1. ǰ��
����Executor����������ӣ���ο�ǰ�沩�ģ������ݣ�Spark Core���ģ���LogQuery��������˵��Executor���������RDD�����ӣ���Executor����reduce�����ʱ����������������ʱShuffle���ݣ��������ڴ����У�������Action���ӵ��ã�������ξ�����ShuffleMapTask��ִ�еġ�
ǰ�沩����Ҳ�ᵽ�ˣ���ʲôShuffleWrite����ShuffleHandler�������ģ�����ƪ��������Ҫ���������SortShuffleWrite�ĺ����㷨ExternalSorter.
2. �ṹAppendOnlyMap
��ǰ�沩���н�����SortShuffleWriter����ExternalSorter.insertAll�������ݲ�������ݺϲ��ģ�ExternalSorted��ʹ����PartitionedAppendOnlyMap��Ϊ���ݵĴ洢��ʽ
������PartitionedAppendOnlyMap�Ľṹ
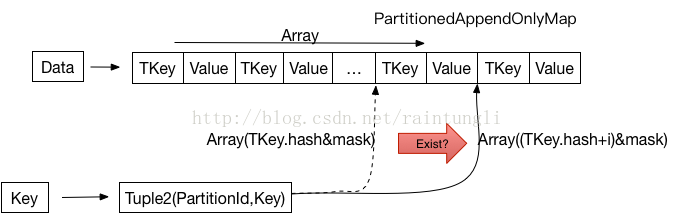
��Ȼ����ΪMap,����������ͳ�����Map�Ľṹ����̫һ�������沢û��ʹ���������������ͬ��hashֵ��key���������key��hashcode��ͬ��ʱ��key����ͬ����ͨ��i�ĵ���һֱ�ҵ���������е�λ�á�
�����м���ע��㣺
- Key ע�������Key������ͨ��Map���ֵ�Key, ����Tuple2(PartitionId,Key)���ɷ�Ƭ�Ķκ�key��ϵ�����key
- ����PartitionId? ������Partitioner��������
2.1 Partitioner
Partitioner�ķ���
abstract class Partitioner extends Serializable {def numPartitions: Intdef getPartition(key: Any): Int
}ͨ������getPartition�����ҵ���Ӧ��partition��Ӧ�Ŀ飬�����õ���HashPartitioner
def getPartition(key: Any): Int = key match {case null => 0case _ => Utils.nonNegativeMod(key.hashCode, numPartitions)}���� key��hashCode�������ܵķ�Ƭ�����࣬���䵽��Ӧ��Ƭ��
3. Spill
�ڴ����ݵ�����½��й鲢�����ںϲ����������dz�����ʹ��AppendOnlyMap�������ݵĹ鲢�ڴ���Ȼ�Dz��㹻�ģ��������������Ҫ�Խ��ڴ�����Ѿ��鲢������ˢ�������ϱ���OOM�ķ��ա�
����Spill�����̵ķ�ֵ
- �ڴ棺��ȻJava�Ķ��ڴ��������JVM������ܿأ�����Spark�Լ�ʵ����һ���ĵ��������ڴ�������ڴ��������TaskMemoryManager����й���
if (elementsRead % 32 == 0 && currentMemory >= myMemoryThreshold) {// Claim up to double our current memory from the shuffle memory poolval amountToRequest = 2 * currentMemory - myMemoryThresholdval granted = acquireMemory(amountToRequest)myMemoryThreshold += granted// If we were granted too little memory to grow further (either tryToAcquire returned 0,// or we already had more memory than myMemoryThreshold), spill the current collectionshouldSpill = currentMemory >= myMemoryThreshold}spark.shuffle.spill.initialMemoryThreshold- ���ݵ��������е�ʱ��ÿ���������Ƚ�С���������ݵ������dz���Ϊ�˱�����AppendOnlyMap���д��������ݣ���Spill��ʱ��ͬʱ������ʹ�������Ŀ��ƣ�
spark.shuffle.spill.numElementsForceSpillThreshold3.1 ���Spill?
