论文地址:https://doi.org/10.3390/rs13030498
近年来,人们提出了大量基于深度卷积神经网络(CNN)的高光谱图像(HSI)分类方法。本文提出的基于cnn的方法虽然具有空间特征提取的优势,但它们难以处理序列数据,且cnn不擅长对远程依赖关系进行建模。然而,HSI的光谱是一种序列数据,通常包含数百个波段。因此,cnn很难很好地处理HSI处理。另一方面,基于注意机制的Transformer模型在处理序列数据方面已经证明了其优越性。为了解决长距离HSI序列谱的捕获关系问题,本研究采用Transformer进行HSI分类。具体而言,本研究提出了一种新的分类框架SST (spatial-spectral Transformer, SST)用于HSI分类。在本文提出的SST中,利用设计良好的CNN来提取空间特征,并提出了一个改进的Transformer(一个连接密集的Transformer,即DenseTransformer)来捕获序列谱关系,使用多层感知器来完成最终的分类任务。此外,还提出了动态特征增广的方法,以缓解过拟合问题,提高模型的通用性,并将其加入到SST (SST- fa)中。此外,针对HSI分类中训练样本有限的问题,将迁移学习与SST相结合,提出了迁移-SST (T-SST)分类框架。最后,为了缓解过拟合问题,提高分类精度,对基于T-SST的分类框架(T-SST-L)引入标签平滑。
根据模型的输入信息,基于CNN的HSI分类方法可以分为三类:光谱CNN、空间CNN和光谱-空间CNN。基于光谱CNN的HSI分类接收像素向量作为输入,使用CNN对仅在光谱域中的HSI进行分类。
现有的HSI分类CNN模型已经达到了最先进的性能;然而,仍然有一些限制。
- 首先,在基于cnn的方法中,忽略了输入HSI的一些信息,没有很好地挖掘这些信息。CNN是一种基于向量的方法,它认为输入是像素向量[35]的集合。对于HSI,它本质上具有基于序列的谱域数据结构。因此,在处理高光谱像素向量[36]时,使用CNN会导致信息丢失。
- 其次,学习远距离序列依赖是困难的。由于卷积运算处理的是一个局部邻域,CNN的接受域受到其内核大小和层数的严格限制,这使得它在捕获输入数据[37]的长依赖关系方面的优势较低。
最近,人们提出了一个名为Transformer[38]的模型,它基于自注意机制[39],用于自然语言处理。Transformer使用注意力来绘制输入序列中的全局依赖项。对于包括Transformer在内的深度学习模型,普遍存在梯度消失的问题,这阻碍了训练过程[40]的收敛。为了缓解梯度消失的问题,本研究提出了一种新型的Transformer,它使用密集连接来加强特征传播,名为DenseTransformer。
在此基础上,提出了两种基于DenseTransformer的HSI分类框架。
- 第一个分类框架结合了CNN、DenseTransformer和多层感知器。
- 在第二个分类框架中,将迁移学习策略与Transformer相结合,在训练样本有限的情况下提高HSI分类性能。
本研究的主要贡献如下:
- (1)提出了一种名为DenseTransformer的改版Transformer,该Transformer采用密集连接的方式来缓解Transformer中梯度消失的问题。
- (2)将CNN、DenseTransformer和多层感知器(multilayer perceptron,MLP)相结合,提出了一种新的HSI分类框架SST (spatial-spectral Transformer)。在该方法中,利用设计良好的CNN提取HSI的空间特征,利用DenseTransformer捕获HSI的序列谱关系,利用MLP完成分类任务。
- (3)为了缓解过拟合问题,提高模型的通用性,提出了动态特征增广方法,并将其加入到SST中,形成了一种新的HSI分类方法(即SST-FA)。
- (4)为了进一步提高HSI分类的性能,提出了另一种新的分类框架,即传递空谱Transformer(T-SST) 。所提出的T-SST采用在大数据集上预先训练的类vgg模型作为所使用的CNN在SST中的初始化(迁移学习)。因此,在训练样本有限的情况下,提高了HSI分类精度。
- (5)最后将标签平滑引入到基于Transformer变换的分类中。将标签平滑与T-SST相结合,形成了一种新的HSI分类方法T-SST-L。
本文提出的用于HSI分类的SST框架如图1所示。一般来说,分类方法分为三部分:基于cnn的空间特征提取、基于改进Transformer 变换的空间光谱特征提取和基于MLP的分类。

