【摘要】
全量预汇总真的是提高 OLAP 性能的可行方案吗?点击了解OLAP 服务器,空间换时间可行吗?
多维分析提供拖拽、旋转、切片、钻取等等人机交互操作,必须有秒级的响应速度。而这些操作对应的明细数据量非常巨大,如果在明细数据的基础上直接计算,速度会很慢,等待时间过长,是用户无法接受的。
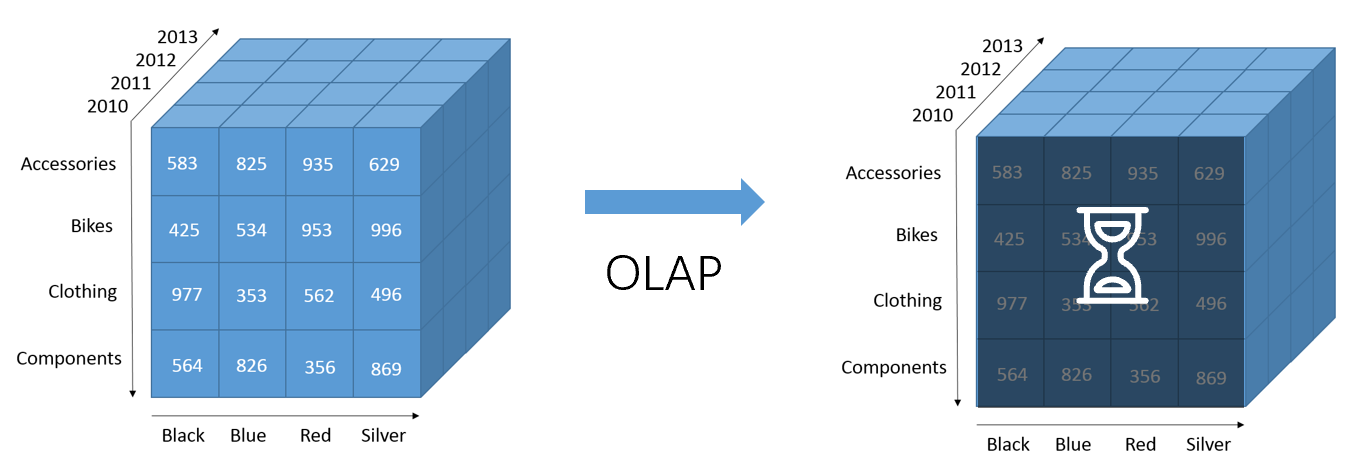
图1:基于明细的OLAP响应时间过长
为了保证秒级甚至毫秒级的响应速度,一些OLAP产品事先将几千万甚至上亿条明细数据计算成汇总数据,保存在硬盘上。这样,在分析的时候,就直接查询汇总数据,不会出现等待时间过长的问题。这种预汇总的基本逻辑就是用更多的硬盘空间换更短的查询时间。但是,容易忽视的一个问题是:到底要用多大的硬盘空间才能达到这个目的?下面就让我们实际计算一下看看。
存储空间计算1:3个独立维度,7个中间结果…
为了简化分析,我们假设一个多维分析系统,仅有3个独立维度。独立维度是指不相互依赖的维度,例如:产品(product)、雇员(employee)、客户(customer)。类似“年/月/日”这样的分层维度,可以认为是一个独立维度,而不是多个。
这三个独立维度组合预先汇总,会有7个中间结果,也就是2的3次方减1个。如下:
1、 产品、雇员、客户
2、 产品、雇员
3、 产品、客户
4、 产品
5、 雇员、客户
6、 雇员
7、 客户
存储空间计算2:50个独立维度,要一百万块硬盘!
一般的多维分析系统都不会只有3个独立维度,假设有50个的话,我们将所有可能的维度组合都预先汇总出来存在硬盘上,会有多少个中间结果呢?答案是2的50次方减1个!
这些中间结果我们称之为中间CUBE(立方体)。每个中间CUBE还会包含很多汇总数据,。例如:“2、产品、雇员”这个中间结果就包括很多行产品、雇员组合起来的汇总订单金额值。假设每个中间CUBE有1K字节数据,那么2的50次方个中间CUBE占用的存储空间将超过1MT。也就是说,需要一百万个1T的硬盘才能存的下!
