- Squeeze-and-Excitation NetworksŁ¨SENetŁŠĘÇÓÉ×ÔśŻźÝĘťšŤËžMomentaÔÚ2017Äꚍ˛źľÄŇťÖÖČŤĐÂľÄÍźĎńĘśąđ˝áššŁŹËüͨšýśÔĚŘŐ÷ͨľŔźäľÄĎŕšŘĐÔ˝řĐĐ˝¨ÄŁŁŹ°ŃÖŘŇŞľÄĚŘŐ÷˝řĐĐÇżťŻŔ´ĚáÉýןȡÂĘĄŁŐâ¸ö˝áššĘÇ2017 ILSVRžşČüľÄšÚžüŁŹtop5ľÄ´íÎóÂĘ´ďľ˝ÁË2.251%ŁŹąČ2016ÄęľÄľÚŇťĂűťšŇŞľÍ25%ŁŹżÉνĚáÉýžŢ´óĄŁ
- Squeeze-and-Excitation(SE) block˛˘˛ťĘÇŇť¸öÍęŐűľÄÍřÂç˝áššŁŹśřĘÇŇť¸ö×ӽᚚŁŹżÉŇÔÇśľ˝ĆäËűˇÖŔŕťňźě˛âÄŁĐÍÖĐ
- SENetľÄşËĐÄËźĎëÔÚÓÚͨšýÍřÂç¸ůžÝlossȼѧϰĚŘŐ÷ȨÖŘŁŹĘšľĂÓĐЧľÄfeature mapȨÖŘ´óŁŹÎŢЧťňЧšűĐĄľÄfeature mapȨÖŘĐĄľÄˇ˝Ę˝ŃľÁˇÄŁĐÍ´ďľ˝¸üşĂľÄ˝ášűĄŁ
- ÂŰÎÄľŘÖˇŁşhttps://arxiv.org/abs/1709.01507
- ´úÂ룺https://github.com/hujie-frank/SENet
- PyTorch´úÂëľŘÖˇŁşhttps://github.com/miraclewkf/SENet-PyTorch
Ěáłö
˝üĐŠÄęŔ´ŁŹžíťýÉńžÍřÂçÔںܜŕÁěÓňÉĎśźČĄľĂÁ˞޴óľÄÍťĆĆĄŁśřžíťýşË×÷ÎŞžíťýÉńžÍřÂçľÄşËĐÄŁŹÍ¨łŁąťż´×öĘÇÔÚžÖ˛ż¸ĐĘÜŇ°ÉĎŁŹ˝ŤżŐźäÉĎŁ¨spatialŁŠľÄĐĹϢşÍĚŘŐ÷ÎŹśČÉĎŁ¨channel-wiseŁŠľÄĐĹϢ˝řĐОۺϾÄĐĹϢžŰşĎĚ奣žíťýÉńžÍřÂçÓÉҝϾÁĐžíťý˛ăĄ˘ˇÇĎßĐÔ˛ăşÍĎ²ÉŃů˛ăššłÉŁŹŐâŃůËüĂÇÄÜšť´ÓČŤžÖ¸ĐĘÜŇ°ÉĎČĽ˛śťńÍźĎńľÄĚŘŐ÷Ŕ´˝řĐĐÍźĎńľÄĂčĘöĄŁ
ÔÚżŐźäÎŹśČÉĎĚáÉýÍřÂçĐÔÄÜľÄĚ˝Ë÷
