Overview of Fingerprinting Methods for Local Text Reuse Detection
ժҪ
�ڼ�Ҫ��������Ҫ���ı����ü�ⷽ��֮�����Ǵ���Ϣ�����ĽǶȽ�����ָ���㷨��һ��ԭ���� ����������ָ�Ʒ�����overlap, non-overlap, and randomized���� �������ض����㷨������k-gram, winnowing, hailstorm, DCT and hash-breaking�� ��Щ�㷨�����ܺ��ص�����������ݽ������ܽᡣ
�ؼ��֣���Ϣ�������ı����ã���Ϯ��⣬ָ��ʶ��
1 ����
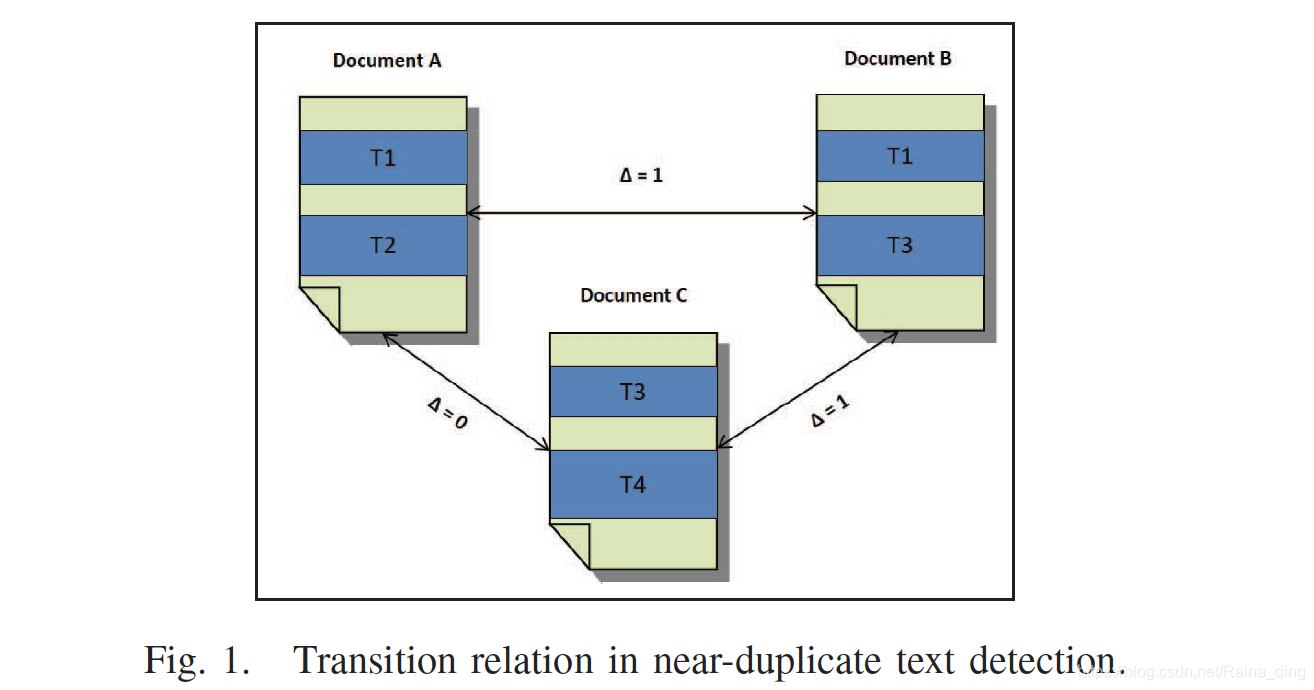
�����ظ����ĵ�����㷨�ٶ����ĵ�֮��Ĵ��ݹ�ϵ��Ҳ����˵�������ĵ�A���ĵ�B�Ľ����������ĵ�B���ĵ�C�Ľ����������ĵ�A���ĵ�C�Ľ�������ͼ1��ʾ����������������Υ���˼���,ͼ�еĦ���һ��ָʾ����������������ĵ������ı����ù�ϵ���������Ϊ1��
������˶��ּ����������ı����ü�⣬�ر��dz�Ϯ��⡣��Щ����������������������ַ���֮һ��
- ���ַ���ƥ�䣺�����ַ����У�����Greedy String Tiling(GST)[5]�;ֲ�����[6]֮��ļ�������ʶ��ɶԵ��ַ����е����ƥ�䣬Ȼ��������ָʾ���� ��Щ�ַ�����ʾΪ����������ͼ��ָ�����������ı����õ������� ���ǣ���Щ������ʱ��ʹ洢����ļ��㸴�ӶȺܸߡ� ���磬��̰���ַ���ƽ�̷������������Ӷ��� O �� n 3 �� O��n^3�� O��n3��[5]�� ��һ���棬���������ַ���A��B�ľֲ������㷨�ĸ��Ӷ�Ϊ O �� ( �O A �O + �O B �O ) 3 �� O��(| A | + | B |)^3�� O��(�OA�O+�OB�O)3��[6]��
Greedy String Tiling(GST)�㷨
GST��Greedy String Tiling���㷨��һ��̰����ƥ���㷨����һ�㷨�������ַ�������̰��ʽ�������ҳ�������Ӵ�������Ҫ��Ҫ����������ַ������ж��������ÿ���ҳ���ǰ�ַ�����δ����ע�����ֵ�������Ӵ��������ҳ���������Ӵ�����ע��Ϊ��ʹ�ã��������ƥ���ظ�ʹ�á���abcdefghijklmuvwxyz���롰ijkabclmdefghpq��Ϊ������GST���������̣���1��������������Сƥ�䳤��Ϊ2����һ����Ѱ���̣����ҵ�abc����ʱ���ƥ�䳤����3��֮���ҵ�defgh��������ij��ȴ���3�����Դ�ʱ���ƥ�䳤��5��֮���ҵ�ijk�������䳤��С��5�������������lm���䳤��ͬ��С�ڵ�ǰ���ƥ�䳤��5����������2������1�����ҵ������ƥ���Ӵ�����עΪ��ʹ�á����ظ���1���Ĺ��̣��������ٶԡ��ѱ�ע�Ӵ���������ֱ����1�����ҵ������ƥ���Ӵ��ij���Ϊ���õ���Сƥ�䳤�ȡ�
- �ؼ������ƶȣ�
�ռ���Ȩ���ĵ�����������صĵ��ʣ���ʹ�������������ĵ�֮��������ԡ�
- �ٶ��ĵ��Ǿֲ���صġ�������ƶȳ���ij����ֵ����ѡ�ĵ��ֳɽ�С�IJ��֣�Ȼ��ݹ�Ƚ����ǡ�
- ��һ�����Ƶķ�����ʹ�û����ĵ�֮�䵥�����Ƶ�ʵ������Զ���[1]�� ������ͬ�Ķ�������ڱ˴˾�����ͬ�Ĵ�Ƶ�� ���룬ɾ���ͱ༭�ή���������Ƶ�ʵ÷ֵ�ֵ��
�����ַ�����Ŀ���Ǽ���ĵ�֮��ĸ���[7]��
- ָ�Ʒ�����ָ�Ʒ����Ǿֲ��ı����ü���������еķ���[8]�����ĵ���Ϊk-gram��Ȼ����ת��Ϊ�����ĵ�ָ�Ƶ�������ʽ�������ĵ�����һ������ָ�Ʊ�ʾƥ�䣬����˱�����Щ�ĵ�֮�����ظ�ʹ�õ��ı�[1]���������ĵ������е������Ƶ�ʵ÷ַ�����бȽϣ����ǽ�ʹ�ô����ĵ���һ��ѡ����ָ������������ƥ��ָ�Ƶ��ĵ�֮��ı����ı�����ʵ����
2 ָ�Ʒ���������
��k-gram ���ĵ�����Ϊһ�鳤��Ϊk�������ַ�/�ַ�����Ȼ��ÿ��k-gram���й�ϣ������Ȼ��ѡ����Щ��ϣ���Ӽ���Ϊ�ĵ���ָ�ơ��ĵ��Ĵ���ָ�����ڱ����ı����ü�⣬���ұ����ṩ�����ܶ���ĵ�������Ϣ��
A ָ������
�ڴ���ȷ����Ч��ָ�Ƽ�����������Ҫ�����ĸ�����[9]��
��1���Ӵ�ѡ��ԭʼ�ĵ��У�����ijЩѡ�������ȡ���ַ������飩�������IJ��Կ��Կ���λ�ã�����Ƶ�ʻ�ṹ����Ϣ��
��2���Ӵ��š����ַ����ſ���ָ�ƽ��������ָ������������ɱ��Ϳռ�Ҫ��֮��������Ե�Ȩ�⣬�������Ȩ�⡣ָ���б�����ĵ���ϢԽ�࣬���Ը��ɿ��ؼ�����ָ�ƵĿ����ص���
��3���Ӵ���С������ָ�Ƶ����ȡ�ϸ���ȸ������ܵ�����ƥ���Ӱ�죬����������ָ�ƶԱ仯��÷dz����С�
��4���Ӵ����롣���ַ���ת��������һ����ϣ���㣬��Ψһ�Ժ;������⣬Ч����һ����Ҫ���⡣�ڴ����ָ�Ƽ����У�ͨ��ʹ�����е�MD5��Karp-Rabin��ϣ�㷨��
B ָ�Ʒ���
���ĵ�B�������ĵ�A�е��ı�����ʾΪ����ָ�������ĵ�Aָ����֮�ȡ�B�а�����A����ʾΪC��A��B����Ϊ ��������[8]��
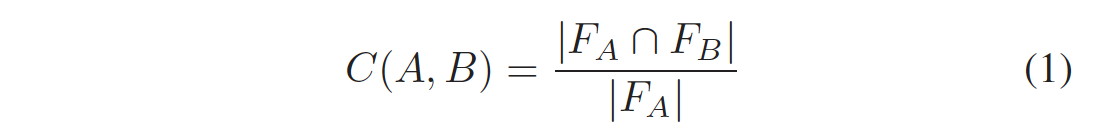
