ�����Է�б����ʾ�ģ����ǵ�����ʹ��QFile::filePath�Ƚӿ�ʱ�����ص�QString�ж���/��б�ָܷ�����������ܶ�Գֱ�Ӿ���������������·����
����ʶQString
QString-Detailed Description
The QString class provides a Unicode character string. QString stores a string of 16-bit QChars, where each QChar corresponds(����) one Unicode 4.0 character.
Unicode is an international standard that supports most of the writing systems in use today. It is a superset�������� of US-ASCII and Latin-1, and all the US-ASCII/Latin-1 characters are available at the same code positions.
QString str = "Hello";
QString converts the const char * data into Unicode using the fromAscii() function. By default, fromAscii() treats character above 128 as Latin-1��ISO-8859-1���룩 characters, but this can be changed by calling QTextCodec::setCodecForCStrings().
ͨ������������QTextCodec::setCodecForCStrings(QTextCodec::codecForName(��UTF-8��));�������ϴ�ʱ��QString��������� static QString::fromUtf8��������ת������һ��utf8��cpp�ļ��ı��룩�� const char *data ת��ΪUnicode��QString��Ҳ��QString����ʼ����Unicode�ġ�
In all of the QString functions that take const char * parameters, the const char * is interpreted�������� as a classic C-style ��\0��-terminated string. It is legal���Ϸ��ģ� for the const char * parameter to be 0.
����ʶQTextCodec
�±��DZ�"����"�����д��룬��Ҫ���۵��ǣ�����������������ù��̣��ڸ߰汾Qt�У��⼸�������Ѿ�������Ӱ��QTextCodec-4.8.6 �� QTextCodec-5.14����ο���ȡ��ԭ���Լ�ǣ�qt5�Ժ�ǿ��Ҫ����Դ�루��cpp�ļ����룩Ϊutf-8���루��4.8.6�п��Խ�cpp�ļ�����ǿ�ij�ANSI���룩���ˣ�������ҪsetCodecForTr/ForCString������?#�겻ϸ������setCodecForCStringsΪ����4.8.6�У�����QStringʹ��const char*�������ʱ�������ã�
Qt5�о���ȥ����setCodecForTr/ForCString����������Ĭ�ϱ��뻹��latin1�������Ҫ��ʹ�� ���й����֡� �������ַ����������Լ�ʹ��QTextCodec����QString::fromXXX ��غ�������ת����Ҳ������QStringLiteral����ֶ�ת���� ����Qt����һ�ٴ룬ʹ������MSVC�ļ������������ͣ��˴������
QTextCodec::setCodecForLocale(QTextCodec::codecForName("UTF-8"));
QTextCodec::setCodecForCStrings(QTextCodec::codecForName("UTF-8"));
The QTextCodec class provides conversions between text encodings. Qt provides a set of QTextCodec classes to help with converting non-Unicode formats to and from Unicode.
Qt uses Unicode to store, draw and manipulate strings. In many situations you may wish to deal with data that uses a different encoding. For example, most Japanese documents are still stored in Shift-JIS or ISO 2022-JP, while Russian users often have their documents in KOI8-R or Windows-1251.