ѧľ˝Ňť¸öĐÔÄܡdzŁÇżž˘ľÄÍřÂçĘÇĎŕľąŔ§ÄѾģŹĆäÄŃľăŔ´×ÔÓںܜࡽĂ楣Óкܶ๤×÷ĚáłöŔ´´ÓżŐźäÎŹśČ˛ăĂćŔ´ĚáÉýÍřÂçľÄĐÔÄÜŁŹČç Inception ˝áššÖĐÇśČëÁËśŕłßśČĐĹϢŁŹžŰşĎśŕÖÖ˛ťÍŹ¸ĐĘÜŇ°ÉĎľÄĚŘŐ÷Ŕ´ťńľĂĐÔÄÜÔöŇ棝ÔÚ Inside-Outside ÍřÂçÖĐżźÂÇÁËżŐźäÖĐľÄÉĎĎÂÎÄĐĹϢŁťťšÓĐ˝Ť Attention ťúÖĆŇýČëľ˝żŐźäÎŹśČÉĎŁŹľČľČŐâĐŠš¤×÷śźťńľĂÁËĎŕľą˛ť´íľÄłÉšűĄŁ
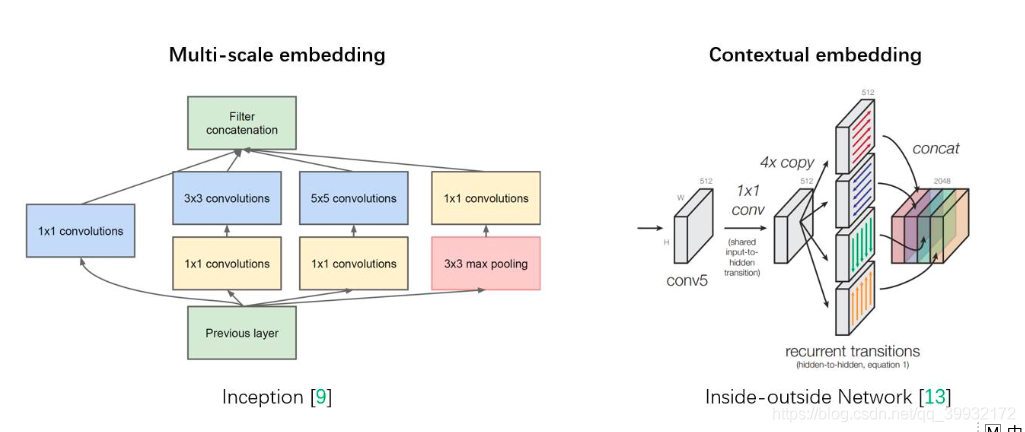
ĚáłöSENetľÄśŻťú
ŇÔÉĎš¤×÷śźĘÇ´ÓżŐźäÎŹśČÉĎŔ´ĚáÉýÍřÂçľÄĐÔÄÜĄŁÄÇĂ´şÜ×ÔČťĎëľ˝ŁŹÍřÂçĘǡńżÉŇÔ´ÓĆäËű˛ăĂćŔ´żźÂÇČĽĚáÉýĐÔÄÜŁŹąČČçżźÂÇĚŘŐ÷ͨľŔÖŽźäľÄšŘĎľŁżËůŇÔťůÓÚŐâŇťľăşú˝ÜľČČËąăĚáłöÁË Squeeze-and-Excitation NetworksŁ¨źňłĆ SENetŁŠĄŁËűĂǾĜŻťúĘÇĎŁÍűĎÔĘ˝ľŘ˝¨ÄŁĚŘŐ÷ͨľŔÖŽźäľÄĎ໥ŇŔŔľšŘĎľĄŁÁíÍ⣏˛˘˛ť´ňËăŇýČëŇť¸öĐ¾Ŀ՟äÎŹśČŔ´˝řĐĐĚŘŐ÷ͨľŔźäľÄČںϣŹśřĘDzÉÓĂÁËŇťÖÖČŤĐ¾ĥ¸ĚŘŐ÷ÖعꜨĄš˛ßÂÔĄŁžßĚĺŔ´ËľŁŹžÍĘÇͨšýѧϰľÄˇ˝Ę˝Ŕ´×ÔśŻťńČĄľ˝Ăż¸öĚŘŐ÷ͨľŔľÄÖŘŇŞłĚśČŁŹČťşóŇŔŐŐŐâ¸öÖŘŇŞłĚśČČĽĚáÉýÓĐÓĂľÄĚŘŐ÷˛˘ŇÖÖĆśÔľąÇ°ČÎÎńÓĂ´Ś˛ť´óľÄĚŘŐ÷
Squeeze-and-ExcitationÄŁżé
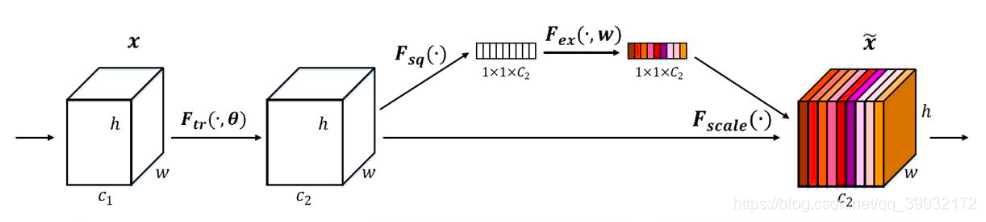
ÉĎÍźĘÇ SE ÄŁżéľÄĘžŇâÍźĄŁ¸řś¨Ňť¸öĘäČë xŁŹĆäĚŘŐ÷ͨľŔĘýÎŞ c_1ŁŹÍ¨šýҝϾÁĐžíťýľČŇť°ăąäťťşóľĂľ˝Ňť¸öĚŘŐ÷ͨľŔĘýÎŞ c_2 ľÄĚŘŐ÷ĄŁÓë´ŤÍłľÄ CNN ˛ťŇťŃůľÄĘÇŁŹ˝ÓĎÂŔ´Í¨šýČý¸ö˛Ů×÷Ŕ´ÖعꜨǰĂćľĂľ˝ľÄĚŘŐ÷ĄŁ
1.Squeeze ˛Ů×÷
