Abstract & Introduction & Related Work
- 研究任务
- 基于实例的学习,使模型拥有可解释的推理过程,用于结构化预测
- 本研究提出并研究了一种基于实例的 span 表征学习方法。
- 已有方法和相关工作
- 基于实例的学习是一种机器学习方法,可以学习实施之间的相似性,在推理阶段,最相似的训练实例会被分配到新的实例
- 最近,尽管有很高的可解释性,但这个方向还没有被探索。
- 面临挑战
- 神经模型通常有一个共同的技术难题 的挑战:黑箱特性
- 基于BIO的标注,面临着不连续标签的预测问题
- 将NER任务视为序列标注问题时,很难解决嵌套实体的问题
- 创新思路
- 这是第一个研究基于实例的span表征学习的工作
- 与token-wise预测相反,我们采用span-wise预测,它可以自然地避免这个问题,因为每个span被分配一个标签
- 实验结论
- 通过对NER的实证分析,我们证明了我们基于实例的方法能够在不牺牲性能的情况下建立具有高可解释性的模型。
Instance-Based Span Classification
NER as span classification
对于一个句子,首先枚举所有可能的span,然后给它分配一个类别,span s的类别是由一个softmax函数来计算的

score是由标签的权重矩阵和span的特征向量内积得到的:
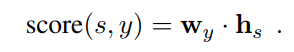
null类型的标签被设置成一个常量,其内积的值恒为0
在训练阶段,最小化一个负对数似然函数:
Instance-based span model
输入经过encoder编码后,在特征空间找到与其最接近样本,并计算其特征分布,然后将概率最大的标签分配到输入样本

使用一个不包含自己的softmax

计算出 s i s_i si? 属于 y i y_i yi? 的概率
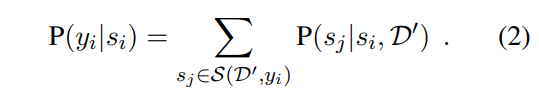
损失函数:
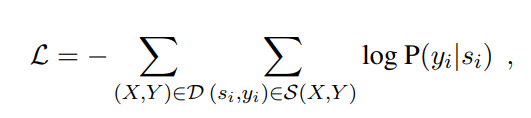
在推理阶段,求argmax

Efficient neighbor probability computation
用整个训练集来当做负样例的计算成本太高,可以从数据集中抽取k个样本作为负样例(在一个mini-batch里面)

Experiments




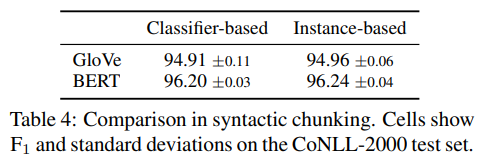
Conclusion
我们提出并研究了一种基于实例的学习方法,它可以学习跨度之间的相似性。通过NER实验,我们证明了我们的方法所建立的模型(i)具有与基于分类器的span模型相竞争的性能;(ii)可解释的推理过程,即很容易理解每个训练实例对预测的贡献有多少。
Remark
首先看完model部分我就懵逼了,这篇paper真的有contribution?不就是做了个聚类?
再者,我发现了一个细节的问题,作者的argmax的下标位置是居中而不是在max下面(虽然好像也没什么问题)
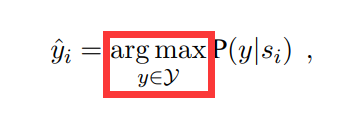
终极总结:我读了个寂寞