存储空间计算3:50个独立维度选20个分析,还要几十万块硬盘!
根据实际情况,一般用户都不会选中所有的50个维度来做分析,没必要预汇总所有的维度组合。所以我们减少维度个数,最多只汇总50个维度中的20个。在数学上,从50个维度中选出n个,用组合数C(50,n)来表示。所以从50个维度中选出1到20个维度形成的中间结果就有C(50,1)+C(50,2)+…+C(50,20)。我们只看这里面最大的一个C(50,20),含义是从50个维度中选出20个来汇总成中间结果,得到的中间CUBE大概是4.7E13个,也就是4.7乘以10的13次方个。这些中间结果都包含20个独立维度,所以包含的汇总数据的数量比较大,我们保守估计每个有1万行,总共就有4.7E17行数据(4.7E13乘以1万)。即使不考虑维度字段,只考虑一个汇总字段“订单金额”,仅占用1字节存储,计算出来也需要470000T以上的容量,还是需要47万块硬盘!
存储空间计算4:6层交叉表,4个切片维度,仍然要上千块硬盘!
继续从实用角度出发,多维分析一般展现为多层表头的交叉表。例如:2层上表头是客户和产品维度,1层左表头是雇员维度。表头层数太多时,分析起来也很不方便。我们就假设上表头和左表头都是3层,也就是总共6层。50个维度中取6个的组合数为C(50,6),大概是1589万个组合。仍然按照每个中间CUBE有1万行计算,总行数不到160G行。每行数据只算十几个统计值,一般不会超过1K,那么总共需要100T存储容量。也就是100块硬盘就够了,看起来似乎可以接受。
