文章目录
- Sequential Games
-
- Markov Games
- 马尔科夫博弈中的强化学习
-
- 值迭代
- 策略迭代
- Sparse Interactions in Multi-agent System
-
- Learning on Multiple Levels
- Learning to Coordinate with Sparse Interactions
-
- Learning Interdependencies among Agents
- Learning a Richer State Space Representation
-
- Learning of Coordination
- Coordinating Q-Learning
Sequential Games
多智能体强化学习在有状态转移的环境中进行序列决策。马尔科夫博弈可以看做是MDP在多智能体条件下的扩展,和repeated games到多状态条件下的扩展。如果只有一个agent,马尔科夫博弈变成MDP,如果只有一个状态,马尔科夫博弈变成repeated normal game。
Markov Games
联合动作是多智能体独立选择动作的结果。


不同agent在同一个状态转移可能收到不一样的奖励。
与单agent RL的主要区别在于,现在这些标准还取决于其他agents的策略。

应该注意的是,在一个马尔可夫博弈中的学习在MDP中引入了一些新的关于正在学习的策略的学习问题。在MDP中,可以证明,在一些基本假设下,最优确定性策略始终存在。这意味着只考虑那些确定地将每个状态映射到一个动作的策略是有效的。然而,在马尔可夫博弈中,当我们必须考虑agents策略之间的平衡时,这不再适用。类似于repeated game的情形,一个折扣的马尔可夫博弈可能只有涉及随机策略的纳什均衡。因此,让agents将固定的行动映射到每个状态是不行的:他们必须能够学习混合策略。当考虑到其他奖励标准(如平均奖励)时,情况变得更加困难,因为在固定策略中可能不存在均衡(Gillette,1957年)。这意味着,为了达到一个平衡的结果,agents必须能够表达策略,这个策略根据整个学习过程的历史,在一个状态下选择动作。幸运的是,我们可以对问题的结构引入一些额外的假设,以确保平稳平衡的存在。
马尔科夫博弈中的强化学习
在normal form game中,强化学习者面临的挑战主要来源于agents之间的相互作用,而在马尔可夫博弈中,他们面临着状态转换环境的额外挑战。这意味着agents通常需要将repeated game中使用的协调方法或均衡解法与agent RL的MDP方法结合起来。
值迭代
将Q-learning成功应用于多智能体情境下需要解决许多关键问题:
- 即时奖励和转移概率依赖于所有agents的动作。agent根据别的agents选择的动作选择动作,更新估计的Q(s,a),a是联合动作。
- bootstrap时需要用到下个状态的最大Q(s,a),但agent不能预测自己在下个状态执行动作的值,因为这个值依赖于别的agents的值。下图是多智能体Q-learning的模板,不同方法在计算下个状态的值上有区别

确定状态期望值的第一种可能是使用opponent modeling,预测其他agents 的策略。例如 Joint Action Learner (JAL) ,记录状态s下其他agents使用这种联合动作的次数,然后计算它的频率:
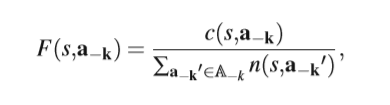
然后就能计算agent k在状态s下的期望值:
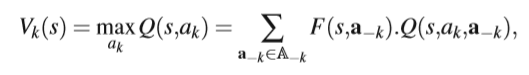
Q(s,ak)就是agent k执行动作ak,然后含有ak的联合动作的奖励的估计期望。
另一种是假设其他agents根据某种strategy操作。例如minimax Q-learning,针对两个agent的零和博弈,假设对手执行最小化learner收益的动作:
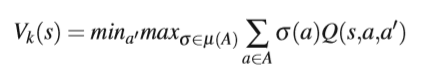
对手执行动作最小化q值,learner选择一个动作概率最大化期望,然后将所有动作的期望值加起来。(存疑)策略可以是混合策略。后来推广到friend-or-foe Q-learning ,要么是朋友帮助maximize,要么是foe来minimize。
还有是假设agents会执行均衡策略。例如Nash-Q,观察所有agents 的reward,保留所有agents Q值的估计,然后对于每个状态都有一个收益矩阵,这种表示叫做stage game,因为每个状态是一个博弈,阶段性的博弈。然后nash-q的agent假设所有的agents根据那个阶段的纳什均衡选动作:
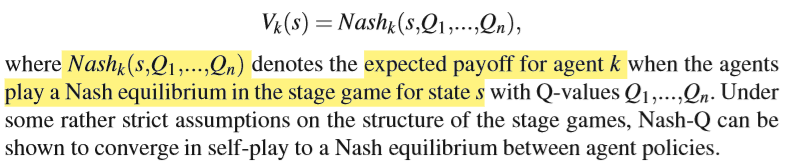
这个方法的均衡也能换成别的,但这个方法的问题在于多个均衡存在时,需要协作。
基于值迭代的MARL在一般马尔科夫博弈条件下的收敛结果依然难以解释。更进一步的是,最近的研究揭示了在任意一般和博弈仅依赖Q-values或许不能成功学到均衡策略,需要新方法的出现。
策略迭代
基于LA的Interconnected Learning Automata for Markov Games (MG-ILA) 可以被应用于平均奖励马尔科夫博弈,可以被看做actor-critic框架的实现,使用LA存储策略。主要思想很直接:每个agent k在每个状态si放一个LA(k,i),在每个时间步,只有当前状态的LA激活,每个LA独立为它对应的agent选择动作,联合动作出发状态转移和即时奖励,LA使用估计平均奖励的回应来更新,下面是完整算法:

结果表明,该算法在该博弈中将收敛到纯纳什均衡(如果存在),并且该均衡对应于agents策略之间的纯均衡。
Win or Learn Fast (WoLF) principle,结果不理想时加大梯度,快速逃离。
Sparse Interactions in Multi-agent System
在马尔可夫博弈中,强化学习的一个大缺点是agents学习的状态空间的大小。所有的agents在整个联合状态行动空间中学习,因此,除了最小的环境和有限数量的agents,这些方法很快就不可行了。最近,人们对缓解这一问题进行了大量的关注。这些方法的主要直觉是,只有当通过这样做可以获得更好的回报时,才明确地考虑其他agents。在所有其他情况下,可以安全地忽略其他代理,这类agents具有在小状态行动空间学习的优势,同时也可以访问必要的信息,以处理其他agents的存在(如果这是有益的)。这种系统的一个例子是自动化仓库,在那里,自动化引导车辆只有在彼此靠近时才需要相互考虑。我们可以区分两种不同的研究方向:agents可以根据所选择的行动来做出协调的决定,或者agents可以将注意力集中在其可支配的状态信息上,并了解何时观察其他agents的状态信息是有利的。
Learning on Multiple Levels
稀疏交互的想法是:一个agent什么时候经历来自另一个agent的影响?用来解决指数型增长的状态空间问题。将多智能体学习过程分两层:顶层学习什么时候有必要观察其他agents 的状态信息,选择是否要独立学习;底层包含独立学习时用的单agent的学习技术,和状态转移与奖励依赖其他agents当前的状态与动作时使用的多智能体技术。下图是框架的图解:
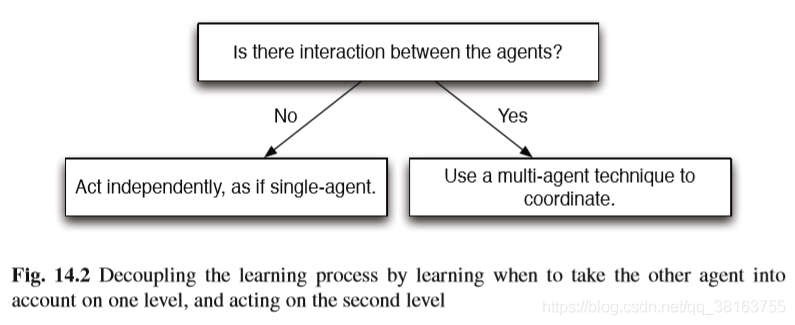
Learning to Coordinate with Sparse Interactions
Learning Interdependencies among Agents
Sparse Tabular Multiagent Q-learning 维护一个状态表,表中的状态有必要协作,在这些状态,agents选择联合动作,其他状态都独立选择动作。将状态表替换为协作图(CG),可以表示限于一些agents 的依赖,这叫Sparse Cooperative Q-learning (SCQ)。下图表示一个简单的CG:
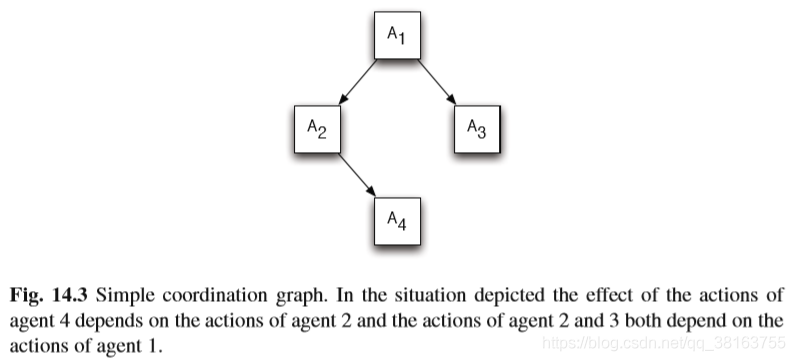
如果agents转移到了协作的状态,他们应用变量清除算法来计算当前状态下的最优联合动作。(这个算法不懂)
Utile Coordination使用和SCQ一样的想法,但不再是提前定义CG了,而是在线学习。这是通过维护有关基于其他agents的状态和行为获得的奖励的统计信息来实现的。因此,可以学习agents之间存在的特定上下文依赖性,并在CG中表示它们。然而,这种技术仅限于完全合作的MAS。
这些方法的首要目标是减少联合动作空间,但他们往往需要整个联合状态空间,因此学习的状态空间依然是指数型增长,这些方法仅限于可以观察整个联合状态空间的情况。
Learning a Richer State Space Representation
不再是具体学习最优联合动作,而是学习在哪些状态包含其他agents 的状态信息是有利的。有两种不同的方法,一个是使用RL学习在哪些状态协作是有利的,另一个是基于观测的奖励学习协作是有利的状态的集合。不像上一节里的方法,这些方法也能应用在冲突利益博弈,允许独立动作选择。下图是方法的整体思想,这些方法将扩展agent的局部状态信息来包含另一个agent的信息,如果这对于避免次优奖励是有必要的:
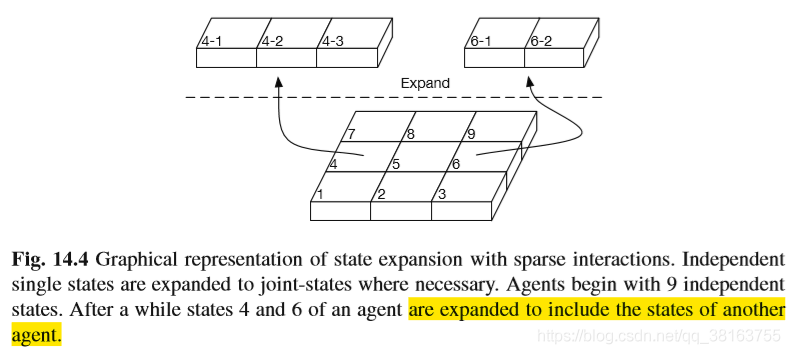
Learning of Coordination
使用**interaction-driven Markov games (IDMG)**作为不确定性下的多智能体决策的新模型。模型包含一个相互作用状态集合,列举了协作是有利的所有状态。为了学这个集合,在每个agent的动作空间增加一个伪协作动作(COORDINATE),这个动作执行一个主动感知步,可以是广播让其他agents透露他们的位置,或者是使用摄像机或传感器检测其他agents 的位置。主动感知步将决定协作是不是必要的。依靠主动感知步,这个算法可以用于协同或冲突利益系统。