Ňť°ăCNNÖĐľÄĂż¸öͨľŔѧϰľ˝ľÄÂ˲¨Ć÷śźśÔžÖ˛ż¸ĐĘÜŇ°˝řĐвŮ×÷ŁŹŇň´ËĂż¸öfeature mapśźÎޡ¨ŔűÓĂĆäËüfeature mapľÄÉĎĎÂÎÄĐĹϢŁŹśřÇŇÍřÂç˝ĎľÍľÄ˛ă´ÎÉĎĆä¸ĐĘÜŇ°łß´çśźĘÇşÜĐĄľÄŁŹŐâŃůÇéżöžÍťá¸üŃĎÖŘĄŁ
Squeeze ˛Ů×÷ĘÇĘ×ĎČËł×ĹżŐźäÎŹśČŔ´˝řĐĐĚŘŐ÷ŃšËőŁŹ˝ŤĂż¸öśţÎŹľÄĚŘŐ÷ͨľŔąäłÉŇť¸öĘľĘýŁŹŐâ¸öĘľĘýÄłÖֳ̜ČÉĎžßÓĐČŤžÖľÄ¸ĐĘÜŇ°ŁŹ˛˘ÇŇĘäłöľÄÎŹśČşÍĘäČëľÄĚŘŐ÷ͨľŔĘýĎŕĆĽĹ䥣ËüąíŐ÷×ĹÔÚĚŘŐ÷ͨľŔÉĎĎěÓŚľÄČŤžÖˇÖ˛źŁŹśřÇŇĘšľĂżż˝üĘäČëľÄ˛ăҲżÉŇÔťńľĂČŤžÖľÄ¸ĐĘÜŇ°ŁŹŐâŇťľăÔںܜŕČÎÎńÖĐśźĘǡdzŁÓĐÓþĥŁ
Ę×ĎČFtrŐâŇť˛˝ĘÇתťť˛Ů×÷Ł¨Ńϸń˝˛˛˘˛ťĘôÓÚSENetŁŹśřĘÇĘôÓÚÔÍřÂ磏żÉŇÔż´şóĂćSENetşÍInceptionź°ResNetÍřÂçľÄ˝áşĎŁŠŁŹÔÚÎÄÖĐžÍĘÇŇť¸öąęןľÄžíťý˛Ů×÷śřŇŃŁŹĘäČëĘäłöľÄś¨ŇĺČçĎÂąíĘžŁş
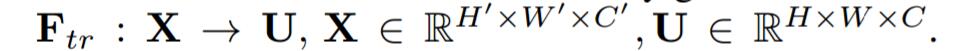
ÄÇĂ´Őâ¸öFtrľÄšŤĘ˝žÍĘÇĎÂĂćľÄšŤĘ˝Ł¨žíťý˛Ů×÷ŁŹvcąíĘžľÚc¸öžíťýşËŁŹxsąíĘžľÚs¸öĘäČ룊ĄŁ
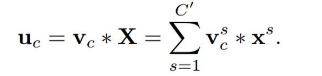
FtrľĂľ˝ľÄUžÍĘÇFigure1ÖĐľÄ×óąßľÚśţ¸öČýÎŹžŘŐóŁŹŇ˛˝ĐtensorŁŹťňŐß˝ĐC¸ö´óĐĄÎŞH*WľÄfeature mapĄŁśřucąíĘžUÖĐľÚc¸öśţÎŹžŘŐóŁŹĎÂąęcąíĘžchannelĄŁ
˝ÓĎÂŔ´žÍĘÇSqueeze˛Ů×÷ŁŹšŤĘ˝ˇÇłŁźňľĽŁŹžÍĘÇŇť¸öglobal average pooling:
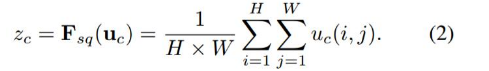
Ňň´ËšŤĘ˝2žÍ˝ŤH*W*CľÄĘäČëתťťłÉ1*1*CľÄĘäłöŁŹśÔÓŚFigure1ÖĐľÄFsq˛Ů×÷ĄŁÎŞĘ˛Ă´ťáÓĐŐâŇť˛˝ÄŘŁżŐâŇť˛˝ľÄ˝ášűĎŕľąÓÚąíĂ÷¸Ă˛ăC¸öfeature mapľÄĘýÖľˇÖ˛źÇéżöŁŹťňŐß˝ĐČŤžÖĐĹϢĄŁ