但是,多维分析不能只看交叉表,还要做一些切片条件过滤操作。例如:针对某个雇员、某个客户、某个产品来看看其他维度的交叉表。所以,与汇总的数据,不能只考虑交叉表本身的6维度,还要加上切片用到的维度。假设再留4个维度来切片,就要计算10个维度需要的空间了。C(50,10)大概是100亿个中间CUBE,每个按照1万行,总计就是100T行。每行十几个统计值,1K容量,总容量又是几千T了,还是需要上千硬盘。
问题出在哪里?全量预汇总不可行,要部分预汇总。
上面计算的全量预汇总的优点是将需要的统计结果全部计算出来,分析的时候直接用就可以了,不用再做任何汇总。但是,经过上面的计算我们发现,全量预汇总需要的硬盘数量太多,已经不可行了。
所以,我们要改变一下思路,不把每种可能出现的维度组合都预汇总出来,只预汇总部分维度组合。在查询时,对于已经有预汇总的数据则直接返回,而如果碰到没有预汇总的维度组合时,则仍然从原始明细数据遍历聚合出来。
更进一步,我们还可以从某个已有的中间 CUBE 聚合。比如,如果保存了维度组合 [A,B,C] 的预汇总数据,那么维度组合 [A,B] 或[B,C]的查询就可以从这个中间 CUBE 再聚合出来了,而不必从原始明细数据聚合,计算量将会大大降低。为了容易理解,我们用SPL语言来举例说明如何实现部分预汇总,如下图:
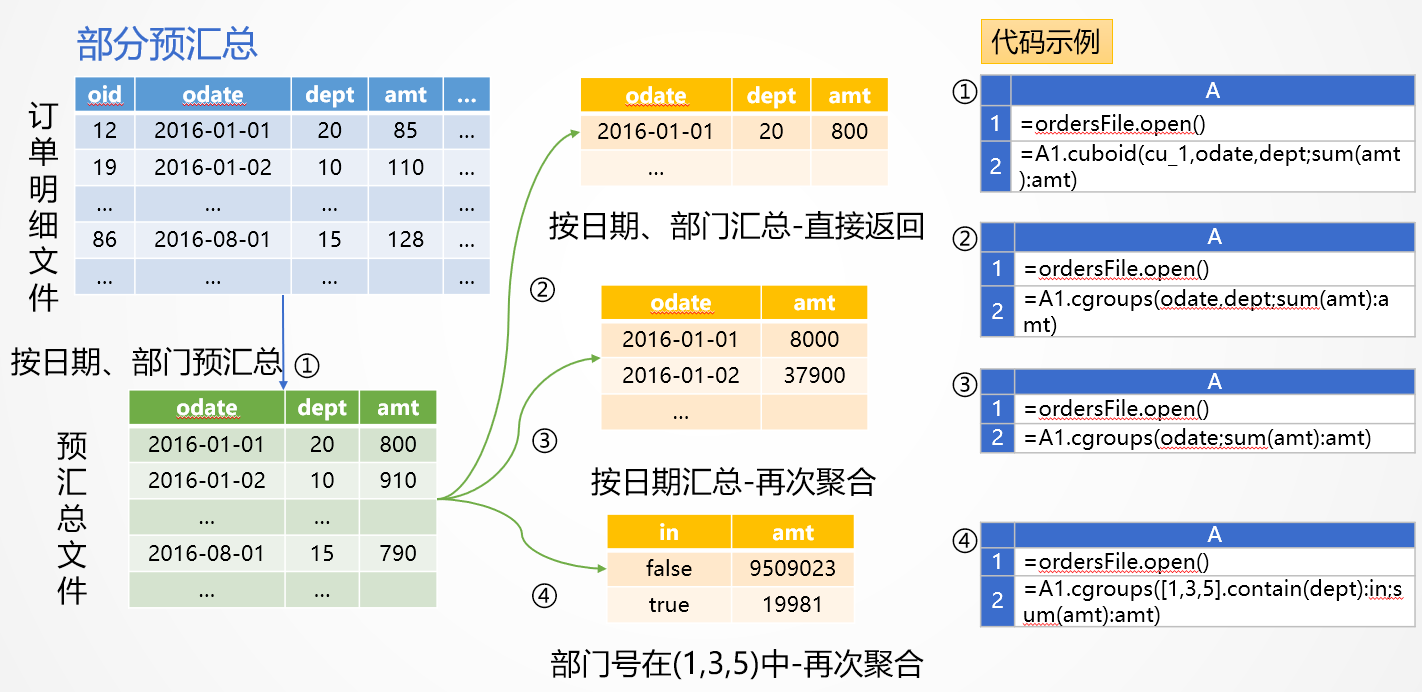
图2:部分预汇总
图2中,订单明细预先按照日期和部门汇总保存成中间CUBE,数据量就小了很多。再按照②③④三种方式汇总时,就可以在中间CUBE基础上再次汇总了。这样做,即解决了在大量明细数据上汇总耗时太长的问题,也避免了全量预汇总占用空间过大的问题。
有时可能会有多个中间 CUBE 都能聚合出目标查询,比如组合 [A,B,C] 和[B,C,D]都可以再聚合出组合[B,C],这时SPL会优先选择数据量较小的那个中间 CUBE,保证获得最好性能 。
那么,我们怎么知道在初始状态时该预先汇总哪些组合呢?