首先,对于HSI的每个波段,选择一个2D patch作为输入(按照波段,每个波段的维度是H×W),该patch包含待分类像素的相邻像素。一个训练样本有n个patch(即HSI的band数)。然后,使用一个精心设计的CNN提取每个2D patch的特征,然后将提取的特征发送给Transformer。然后,利用改进后的Transformer来获得序列空间特征之间的关系。最后,利用得到的空间-光谱特征得到分类结果。
2.1. CNN-Based HSI Spatial Feature Extraction
使用CNN来有效提取HSI的空间特征。我们使用2D-CNN分别提取每个波段的特征,并将提取的特征输入Transformer。设计一个类似VGG的网络来提取空间特征。
2.2. Spectral-Spatial T ransformer for HSI Classification
CNN使用局部连接来提取输入的邻近特征。HSI通常包含数百个波段;因此,CNN很难获得远距离的光谱关系。自注意机制可以得到每两个波段的关系。
对于HSI图像,包含224个波段,利用自注意机制,通过学习过程可以得到一个形状为224 × 224的矩阵。矩阵中的每个元素表示这两个波段之间的关系。
如图1所示,最后一部分CNN提取的特征被发送到Transformer中,主要包含三部分:
- 第一个部分称为位置嵌入,其目的是捕获不同波段的位置信息。这个元素修改最后一部分的输出特性,这取决于它的位置,而不改变这些完整的特性。本文采用一维位置嵌入的方法,将输入特征视为不同波段的序列。这些生成的位置嵌入被添加到特征中,然后一起发送到下一个元素。此外,还准备了一个可学习的位置嵌入(即数字零),其状态作为整个频带的表示。该可学习位置嵌入与第三部分结合完成分类任务。
- 第二个部分是Transformer编码器,它是我们模型的核心部分。Transformer编码器共包含d个编码器块,每个编码器块由一个多头注意层和一个MLP层组成,再加上层归一化和残差连接。在每个编码块中,在每个多头注意和MLP层之前添加一个归一化层,在每个多头注意和MLP层之后设计残差连接。
B ∈ R n × d m o d e l 表 示 H S I ( b 1 , b 2 , ? ? ? b n ) 的 n 个 波 段 , 其 中 d m o d e l B∈R^{n×d_{model}}表示HSI (b_1, b_2,・・・b_n)的n个波段,其中d_model B∈Rn×dmodel?表示HSI(b1?,b2?,???bn?)的n个波段,其中dm?odel表示CNN提取的特征的维。Transformer编码器的目标是根据全局上下文信息对每个波段进行编码,从而捕获HSI的所有n个波段之间的交互。具体定义了维度dk的查询(Q)、键(K)、维度dv的值(V)三个可学习的权重矩阵。使用点积计算具有所有键的查询,然后使用softmax函数计算值的权重。注意的输出定义如下:
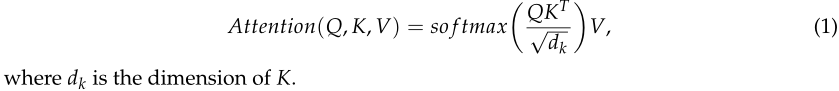

为了缓解消失梯度,加强特征传播,采用了快捷连接(可以理解成skip-connection),形成l
了DenseTransformer。特别地,DenseTransformer中的每一层都与DenseTransformer中的前一层有连接。

