ёХёХМӨЧгТҪБЖ·ҪПт,ДҝЗ°ФЪСРҫҝТҪБЖКөМеұк»ҜОКМв,ПаҪПУЪ№гТеЙПөДКөМеБҙҪУ(entity linking),І»ҙжФЪКөМеБҙҪУТ»°г»бҙжФЪөДТ»ҙК¶аТе(Entity Ambiguity)ОКМв,И·ЗРАҙЛө,ТҪБЖұкЧј»ҜХвҝйЧоЦчТӘөДОКМвКЗ¶аҙКН¬Те(Mention Variations),јҙН¬Т»ЦЦІЎ,Н¬Т»ЦЦТ©өИ»бУРРн¶аІ»Н¬өДұнҙп·ҪКҪ,ХвҫНКЗОТГЗТӘИҘҙҰАнөД,ИГ·ЗҪб№№»ҜөДКэҫЭКдИлҪшАҙ,ПИХТөҪmention,И»әуИҘKBАпХТөҪ¶ФУҰөДentityЧчОӘКдіц,јҙұкЧј»Ҝ.ҫЩёцАэЧУ,"ёРГ°"ҪшАҙ,Кдіц"ЙПәфОьөАёРИҫ".
ҝҙБЛІ»ЙЩВЫОД,ДҝЗ°ФЪ¶ФЖдЦРТ»ЖӘҪшРРіхМҪ,УРПл·ЁУРТЙОКҫНРҙіцАҙ,өұіЙ·ӯТлТІРР,ҙујТТ»ЖрСРҫҝ.
Title:<A Lightweight Neural Model for Biomedical Entity Linking>
ВЫОДЈәhttps://arxiv.org/abs/2012.08844
ҙъВлЈәhttps://github.com/tigerchen52/Biomedical-Entity-Linking
ВЫОДЛјВ··ЦИэІҪ:
Т»~ФӨҙҰАнЎЈ¶ФУпБПҝвЦРөДЛщУРmentionәН KB ЦРөДentityҪшРРФӨҙҰАнЈ¬К№ЛьГЗҫЯУРНіТ»өДёсКҪЎЈ
¶ю~әтСЎКөМеЙъіЙЎЈ¶ФУЪГҝёцmentionЈ¬ҙУKBЦРЙъіЙТ»ЧйәтСЎentityЎЈ
Иэ~rankingДЈРНЎЈ¶ФУЪГҝёцmentionј°ЖдәтСЎentityЈ¬К№УГЕЕГыДЈРН¶ФГҝ¶ФҪшРРЖА·ЦЈ¬Кдіцtopk
Т»~ФӨҙҰАн
ЛхРҙА©ід('DM'-'Diabetes Mellitus')
КэЧЦМж»»('VI'-'6')
KBФцЗҝ(ДГСөБ·јҜА©ідKB)
¶ю~әтСЎЙъіЙ
ОӘБЛјЖЛгmention M әНentity S Ц®јдөД·ЦКэЈ¬ОТГЗҪ«ЛьГЗЦРөДГҝТ»ёцІр·ЦОӘtokenЈ¬ M = {m1, m2, ..., |} әН S = {s1, s2, ...,
|}ЎЈ
ҫӯ№эembeddingәуtokenО¬¶ИКЗd*V,(embedding_dim*vocab_size*)
ҝјВЗ MәНSЦРІ»Н¬tokenЕЕРтөДҝЙДЬРФ,АыУГБЛУаПТПаЛЖ¶И(cosine similarity),¶ЁТеБЛТ»ёцAcosәҜКэ,№«КҪИзПВ:
Хвёц№«КҪЧчУГКЗХТөҪ¶ФУҰMЦРөДtoken УіЙдөҪSЦРөДЧоПаЛЖөДtoken
Іў·ө»ШУлёГУаПТПаЛЖ¶И.