可以动态生成这些组合。在查询时,无法从现有中间 CUBE 聚合出来的组合只能从原始明细数据聚合,我们可以在聚合完成后将结果保存起来作为一个新的中间 CUBE。发现新组合时第一次访问会有延迟感,以后基于这个组合的查询或者可由该组合聚合出来的查询就都可以较快返回了。
其实,也不是只要能从现有中间 CUBE 聚合出来的组合就总是临时聚合。多维分析性能优化的目标是前端反应速度,如果中间 CUBE 仍然很大,那么再聚合也会比较慢,这时候,这些再聚合的结果也可以作为一些新的中间 CUBE 保存起来。
另外,在过程中我们还可以记录每个中间 CUBE 的使用频率,在空间总量限制下,删除那些使用率较低的中间 CUBE,从而更有效地利用有限的空间。
还可以利用的技巧:时间段预汇总
很多场景下,明细数据都是按照日期顺序存储的,我们可以将数据按更高的时间维度层次预汇总,在查询时就可以减少遍历计算量。如下图计算20180609到20181111的销售总金额:
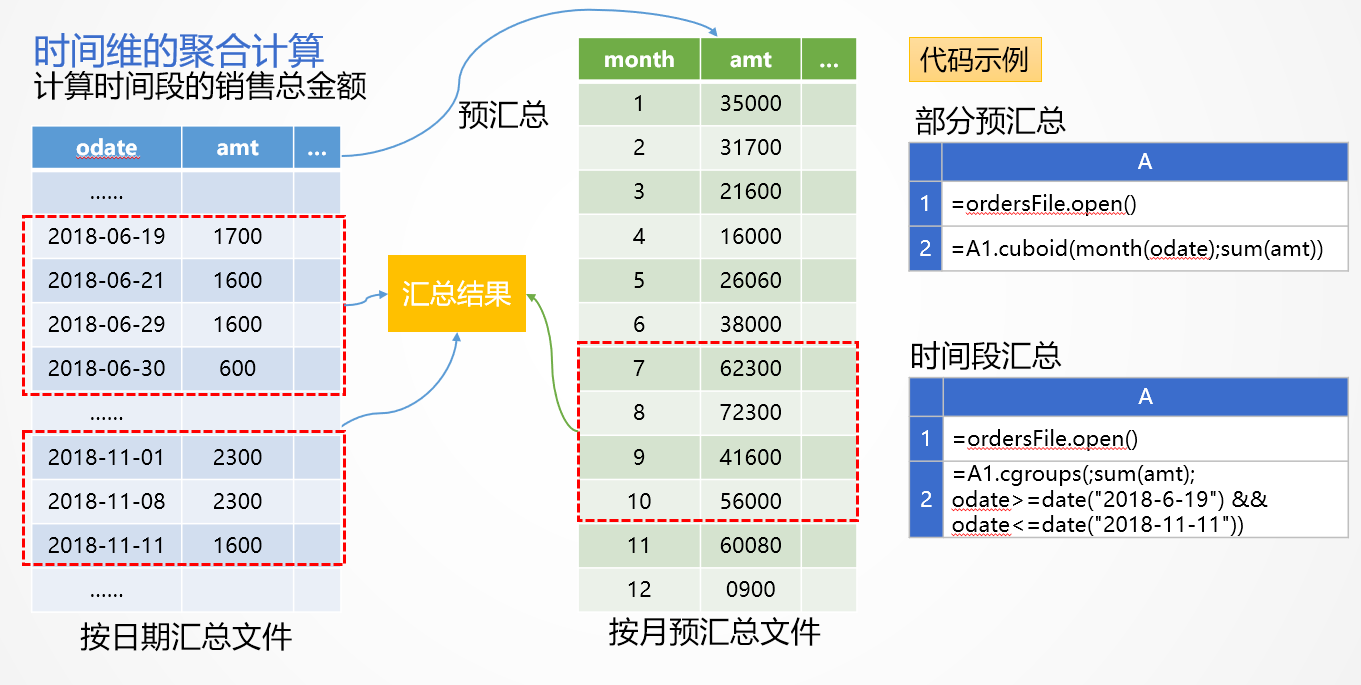
图3:时间段预汇总
为了方便理解,图3中用按照日期汇总数据来代替原始明细文件,实际上用明细文件也是一样的原理。从20180609到20181111是145天,如果直接用按照日期汇总数据来计算需求的话,要汇总145条数据。
如果我们事先有月汇总数据(图3右上代码准备),那么可以利用它来减少计算量。SPL在计算从20180609到20181111这段日期的统计时,会将日期段划分为3段:6月19日-6月30日,需要查询12条日金额数据。7月-10月是整月汇总,只需要查询4条月金额数据就可以了。11月1日-11月11日,11条日金额数据。3段汇总数据共27条,比直接查日汇总数据145条少了很多。
如果再对比原始明细数据,当进行较长时间段统计的时候,计算量可以减少十倍甚至更多。
结论:部分预汇总可满足多维分析性能要求,还能避免占用空间过大
经过“部分预汇总”优化后,我们虽然无法完全做到全量预汇总那样直接查询的程度,但常常也能把计算性能从全量硬遍历提高几十倍甚至上百倍,这对于大多数多维分析场景已经足够了。