[river.qu] Chinese doc or chinese pc file system list show are still used GBK. The GBK codec provides conversion to and from the Chinese GB18030/GBK/GB2312 encoding.[QTextCodec Class Reference GB18030-0]
void QTextCodec::setCodecForCStrings ( QTextCodec * codec ) [static]
Sets the codec used by QString to convert to and from const char * and QByteArrays. If the codec is 0 (the default), QString assumes(����) Latin-1. Ҫ��������������������Ķ���QString Detailed Description����Initializing a String �IJ��֡��������ܣ�����QString�������У���const char*��QByteArrays���ݣ���ʽת���ı����������磺
- ��const char* ����QString��QString converts the const char * data into Unicode using the QString::fromUtf8() function, If ִ����setCodecForCStrings(��UTF-8��),����ɲμ��������е�QString���졣
- QByteArray QString::toUtf8 ()�� Returns a UTF-8 representation of the string as a QByteArray.UTF-8 is a Unicode codec and can represent all characters in a Unicode string like QString. [UTF8 & Unicode - Help]
- ���⣬��ʹ��QStringʱ�����ע�⣬����cpp�ļ������ʽ��CodecForCStrings����ȫһ�£������������Ĵ����ַ�����
However, in the Unicode range, there are certain codepoints that are not considered characters. The Unicode standard reserves the last two codepoints in each Unicode Plane (U+FFFE, U+FFFF, U+1FFFE, U+1FFFF, U+2FFFE, etc.), as well as 16 codepoints in the range U+FDD0��U+FDDF, inclusive, as non-characters. If any of those appear in the string, they may be discarded and will not appear in the UTF-8 representation, or they may be replaced by one or more replacement characters.
�ܽ��������Ҫ������QString�Ĺ����ϣ�����ͬ����(��UTF-8��System)��const char* data���ļ��������ȣ�������֮��Ӧ��ת��������ת��Unicode�����QString���˴�����������QString�����ı����ʽ����ʼ����Unicode�ġ�
void QTextCodec::setCodecForLocale ( QTextCodec * c ) [static]
Set the codec to c; this will be returned by codecForLocale(). If c is a null pointer, the codec is reset to the default. ע�⣺�����Local��Qt��ǰ����Ӧ�ó�����ϵͳ��Local�����ʽ���ú�����Ҫ�����toLocal8Bit��ʹ�á�
QTextCodec * QTextCodec::codecForLocale () [static]
Returns a pointer to the codec most suitable for this locale.
On Windows, the codec will be based on a system locale. On Unix systems, starting with Qt 4.2, the codec will be using the iconv library. Note that in both cases the codec��s name will be ��System��.
QByteArray QString::toLocal8Bit () const
Returns the local 8-bit representation����ʾ���� of the string as a QByteArray. The returned byte array is undefined if the string contains characters not supported by the local 8-bit encoding.
QTextCodec::codecForLocale() is used to ���������� perform����ɣ� the conversion from Unicode. If the locale encoding could not be determined, this function does the same as toLatin1().
ע�ͣ�
QString::toLocal8Bit �� Unicode�����QString��ת��Ϊ���������ʽ �������Դ洢�����ı��ļ������Qt����ʾ����win�ļ�ϵͳ�б��������ת��QByteArray�Ĺ��̣�������codecForLocale() ��Ҳ��setCodecForLocale(��)�����ý�� ��
������
QTextCodec::setCodecForTr(QTextCodec::codecForName(��UTF-8��));�京����setCodecForCStrings���ƣ�����Ϊtr()������ģ�tr()����QObject�����ǿ���ʹ��Q_DECLARE_TR_FUNCTIONS()�궨��Ϊ��QObject����������tr()���������GUI-Qt4_P153����
�ļ��ı���
ֻ֪����txt�ļ���cpp�ļ��ȣ���NotePad���ı����ʽ������ı����ʽָ���ǣ���ͨ��˵���ַ������ʽ����������ϵ�أ�
PS: �������ļ����ı��ļ����ļ������ʽ�ļ����ԣ���ʱ�ο�1����ʱ�ο�2��
���ڣ���UTF-8������ַ�����Ϊ�ļ����ƴ����ļ�������ļ��������룻��UTF-8��char�ַ�������fopen���ϣ�����Ӧ������PC�ļ�ϵͳ����ģ���йأ���Ҳ��Ӧ�ó���Ҳ��Գ��ģ������Ͳ���UTF-8���룬��ϣ�����ǣ���ANSI��System-GBK ���ѡ��Ӧ�����ڰ�װwin����ϵͳѡ��-��������-ʱ�����ģ�
���д��"һ������"?