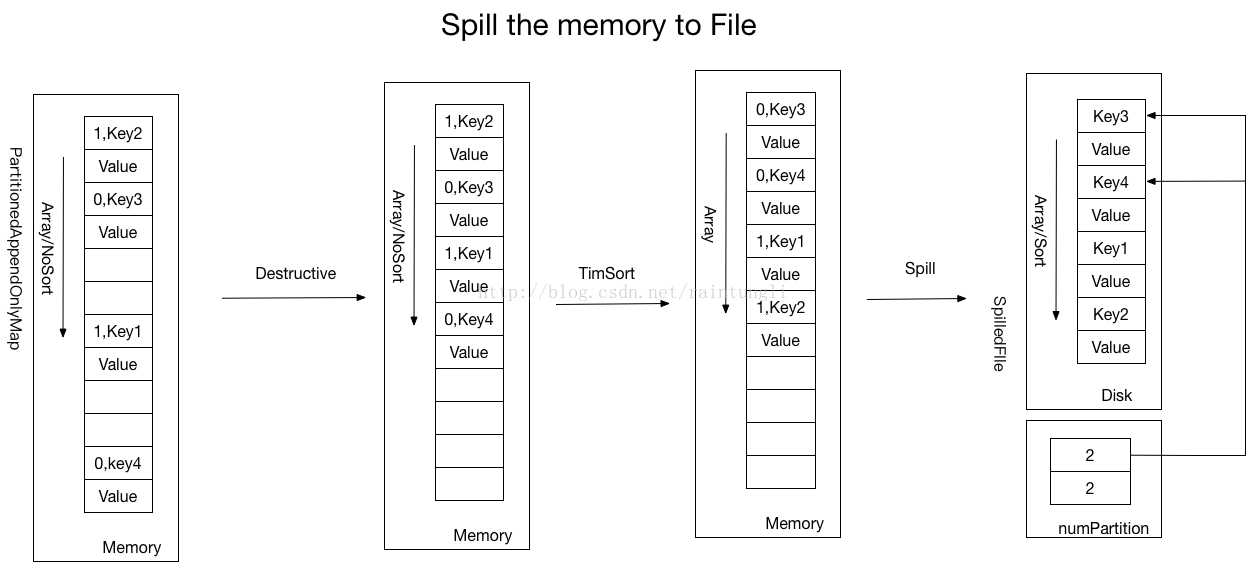
- �������飬��������IJ�����KV�Ŀռ��Ƴ�
- ������������ͬһ�������Keyʹ��TimeSort��������TimeSort���ڴ˴�����
- Spill���ļ���ʱ��ֻ�DZ��������л���Key,Value��û�б���Key��������Ϣ������SpilledFile�Ķ������м�¼ÿ��partitionkey������������
4. ����ShuffleWrite�������ļ�
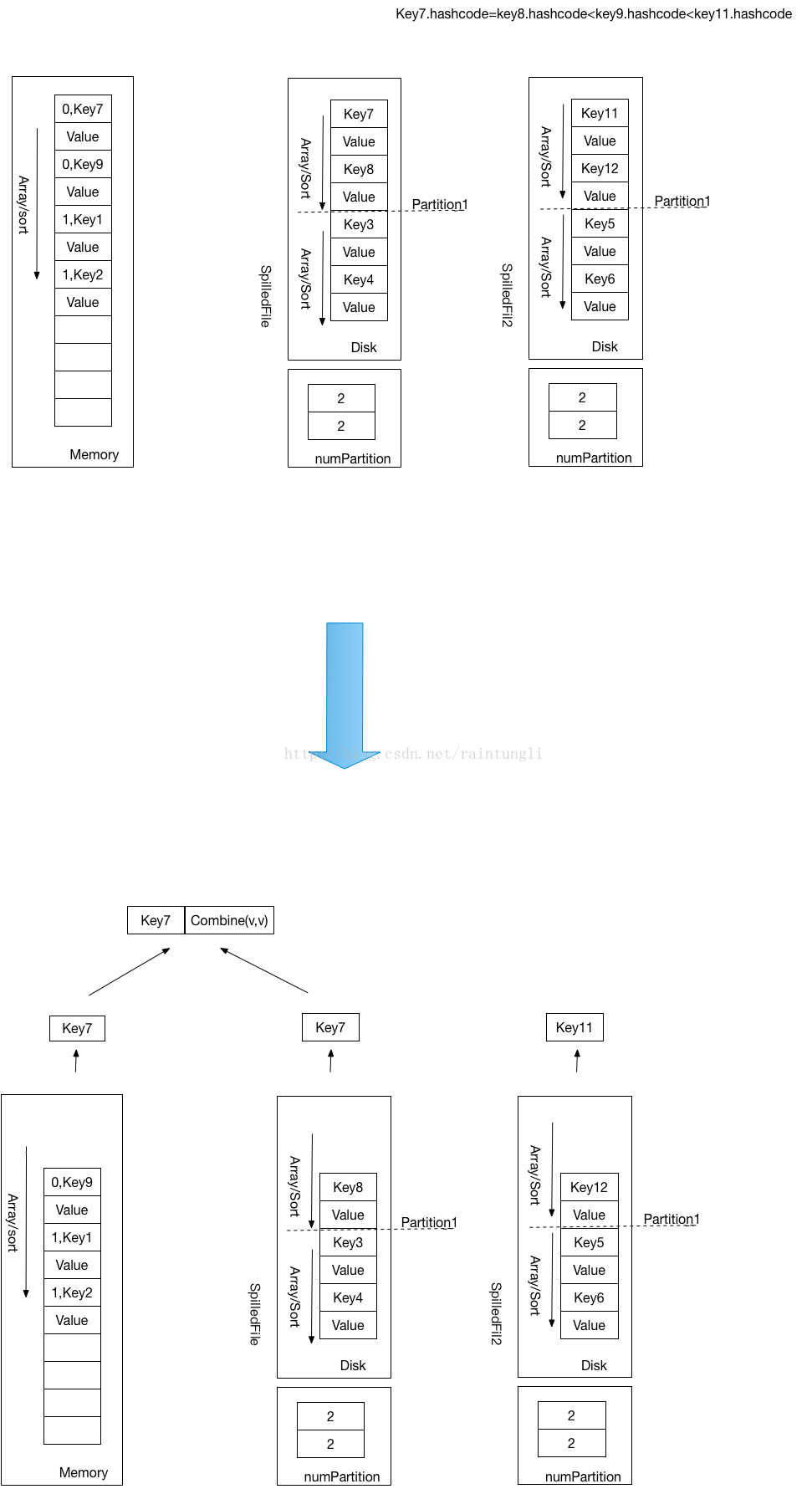
- ���ȶ�AppendOnlyMap���й鲢������
- ��ʼ��ͬһ����Ľ��й鲢
- ��AppendOnlyMap��SpilledFile���ļ��������ȼ���Queue�ĵ�����ÿ�ε���������Queue��һ����С��Key����С��Key����HashCode��С
private def mergeSort(iterators: Seq[Iterator[Product2[K, C]]], comparator: Comparator[K]): Iterator[Product2[K, C]] ={val bufferedIters = iterators.filter(_.hasNext).map(_.buffered)type Iter = BufferedIterator[Product2[K, C]]val heap = new mutable.PriorityQueue[Iter]()(new Ordering[Iter] {// Use the reverse of comparator.compare because PriorityQueue dequeues the maxoverride def compare(x: Iter, y: Iter): Int = -comparator.compare(x.head._1, y.head._1)})heap.enqueue(bufferedIters: _*) // Will