链路追踪工具 skywalking
一、关于应用性能监控 APM(Application Performance Monitor)
对于单体应用,性能分析相对简单,不同的语言都提供了工具,在代码层面埋点,然后跑一个压力测试,最后以图形化的方式看到每个调用的耗时,以此来分析性能。
对于微服务系统,在解决了单个服务的性能之后,各个服务之间的调用链的性能分析就变的错综复杂,于是需要有链路追踪系统。
常见apm参考对比及工具选型
SkyWalking:中国人吴晟(华为)开源的一款分布式追踪,分析,告警的工具,现在是Apache旗下开源项目,对云原生支持,目前增长势头强劲,社区活跃,中文文档没有语言障碍。
Zipkin:Twitter公司开源的一个分布式追踪工具,被Spring Cloud Sleuth集成,使用广泛而稳定,需要在应用程序中埋点,对代码侵入性强
Pinpoint:一个韩国团队开源的产品,探针收集的数据粒度非常细,但性能损耗大,因其出现的时间较长,完成度很高。
Cat:美团大众点评开源的一款分布式链路追踪工具。需要在应用程序中埋点,对代码侵入性强。
项目不想侵入其他的代码,工具尽量损耗性能低,工具的社区活越,文档完善*也是考虑的必要条件,经过以下表格部分参数对比,相对来说,SkyWalking更占优,因此团队采用SkyWalking作为APM工具。
| 工具名称 | 代码入侵方式 | 性能 | ui | 使用人数 | 粒度 | 告警 | 依赖分析 | traceID查询 |
|---|---|---|---|---|---|---|---|---|
| SkyWalking | 无侵入 | 高 | 丰富 | 多 | 方法级 | 有 | 有 | 有 |
| Pinpoint | 无侵入 | 低 | 丰富 | 多 | 方法级 | 有 | 有 | 有 |
| Zipkin | 侵入低 | 中 | 一般 | 多 | 接口级 | 无 | 有 | 有 |
| Cat | 侵入高 | 中 | 丰富 | 较多 | 代码级 | 有 | 无 | 无 |
二、skywalking 简介
官网:https://skywalking.apache.org/
github:https://github.com/apache/skywalking
SkyWalking为超大规模而生。无论你的微服务是否在服务网格(Service Mesh)架构下,它都可以提供高性能且一致性的监控,作者吴晟。
SkyWalking做为Apache的顶级项目,是一个开源的APM和可观测性分析平台,它解决了21世纪日益庞大、分布式和异构的系统的问题。它是为应对当前系统管理所面临的困难而构建的:就像大海捞针,SkyWalking可以在服务依赖复杂且多语言环境下,获取服务对应的指标,以及完整而有意义的性能视图。
SkyWalking是一个非常全面的平台,无论你的微服务是否在服务架构下,它都可以提供高性能且一致性的监控。
让我们来看看,SkyWalking是如何解决大规模集群的可观测性问题,并从一个纯粹的链路跟踪系统,发展成为一个每天分析百亿级跟踪数据,功能丰富的可观测性平台。
为超大规模而生
SkyWalking的诞生,时间要追溯到2015年,当时它主要应用于监控顶级电信公司(例如:中国联通和中国移动)的第一代分布式核心系统。2013-2014年,这些电信公司计划用分布式系统取代传统的单体架构应用。从诞生那天开始,SkyWalking首要的设计目标,就是能够支持超大型分布式系统,并具有很好可扩展性。那么支撑超大规模系统要考虑什么呢?
