ͨ���첽���������ʵ�ָ߿�����
�漰����
�Ʋ���ִ�еĸ��https://zhuanlan.zhihu.com/p/33145828
Xen�ĸ��https://baike.baidu.com/item/Xen
ϵͳ��ҳ��ҳ����ĸ���https://juejin.im/post/5d59638c518825291e3dd77f
Hypervisorhttps://zhuanlan.zhihu.com/p/34320333
ժҪ
��Ӧ�ó�����Ӳ���������Ҵ�������һ����ۺܸߵĹ�����ͨ����������������������ӵĻָ����Լ�����ר��Ӳ���������ߴ��ͻ�ͳӦ�ó���Ŀɿ��Թ��������ص��ϰ������ǽ�����һ��ͨ�������ĸ߿����Է���ļܹ����üܹ����Ա����������������Ҳ���Ҫ�ģ���ֹ���������ڵ�����������������ϡ� Remus�ṩ�˼��ߵ��ݴ������������ֹ���ʱ�������е�ϵͳ�������л�����������������ִ�У���ͣ��ʱ��ֻ�м����ӣ�ͬʱ��ȫ�������������ӵ�����״̬���ӡ����ǵķ������ܱ�����������װ��������У���ÿ����ʮ�ε�Ƶ���첽�����ĵ�״̬������������������ʹ���Ʋ���ִ�У�ʹ��������״̬�������ڸ��Ƶ������״̬��
1 Introduction ����
�߶ȿ��õ�ϵͳ�Ƿdz������ĸ�� ����ȴ����ʵ�ֿɿ��ԣ���������Դ����ϵͳ�С� ���ҵ��ǣ��߿����Ժ���ʵ�֨C��Ҫ��ϵͳ������������ɣ���Щ��������ܹ��ڷ�������ʱ����ά�����л������ݡ� ּ�ڱ����ִ�����������ҵ�߿�����ϵͳͨ��ʹ��ר��Ӳ��������������ͬʱʹ�����ߣ�����[12]���� ��ÿ������£����ؽ�����ϵ������ȸ����ְ���������ֹ����ͨ�������Ͻ��в���
���Ľ�����Remus������һ������ͨӲ�����ṩ�����ϵͳ��Ӧ�����صĸ߿����Ե�����ϵͳ�����ǵķ����������⻯���ܣ�ʵ������������֮����Ǩ���������е������������չ�˸ü����Էdz��ߵ�Ƶ�ʣ�ÿ25ms������Σ����������������е������ʵ���Ŀ��ա�ʹ�ô˼��������ǵ�ϵͳ���������ִ����ɢ��Ϊһϵ�еĿ��ա��ڸ�����������ϵͳ״̬֮ǰ�������ͷ��ⲿ������ر��Ǵ�����������ݰ���
���⻯���Դ����������еļ�����ĸ����������ܱ�֤�ù��̵��ʡ�ͬ���ش���ÿһ��״̬�ĸı��Dz���ʵ�ģ���Ϊ���Ʋ�����ռ�������豸�����Ĵ�����������һ���������Ʋⷽʽִ�У�Ȼ�����ü��㲢�첽������״̬�����ύ����֮ǰ��ϵͳ״̬�������ⲿ�ɼ�������ͨ���ڹ�ȥ��ʮ��������Ч������ϵͳ��ʵ�ָ��ٸ������ܡ�
���ĵĹ�����ʵ�õġ�����ϵͳ������һ��������֪���ṩ�߿��õķ��������ǣ�ͨ����Ϊ���Ƚ�����������ݵ��ض���Ӧ�ó���ļ��㼼��Ҫ����ö�[15]�����ǵķ��������ڽ�HA��Ϊ�������ƽ̨����������ڡ����������ڲ������ܵ�Ӳ�������������ƣ�����ϵͳ�����ṩ�����ý������ͬ���������õı�������������ϵͳ���Գ־��Դ洢������Ҫ��Ӧ�ó���ӱ���һ�µij־�״̬��ִ�лָ������֮�£�Remusȷ���������ڵ��ʱ�������ϣ������ᶪʧ�κ��ⲿ�ɼ�״̬��
1.1 Goals Ŀ��
Remusּ��ʹ�еͶ�ϵͳ��ø߿����ԡ�ͨ�������ò�����������������ϵ����ٵ����������ϣ����⻯ʹ��Щϵͳ���ܻ�ӭ�����ǣ��ϲ������ô���ͬʱ�����˳���Ӳ�����ϵĿ����ԡ� Remusͨ�����߿�������Ϊ���⻯ƽ̨�����ṩ�ķ��������Ʒ���������Ϊ������Ĺ���Ա�ṩ�˼����յĹ��ߡ�
Remus����ƻ�����������Ŀ�꣺
Generality ͨ���� ����һ��Ӧ�ó�����֧�ָ߿����Կ��ܻ�dz�������˵��֯���������ĸ���������Ϊ�˽�������⣬Ӧ���߿�������Ϊ�ײ�����ṩ������ͨ�õĻ��Ƴ��֣�������ע�ܱ�����Ӧ�ó�������и�Ӧ�ó����Ӳ����Ρ�
Transparency ���� ��������У��������IJ���ϵͳ��Ӧ����Ϊ�˾�����֧�ֹ㷺��Ӧ�ó��߿����Բ�ӦҪ����OS��Ӧ�ó��������֧��������ϼ���״̬�ָ�֮��Ĺ��ܡ�
Seamless failure recovery ����ϻָ� �ڵ��������ϵ�������κ��ⲿ�ɼ�״̬����Ӧ��ʧ�����⣬���ϻָ�Ӧ���㹻��ؽ��У����ⲿ�û��ĽǶ�����ֻ����ʱ�����ݰ���ʧ���ѽ�����TCP���Ӳ�Ӧ��ʧ�����á�
��Щ�dz������ʵ�ֵ�Ŀ�꣬��Ҫ�ṩԶԶ������ͨHAϵͳ���ṩ����ˮƽ����ͨHAϵͳ�����첽�洢����������ض���ijЩӦ�ó���Ļָ����롣���⣬��Ҫ�ڲ���������ڴ���������ʵ�����ֿ����Լ�����Ҫ���÷dz������ȵķ�������������⡣��ϵͳ����������Ŀ����ʵ����ЩĿ�꣬ͬʱ�ṩ�ɲ��������ˮƽ����ʹ��Ե��������Ӳ���ϳ�����SMPӲ��Ҳ����ˡ�
1.2 ;��
Remus������active-passiveģʽ���еijɶԵķ���������Ϊ�˿˷��÷����йص����ѣ����Dz�����������Ҫ������ ���ȣ����ǻ������⻯�Ļ����ܹ����������ǵ�ϵͳ����ʵ������ϵͳ�ĸ��ơ� �ڶ�����ͨ���Ʋ�ִ�������ϵͳ���ܣ���ִ�н��ⲿ�����ͬ����������������������������Ч�ʣ����븴�Ʒ�������ͬ�����첽ִ�еġ�ͼ1������Remus�л����IJ����Ρ�


ͼ1:remus�е��Ʋ�ִ�к��첽����1:���㣬2:���䣬3:ͬ����4:����
����VM������ϵͳ���� ϵͳ�������������ڹ���HAϵͳ�����������У����⻯�����������������һ��ϵͳ�����������˶����֧����ȷ��һ�����������ϵ��������ѭȷ����ִ��·����Ϊ��������ͱ��������ע����ͬ���ⲿ�¼�����ʹ��״̬��ͬ��ǿ��ִ�����ֲ���������������⡣���ȣ�Ҫ�����Ǹ߶��ȶ��Ľṹ���Ӷ�ϵͳ������ִ�е�ָ����ⲿ�¼�����ͬ�Ľ������Σ��ڶദ����ϵͳ��Ӧ��ʱ����ᵼ�²��ɽ��ܵĿ������ڶദ����ϵͳ�У����빲��������֮����ڴ���ʵ�־�ȷ����[8]��
�Ʋ�ִ�� ���ƿ���ͨ������ϵͳ״̬��ȷ��������ִ��������ʵ��������Ϊ���߶���ʵʱ�����Dz���ʵ�ʵģ��������ڶദ���������С���ˣ�Remus���᳢��ʹ����ȷ�����������ϵͳ�ع����ü��㲢�ط������룬����ںܴ�Ŀ����ԣ���ϵͳ�ڸ�������֮������������������ͬ�����ǣ�������������ⲿ�ɼ�ʱ������Ҫ��������״̬�������ݿ�ͬ����������������嵽�����ʵ�ʱ�䣬������������������������ʱ����ͬ������ͬ����֮ǰ�����Ʋ��Եļ��㡣��������������ӳٺ�����ʱ��֮������������Ȩ�⣬��̶ȿ����ɹ���Ա���ơ�
�첽���� �����������ϻ����ⲿ�����ʹ���ƿ����첽ִ�С� �����������ڲ���������״̬����һ�̺�ָ�ִ�У�������ȴ�Զ�̱��ݶ˵�ȷ�ϡ� ������ִ���븴�ƹ����ص������ʵ���Ե��������ơ� ��ʹ�����ʮ����ļ���ʱ��Ҳ���Խ��и�Ч�IJ�����
2 ��ƺ�ʵ��
ͼ2��ʾ������ϵͳ�ĸ���ͼ�����ȣ���Ҫ�����Ļ�����װ��������С����ǵ�ʵ�ֻ���Xen�����������[2]������չ��Xen��ʵʱ��Ǩ�Ƶ�֧�֣����ṩϸ���ȵļ��㡣����һ���ּ���֧�ֵĴ����Ѳ���XenԴ���롣
Remusͨ������������Ƶ�������㣬����������������������ʵ�ָ߿����ԡ��ڱ��������������ӳ��פ�����ڴ��У��������������ϵͳ�Ĺ��ϣ������������ʼִ�С����ڱ��ݽ��������ݿⶨ�ڱ���һ�£���˱��뻺���������������ֱ�������ϵ�״̬ͬ��Ϊֹ�����յ�������һ�µ�����ӳ����˻��������ͷŸ��ⲿ�ͻ��ˡ����㣬���������ͷ����ڷdz�Ƶ���������Ըߴ�ÿ��40�ε�Ƶ���ṩ�����Խ��������ÿ25�����������ʹ���״̬�������������㡣
�봫������紫�䲻ͬ������״̬���ⲿ���ɼ������ǣ����뽫��Ϊ������һ�µĿ��մ�����Զ��������Ϊ�˶Դ��̽��и��ƣ����ж������̵�д���������첽���䵽���������ϣ�Ȼ���仺����RAM�У�ֱ����Ӧ���ڴ���㵽���ʱ�����������ݿ�ȷ�������ļ��㣬Ȼ���ͷų�վ�������ݣ���������Ĵ���д����д�뱸�ݴ��̡�
ֵ��ǿ�����ǣ������ֱ���������ϲ������ڱ���������ִ�С����dz䵱��������������������������Խ��ٵı���������Դ���Ӷ�������N��1������ͬʱ�����ڶ���������������е���������������������Ϊ����Ա�ṩ�˸߶ȵ����ɶȣ�����������Ⱥ���Դ�ɱ�֮��ȡ��ƽ�⡣

ͼ2:remus:�߲���ϵ�ṹ
2.1 ����ģ��
Remus�ṩ�������ԣ�
1. �κε��������Ĺ��϶��ǿ������̵ġ�
2. �����Ҫ�����ͱ�������ͬʱ�������ϣ����ܱ���ϵͳ�����ݽ����ڱ���һ��״̬��
3. ��ϵͳ״̬���ύ������֮ǰ���������ⲿ�ɼ������
���ǵ�Ŀ����Ϊ�������������Ĺ���ֹͣ���ṩ��ȫ���Ļָ�����ϵͳ������עĿ�ķ����ǿ������ɵؽ��߿����Ը�װ��������Ӳ�������е����������ϡ���ʹ��һ����������ͨ������ǧ��λ��̫�����ӣ����ҿ��Դ��κ�����Ĺ����лָ���ͨ����Ͽ��豸��״̬����Э�飬����������Ҫ�����������總�Ӵ洢���洢����ӳ��
���ǵ�Ŀ�겻�Ǵ����������Ϲ����лָ���������[5]�й۲쵽��������remus�����ṩ������ϵͳ״̬������ƣ���˻ὫӦ�ó�������������С������ṩ���Ⱥ�ͨ���Եı�Ҫ�����
���ǵĹ���ģ��������HA��Ʒ��ͬ������Ϊ�������������ṩ�˱���[31��30]�����ǣ���Щ��Ʒ�ṩ�ı����̶�ԶС��Remus�ṩ�ı����̶ȣ����е���ҵ��Ʒͨ���شӱ���һ�µĴ���״̬����������һ̨�����ϵ���������Ӷ������������Ĺ�����������Ӧ�����ǵķ�����������ʵʱǨ�����Ƶ�ʱ�䷶Χ�ڱ�����ϣ���ʹ��������в����������������������ᶪʧ�ⲿ��¶״̬��Ҳ�������̡�
2.2 �ܵ�����
ÿ���ζ������е���������м��㣬������ϵͳ����˼��ߵ�Ҫ�� Remusͨ����ˮ�������������������⡣����ʹ��epoch-based��ϵͳ���ڸ�ϵͳ�У����������ܵ����ݵ���ͣ����ִ�й������Զ�������ĵ�״̬��������״̬�Ѵ���������ʱ�ͷ��ⲿ������ٴβο�ͼ1���ù��̿��Է�Ϊ�ĸ��Σ�
- ÿ��ʱ����ͣһ���������е�������������κ��Ѹ��ĵ�״̬���Ƶ��������С��������ʵ������ʵʱǨ�Ƶġ�stop-and-copy�������������籾���Ժ����������Ѿ���Ը�Ƶ����������Ż�����״̬���ı����ڻ������к������������ִ�С�
- ����״̬�����䲢�洢�ڱ����������ڴ��С�
- ���������յ�������״̬������ͻᱻ��֪�����ݿ⡣
- �ͷŻ�������������
���ַ����Ľ�����ڼ���߽��ִ����Ч����ɢ���ˡ����ݴ�������ɵļ����ȷ�ϣ����ͷ��ѻ���������������ʲô�أ�����ʾ�����µĹ��ɹ��̡�
2.3 Memory and CPU