Ϊ�˾����ܵ���ȴ��Ӱ�� �˴���char�� + C-FILE��������ʹ��Ҳ����Ҫ�κ�QString��QTextCodec���ã���Ҫ�������������ɣ����£�
//�����1 //�±ߵĴ���д��ANSI(system)��ʽ�����cpp�ļ���
FILE *pFile = fopen("F:/testfile.dat", "wb");
if(NULL != pFile) qDebug() << "ok";
//char chardata[50] = "abc123";
char chardata[50] = "abc�����123";
int numok = fwrite(chardata, 1, strlen(chardata), pFile);
fclose(pFile);
//�����2 //�±ߵĴ���д��UTF-8(Without BOM)��ʽ�����cpp�ļ���
FILE *pFile = fopen("F:/testfile.dat", "ab");
if(NULL != pFile) qDebug() << "ok";
char chardata[50] = "abc�����123";
int numok = fwrite(chardata, 1, strlen(chardata), pFile);
fclose(pFile);
������Թ������£�
- ��testfile.datִ��Ƭ��1(д��ANSI�����abc123)����ʱ�鿴�ļ������ʽΪANSI��Ȼ��ִ��Ƭ��2��д��UTF-8�����"abc�й�����123"����������NotePad2�鿴�ļ�����ΪUTF-8����������ʾ��ע�⡢ע�⡢ע�⣺���ĵ�һ��д��ʱ��
- ��testfile.datִ��Ƭ��1(д��ANSI�����abc�й�����123)����ʱ�鿴�ļ������ʽΪANSI��Ȼ��ִ��Ƭ��2��д��UTF-8�����"abc�й�����123"����������NotePad2�鿴�ļ����뻹��ANSI���Һ���Ϊ������ʾ��abc�й�����123abc�?��汉字123����ע�⡢ע�⡢ע�⣺�����"д��������ֶ�"��
���Խ������£�������Ƭ��ģ���
����һ�����ı��ļ�д�뺺��ʱ���õı����ʽ���ᱻ��Ǽ�¼��֮����ִ���ַ���(������)��д��ʱ����Dz��䡣��ʹ���ı��༭�����ļ�ʱ�����ձ�ǵı����ʽ���н��롣�DZ�DZ����ʽ���ַ���������"����ʾ��"���ı��ļ���Ĭ�ϱ����ʽ��ANSI����ʼ��ֻ������д��Ӣ�ģ�������ʲô�����ʽ�ģ��ļ��ı����ʽ����ANSI���䣻ֱ����һ��д�����Ĵ�������ʱ���Ĵ�ΪUTF-8����ģ�д��������ļ��ı����ʽҲ��ANSI�����UTF-8��ʽ���롣
˼��һ��������,��˭�ڲٿأ������������IJ��Խ������Ҫ��˭��ʲôʱ��̻���һ���洢�ļ��ı����ʽ��
���У��ҿ�����������ǣ�cpp�ļ�������˵��Դ���룩�еģ��Ǹ��ַ���"�й�����"������ô�����г�����ϵ��������������û�б������ã������������룿������ڱ���ξ;����ˣ���������һ�������ļ��ļ�cpp�����������ļ�exe��ת�����̡���
������ϱߵIJ���������������˼�����ļ����롢�ļ��༭���������е��ַ������������ȸ���������Щ��
�����ļ��洢�ʹ��䱾���������ر����ʽ����Ϊ���Ǵ������DZ���������ȡ/�շ�ʲô���ؽ�Ҫ��ֻҪ�洢/�����ִ���ߣ�֪�����뼴�ɡ�ֻ�ǣ����ͬһ����Ϣ���ַ����������ò�ͬ�����ʽ����GBK��UTF-8������洢/������ֽڴ�С���ܲ�ͬ��
QStringתchar*
��һ���쳣��������IDE��Locals and Expressions���Դ����У��鿴һ��char*����ʱ,�����������£�
...QString strZipFileName = "F:/4.zip"��//ִ��ǰ ��δ���� ���Դ���ʾpcharZipName ָ��3���ֽ�
char *pcharZipName = (char*)malloc(strZipFileName.toLocal8Bit().size());
