centos7+Hadoop1.0.3单机和分布式配置
- 单机模式
-
- 先决条件
- 文件导入centos和配置jdk
- 配置hadoop
- 分布式模式
单机模式
先决条件
Vmware虚拟机,安装好centos7,Hadoop1.0.3,JavaTM1.5.x以上,必须安装,建议选择Sun公司发行的Java版本。
以上软件准备好就可以开始了
注:jdk和centos必须同时是x64或者86
文件导入centos和配置jdk
主机往linux虚拟系统传文件有好几种方法,如ftp,usb,共享文件夹等等
大家怕麻烦可以用u盘,或者如果你安装的是带GUI的centos,并且你安装了VMware tools,那么可以直接拖拽文件夹到虚拟机了里,我用的是不带界面的centos,所以就稍微介绍一下,共享文件夹吧,当然u盘方式也是十分便捷的。
此处我使用的是共享文件夹
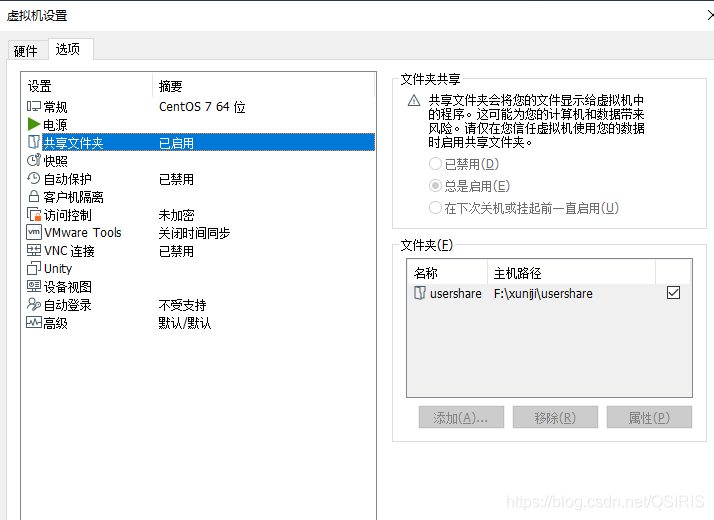
这个基础设置大家应该都会
接下来就是centos执行的了
在终端执行下列指令
先创建挂载目录mkdir /mnt/hdfs (注:改文件夹名字可以自己取)
执行挂载vmhgfs-fuse .host:/usershare /mnt/hdfs(注:共享文件夹名字要和设置的一样)
注:只需要写共享出来的文件夹即可,也可以通过vmware-hgfsclient查看共享的文件夹名。
然后就是把文件拷贝到共享文件夹,再从虚拟机centos复制就行
cp 源文件(source) 目标文件(destination)
源文件就是

这是我共享文件夹的文件
单独为java准备文件夹,我准备的是/usr/local/java
然后就是把/mnt/hdfs/jdk-6u32-linux-x64.bin拷贝到/usr/local/java
就是用上便那个cp指令
然后就用cd /usr/local/java
进入后执行jdk-6u32-linux-x64.bin

会得到一个jdk1.6.0_32文件夹
在上述文件夹运行完后,就要修改配置文件配置环境变量
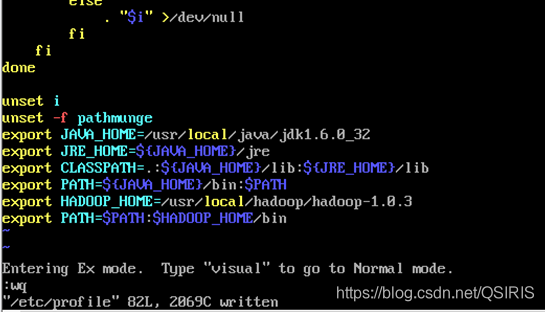
用指令:vi /etc/profile在配置文件末尾添加
export JAVA_HOME=/usr/local/java/jdk1.6.0_32
export JRE_HOME=${
JAVA_HOME}/jre
export CLASSPATH=.:${
JAVA_HOME}/lib:${
JRE_HOME}/lib
export PATH=${
JAVA_HOME}/bin:$PATH
然后退出保存(输入i进入编辑模式,按esc在切换大写输入下Q会到命令模式,输入wq按回车就保存退出了)
刷新缓存载入最新配置source /etc/profile
然后可以输入:java -version验证。

