这篇文章中我会通过几个例子向大家介绍一些weka中经典的数据挖掘算法和评估算法的手段。
J4.8 决策树算法
在预处理标签页 点击 open file ,选择 Weka 安装目录下 data 文件夹中的 weather.numberic.arff 。(在这个目录中有很多经典的样本)
进入分类器标签,点击 Choose 按钮,开始选择分类器算法。在弹出的树状目录中找到 trees 节点,打开它,选择 J48 算法。验证方式选择 10折交叉验证。点击 Start 开始分类。
J4.8算法是著名的决策树算法C4.5的一个改进版,也是最后一个免费版本。选完这个算法后可以看到weka对J48算法赋予了默认参数:-C 0.25 -M 2。前者是用于剪枝的置信因子,后者指定了每个叶结点最小的实例数。详见:http://blog.csdn.net/buaalei/article/details/7105965。
运行完成后可以在 output 界面查看结果。
outlook = sunny
| humidity <= 75: yes (2.0)
| humidity > 75: no (3.0)
outlook = overcast: yes (4.0)
outlook = rainy
| windy = TRUE: no (2.0)
| windy = FALSE: yes (3.0)在 output 版面的最后可以看到一些 高级的统计数据,如下图:
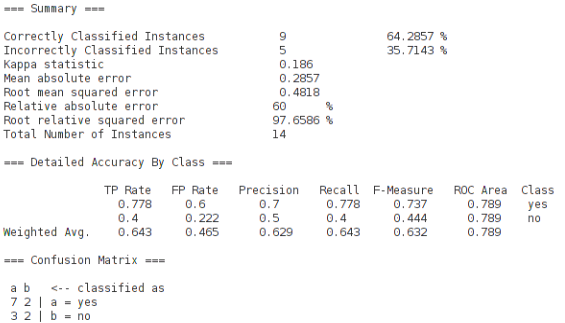
我们一个一个解释:
Kappa statistic:
这个参数是把分类器与随机分类器作比较得出的一个对分类器的评价值。那么0.186是怎么计算出来的呢?
从output 版面的最下面的 confusion matrix(混淆矩阵)中,我们发现分类器把10个实例预测成了a情况(其中7对3错),4个实例预测成了b情况(2对2错)。如果换做一个随机分类器,也把10个实例预测成了a,4个实例预测成了b,那么该随机分类器的预测准确情况会是什么样的?按照概率分布,正确地预测a的概率为9/14,正确地预测b的概率为5/14。所以该分类器能准确预测的实例个数为 10×(9/14)+4×(5/14)=110/14≈7.85。Kappa=(9-7.85)÷(14-7.85)≈0.186
Mean absolute error 和 Root mean squared error:
平均绝对误差,用来衡量分类器预测值和实际结果的差异,越小越好。
Relative absolute error 和 Root relative squared error:
举个例子来说明:实际值为500,预测值为450,则绝对误差为50;实际值为2,预测值为1.8,则绝对误差为0.2。这两个数字50和0.2差距很大,但是表示的误差率同为10%,所以有时绝对误差不能体现误差的真实大小,而相对误差通过体现误差占真值的比重来反映误差大小,效果更佳。
详见:http://www.doc88.com/p-89192423133.html
TP,FP:
Precision:
Recall:
召回率,又称查全率。表示识别正确的实例数,占该类别的实例的总数。由于本例中没有未识别的实例,所以Recall=TP。