//ִ�к� ���Դ���ʾpcharZipNameָ��23�����ֽ� //ʵ��sizeΪ8//ִ�к� pcharZipName Ϊ""
memset(pcharZipName, '\0', strZipFileName.toLocal8Bit().size());//ǰ8���ֽ�Ϊ��ȷ����"F:/4.zip" ���������
memcpy(pcharZipName, strZipFileName.toLocal8Bit().data(), strZipFileName.toLocal8Bit().size());
//������Ĵ���ʵ�֣�
char *pcharZipName = (char*)malloc(strZipFileName.toLocal8Bit().size() + 1);//size() == 8
memset(pcharZipName, '\0', strZipFileName.toLocal8Bit().size() + 1);
memcpy(pcharZipName, strZipFileName.toLocal8Bit().data(), strZipFileName.toLocal8Bit().size());
��QStringת��Ϊchar array[n]ʱ����ͬ�������⣬�����һ���ֽڵġ�\0��������ܵ���charָ���ڴ����Here�����ڴ�ָ��Χ�����µ����룬��C�ַ�����Ҫ��\0����β�йأ�����pcharZipNameָ����ַ�����ʲô�����ʽ�Ĺ�ϵ�������쳣���µ����룬�Ǵ洢����ʾ����Ĵ������ݱ����ǶԵģ�ֻ��չʾ�����Ǵ���ġ�
**PS1��*const char data ��QString�Ĺ��죬QString�����Զ��ġ�\0��������������ģ�QString::toLocal8Bit()��QString::toStdString() etc. �����ƵĴ����� �ȱ����½��ۣ������£�
QString strTmp("F:/abc.txt");
char *pFileName = strTmp.toLocal8Bit().data();/** @brief running result���ڴ�鿴���п��Կ��Է���pFileName��ָ��Χ��100���ֽ� ���뵽fopen�в�ʶ�� **///������������������
const char *pFileName = strTmp.toStdString().c_str();//�Ͳ��һ���ֽ� //�Ǵ����������������� //�ɲμ����ڵ�һ�δ���
ͨ�����ԣ����ѵó���QString��QByteArray��std::string��etc. ��תconst char* cdata�������ڴ��ڴ��ĩβ��һ����\0��,�����Ҫ�Լ������ӣ�ͨ��������malloc size+1 ��������ʱ size+1������+1�ڴ沢memsetǰ��ֱ��ȥ��cdata��ֵ������ľ�����廹�ᷢ�����ش���
//�Ƿ�ָ�����鳤����Ӱ��
char a[/*10*/] = "river"; //�����鿴����ʾ���� ������½�ͼ
printf("%s-strlen-%d", a, strlen(a)); fflush(stdout); //river-strlen-5/** @brief //��ϧ�� �±ߵĴ����DZ��벻ͨ���� ��Ȼ����ͦ�����* array must be initialized with a brace-enclosed(������) initializer //little ps: �ַ���������ֵʱ��ʡ��{} ..���� **/
char pFileName[] = strTmp.toLocal8Bit().data();
char pFileName[20] = strTmp.toLocal8Bit().data();
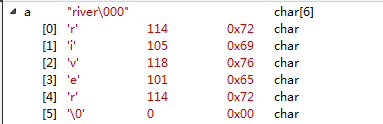
��ͼ��char a[ ] = ��river��;�ĵ��Խ�ͼ���Լ�������һ������������ֱ�Ӷ���char a[10] = ��river����ʱ�������鿴����ʾ�����5����\0���ַ������Զ���ʼ���ϵģ����ǵ������{}��ֵ�������²���Щ��\0����ʡ�Ե��Ĵ����ŵ����ҽ����ʹ��char a[10] = {};���ԣ����ֹ�Ȼa����ʼ������10����\0���ַ������⣬�ڴ˴�������strlen()��sizeof()������
PS2�� string.h �� std::string �� C�ַ���
���ȿɲο�string.h�ٿƣ�C������<string.h>ͷ�ļ�������ȴû��string������͡���C�����У��ַ����Ǵ�����ַ��������еģ�Ϊ�˲ⶨ�ַ�����ʵ�ʳ��ȣ�C���Թ涨��һ��"�ַ���������־",����\0����־(ASCII����-NULL��PS:��0���롯\0��)��
��Qt-IDE��mingw���� #include ��mingw32\i686-w64-mingw32\include\c++ ���� #include <string.h>��mingw32\i686-w64-mingw32\include����ͨ������£�����.h���Ǵ�.h�������棨string.h�ٿƣ���Ψ��string�ر���������C++Ҫ����C�ı��⣬��C�ĵı�����ǡ��Ҳ��һ�����ֽ���string.h��ͷ�ļ������ͷ�ļ���C++��string���ëǮ��ϵľ�С��ֱ��C��C++�µĸ�ͷ�ļ����Ƚϣ��亯��������Ŀ�ǻ���һ�µģ�ֻ���������в�𣬱����C�ľ���C++�ģ����ݼ��ݰ��� string.h�еij��ú���-�ɲ�1����Qt-IDE�£�std::string �����͵Ķ����Լ����:
//mingw32\i686-w64-mingw32\include\c++\bits\stringfwd.h
//���հ�����<string>�ļ�(��)�� ��д#include <string> ����ȥLookLook
namespace std _GLIBCXX_VISIBILITY(default)
{
... typedef basic_string<char> string; ... }//basic_string �Ǹ�C++ģ����
template<typename _CharT, typename _Traits, typename _Alloc>
class basic_string
{
... has func insert/replace/find etc. ... };
char* ת QString
���ˣ������Ѿ�����������QString����char* ����Ϊ�����Ļ������̣�Ҳ֪��const char* sData����QStringʱ�����üӡ�\0��,��������ȴ�����ڴ�����Щ����const��char*����ʱ�����������磬�յ���һ���������� ��char *buffer, bufLen��,Ȼ����浽����
//�뵱Ȼ�Ĵ���ͳ�����
QString strData = QString();
��������ͨ�������ֽ���취��
- Ҫ�����ݽ����ĶԷ�����֤���͵�buffer��������ԡ�\0����β��
- ����bufLen�ڱ��ؿ���+1��С�������ֱ��malloc+�ڴ棬Ȼ��ΪbufferCopy�����ʹ��bufferCopy����QString
�ص���ʼ������
FILE *__cdecl fopen(const char * restrict _Filename,const char * restrict _Mode);
���ڿ��Ի����ش�����������ˣ�_Filenameֻ����ϵͳ�����ʽ���ַ�������Qt��IDE�£��������������CodecForLocaleΪ��"System", ����������CodecForCStrings��cpp�ļ������ʽһ�£�ֻҪ����QString::toLocal8Bit().data(),�Ϳɵõ��ܱ�fopen��ȷ�ģ������ĵ��ļ�ȫ·����
���ǣ���ʱ�ò�����CodecForLocaleΪUTF-8,�磬���������ڴ����ʽҪ��Ϊutf-8�����������£������ܲ�̫��ÿ�ε�������fopen����ʱ������ʱ����CodecForLocaleΪ"System"������͵�ʹ�ö��ֽ�ת���ֽ��ˡ�Qtͨ��QString��QTextCodec����Ϊ���Ƿ�װ���˶�/խ�ֽڼ��ת����ֻҪ���������������½�����Щto�� from�� setCode�� etc.�������ɡ�
//������cpp��ͷ ������֮�� //��ֹ�������и澯
static QTextCodec *pcode = QTextCodec::codecForName("gbk"); //����
static QTextCodec *pcode = QTextCodec::codecForName("gb18030"); //Ч��ͬ��//�������еľ������
QString strTmp("F:/�й�����.txt");//��Ȼ����ʱ�������� //���Dz���������ֱ�Ӹ�ֵchar*
const char *pFileName = pcode->fromUnicode(strTmp).data();
qDebug() << strlen(pFileName); //15 //and fopen can ok
���������е�fromUnicode���������ã��е�����setCodecForLocale(����System��) + toLocal8Bit ��Ϻ�����ý������Qt�£����Ȳ�����������ForLocale(UTF-8)ʱ������������pcode�������������Ƽ��ת����
���ֽ�/���ֽ�ת��
������Qt��IDE�£��Ѿ��ò����Լ���ȥдת�������ˣ�ֻ���ڲ�����ܵĴ�C++�����У��ſ��ܻ��õ���������о��������ù��Ĵ��롣
//need
Qt��������-����
Here����Ҫ�����Qt���ɿ��������ģ�����qDebug() << qstringObj�� ��ֱ�����е�����£������������̨������ӡ���ģ�������Debug�����£�ȴ�ᱻ��ӡ�����룿��������Ѿ������Һþ��ˣ��������ַ�����һ����ֵĴ��룺
QString strTmp("F:/�����.txt");
qDebug() << strTmp;QTextCodec *pcode = QTextCodec::codecForName("gb18030"); //guobiao
const char *pFileName = pcode->fromUnicode(strTmp).data();
qDebug() << strlen(pFileName); FILE *outFile = fopen(pFileName, "rb");
if (NULL == outFile)qDebug() << "Can't open specified file absolute path!";
���������ڷǵ��������£�һ��������������Debug�����£�ȫ�����⣬����strTmp����ӡ�����룻�������е���һ�д���ʱ���澯can��t find linker symbol for virtual table for `QTextCodec�� value found `shadowWidth�� instead���ұ����鿴�������쳣�����鿴strTmpֵ������ֱ�ӵ������б�����fromUnicodeҲ����ʧ�ܣ�pFileName��ֵҲʧ�ܣ�ָ�뷶Χ��������Ȼ��ʧ�ܣ�
�ο��˺þ�ǰд�Ĵ��룬�ں�������cpp��ʼ�ĵط� ��д����static QTextCodec *pcode�� ���Խ��������ظ澯���⡣
��������
����C-FILE����
�Ѳ��ɣ�wchar.h �е�FILE��������������ֱ�ӽ���QString.c_str() ? (utf-8����)�������ԡ�
NotePad++�ڵĿ�
��ȷ��QtĬ���½����ļ���ʽ��uft-8��������Notepad���鿴��ʽ��ȴ��Ȼ��ʾ��"��ANSI��ʽ����"Ϊѡ��״̬������Ż����ˣ��Ѳ��ɽ���Ĺ��ڱ���IJ��ԣ���ϵͳ����ˣ��и��뷨�����£���QtCreateor��Ϊ����������һ������ע�ͣ��������ʱ��������NotePad���ļ��������ʾ����"��UTF-8 ��BOM��ʽ����"��
��һ���IJ������£��¼���һ����ͨ���ı��ĵ�1.txt����������abc�����档��QtCreator�£���һ��.h�ļ��У�����һ��ע�� //���Ȼ�档Ȼ����NotePad��.h�ļ�����������ʽΪANSI������Ϊ�����ע�ͣ�//你好���㵽���а塣Ȼ���1.txt�ı��ļ���ճ�������档������Notepad��1.txt�鿴������ʽ��Ҳ����UTF-8��ʽ���ҿ�����������ʾ�������²⣬NotePad���Զ�����һЩ��ʾ�������˴�û����ȥ����һ�����о�����Ҫ����Ŷ��