配置hadoop
(可选操作,做实验的话建议直接root下运行就行,简单还省事,不需要创建用户,至于大佬们也不需要来看教程创建用户了)由于我直接用的是root用户,最好情况下还是单独创建一个用户来管理比较好
sudo useradd -m hadoop -s /bin/bash
sudo passwd hadoop
sudo adduser hadoop sudo
为了获取Hadoop的发行版,从Apache的某个镜像服务器上下载最近的 稳定发行版。
这里我们使用安装包中的稳定版hadoop-1.0.3.tar.gz
此处我也创建了一个文件夹来放hadoop文件目录是/usr/local/hadoop
复制文件方法往上看看jdk那里

运行tar -xzvf hadoop-1.0.3.tar.gz
解压成功后会得到上图那个蓝色的文件夹
下图是解压的显示,由于显示东西较多,我就不一一截图了

解压所下载的Hadoop发行版。编辑 conf/hadoop-env.sh文件(还是在Hadoop文件夹,解压那个蓝色的里边,用cd进入就行),至少需要将JAVA_HOME设置为Java安装根路径。
下图是配置环境变量,和jdk操作一样,就是多加了后两行
刷新缓存载入最新配置source /etc/profile
完成后可以输入hadoop来验证配置是否成功
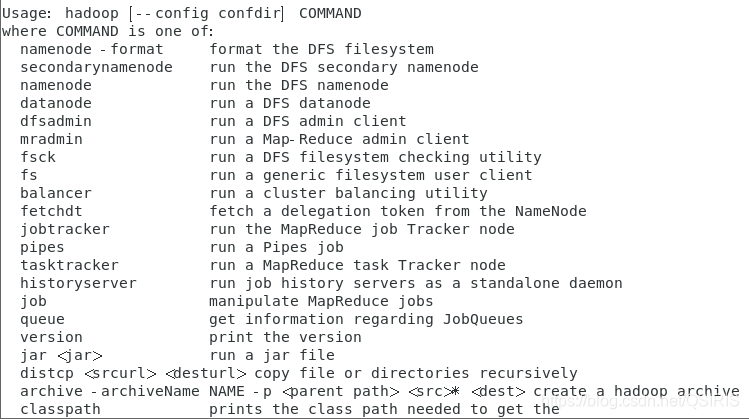
关于 Warning: $HADOOP_HOME is deprecated,是由于hadoop脚本中对HADOOP_HOME的环境变量设置做了判断,我的环境不需要设置HADOOP_HOME环境变量,有强迫症的可以编辑"/etc/profile"文件,去掉HADOOP_HOME的变量设定
分布式模式
(1) 以下操作在上述单机模式的基础上执行
(2) 关闭防火墙和selinux
systemctl status fiewalld.service #查看防火墙状态
systemctl stop fiewalld.service #临时关闭防火墙
systemctl disable fiewalld.service #禁止开机自启动
systemctl start fiewalld.service #打开防火墙
systemctl enable fiewalld.service #打开开机启动
不关闭防火墙开放端口也可以,由于是实验所以从简操作
getenforce #查看状态
setenforce 0 #临时关闭
setenforce 1 #临时打开
这三行用于selinux的打开关闭
注:3,4步骤中3的主机ip和名字自己取,怎么好记怎么来,此处取名和某些操作是我参考的一位大佬的博客,由于hadoop版本不同,所以我在原有基础上修改了一下,附上大佬的链接,有需要请跳转
https://blog.csdn.net/weixin_44546992/article/details/105875133
(3) 修改主机名(可选,最好修改便于记忆)和网络配置
hostnamectl set-hostname s161 #修改主机名命令
hostname #查看主机名命令
网络配置命令:
vim /etc/sysconfig/network-scripts/ifcfg-ens33(命令输入到ifcfg-en处可以按两次tab键获取提示)