2.Excitation ˛Ů×÷
ËüĘÇŇť¸öŔŕËĆÓÚŃťˇÉńžÍřÂçÖĐĂžĝúÖĆĄŁÍ¨šý˛ÎĘý w Ŕ´ÎŞĂż¸öĚŘŐ÷ͨľŔÉúłÉȨÖŘŁŹĆäÖвÎĘý w ąťŃ§Ď°ÓĂŔ´ĎÔĘ˝ľŘ˝¨ÄŁĚŘŐ÷ͨľŔźäľÄĎŕšŘĐÔĄŁ
Č皍ʽ3ĄŁÖą˝Óż´×îşóŇť¸öľČşĹŁŹÇ°ĂćsqueezeľĂľ˝ľÄ˝ášűĘÇzŁŹŐâŔďĎČÓĂW1łËŇÔzŁŹžÍĘÇŇť¸öČŤÁŹ˝Ó˛ă˛Ů×÷ŁŹW1ľÄÎŹśČĘÇC/r * CŁŹŐâ¸örĘÇŇť¸öËőˇĹ˛ÎĘýŁŹÔÚÎÄÖĐČĄľÄĘÇ16ŁŹŐâ¸ö˛ÎĘýľÄÄżľÄĘÇÎŞÁËźőÉŮchannel¸öĘý´Óśř˝ľľÍźĆËăÁżĄŁÓÖŇňÎŞzľÄÎŹśČĘÇ1*1*CŁŹËůŇÔW1zľÄ˝ášűžÍĘÇ1*1*C/rŁťČťşóÔŮžšýŇť¸öReLU˛ăŁŹĘäłöľÄÎŹśČ˛ťąäŁťČťşóÔŮşÍW2ĎŕłËŁŹşÍW2ĎŕłËҲĘÇŇť¸öČŤÁŹ˝Ó˛ăľÄšýłĚŁŹW2ľÄÎŹśČĘÇC*C/rŁŹŇň´ËĘäłöľÄÎŹśČžÍĘÇ1*1*CŁť×îşóÔŮžšýsigmoidşŻĘýŁŹľĂľ˝sĄŁ
![]()
ҲžÍĘÇËľ×îşóľĂľ˝ľÄŐâ¸ösľÄÎŹśČĘÇ1*1*CŁŹCąíĘžchannelĘýÄżĄŁŐâ¸ösĆäĘľĘÇąžÎľĺËĐÄŁŹËüĘÇÓĂŔ´żĚťtensor UÖĐC¸öfeature mapľÄȨÖŘĄŁśřÇŇŐâ¸öȨÖŘĘÇͨšýÇ°ĂćŐâĐŠČŤÁŹ˝Ó˛ăşÍˇÇĎßĐÔ˛ăѧϰľĂľ˝ľÄŁŹŇň´ËżÉŇÔend-to-endŃľÁˇĄŁŐâÁ˝¸öČŤÁŹ˝Ó˛ăľÄ×÷ÓĂžÍĘÇČںϸ÷ͨľŔľÄfeature mapĐĹϢŁŹŇňÎŞÇ°ĂćľÄsqueeześźĘÇÔÚÄł¸öchannelľÄfeature mapŔďĂć˛Ů×÷ĄŁ
3.Reweight ˛Ů×÷
˝Ť Excitation ľÄĘäłöľÄȨÖŘż´×÷ĘÇžšýĚŘŐ÷ŃĄÔńşóľÄĂż¸öĚŘŐ÷ͨľŔľÄÖŘŇŞĐÔŁŹČťşóͨšýłËˇ¨ÖđͨľŔźÓȨľ˝ĎČÇ°ľÄĚŘŐ÷ÉĎŁŹÍęłÉÔÚͨľŔÎŹśČÉϾĜÔÔĘźĚŘŐ÷ľÄÖعꜨĄŁ