contain only the iterators with hasNext = truenew Iterator[Product2[K, C]] {override def hasNext: Boolean = !heap.isEmptyoverride def next(): Product2[K, C] = {if (!hasNext) {throw new NoSuchElementException}val firstBuf = heap.dequeue()val firstPair = firstBuf.next()if (firstBuf.hasNext) {heap.enqueue(firstBuf)}firstPair}}}- ���ҵ�һ����С��Key��ʱ�����ܱ��浽ShuffleWrite�ļ��У���Ϊ�п��ܴ�����ͬ����С��key�����Ի���Ҫ�ڵ����ҵ���һ����С��Key�����key��hashcode��ͬ��ʱ��Ҫ������ͬ��Key���кϲ�����ΪKey��������������HashCode�Ĵ�С��������ͬ����С��Key��������HashCode��ͬ��Key���������ͬ�����ͬHashCode�����飬������һ�ε�����queue�IJ��ң�ֱ���ҵ���Key��hashcode������С��Key����
if (!hasNext) {throw new NoSuchElementException}keys.clear()combiners.clear()val firstPair = sorted.next()keys += firstPair._1combiners += firstPair._2val key = firstPair._1while (sorted.hasNext && comparator.compare(sorted.head._1, key) == 0) {val pair = sorted.next()var i = 0var foundKey = falsewhile (i < keys.size && !foundKey) {if (keys(i) == pair._1) {combiners(i) = mergeCombiners(combiners(i), pair._2)foundKey = true}i += 1}if (!foundKey) {keys += pair._1combiners += pair._2}}