service network restart #重启网络
(4) 配置`hosts’文件
vi /etc/hosts #配置节点的域名解析

前边是ip地址,后边是四台主机名字
(5) 把虚拟机复制三份分别修改上图ip和主机名字
重要: 复制完后其他三台虚拟机设置看步骤3的修改主机名字和ip,分别为步骤4的后3台
(6) ssh无密匙验证配置
- 修改配置信息
vi /etc/ssh/sshd_config
将下面部分前面的注释“#”去掉
#RSAAuthentication yes
#PubkeyAuthentication yes
#AuthorizedKeysFile .ssh/authorized_keys
(有那个去哪个,不同版本不太一样,centos7我这个就去一个第二个就可以了)
2. 生成密钥
ssh-keygen -t rsa
一直连续回车就行
3. 将公钥写入认证文件
这一步是将自己的公钥写入认证文件
cat /root/.ssh/id_rsa.pub >> /root/.ssh/authorized_keys
连接其他机器,将他们的密钥也写入认证文件
ssh root@s162 cat /root/.ssh/id_rsa.pub >> /root/.ssh/authorized_keys
另外两台同理,改名即可
4. 查看认证文件的内容
cat ~/.ssh/authorized_keys
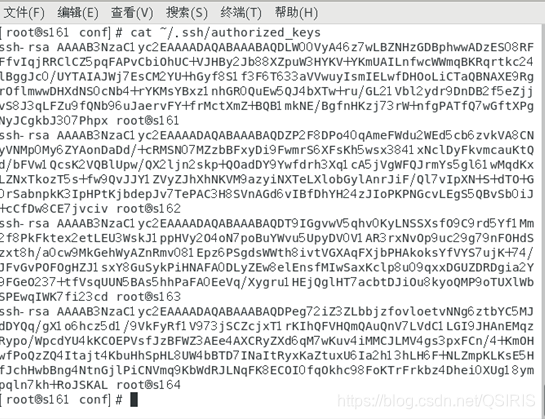
四台设备都在,说明添加成功
5. 查看known_hosts中的主机列表
vi ~/.ssh/known_hosts
执行之后结果是下图的红圈内的东西,没有最后一个s161
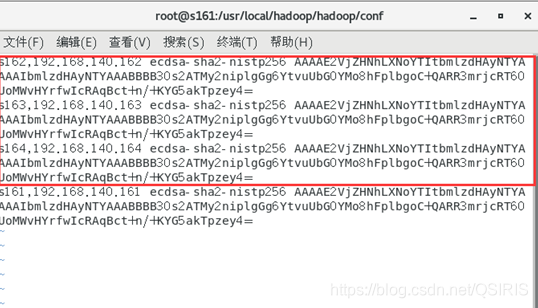
用这个指令
ssh s161
连接下s161则变成上图全部的
6.将认证文件复制到其他主机
scp ~/.ssh/authorized_keys root@s162:~/.ssh/authorized_keys
主机的名字则自己修改,第一次链接,估计都会需要密码
7. 验证测试
ssh s163