Ôھþ˝sÖŽşóŁŹžÍżÉŇÔśÔÔŔ´ľÄtensor U˛Ů×÷ÁËŁŹžÍĘÇĎÂĂćľÄšŤĘ˝4ĄŁŇ˛şÜźňľĽŁŹžÍĘÇchannel-wise multiplicationŁŹĘ˛Ă´ŇâËźÄŘŁżucĘÇŇť¸öśţÎŹžŘŐóŁŹscĘÇŇť¸öĘýŁŹŇ˛žÍĘÇȨÖŘŁŹŇň´ËĎŕľąÓÚ°ŃucžŘŐóÖĐľÄĂż¸öÖľśźłËŇÔscĄŁśÔÓŚFigure1ÖĐľÄFscaleĄŁ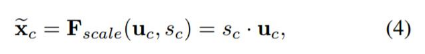
×Ü˝á
- ĎŕľąÓÚĎČ˝ŤinputŁ¨h*w*cŁŠŃŘ×Ĺsizeˇ˝ĎňžšýSqueeze˛Ů×÷ąäłÉ(1*1*c)
- ÔŮžšýExcitationŐâŇť˛˝Ń§ľ˝Ňť¸öȨÖŘW
- ×îşó¸ůžÝѧľ˝ľÄȨÖŘW ÔŮžšýscale˛Ů×÷ąäłÉŁ¨h*w*cŁŠľÄoutput
żÉŇÔż´łöŁŹinputşÍOutputľÄshapeĘÇŇťŃůľÄŁŹľŤĘÇĂż¸öÎťÖĂÉĎľÄ־ȴĘÇžšýÖŘĐ¹ꜨľÄŁŹĘľźĘÉĎÖąšŰľŘż´Őâ¸öÍřÂçBLOCK ÓŚ¸ĂťáĚáÉýĐÔÄÜŁŹŇňÎŞźŮÉčWĘÇidentityÄÇĂ´žÍĘÇÔŔ´ľÄÇéżöŁŹŐâŔďľÄËźĎëÓĐľăĎńResduialŔďľÄĎ롨ŁŹžÍĘÇÓĐŇťĚő¡żÉŇÔąŁÖ¤˛ťąäŁŹČťşóÁíÍâŇťĚő¡śŕÉŮżÉŇÔѧľ˝ŇťĐŠŁŹËůŇԾþ˝ľÄÍřÂçĘÇÓĐĚáÉýľÄ
SEÄŁżéľÄÓŚÓĂ
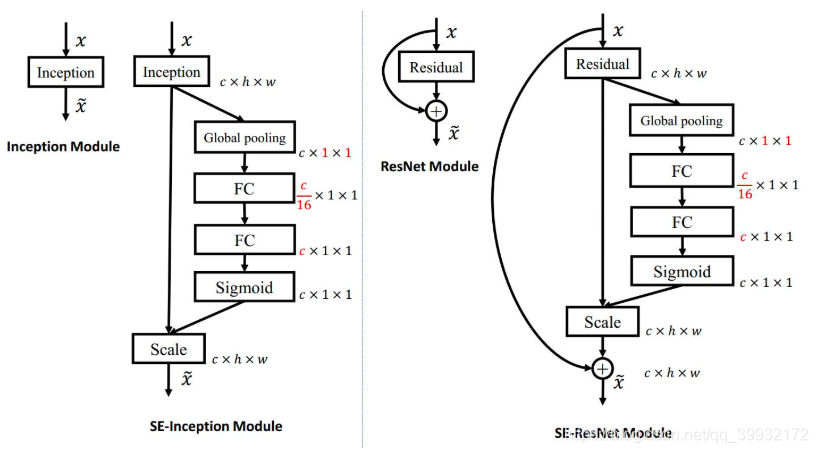
ˇ˝żňĹÔąßľÄÎŹśČĐĹϢ´úąí¸Ă˛ăľÄĘäłöĄŁ
1. ˝ŤSEÄŁżéÇśČëľ˝ Inception ˝áššÖĐŁ¨ÉĎ×óÍźŁŠ
ŐâŔďĘšÓĂ global average pooling ×÷ÎŞ Squeeze ˛Ů×÷ĄŁ˝ô˝Ó×ĹÁ˝¸ö Fully Connected ˛ă×éłÉŇť¸ö Bottleneck ˝áššČĽ˝¨ÄŁÍ¨ľŔźäľÄĎŕšŘĐÔŁŹ˛˘ĘäłöşÍĘäČëĚŘŐ÷ÍŹŃůĘýÄżľÄȨÖŘĄŁĘ×ĎČ˝ŤĚŘŐ÷ÎŹśČ˝ľľÍľ˝ĘäČëľÄ 1/16ŁŹČťşóžšý ReLu ź¤ťîşóÔŮͨšýŇť¸ö Fully Connected ˛ăÉýťŘľ˝ÔŔ´ľÄÎŹśČĄŁŐâŃů×öąČÖą˝ÓÓĂŇť¸ö Fully Connected ˛ăľÄşĂ´ŚÔÚÓÚŁş