ОӘБЛ·АЦ№УаПТПаЛЖ¶ИЗгПтУЪіӨОДұҫ(УаПТПаЛЖ¶ИЛЖәхККУГУЪ¶МОДұҫ°Ў,ФхГҙ»бЗгПтіӨОДұҫ?),ТФј°¶ИБҝ¶ФіЖ(metric symmetric,ХвёцОТІ»¶®),ЛщТФЙијЖБЛТ»ёцПаЛЖ¶И·ЦКэ, ұнҙпИзПВ:
№№ФміцАҙөДәтСЎјҜ ={ <E1, S1> Ј¬ <E2,S2>,...,<Ek,Sk>} ,ЖдЦР EiКЗmentionөД idЈ¬ SiКЗәтСЎentity.ХвёцјҜәП°ьә¬Гҝёцmention өДtopkёцәтСЎentity,Из№ыҙжФЪ·ЦКэөИУЪ 1өДәтСЎentityЈ¬ұрөДҫНЦұҪУpass.
Иэ~rankingДЈРН
ХыёцҪб№№ИзНј

ҙУПВөҪЙП:
word embedding:ҫШХу d*V, V КЗҙКұнҙуРЎ(vocab_size),d КЗҙКПтБҝО¬¶И(embedding_dim)
char embedding:ҪвҫцOOVОКМв,ҫНКЗҙУЧЦБЈ¶Иіц·ў,ІЙУГBi-lstmөДКдіцЧчОӘchar-levelөДұнХч.И»әуУлword embeddingКдіцЖҙҪУЧчОӘХыёцentityөДұнХч.
alignment fearture:¶ФЖлІгҪвҫцөДЖдКөҫНКЗЛіРтОКМв,ХвАпАыУГБЛТ»ёцЧўТвБҰҫШХу(attention martrix),ЙијЖТ»ёцО¬¶И|M|*|S| өДИЁЦШҫШХу W Ј¬ұнКҫmention өД
УлentityөД
өДПаЛЖ¶И,
,ФЪW өДГҝТ»РРЙПУГsoftmax әҜКэ№йТ»»ҜЈ¬ІъЙъТ»ёцРВөДҫШХу W '
¶ЁТеmentionөДөЪ i ёц tokenПтБҝ Ј¬ЛьКЗ S ЦРtokenөДПтБҝЦ®әНЈ¬ИЁЦШОӘЖдУл
өДПаЛЖ¶И:
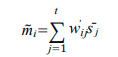
ЦчТӘК№УГ S ЦРУл
ПаЛЖөДПтБҝПајУАҙЦШ№№
Ј¬Из№ыЦШҪЁіЙ№Ұ(јҙ
Ул
ПаЛЖ)Ј¬Фт S °ьә¬Ул
ПаН¬өДРЕПў
ОӘБЛәвБҝХвЦЦПаЛЖРФЈ¬К№УГТФПВБҪёцұИҪПәҜКэ:
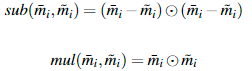
![]() ұнКҫЦрФӘЛШПаіЛ
ұнКҫЦрФӘЛШПаіЛ
sub УлЕ·КПҫаАлПаЛЖЈ¬mul Ул УаПТПаЛЖ¶ИПаЛЖ
Чоәу,УРБЛРВөД¶ЁТе
![]()
АаҙЛ,ҝЙТФІъЙъ
![]()
CNNІг :ПЦФЪmentionәНentityУРБЛРВөДұнКҫ,![]()
![]()
ЦұҪУЙПТ»Ігcnn
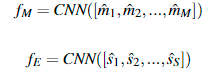
әПІўОӘТ»ёцКдіц: ![]()
КдіцІгЎЈК№УГБҪІгИ«Б¬ҪУЙсҫӯНшВз
![]()
ЖдЦРW2 әНW1КЗС§П°өДИЁЦШҫШХ󣬶ш b1 әН b2КЗЖ«ІоЦөЎЈ
ПИРҙөҪХвАп,әуГжУРРВөДАнҪвәН·ӯТлФЩёьРВ,2021Дк12ФВ22ИХ18:31:08