- ��k,v����д��shufflewrite���ļ�Shuffle_shuffleId_mapId_reduceId.data��ȥ
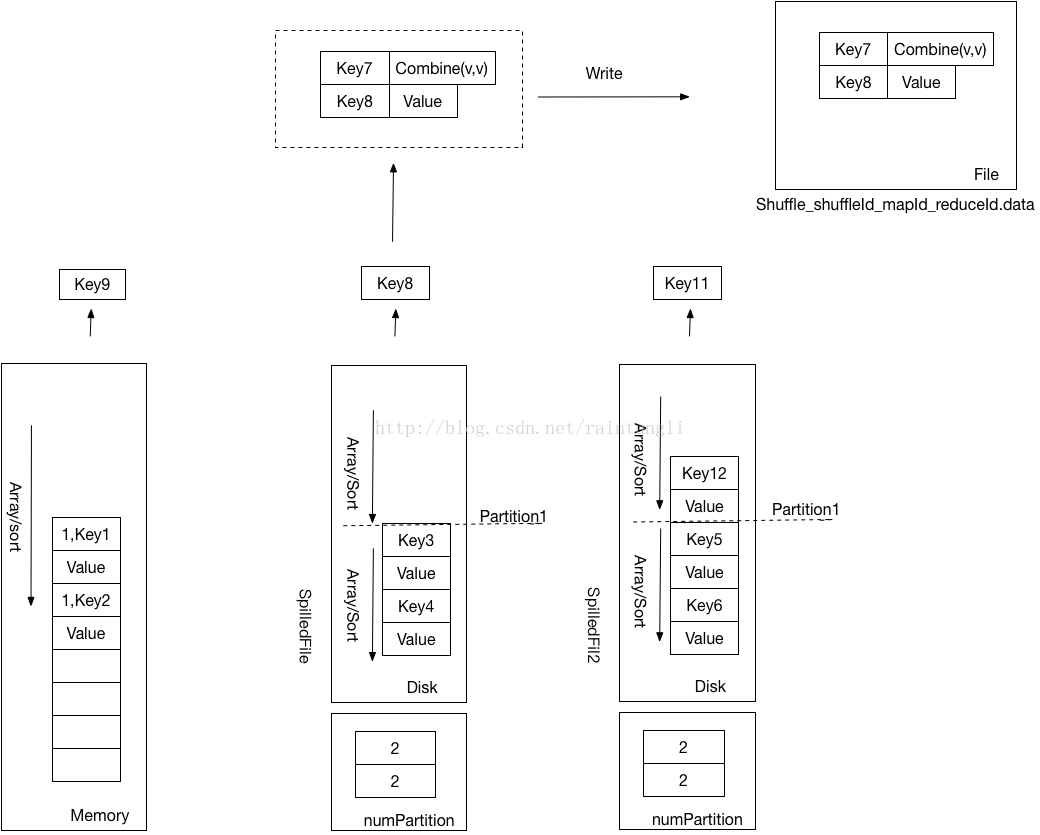
- �ظ�ǰ�����Ϊֱ�����е�key����������
- ǰ��Ĺ鲢��������(Partition)Ϊ��λ�ģ���data���ļ��ﲢû�б�������������Ϣ������ÿ������һ��Partition��ʱ��(SpilledFile�ļ�����Ҳû��Partition����Ϣ��������ͨ��SpilledFile�ṹ�е�numPartition���������ж�Partition�������Ƿ��Ѿ�����)��������һ��Segement��Segement ���¼������鱣����data�ļ���ij���
- �������Shuffle_shuffleId_mapId_reduceId.index�ļ����ļ����¼��ÿ��Partition��data�ļ��е�λ��
5 �ܽ�
- ʹ��AppendOnlyMap���ݽṹ�����������ݵĺϲ�����
- ����������ǽ��з����ϲ����㣬�����ķ�ʽ����Partitioner������
- ���ڴ治����ʱ�������ͬ�����µ�������������Spill����ʱ�ļ�temp_shuffle_UUID
- �������е����ݼ��ϣ�AppendOnlyMap������ݺͶ��Spill����ʱ�ļ���������������ݺϲ�
- ����Shuffle_shuffleId_mapId_reduceId.data �����������ļ���Shuffle_shuffleId_mapId_reduceId.index��¼������λ��