- žßÓиüśŕľÄˇÇĎßĐÔŁŹżÉŇÔ¸üşĂľŘÄâşĎͨľŔźä¸´ÔÓľÄĎŕšŘĐÔ
- źŤ´óľŘźőÉŮÁ˲ÎĘýÁżşÍźĆËăÁżĄŁ
ČťşóͨšýŇť¸ö Sigmoid ľÄĂĹťńľĂ 0~1 ÖŽźäšéŇťťŻľÄȨÖŘŁŹ×îşóͨšýŇť¸ö Scale ľÄ˛Ů×÷Ŕ´˝ŤšéŇťťŻşóľÄȨÖŘźÓȨľ˝Ăż¸öͨľŔľÄĚŘŐ÷ÉĎĄŁ
śŕ¸öfeature mapżÉŇÔąť˝âĘÍÎŞžÖ˛żĂčĘö×ӾğŻşĎŁŹŐâĐŠĂčĘö×ÓľÄÍłźĆĐĹϢśÔÓÚŐű¸öÍźĎńŔ´ËľĘÇÓĐąíĎÖÁŚľÄĄŁŐâŔďŃĄÔń×îźňľĽľÄČŤžÖĆ˝žůłŘťŻ˛Ů×÷ŁŹ´ÓśřĘšĆäžßÓĐČŤžÖľÄ¸ĐĘÜŇ°ŁŹĘšľĂÍřÂçľÍ˛ăҲÄÜŔűÓĂČŤžÖĐĹϢĄŁ
2.˝ŤSEÄŁżéÇśČëľ˝ ResNet ÄŁżéÖĐŁ¨ÉĎÓŇÍźŁŠ
łýÁËÉĎĂćżÉŇÔ˝ŤSEÄŁżéÇśČëľ˝ Inception ˝áššÖĐÍ⣏SE ÄŁżéťšżÉŇÔÇśČëľ˝şŹÓĐ skip-connections ľÄÄŁżéÖĐĄŁ˛Ů×÷šýłĚťůąžşÍ SE-Inception ŇťŃůŁŹÖť˛ťšýĘÇÔÚ Addition Ç°śÔˇÖÖ§ÉĎ Residual ľÄĚŘŐ÷˝řĐĐÁËĚŘŐ÷ÖعꜨĄŁČçšűśÔ Addition şóÖ÷Ö§ÉĎľÄĚŘŐ÷˝řĐĐÖعꜨŁŹÓÉÓÚÔÚÖ÷¸ÉÉĎ´ćÔÚ 0~1 ľÄ scale ˛Ů×÷ŁŹÔÚÍřÂç˝ĎÉî BP ÓĹťŻĘąžÍťáÔÚżż˝üĘäČë˛ăČÝŇ׳öĎÖĚÝśČĎűɢľÄÇéżöŁŹľźÖÂÄŁĐÍÄŃŇÔÓĹťŻĄŁ
´óśŕĘýľÄÖ÷Á÷ÍřÂçśźĘÇťůÓÚŐâÁ˝ÖÖŔŕËƾľĽÔŞÍ¨šý repeat ˇ˝Ę˝ľţźÓŔ´ššÔěľÄĄŁÓɴ˿ɟűŁŹSE ÄŁżéżÉŇÔÇśČëľ˝ĎÖÔÚź¸şőËůÓĐľÄÍřÂç˝áššÖĐĄŁÍ¨šýÔÚÔĘźÍřÂç˝áššľÄ building block ľĽÔŞÖĐÇśČë SE ÄŁżéŁŹÎŇĂÇżÉŇÔťńľĂ˛ťÍŹÖÖŔŕľÄ SENetĄŁČç SE-BN-InceptionĄ˘SE-ResNetĄ˘SE-ReNeXtĄ˘SE-Inception-ResNet-v2 ľČľČĄŁ