这里已经变成s163主机了,可以操作163主机了
Exit就能退出回到本机
(7) hadoop集群配置(重中之重)
前边单机模式中已经配置过hadoop-env.sh这里就不需要了
(都在hadoop安装目录的conf里边)
配置方法就是通过cd进入文件夹,再通过vi编辑器或者vim编辑器去修改,如果是用的GUI可以直接在文件夹中修改,总之,怎么方便怎么来吧
1.配置core-site.xml文件
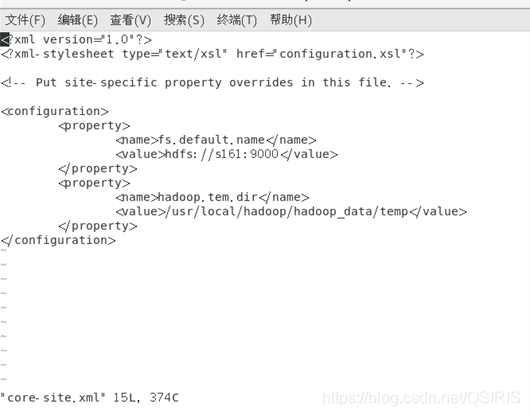
<configuration><property><name>fs.default.name</name><value>hdfs://s161:9000</value></property><property><name>hadoop.tem.dir</name><value>/usr/local/hadoop/hadoop_data/temp</value></property>
</configuration>
3.配置mapred-site.xml
这个文件本身不存在先执行以下命令:cp mapred-site.xml.template mapred-site.xml
复制一份去修改
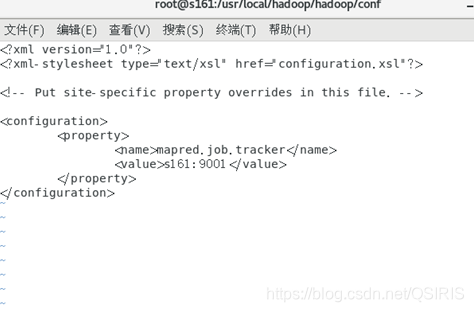
<configuration><property><name>mapred.job.tracker</name><value>s161:9001</value></property>
</configuration>
- 配置master文件
修改localhost为master - 配置slaves文件【master主机独有】
去掉"localhost",每行只添加一个主机名,把剩余的Slave主机名都填上。
比如s161的主机就不写161,其他三台同理
s162
s163
s164
6.配置其他机器
用scp命令发送一份过去就行
例如:
scp /usr/local/hadoop/hadoop/conf/core-site.xml root@s162: /usr/local/hadoop/hadoop/conf/core-site.xml #文件夹路径是我自己的,自行修改
发送完后回到上边4,5步,分别修改剩下主机
(8) 启动及验证
1.格式化HDFS文件系统
在主机上进行操作(备注:只需一次,下次启动不再需要格式化,只需 start-all.sh)
hadoop namenode -format
2.启动hadoop
在hadoop文件夹的bin中,即用cd进入到该文件夹下
直接执行start-all.sh指令
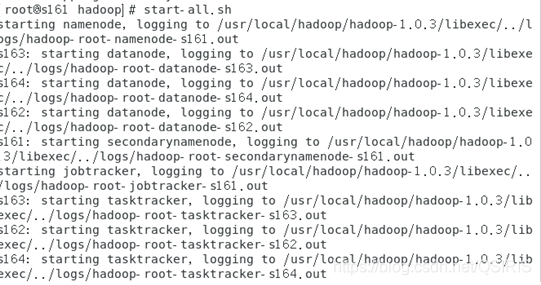
验证hadoop
方法1:在主机上用 java自带的小工具jps查看进程
直接输入jps
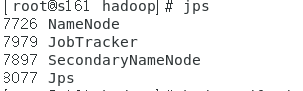
在从机上也用jps查看进程

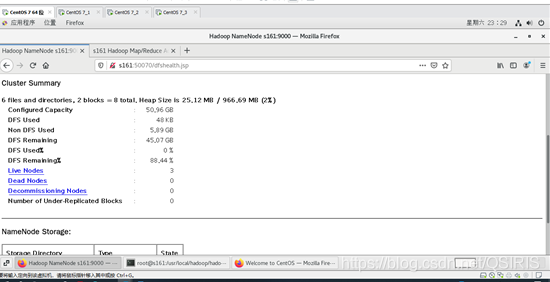
方法2:用hadoop dfsadmin -report
用这个命令可以查看Hadoop集群的状态。
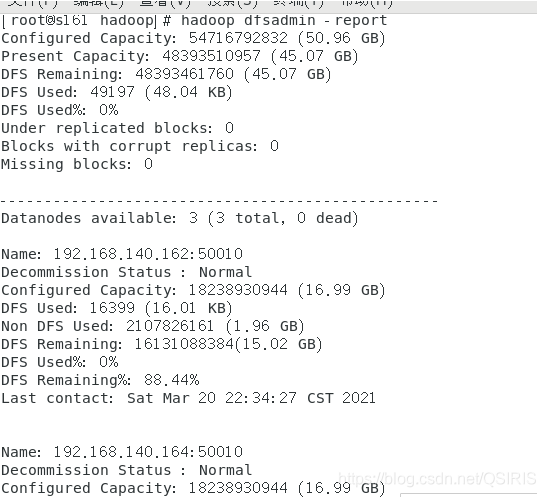
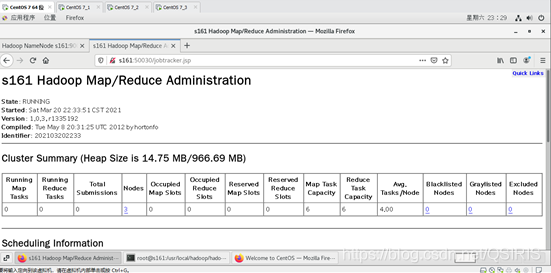
或者,在界面的centos7下,在游览器中用主机名:50070端口查看或者50030端口,其他端口自行百度吧