��Xen���еĻ�����ʵ���˼��㣬�Խ���ʵʱǨ��[6]��ʵʱǨ����һ�ּ�����ͨ���ü������Խ���������¶�λ����һ̨������������ֻ��Ҫ���ݵ��жϷ��ɡ�Ϊ�ˣ����ڴ渴�Ƶ�����������ͬʱ����������ھ��������С���ʵʱǨ�ƹ����У������ض��ڴ��д�룬���ҽ���ҳ���ٸ��Ƶ�������������ָ����ʱ�����������������д���ڴ���ٶ����ٴﵽǨ�ƹ����и��Ƶ��ٶȶ�δ�����κ���ǰ����ʱ���������������ʣ������ڴ潫�����Ƴ�ȥ�Լ���ǰ��CPU״̬����ʱ�����������ϵľ������ͣ��ʱ��ȡ�������������ʱҪ���Ƶ�ʣ���ڴ�������ͨ��������100���롣��Ǩ��ʱ���ǿͻ���ʹ�õ��ڴ��������д�������йء�
Xen�ṩ��ʹ�ó�ΪӰ��ҳ����shadow page table���ļ�����������������ڴ��д�����������ô˲���ģʽ��VMM��ά�������ҳ����˽�У���Ӱ�ӡ����汾�������乫����Ӳ��MMU��ҳ�汣�����ڲ������������ҳ����ڲ��汾�ķ��ʣ��Ӷ��������������������ٸ��£������ʵ�ʱ������Ӱ�Ӱ汾
����ʵʱǨ�ƣ��˼�������չΪ���أ�����������ԣ�������������ڴ���Ϊֻ����Ȼ����������Բ�����������ڴ������д��������ά������һ�������ѱ�Ū���ҳ��ӳ�䡣ÿһ��Ǩ�ƹ��̶����Զ���ȡ�����ô�ӳ�䣬������Ǩ�ƹ��̽��������ҳ�棬ֱ�����ٲ���Ϊֹ������������ʵʱǨ�ƹ������ջ���ͣ�������ִ�У�����������"stop-and-copy"�����ڴ˻ش�����ʣ���ҳ�棬����Ŀ�������ϻָ�ִ�С�
Remus��ʵ�ּ�����ΪʵʱǨ�Ƶ��������ظ�ִ����ÿ��ʱ�ڣ������������ͣ�������ĵ��ڴ��CPU״̬�������Ƶ���������Ȼ��������ڵ�ǰ�����ϻָ�ִ�ж�������Ŀ��������ȷ��ʼ����Զ��λ���ṩһ�µ�ӳ����Ҫ��Ǩ�ƹ��̽���һЩ�ģ����ṩ�㹻�����ܡ���Щ������������
Ǩ����ǿ
��ʵʱǨ���У�������ڴ��������ƺü��أ����ҿ��ܻ����ļ����ӵ�ִ��ʱ�䡣 ����stop-and-copy��ɵķ����ж���ɵ�������Ǻܴ��� ���ڲ���Ƶ�������������ʱ�������������ÿ������ֻ��Ǩ�Ƶ�������stop-and-copy�Σ����������˼��ټ��㿪�����Ż��Ĺؼ��㡣 ��Xen�������ļ����ʾ����������ڹ���״̬ʱ�����ѵĴ�ʱ�䶼�˷����˵����ϣ�����Ҫ�Ǹ��ػ��������������domain 0 ֮���ṩ����ͨ�ŵ�xenstore�ػ������ʵ��Ч�ʵ��¡�
Remusͨ�����ַ�ʽ�Ż����㣺
���ȣ��������˹���ͻָ����������Ľ��̼������������
��Σ�����xenstore��ȫ�ӹ���/�ָ�������ɾ����
��ԭʼ�����У���Ǩ�ƹ���ϣ�����������ʱ����������������ػ�����xend������һ����Ϣ�� Xend������xenstoreд��һ����Ϣ������Ϣͨ���¼�ͨ���������жϣ����������Ӧ��ִͣ�С�������ڹ���֮ǰ�����һ�������ǽ���hyper call��hypercall��������˵��ȣ�������Xen��xenstore����֪ͨ��Ȼ��xenstore������һ���жϵ�xend�����ս�����Ȩ���ظ�Ǩ�ƹ��̡�������ӵĹ���Ҫ���ѵ�ʱ����ȷ��-���͵IJ����ӳ�Ϊ30��40���룬������ijЩ����£����ǿ������ӳٳ���500���롣
Remus�Ż��ķ���ͨ����������д���һ��ר�����ڽ�����ͣ������¼�ͨ�����˹��̣�Ǩ�ƹ��̿���ֱ�ӵ��ø�ͨ�������⣬�ṩ���µ�hypercall������������ע���¼�ͨ���Խ��лص�����֪ͨ�������������ɡ���֮��������֪ͨ����ʹ����������������ʱ����ٵ���Լ100��-����ǰ��ʵ��������������������������
������Щ������ʽ����֮�⣬���ǻ�������ڴ渴�ƹ��̵�Ч�ʡ����ȣ����ǿ��ٴ��ڴ�ɨ����ɸѡ���ɾ���ҳ�棬��Ϊ�ڸ�Ƶ�����ü����£�������ڴ��Dz���ġ���Σ��������������ʼʱ������������������ڴ�ӳ�䵽���ƹ����У���������ÿ��ʱ�ڶ�ӳ���ȡ��ӳ����ҳ��-���Ƿ���ӳ��foreign pages�븴�����Ǵ�Լ��Ҫ��ͬ��ʱ��
����֧��
��Xen���ṩ����֧����Ҫ�����еġ�suspend-to-disk����ʵʱǨ�ƴ���������и��ġ�
���ȣ�֧�ֶ��������ͣ�����ִ�С� Xen��ǰ������������㡱�������ڽ���״̬д����������VM��
��Σ�����������ɵ��α�Ϊ�ظ�ִ�У��������ת��Ϊ�ػ����̡� �������ڵ�һ��֮��ļ���غϽ������²��������ڴ档
֧�ָֻ���Ҫ�����������ġ� ��һ�����µ�hypercall�����ڽ����ٴα��Ϊ�ɵ��ȵģ�Xen�ӵ��ȿ�����ɾ���˹��������Ϊ��ǰ���������ڸ�����״̬�����٣��� Ϊ����xenstore�����¼��ӣ�����ִ�����ƵIJ���
�첽����
Ϊ���������������ָ���������Ҫ��Ǩ�ƹ��̽����ģ������ҳ�渴�Ƶ��ݴ滺������������������ͣʱ������ֱ�Ӵ��ݵ����硣 ����������������ӣ���3.3�������۵��ں˹��������������ʱ����ÿ��20������ʱ�����˴�Լ10����
�ⲿ��
����������Xen�е�����ͻ�������һ�����������ô�����������յ���������������豸״̬�� ���˱���ǰ��������֪ͨ�Ż�֮�⣬���Թ�������������������ģ��Լ����ڹ���֮ǰ��ɵĹ������� ��ԭʼ�����У�����Ҫ��Ͽ������豸�����ӣ����γ���CPU֮�����еĵ�Դ�� ����֮����������Ƴٵ�����һ̨��������������֮��ִ�У� ��Щ����3.1.0���Xen�п��á�
��Щ���IJ����������ȷ�ԣ���������ȷʵ�����������������ܣ������漰��������ں˵ķdz��ײ���ġ� �ڰ������ݹҴ��������У��ܸ�������100�д��롣 ��ǰ���������ڷǰ����⻯������������������Щ�ġ�
2.4 ���绺��
����ָ������������ṩ�ɿ������ݡ���ˣ�����Ӧ�ó������������ݰ���ʧ�����ƺ�����������ʹ�ø�Э�飬���ṩ����֤��TCP����һ��ʵ���������绺����������������ݰ�����Ҫ���ƣ���Ϊ���ǵĶ�ʧ����ʾΪ��ʱ��������ϣ����Ҳ���Ӱ���ܱ���״̬����ȷ�ԡ� ���ǣ��Ŷӵȴ���������ݰ�Ҫ�ȵ��������ǵļ���״̬�ύ������Ϊֹ�� ������ڵ�ʧ�ܣ�����Щ���ɵ����ݰ�Ҳ�ᶪʧ��
ͼ3������������ֹ�Ʋ�������״̬�ͷŵĻ��ơ� ��վ�������������ݵ��ܱ��������������ǽ�����һ�������������ɵij�վ���ݰ����Ŷӣ�ֱ����ǰ״̬�ѱ����㱸����վ����ȷ�ϸü���Ϊֹ�� �����ѽ��˻�������Ϊһ��Linux�Ŷӹ�����ʵ�֣��ù������������е�������������豸��������Ӧ����RT-netlink��Ϣ�� �������ÿ��ڼ���֮��ָ�ִ��֮ǰ�����绺�������յ�CHECKPOINT��Ϣ����ᵼ�����ڳ�վ�����в���һ���ϰ�����ֹ�ͷ��κκ������ݰ���ֱ���յ���Ӧ�����·�����ϢΪֹ�� ����ȷ���˷ÿͼ�����������յ�RELEASE��Ϣ���˺�����ʼ�������Ӷ������ͷ�
�ڴ�ʵ����������С���⡣��������linux�У��Ŷӹ���ֻ�Դ������������á���Xen�£��ÿ�����ӿ��ɷÿ��е�ǰ���豸����0�е���Ӧ����豸��ɡ����Էÿ͵ij�վ��������0�еĺ���豸����ʾΪ��վ��������ˣ�Ϊ�˽������Ŷӣ�����ͨ����Ϊ�м��Ŷ��豸[16]�������豸·����վ����������վ����ת��Ϊ��վ��������ģ��ּ��ͨ��iptables [27]��IP�㹤������������չ������������ʵ��VM������ʵ��ŽӲ㹤���������ѡ�
�ڶ���������Xen���������豸��ʵ�֡�Ϊ��������ܣ���վ��������ʹ�õ��ڴ治�������������0֮�临�ƣ����ǹ��������ǣ�һ��ֻ�ܹ�������ҳ�档�����Ϣ���ڶ�ʱ��������������0֮�䴫�䣬��������Dz����ܵġ����ҵ��ǣ�����������������ܵ�����Ϣ�������г�������ʱ�䣬����û������豸�ڷ����˷dz�����������֮����������ˣ��ڶ���Ϣ�����Ŷ�ʱ���������Ƚ����Ǹ��Ƶ������ڴ��У�Ȼ����ӳ���ͷŵ���������

2.5���̻���
���������ٵ���ս������ӿ������ٵ���ս��Ȼ��ͬ����Ҫ����Ϊ���̿����ṩ��ǿ��Ŀɿ��Ա�֤�������ǣ���������ȷ��д���ʹ��ȷ�Ϻ�����������Դ���ϣ�Ӧ�ó����ļ�ϵͳ��Ҳ�����ָ������ݡ�����Remusּ�ڴӵ������������лָ�������ʹ�����������������ϣ���Ҳ���뱣�ֱ�����һ���ԡ�
���⣬�ṩͨ��ϵͳ��Ŀ���ǣ��ų�ʹ��ΪHAӦ�ó�����Ƶİ���ľ���洢Ӳ������ˣ�Remus���ڱ���������ά���VM���̵�����������ʹ�ñ���ϵͳ֮ǰ���������ϴ��̵ĵ�ǰ״̬�����������һ����ȡ�˱�����ʩ���Գ־��Դ洢��д�����������ٺͼ���������ڶ��ڴ�ĸ�����ͼ4�����˴��̸��ƻ���


���2.3�����������ڴ渴����ϵͳһ�����ӻ�����д����̵IJ�������Ϊֱд��write-through�������ǽ�����д����������ӳ���첽������������ϵ��ڴ滺���������ַ����ṩ������ֱ�ӵĺô������ȣ���ȷ�������ӳ��ʼ�ձ��ֱ���һ�¡���������������������ϣ��������̽����淢������ʱ�ⲿ�ɼ�������ı���״̬������������δ�������ϣ����߱��������ڼ���֮ǰҲʧ�ܣ����ⲿ�ɼ�״̬פ������������ϣ�������������������ϣ�����ע����δ�������ϣ�����λ�ڱ��������У�����Σ�ֱ��д����̿�ȷ˵�������豸����ʱ�����������ԡ������Զ��������Ծ����൱��ļ�ֵ��ȷ�ش�����Ӧ������һ��������⣬��Ϊ�����Լ������˽���汾�Ĵ��̻��������û�������д����������������ڴ��У�ֱ���ύ����Ϊֹ�����ַ���Ҫô����д������Ҫô�����Ա�ʾ�������ύ�����������ʱ�䣬����ʹ�������ִ�й����й���Ƶ����Ҫô���صظ߹���д�ӳ٣��Ӷ�����������ʧ��ģ�ͻ����̷���ʱ��dz�����[28]�����ǵ�ʵ����ͨ�������Ӵ��̵���ͻ����������ֱ�ӷ�������������⡣
���ڱ��������ڽ��յ����������������¼���֮ǰ���������ĵ�ǰ���������������Ѵ洢�ľɼ��㣬����ʱ���������������ϣ����¼���Ĵ��佫ʧ�ܣ��������еļ���Ҳ��Ϊ�����Ķ������������ԣ�
�ڱ���ȷ�����յ�����ʱ�����̸��½���ȫ������ڴ��С��ڽ��յ���������֮ǰ�����ø��Ĵ���״̬����Ϊ�⽫�谭���ݻع������µ��������㡣һ��ȷ���˼��㣬�Ϳ��Խ�����������Ӧ���ڴ��̡�
�����������������ϣ��պ��ڴ��������֮�������ϣ��������������ȵ����л��������ݾ���д����̺��ٻָ�ִ�У��������ⲿȥ���ʣ������ܱ��ݿ���ʹ����������Ϊ���������ϵĸ���������ʼִ�У������Υ�����ָ��ܱ���������Ĵ������壺��������ڼ����ʧ�ܣ������ݻ�û����ȫˢ�µ����̣���������-����״̬���ܲ��DZ���һ�µġ�
���κθ���ʱ�䣬Remus�������������̾�����ֻ��һ��ʵ��������Ч�ģ���Ϊֻ��һ̨����������ⲿ���ʣ����Ӷ����������лָ�ʱ����һ��������Ҫ��ͨ���ڱ��ݴ�����ʹ�ü����¼��activation record������ʵ�ִ����ԣ��ü�¼���ڽ����µĴ��̻�������ȫˢ�µ�����֮�����ڱ����������ʼִ��֮ǰд��ġ��Ӷ�����������лָ�ʱ���˼�¼�����ڱ�ʶ���̵���Ч���ͱ���һ�µİ汾��
���̻�������ʵ��ΪXen��block tapģ��[32]������ֽ�ͷ��һ���豸����������Ȩ��privileged domain���еĽ��̽���������Ч�������ṩ���ͻ��������ǰ�˷��ʴ����豸��ʵ��Ϊ�����ṩ����ĺ�˴����豸֮�䡣����ģ���¼�����ܱ���������Ĵ���д���������Ǿ������ϵ���Ӧģ�飬��ģ��ִ����������Э�飬Ȼ��������������ֹ���ʱ����ִ�б���֮ǰ�Ӵ�������·����ɾ��������
2.6���ʧ��
Remus��Ŀ���ǿ���ʹ����ͨӲ�����Գ�������ķ�ʽ�ṩ�߿����ԣ����������ܱ�����Ӧ�ó���ǰ������ʹ��ֱ�Ӽ����ڼ������еļ��ϼ���������ݶ��ύ�������Ӧ��ʱ�������������Ϊ�����ѱ��������ñ�����ͬ�����������ݿ���¼���ij�ʱ�������±��������������������ѱ�������������ļ���ָ�ִ�С�
ϵͳ����Ϊʹ��һ������ӿڣ�����������������ʹ�ñ���NIC�ϵ�һ����̫��������£�������Ľ��������������ӡ��������������·����ʧ�ܣ���Remus��ǰ�����ṩ����ִ�еĻ��ơ���������Ĵ�ͳ���������ٲ�Э�飩��������������������Ӧ�á�������Ϊ������������£������Ѿ���Remus���Ϊ��ƷӲ�����ܴﵽ�ļ��ޡ�
3 ����
���Remus����ҪĿ����ʹ�߿����Ծ����㹻��ͨ���Ժ����ԣ��Ա���Խ��䲿�������ڵ���ƷӲ���ϡ��ڱ����У����ǽ��������ǵķ�����Ը��ֲ�ͬ�Ĺ������������������ģ��Ա�ش��������⣺��1����ϵͳ�Ƿ��ʵ�ʲ��� ��2�����ֹ����������ʺ����ǵķ�����
����������Ӱ��֮ǰ�����DZ���ȷ��ϵͳ�������С����ǿ���ʵ��ͨ���ڸ���Э���ÿ����ע��������ϣ�ͬʱ���ܱ�����ϵͳ�����Ӵ������̣������CPU���ء����Ƿ��֣���ÿ������£����ݽ��ڴ�Լһ�����ڽ��涪ʧ�������ݿ⣬�����������ⲿ�ɼ���״̬����������������ӡ�Ȼ�����������dz���ͬ�Ĺ��������ϵ�ϵͳ���ܿ��������Ƿ��֣������ں˱���֮���ͨ��������ÿ�����20��ʱ�ᵼ�´�Լ50����������ʧ������SPECweb��ʾ����������Ĺ����������Դ�Լ�ķ�֮һ���ϵı����ٶ����С���������µĶ������Ҫ����������ӿ��ϵ�����ύ�ӳ١����ݴ˷��������ǵó����ۣ��������Remus����ҪĿ����ʹ�߿����Ծ����㹻��ͨ���Ժ����ԣ��Ա���Խ��䲿���ڵ������ƷӲ���ϡ��ڱ����У����ǽ��̻����ǵķ�����Ը��ֲ�ͬ�Ĺ��������������ļ�ӷ��ã��Ա������ش��������⣺��1����ϵͳ�Ƿ��ʵ�ʲ��� ��2�����ֹ��������ʺ����ǵķ���������������Ӱ��֮ǰ�����DZ���ȷ��ϵͳ�������С����ǿ���ʵ��ͨ���ڸ���Э���ÿ����ע��������ϣ�ͬʱ���ܱ�����ϵͳ�����Ӵ������̣������CPU�ĸ��ء����Ƿ��֣���ÿ������£����ݽ��ڴ�Լһ�����ڽ��涪ʧ����������������������ⲿ�ɼ���״̬����������������ӡ�Ȼ������������ͬ�Ĺ��������ϵ�ϵͳ���ܿ��������Ƿ��֣������ں˱���֮���ͨ��������ÿ�����20��ʱ�ᵼ�´�Լ50����������ʧ������SPECweb��ʾ����������Ĺ����������Դ�Լ�ķ�֮һ���ϵı����ٶ����С���������µĶ������Ҫ����������ӿ��ϵ�����ύ�ӳ١�
���ڴ˷��������ǵó��Ľ����ǣ�����Remus��״̬���Ʒ������Ч��������ȷ���������ص������ӳ٣��ر��Ƕ������ڴ�д��Ƚϲ�ľֲ���Ӧ�ó�����ˣ��������ӳٷdz����е�Ӧ�ó�����ܲ�̫�ʺ��������͵ĸ߿����Է���������һЩ�Ż��п����������������ӳ٣����ǽ��ڻ����Խ��֮�����ϸ����������һЩ�Ż��������ݻ����Խ����ȡ������ϸ��Ϣ�����ǽ�������ʱ�Ƚϱ��أ�ʹ�û������Ĺ������أ���ȵ��͵����⻯ϵͳԤ�ڵ�Ҫ�ܼ��öࡣ����ϵͳ�����ǿɱ�ģ�������ֻ��������ĺϲ������ر�����������
3.1���Ի���
��������˵�����������в��Ծ���IBM eS-erver x306�����������У��÷�������һ�����ó��̵߳�3.2 GHz Pentium 4�˴�������1 GB RAM��3��Intel e1000 GbE����ӿں�80 GB SATAӲ����������ɡ� ϵͳ����������Xen 3.1.2������2.3���е�������������������IJ���ϵͳΪXen 3.1.2��linux 2.6.18���а汾�� �ܱ�����VM������512 MB����RAM�� Ϊ�����̶ȵؼ�������VMM�ĵ���Ӱ�죬�� domain 0��VCPU�̶�����һ�����̡߳� һ����������ӿ��Žӵ�guest����ӿڲ�����Ӧ�ó���������һ����������ӿ����ڹ������ʣ����һ�����ڸ��ƣ�����û�а����ڸ��ƵĽӿڣ��������Dz����أ��� ���������SATA�������ϵĴ���ӳ���ṩ����ʹ��tapdisk AIO�����������ͻ�����
3.2 ��ȷ����֤
���2.2����������Remus�ĸ���Э�����ĸ���ͬ�Ľ����У���1���������״̬����������ʹ�����������ʱ�ڣ���2������ϵͳ״̬����3���������ڴ����� ���յ���Ӧ�Ĵ��������ӱ��ݷ��ͼ���ȷ�ϣ�4���յ�ȷ�Ϻ��ͷ�����һ��ʱ���Ŷӵij�վ�������ݰ��� Ϊ����֤���ǵ�ϵͳ�Ƿ�Ԥ�ڹ�����������ÿ���β����˹���µ�������ϡ� ����ÿ�����ԣ��ܱ���ϵͳ����ִ���ں˱�����̣������ɴ��̣��ڴ��CPU���ء� Ϊ����֤���绺����������ͬʱִ����һ��ͼ���ܼ���X11�ͻ��ˣ�glxgears�����ÿͻ������ӵ��ⲿX11�������� Remus������Ϊ���ܼ���ÿ25����һ�Ρ� ÿ�������IJ����ظ����Ρ� ��ÿ�����ϵ㣬���ݶ��ɹ��ӹ����ܱ���ϵͳ��ִ�У����ڱ��ݼ����ϲ�����Ƶ�ϵͳʱ��ֻ��С�������ӳ٣���Լһ���ӣ��ű�ע��� glxgears�ͻ����ڶ�����ͣ��������У������ں˱�����������ɹ���ɡ� Ȼ�����������ر���������ڱ��ݴ���ӳ����ִ��ǿ���ļ�ϵͳ��飬�ñ���δ�����κβ�һ�������
3.3 ��
�����²����У�����ʹ�ø��ֺ��������ϵͳ�����ܣ���Щ������Դ���һϵ��ʵ�ʻ�ϵĹ������ء��������е���Ҫ�����������ں˱�����ԣ�SPECweb2005�����Ժ�Postmark���̻����ԡ��ں˱�����һ��ƽ��Ĺ������أ�����ǿ�������ڴ�ϵͳ�����̺�CPU��SPECweb��Ҫǿ���������ܺ��ڴ�����������Postmark��רע�ڴ������ܡ�
Ϊ�˸��õ��������¶���������ִ����һ�������ԣ����ڲ�����������״̬�����ѵ�ʱ�䣨��������ͣʱ���Լ������ݷ��͵����������ѵ�ʱ�䣨���������һ�����������Ѹ��ĵ�ҳ���������DZ�д��һ��Ӧ�ó������ظ��������õ�ҳ�����ĵ�һ���ֽڣ�����1000�ε����в�����ʱ�䡣ͼ5չʾ���ڼ�����ƽλ��ѵ�ƽ������С������¼ʱ�䣬��������Ϊ95��������������Ƶ�ʵ�ƿ���Ǵ���ʱ�䡣

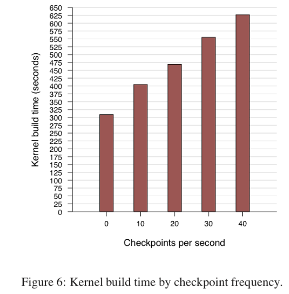
�ں˱��� �ں˱������ʹ��Ĭ�����ú�bz-ImageĿ������������linux�ں�2.6.18�����ʱ��ʱ�䡣����ʹ��GCC�汾4.1.2���������汾3.81�����Dz���CPU���ڴ�ʹ������ܵ�ƽ������ء�ͼ6��ʾ����δ����������еĻ�������ȣ���ÿ��10��20��30��40�ε��ٶȽ��������õ�����ʱ�ı���������ÿ��Ƶ�ʵ��ܲ��������ֱ�Ϊ31%��52%��80%��103%�������Dz��Ե����ʷ�Χ�ڣ����������Ƶ�ʳ����Ա�����ϵ��������Ϊ������������в����Ŀ�������ͨ��ϵͳҲ�Ǻ����ģ���ʹ��ÿ��40�μ���Ƶ�ʵ����Ҳ��������
SPECweb2005 SPECweb����������������������ϵͳ��ɣ�Web��������Ӧ�ó����������һ������Web�ͻ���ģ���������ǽ���������Ϊ��ͬ�������ϵ�����VM����1024 MB���ܿ���RAM�У�ΪӦ�ó���������Ϳͻ���������640 MB�� Web�������ͱ����䱸��2048 MB��RAM������1024�������Web������������������ڲ��Ե�ϵͳ���������ڱ������ᵽ��SPECweb������ʹ��SPECweb��������������ȡ�õ���߳ɼ���������95���ġ����á���99���ġ��ɽ��ܡ�ʱ��
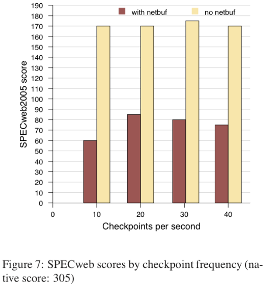
ͼ7��ʾ������ڲ��ܱ����ķ�������SPECweb�ڸ��ּ���Ƶ���µ����ܡ���Щ������Ҫ�Ƿ������Ϳͻ���֮������绺��������ɵ��ӳٵĺ��������ܽ���������Ϊ��һ��Ƶ�ʷ�Χ�����У���SPECweb�㹻��ĽӴ��ڴ棬�����ڴ����ڼ���֮����ڴ������ʱ����ʱ�ᳬ��100���룬�����ؿ��Ǽ���Ƶ����Ρ�������ȷ�ϼ���״̬֮ǰ���ͷ����绺�����������Ч�����ӳٿ��ܸ������õļ������� Remusȷ����ÿ��epoch��ʼʱ����VM���𣬵�����ȷ����ǰÿ��epochҪ���Ƶ�״̬���������������õ�epoch�����ڿ��õĴ�����������Ч����Ƶ�ʵ������õ�Ƶ�ʣ����������ӳ���SPECweb�÷���ռ������λ����������õ�Ƶ�ʷ�Χ��������Խ�ƽ̹�������õ�ÿ��10��20��30��40�����������£���õ�ƽ���������ʷֱ�Ϊ9.98��16.38��20.25��23.34������ƽ���ӳٷֱ�Ϊ100ms��61ms��49ms��43ms��
SPECweb��һ����Ҫ����RAM�Ĺ������أ��������ӳ�Ҳ�dz����С���ʹ�������ʺ����ǵ�ǰ��ʵ�֣���ʵ�ֽ������ӳٻ�Ϊ�ڴ���������ͼ8չʾ�˿ͻ���VM��Web��������SPECweb�ϵľ�Ч���ӳ١�����ʹ��Linux netem [19]�Ŷӹ���ΪWeb�����������⻯��δ��Remus�����У��ij�վ�������Ӳ�ͬ�̶ȵ��ӳ١�Ϊ�˽��бȽϣ�ͼ7����ʾ�˽������绺��ʱ�ı����������Ա���õؽ������ӳ���������ʽ�ļ��㿪�����뿪��ͬ����ƽ��������ļ���������Ч�ļ������ʵ������õ����ʣ� ����3.4�������۵Ľ�ֹʱ����Ⱥ�ҳ��ѹ���Ǽ��ټ����ӳٺʹ���ʱ������ֿ��ܵļ���������֮һ�����߶�����ټ����ӳ٣���˿��ܻ������SPECweb����

Postmark ǰ��IJ����������ܱ�����������ڴ����ܣ�������ʹ�õĻ����ڴ�����ϵͳ��ʩ�����еȸ��ء� Ϊ�˸��õ��˽���̻�����Ƶ�Ч��������������Postmark���̻����ԣ��汾1.51���� �û����Զ��������ʹ�����Ӧʱ��������С� Ϊ�˸�����̸��Ƶijɱ�����������Щ�����ڼ�û��ʹ���ڴ�����籣���� �����벻�ܱ�����ϵͳ��ͬ���������������Tapdisk����ģ���ṩ�� ͼ9��ʾ��ִ��10000���ʴ������������ʱ�䣬��Щ������Ҫ���̸��ƣ����Ҹ��ƵĴ�����ÿ��10��20��30��40�ε�Ƶ���ύ������������ƶԴ�������û������Ӱ�졣
3.4 Potential optimizations DZ�ڵ��Ż�
�����������ű���ǰ����ʾ�����ܿ��������������ṩ�Ĺ����Ǻ����ģ���������ϣ����һ���������ǣ������Ƕ����ӳ����еĹ������ء����˶����д�����и���ϸ�ĵ���֮�⣬������Ϊ���¼����п��ܼ����������ܡ�ʱ��ʽ���ȷ� ��ǰִ�м��������ʱ���ǿɱ�ģ�����ȡ����Ҫ���Ƶ��ڴ���������Remusȷ����ÿ��ʱ�ڵĿ�ʼ�����ܱ�����VM���𣬵���ǰ����δ���Կ��ƿ����ڸ���ʱ��֮��ı��״̬����Ϊ���ṩ���ϸ�ĵ��ȱ�֤�����Ը��ݼ����ҳ���������ڼ���֮�����Ž��ͷÿͲ������ٶ�[10]�����ȿ����ӳٶ�������������Ӧ�ó������磬��3.3�������۵�SPECweb����������ģ��Ӧ�ó��������ô�������������ܡ��������ֲ�����������չӰ��ҳ��������Ա�����ҳ������ij����ˮλ��ʱ���ûص�����������Ϊֱ����ͣ�����
ҳ��ѹ�� �Ѿ��۲쵽������д����ͨ�����ı����ݿ��5�C20��[35]�����RAM�������Ƶ����ԣ������ͨ��������ͬһҳ��ǰ���������������RAM���Լ�����Ҫ���Ƶ�״̬��
Ϊ������ѹ����������DZ�ںô������������һ������ѹ������ԭ�����ڴ���һ��ҳ��֮ǰ����ϵͳ������Ƿ��������ǰ����ҳ��ĵ�ַ����LRU���������ڻ�������ʱ��ҳ�潫����ǰ�İ汾����XOR���������콫�����г��ȱ��롣��ҳ��д�벻���Ĵ�ҳ��ʱ�����ṩ�����ŵ�ѹ�������ܶ��ڴ������������˵������ˣ��������൱һ����ҳ���ѱ��ĵ�XORѹ����Ч�ĵز�������Щ����£�ͨ���㷨������gzipʹ�õ��㷨������ʵ�ָ��̶߳ȵ�ѹ����
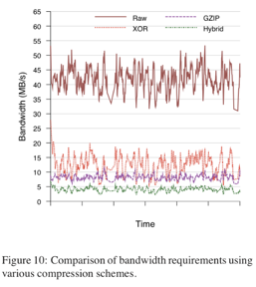
���Ƿ��֣�ͨ��ʹ��һ�ֻ�Ϸ���������ÿ��ҳ�����Ƚ���XORѹ�����������XORѹ���ȵ���5��1���в�������һҳ�����˻ص�gzipѹ�������ǿ��Թ۲츴�����ϵĵ���ѹ����Ϊ10��1��ͼ10��ʾ�˵�3.3�����������ں˱��������60������MBps���ĵĴ����������СΪ8192ҳ��ƽ������������Ϊ99����
ѹ�����������ܻ����ĸ��������ϵĶ����ڴ��CPU��Դ����������XORѹ������֮�������������Ӧ��ͨ�����ٸ�������Ĵ����Լ���֮����������������ջسɱ������ӳ١�
дʱ���Ƽ��� ��ǰ��ʵ�ֽ�����ÿ��������ͣһ��ʱ�䣬ʱ�䳤��������һ�����������ѱ�Ū���ҳ���������Թ�ϵ��ͨ������ҳ���Ϊдʱ���Ʋ������ָ����Լ������ֿ������������Խ��������ͣ��ʱ����ٵ���ÿͿ��õĹ̶�������RAM���������Ǵ���ͨ��ΪXenӰ�ӷ�ҳϵͳ�ṩһ���û��ռ�ӳ��Ļ�������ʵ��дʱ���ƣ��ڻָ���д����Ȩ��֮ǰ�������Խ�������ҳ�渴�Ƶ��û������С����ƹ���Ȼ����Դ�COW����������ȡ���б��Ϊ�Ѹ��Ƶ�ҳ�棬������ֱ�Ӵ�guest�������ȡ���ǡ�����ҳ��ɺ�Xen COWģ����Խ����ڻ������еĿռ���Ϊ���ظ�ʹ�á��������������������Լ���ͣguest��������Ӷ����·����COW����������ֹͣ�����Ʋ���
4 Related Work ��ع���
״̬���ƿ����ڼ���������ִ�У�ÿ��������Ч�ʺ�ͨ�������в�ͬ��ƽ�⡣����ͼ����ϣ�����Ӳ���ĸ��ƿ�������ɿ��Ľ�����������ǣ���������ȣ�Ӳ���Ŀ����ɱ�Ҫ�ߵö࣬��ˣ�Ӳ�����ƴ������Եľ������ơ����⻯��ĸ��ƾ���Ӳ�������������ŵ㣬��������ͨ������ʵ�ֵģ���˳ɱ��ϵ͡����ǣ���Ӳ��һ�������⻯����临�ƵIJ���ϵͳ��Ӧ�ó���״̬û�������ϵ��˽⡣�������������Բ������ϵͳ��Ӧ�ó�����Ӧ�ó������еĽ��̼��㣬��Ϊ�����븴������ϵͳ�����ǵ������̡���Ҳ����Ч�ʽϵͣ���Ϊ�����ܻḴ�Ʋ���Ҫ��״̬��Ȼ������Щ���������ٵ���ս�ǣ���ɼ����״̬Ԫ��֮�����������ڲ�֪�����к���ʶ��ϵͳ�����������з�������������Щ������Ʊ����⻯�еļ���Ҫ���ӵöࡣ
�����Ǩ������ǰ������Remus������Xen��ʵʱǨ�Ƶ�֧��֮��[6]����������������չ��֧��Ƶ����Զ�̼��㡣Bradford���ˣ���չ��Xen��ʵʱǨ��֧�ֵķ����־���״̬��guestһ��Ǩ�ƣ��Ա�����ڲ���ԭʼϵͳ��������洢��Զ�̽ڵ�������������[3]��
��Remusһ����������ĿҲʹ����������ṩ�߿����ԡ������ǵĹ�����ӽ�����Bressoud��Schneider������[4]������ʹ�����������������Ҫϵͳ�����������¼�ת��������ϵͳ���ڱ���ϵͳ�а�ȷ���ķ�ʽ�ط����ǣ��Ը�����Ҫ״̬��ȷ�����طűȼ����⻯��Ŀ����ϵ�ṹ��Լ��Ҫ�ϸ�ö࣬������ҪVMM���ض�����ϵ�ṹ��ʵ�֡�
Bressoud��Schneider�Ĺ���������ȷ�����ز�����һ���ش�ȱ���ǣ���������չ�����CPU��������ȷ�����ķ��ʹ����ڴ��˳���DZ�Ҫ�ģ���Ҳ�����ѡ����˳��Խ�������⡣���磬�������ݼ�¼��[34]��һ��Ӳ��ģ�飬����̽���ٻ����һ�����������Ա��¼������������ʹ����ڴ��˳��ͬ����Dunlap������һ����������������CREWЭ�飨������ȡ������д�룩ͨ��ҳ�汣��[8]Ӧ���ڹ����ڴ档������Щ����ȷʵʹSMP����ȷ���Ե��طų�Ϊ���ܣ������ڿ����ߣ������沢���̶�����������������в���������Ƿ���С����ǵĹ�����ȫ�ܿ���������⣬��Ϊ������Ҫȷ�����طš�
�������־��¼���ز� �������־��¼�����ڸ߿����������������;�����磬��ReVirt [9]�У����⻯������Ϊ��¼Ŀ��ϵͳ�е�״̬�仯�ṩһ����ȫ�����Ա�Ϊ���ּ��ϵͳ�ṩ���õ�ȡ֤֤�ݡ��ز���ϵͳ��ԭʼϵͳ��ֻ������������Ϊ�����´���ϵͳ�������漰���¼������������иø�������־��¼Ҳ�����ڹ���ʱ�����еĵ�����[13]����ReVirtһ�����ûط���������ȡ֤Ŀ�Ķ��ط�ϵͳ��
����ϵͳ���� ���������ϵͳ������Accent [25]��Amoeba [18]��MOSIX [1]��Sprite [23]������֧�ֽ���Ǩ�ƣ���Ҫ���ڸ���ƽ�⡣ʹ������Ǩ�ƽ��й��ϻָ�����Ҫ��ս�ǣ�Ǩ�ƵĽ���ͨ���Ὣʣ����������ڴ���Ǩ�����ǵ�ϵͳ����Ϊ�������������Ĺ��ϣ�������Щ������ϵ�DZ�Ҫ������������ϵͳ�ĸ����Ժ���Щ������ϵ�Ľṹ������������������ġ�
�Ѿ�������һЩ�����ڲ���ϵͳ�����ϸ���Ӧ�ó��� Zap [22]������Linux�ں����������⻯�㡣����Ϊÿ������ϵͳ���¹����˷��������ڸ����汾֮����ϸά����
ͼ��ݷ��� һЩӦ�ó����֧�ֽ���Ǩ�ƺͼ��㡣���֧��ͨ�����ڲ���Ӧ�ó����ܣ���CoCheck[29]��ͨ��������Ǩ�����ڸ���ƽ�⣬���������ڳ��ֹ���ʱ�ָ������ֲ�ʽӦ�ó���
���ƴ洢�����������ѻָ���ȡ֤�Ŀɼ���洢����Ҳ�����˴��������� Linux����������[14]�ṩ��һ��������ʽ�Ŀ�洢��дʱ���ƿ����Ӳ�[33]��ͨ���ڿ鼶���ṩ����������дʱ���ƿ��գ������Ľ��˴����ˮƽ��ͼ�ļ�ϵͳ[11]����������һ�δ���һ�����ա�������������RSnapshot�����������ļ�ϵͳ֮�ϣ���ͨ��һϵ��Ӳ���Ӻ��ֱ����������������ա� DRBD [26]�ǿ��豸�ϵ������������ؽ��临�Ƶ���һ̨��������
Ͷ��ִ����ʹ���Ʋ���ִ�н�I / O�����������뿪���ķ����Ѿ�������ϵͳ���á��ر��ǣ�SpecNFS [20]��Rethink the Sync [21]�����������Ƶķ�ʽʹ���Ʋ⣬��ʹI / O�����첽�� Remus����Щϵͳ�IJ�֮ͬ�����ڣ����Կͻ����Ŀ�I / O��ָ�ʼ�ձ��ֲ��䣺��������Ӧ���ڱ����������̡�ȡ����֮���ǣ����ǵ�ϵͳ�������ɵ������������Ը����Ʋ�ִ�е��ⲿ�ɼ�Ч����ֱ�����״̬����ȫ����Ϊֹ��
5 Future work
���ڼ�Ҫ���������Ǵ���̽����һЩ�����Ը��ƺ���չRemus��������������һ��������ʾ���������߿����Է����������Ŀ��������Dz������ġ����ǣ�����������ʵ�ֻ������ᡣһЩDZ�ڵ��Ż��������д�̽������ɵ�3.4�������۵�Ŀ���Ż������Ǵ����о���ͨ�õ���չ����������������
��ʡ�Ż� Ŀǰ��Remus������״̬�������ϸ��Ҫ�����磬���������ٻ���ҳ�治��Ҫ���ƣ���Ϊ���ǿ��Լشӱ����ϵij־��Դ洢�ж�ȡ��Ϊ��������һ�㣬��������豸���Լ�¼Ϊ���̶�ȡ�ṩ�����Ļ������ĵ�ַ���Լ���صĴ��̵�ַ������ڴ��̶�ȡ��ɺ�δ����Щҳ�棬���ڴ渴�ƹ��̿��ܻ�������Щҳ�档Զ�˽����������̸��������·�����ȡ���ݣ�����䶪ʧ��ҳ�档���ڷ��صĴ��̹������أ���Ӧ�ÿ��Դ�����״̬����ʱ�䡣
Ӳ�����⻯֧�� ��������ʵ�����ڿ���ʱȱ��֧��Ӳ�����⻯���豸������ֻ�����⻯�Ŀͻ�������ṩ�����Ƶ�֧�֡����ǣ������Ѿ��о���֧����ȫ���⻯��������Ĵ��룬����ǰ��ʮ�ֹ�����ʵ���ϣ�����֧�����⻯��Ӳ���ṩ�˸��õķ�װ����������ܱȰ�����ʵ�ָ���
��Ⱥ���� ��չϵͳ�Ա����������ӵ������Ǻ����á���ÿ�����������Զ������ܵ�����ʱ��Э��������ʹ�ڲ�����ͨ���ܹ��ڲ����л��������¼������С����п���������߷ֲ�ʽӦ�ó�����������������й��������������е�����webӦ�ó�����������Ⱥ���Ƶ�֧�ֿ���ͨ���ֲ�ʽ����Э�����ṩ���������ǵ�ͬ��Gang Peng��˶ʿ����[24]���������ģ���Э��ʹ����Remus�ṩ�ļ�������ṹ�����ڰ汾��
���ѻָ��� Remus��Second-Site [7]��Ŀ�IJ�Ʒ������Ŀ��Ŀ�����ṩ����ϵͳ�����������Ծ������Ա����������������档Ϊ�������������ã��������ڼƻ�Remus�Ķ�վ�㲿���ڳ����벿���У������ӳٽ������ע�����⣬��Ҫ����������������Ӧ���ض���Internet����
��־�ṹ���������� ����������չRemus�Ѿ�����ͱ����ܱ���VM������ִ����ʷ���������������µļ��㡣 ͨ�����ͻ��ڴ�ӳ�䵽Parallax [17]������רΪ��Ƶ������Ƶ������洢������ϣ���ܹ��Էdz���ϸ��������Ч�ش洢�����־��Ժ�˲̬״̬�� ��Щ�����ڹ��������Ժ�ȡ֤����ʱ�dz����á����������ṩ��״̬���лָ��ķ�����ƣ���������operatorerror�����ɶ�������������ȣ������
6 Conclusion ����
Remus��һ����ӱ��ϵͳ��������������Ʒ�����е������ϸ���߿�����Ӳ��ϵͳʹ�����⻯����װ�ܱ��������������ִ��Ƶ��������ϵͳ�������첽�������ִ�еĵ����ض��������״̬��
�ṩ�߿�������һ���������Ҵ�ͳ����Ҫ�����ijɱ������ϵ�Ŭ���� Remusͨ�������⻯ƽ̨�㽫�߿����Գ���Ϊһ�������ʵ����Ʒ���������ض�������������Լء��� HA�����κθ߿�����ϵͳһ��������Ҳ����û�д��۵ģ�Ϊȷ��һ�µĸ��ƶ���Ҫ�����绺���Ҫ��dz����ӳٵ�Ӧ�ó�����������ܿ���������Ա�����벿�����Ӳ������ЩӲ��������N��1������ʹ�ã�ʹ��һ��������������������������Ϊ���ֿ����Ľ�����Remus��ȫʡȥ���ĵ���Ӧ�ó������ṩHA���ܵ�������������Ҫ������;��Ӳ����
Remus�������ִ�������HA��ƿռ���һ��δ��̽���ĵط�����ϵͳ������һ�°�ť���ɼؽ�������̬���ṩ���������е�VM��������Ϊ����ģʽ��ϣ��Ϊ�ͻ��ṩ���컯������й��ṩ���ر�����������