źĆËăÁżąČ˝Ď

´ÓÇ°ĂćľÄ˝éÉÜżÉŇÔż´łöÔöźÓľÄ˛ÎĘýÖ÷ŇŞŔ´×ÔÁ˝¸öČŤÁŹ˝Ó˛ăŁŹÁ˝¸öČŤÁŹ˝Ó˛ăľÄÎŹśČśźĘÇC/r * CŁŹÄÇĂ´ŐâÁ˝¸öČŤÁŹ˝Ó˛ăľÄ˛ÎĘýÁżžÍĘÇ2*C^2/rĄŁŇÔResNetÎŞŔýŁŹźŮÉčResNetŇťš˛°üşŹS¸östageŁŹĂż¸öStage°üşŹN¸öÖظ´ľÄresidual blockŁŹÄÇĂ´Őű¸öĚíźÓÁËSE blockľÄResNetÔöźÓľÄ˛ÎĘýÁżžÍĘÇĎÂĂćľÄšŤĘ˝Łş
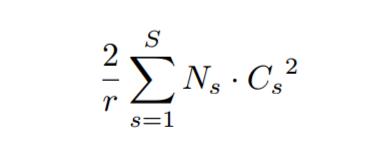
´ÓÉĎĂćľÄ˝éÉÜÖĐżÉŇÔˇ˘ĎÖŁŹSENet ššÔěˇÇłŁźňľĽŁŹśřÇŇşÜČÝŇ׹ť˛żĘ𣏲ťĐčŇŞŇýČëĐ¾ĺŻĘýťňŐ߲㥣łý´ËÖŽÍ⣏ËüťšÔÚÄŁĐͺ͟ĆË㸴ÔÓśČÉĎžßÓĐÁźşĂľÄĚŘĐÔĄŁÄĂ ResNet-50 şÍ SE-ResNet-50 śÔąČžŮŔýŔ´ËľŁŹSE-ResNet-50 ĎŕśÔÓÚ ResNet-50 ÓĐ×Ĺ 10% ÄŁĐͲÎĘýľÄÔöł¤ĄŁśîÍâľÄÄŁĐͲÎĘýśź´ćÔÚÓÚ Bottleneck ÉčźĆľÄÁ˝¸ö Fully Connected ÖĐŁŹÓÉÓÚ ResNet ˝áššÖĐ×îşóŇť¸ö stage ľÄĚŘŐ÷ͨľŔĘýĿΪ 2048ŁŹľźÖÂÄŁĐͲÎĘýÓĐ׎ϴóľÄÔöł¤ŁŹĘľŃ顢ĎÖŇĆłýľô×îşóŇť¸ö stage ÖĐ 3 ¸ö build block ÉĎľÄ SE É蜨ŁŹżÉŇÔ˝Ť 10% ˛ÎĘýÁżľÄÔöł¤źőÉŮľ˝ 2%ĄŁ´ËʹģĐ;ĞŤśČź¸şőÎŢËđʧĄŁ
˛Îżź˛ŠżÍ
https://blog.csdn.net/Evan123mg/article/details/80058077
https://blog.csdn.net/zhangjunhit/article/details/77882406
https://blog.csdn.net/Evan123mg/article/details/80058077