拉取vs推送
与数据流向息息相关的:拉取模式和推送模式。Agent(客户端)收集数据并将其推送到后端,再对数据进一步分析,我们称之为“推送”模式。究竟应该使用拉取还是推送?这个话题已经争论已久。关键因素取决于可观测性系统的目标,即:在Agent端花最小的成本,使其适配不同类型的可观测性数据。
Agent收集数据后,可以在短时间内发送出去。这样,我们就不必担心本地缓存压力过大。举一个典型的例子,任意服务都可以轻松地拥有数百个甚至数千个端点指标(如:HTTP的URI,gRPC的服务)。那么APM系统就必须具有分析这些数量庞大指标的能力。此外,度量指标并不是可观测性领域中的唯一关注点,链路跟踪和日志也很重要。在生产环境下,SkyWalking为了能提供100%采样率的跟踪能力,数据推送模式是唯一可行的解决方案。
SkyWalking即便使用了推送模式,同时也可进行数据拉取。在最近的8.x的发版本中,SkyWalking支持从已经集成Prometheus的服务中获取终端用户的数据,避免重复工程建设,减少资源浪费。另外,比较常见的是基于MQ的传输构建拉取模式,Kafka消费者就是一个比较典型的例子。SkyWalking的Agent端使用推送模式,OAP服务器端使用拉取模式。
结论:SkyWalking的推送模式是原生方式,但拉取式模式也适用于某些特殊场景。
度量指标分析并不仅仅是数学统计
度量指标依赖于数学理论和计算。Percentile(百分位数)是用于反映响应时间的长尾效应。服务具备合理的平均响应时间和成功率,说明服务的服务等级目标(SLO)很好。除此之外,分布式跟踪还为跟踪提供了详细的信息,以及可分析的高价值指标。运维团队(OPS)和系统稳定性(SRE)团队通过服务拓扑图,用来观察网络情况(当做NOC dashboard使用)、确认系统数据流。SkyWalking依靠trace(跟踪数据),使用STAM(Streaming Topology Analysis Method)方法进行分析拓扑结构。在服务网格环境下,使用ALS(Envoy Access Log Service)进行拓扑分析。节点(services)和线路(service relationships)的拓扑结构和度量指标数据,无法通过sdk轻而易举的拿到。
为了解决端点度量指标收集的局限性,SkyWalking还要从跟踪数据中分析端点依赖关系,从而拿到链路上游、下游这些关键具体的信息。这些依赖关系和度量指标信息,有助于开发团队定位引起性能问题的边界,甚至代码块。
三、skywalking架构图
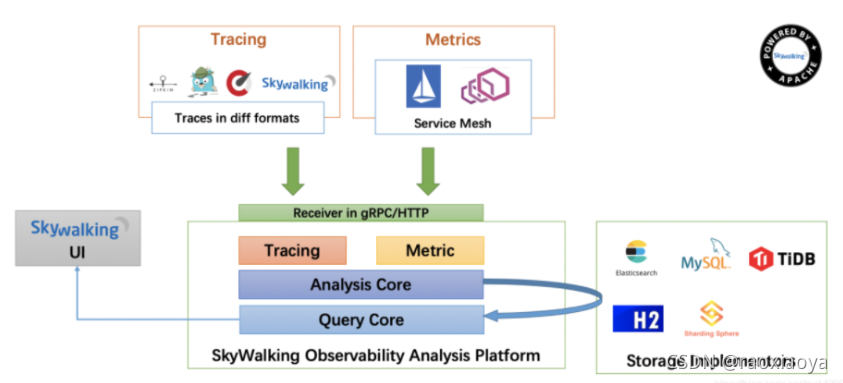
整个架构,分成上、下、左、右四部分
- 上部分 Agent :负责从应用中,收集链路信息,发送给 SkyWalking OAP 服务器。目前支持 SkyWalking、Zikpin、Jaeger 等提供的 Tracing 数据信息。而我们目前采用的是,SkyWalking Agent 收集 SkyWalking Tracing 数据,传递给服务器。
- 下部分 SkyWalking OAP :负责接收 Agent 发送的 Tracing 数据信息,然后进行分析(Analysis Core) ,存储到外部存储器( Storage ),最终提供查询( Query )功能。
- 右部分 Storage :Tracing 数据存储。目前支持 ES、MySQL、Sharding Sphere、TiDB、H2 多种存储器。而我们目前采用的是 ES ,主要考虑是 SkyWalking 开发团队自己的生产环境采用 ES 为主。
- 左部分 SkyWalking UI :负责提供控台,查看链路等等。
大致流程就是,各个服务中都要集成一个叫Agent的程序,它负责收集此服务的各项性能指标;然后推送到SkyWalking OAP,来分析,归纳,存储;最终由SkyWalking UI提供一个可视化的查询展示界面。
四、关于SkyAPM
SkyAPM就是上面提到的Agent,针对不同语言,官方都提供了相应的包可按需下载:https://github.com/SkyAPM