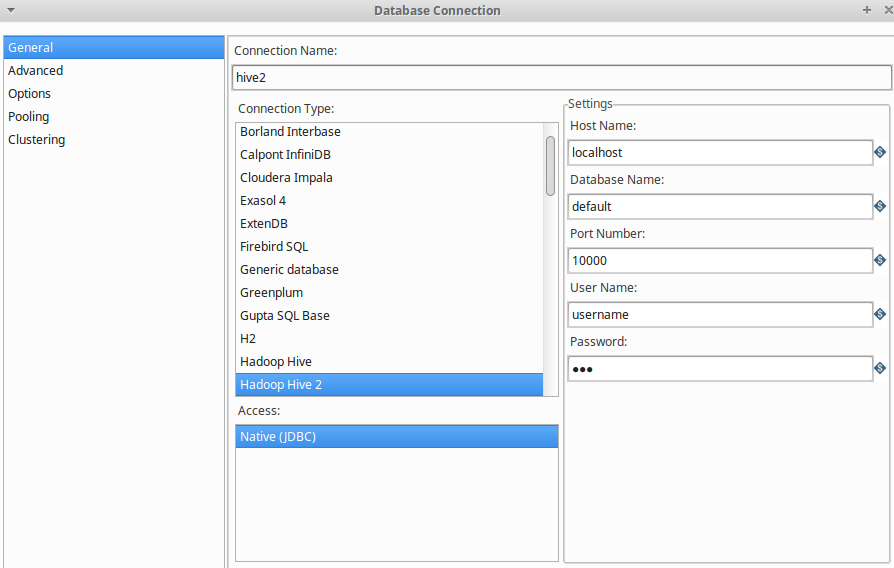
复制驱动:
- 首先在Hive的安装目录里找到Hive的jdbc jar文件. 比如 hive/apache-hive-2.3.2-bin/jdbc/hive-jdbc-2.3.2-standalone.jar.
- 复制这个jar文件到Kettle的lib目录下, 比如 /Kettle/data-integration/lib/
- 重启Kettle
Hadoop权限设置:
参考:https://blog.csdn.net/u012948976/article/details/49904675
https://blog.csdn.net/u012948976/article/details/49904675
Hadoop使用代理机制, 在hadoop的core-site.xml中添加如下代码:
<property> <name>hadoop.proxyuser.super.hosts</name> <value>*</value>
</property>
<property> <name>hadoop.proxyuser.super.groups</name> <value>*</value>
</property> 意思是允许任意主机(第一个*)的任意组((第二个*))的用户使用super这个帐号来访问集群.即所谓i的impersonate模式.
这种impersonate模式类似 ubuntu中常用的 sudo, 能让普通账户, 例如user1 , 获取super这个帐号(管理员)的权限, 并执行操作. 但在系统执行日志中, user1并不会被super覆盖, 而是仍然会被记录user1提交了job.
启动hive 服务器模式:
hive --service hiveserver2Thrift模式的服务器会被启动, 默认端口10000