SST的第三部分是MLP。MLP的体系结构包括两个具有GELU操作的全连接层,其中最后一个全连接层(即softmax层)旨在为HSI分类生成最终结果。在softmax中,对于一个输入向量R,其输入属于第i类的概率可估计为:
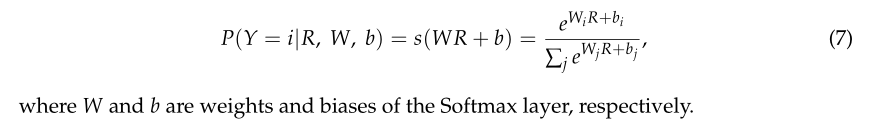
在MLP中,输入层的大小设置为与Transformer的输出层的大小相同,输出层的大小设置为与类的总数相同。Softmax保证每个输出单元的激活之和为1。因此,输出可以看作是一组条件概率。
2.3. Dynamic Feature Augmentation
因此,SST容易发生过拟合,需要适当的正则化才能很好地泛化。在本小节中,提出了一种简单的正则化技术,称为动态特征增强,该技术通过在训练过程中随机mask特征来实现。然后,将SST与特征增强相结合,形成一个新的HSI分类器(即SST- FA),提高了SST的鲁棒性和整体分类性能。
特别是VGG提取的空间特征维数较高(512维),容易对Transformer模型进行过拟合。在这里,首先在特征中随机选择一个坐标,然后,在坐标周围放置一个掩码,它决定有多少特征被设置为零。请注意,坐标在随着epoch训练期间动态地更改,这确保Transformer模型接收不同的特性。所提出的SST-FA不仅易于实现,而且能够进一步提高Transformer模型的性能。
训练样本的收集不仅昂贵而且耗时。因此,训练样本有限是HSI分类中常见的问题。为了解决这一问题,本研究将迁移学习与SST相结合。迁移学习是一种从源领域提取知识并将其转移到目标领域[44]的技术。例如,在基于cnn的迁移学习中,可以使用源域上学习到的权值来初始化目标域的网络。因此,在训练样本数量有限的情况下,迁移学习在适当的使用下可以提高目标任务的分类性能。
为了进一步提高所提出的SST的分类性能,本节提出转移SST (T-SST)。图3显示了提出的用于HSI分类的T-SST的框架。一般来说,分类方法分为三部分:基于转换cnn的空间特征提取、基于变压器的空间光谱特征提取和基于mlp的分类。

3.1. Heterogeneous Mapping of Two Datasets
由于大规模数据集(即源数据集)有三个通道,而HSI(即目标数据集)有数百个通道,因此单纯使用迁移学习进行HSI分类存在问题。为了解决异构迁移学习带来的问题,我们使用映射层来处理两个数据集的信道数(即频带数)不同的问题。
在大规模的ImageNet数据集上,预训练的模型有三个输入通道(R、G、B),但T-SST中的CNN接收到一个波段作为输入。
!!!!没太理解

3.2. The Proposed T-SST for HSI Classification
迁移学习是一种从源领域提取知识并应用于目标领域[44]的技术。从源任务中学习到的知识用于提高目标任务的性能。在基于深度学习的迁移学习中,深度模型可以从ImageNet等大数据集中学习大量知识,并将学习到的知识转移到HSI分类等新的任务中。因此,迁移学习的正确使用可以减少必要的训练样本的数量。
具体来说,ImageNet数据集上学习到的VGGNet权值可以用来初始化HSI分类的网络,然后再对HSI分类任务的权值进行微调。
本文提出了一种新的HSI分类框架T-SST,它是由转移的VGGNet、改进的Transformer(即DenseTransformer)和MLP组合而成的。在T-SST中,使用了在ImageNet数据集上训练的16层VGGNet,将源任务中训练好的所有卷积层的权值转移到我们的目标任务中。然后,在HSI数据集上对这些初始化的权重进行微调。
3.3. The Proposed T-SST-L for HSI Classification
为了解决T-SST中的过拟合问题,引入了标签平滑(label smoothing)。

标签平滑将原标签 y k 修 改 为 y k ′ y_k修改为y'_k yk?修改为yk′?,定义如下:
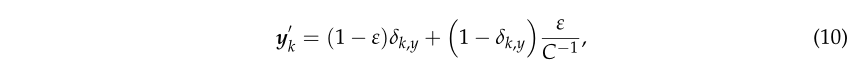
实验部分细节具体看论文。。。。。。