Coordinating Q-Learning
CQ-learning学习哪些状态需要考虑其他agents的状态信息。算法可以被分为三个部分:
- Detecting con?ict situations
agent必须识别哪些状态受到至少一个别的agent的影响。如果agents相互影响,这将反映在agents一起行动时收到的回报。CQ-learning使用统计测试来检测所选状态-动作对观察到的奖励是否与他们单独在环境中行动的情况相比有所变化。两种情况可能出现:
1.1. 统计数据检测到了变化,这个状态是dangerous,agent的状态空间添加这个联合状态信息。该算法将首先尝试检测agent收到的奖励的变化,仅基于其自身的状态,然后再尝试确定这些变化是由哪些其他agents引起的。
1.2. 统计数据揭示agent收到的奖励与单独行动时收到的是同一个分布,继续单独行动。 - 选择动作
根据上一步的结果,如果dangerous,观察全局状态信息,如果其他agents的状态信息与之前检测到的一样,则根据全局信息选动作,否则独立选。 - 更新Q值
跟Learning of Coordination一样
这个算法中用的统计学测试是Student t-test 。这个检验可以确定两个样本总体的平均值相等的原假设是否成立,而另一个假设是样本总体的平均值不相等。在CQ学习中,该测试首先用于确定在哪些状态观察到的奖励与基于单个agent学习的预期奖励有显著差异的状态,并确定这些变化依赖于哪些其他代理的状态。下面是算法的形式化表达:

CQ-learning也能用于从需要协作的状态生成信息来获得状态独立的agents之间协作依赖的表示。这个信息可以被迁移到别的更复杂的任务环境。