���� F A F_A FA?�� F B F_B FB?�ֱ����ĵ�A��B��ָ�Ƽ��� Ȼ����Ի����ı�����Ӧ�ó�������Ժ�Ŀ�꽫���Ƶİ���ֵ����Ϊ�����Χ�����磬��������൱���֣��� Ϊ�˹���һ���ĵ�֮��������ı�����ʹ����һ�ַǶԳƶ�����[4]�� ���� C ( A �� B ) �� C ( B �� A ) C(A��B) \neq C(B��A) C(A��B)??=C(B��A)����Ϊ�������ȷ�ӳ���ĵ������ϵIJ��졣 �����ı����ü���ָ�Ƽ������������֣��ص������ͷ��ص�������overlap techniques and non-overlap techniques.���� ����С�ڸ�������Щ�����Ŀ��÷�����
C �ص�ָ�Ʒ� Overlap Fingerprinting Methods
�ص�����ʹ��ÿ���ƶ�һ���ֵĻ������ڡ� �����еĵ������У���������ֵ������Ϊ chunk �� ����һ����СΪk�Ĵ��ڣ���i�����ڽ��ӵ�i������չ���ĵ��е� i + k ? 1 ���֡� ���ڻ������ڵķ�������Ϊ�ص���������Ϊ���ڵĴ��ڱ˴��ص���
�����������ɴ���chunks�������ص��������������õĽ�����������ǽ������ĸ�����������
K-gram
K-gram���ص���������ġ� k-gram�����Ը����ı���k��������Ԫ�ļ��ϡ� ����Ӧ��[10]����Щ��λ���������أ��ַ��ʡ� k�����ʹ���ĵ�������chunks��Ҳ��Ϊshingles)�������ɴ�СΪk�Ļ���������Ϊָ�ơ� ��ˣ�����n��token���ĵ���ָ����������Ϊ��
N k ? g r a m = n ? k + 1 N_{k?gram} = n ? k + 1 Nk?gram?=n?k+1
�ŵ㣺Ч������
ȱ�㣺chunks̫��
0 mod p
0 mod p������������k-gram����ѡ���ϣֵ�ɱ�p�����Ŀ�[11]�� ��ˣ���������ĵ���ͬ�����ĵ���ͨ��0 mod p����ѡ��Ŀ�����ͬ�ġ� ѡ���ָ�Ƶ�ƽ����������p����������ʾ��
N 0 m o d p = N k ? g r a m / p N_{0modp} = N_{k?gram}/p N0modp?=Nk?gram?/p
ȱ�㣺����ȷ��ʾ�����ĵ������磬�߶ȳ�����chunk�ɱ�p���������ܴ����ȷ�����ù�ϵ;�������ϣΪ0 mod pʱ���Ż���ĵ�֮�乲�е�k-gram, ���ܱ�֤���ĵ�֮���ƥ�䣬�����û�м���κ�ƥ���
Winnowing
��ʹ�ô�СΪw�ĵڶ������ڣ���k-gramΪ��λ��ԭʼ���ڵĿ��ϻ�������ÿ��Winnowing �����н�ѡ��һ��������С��ϣֵ��chunk ��Ϊָ��; �����ƽ�֣���ѡ�����ұߵ�ֵ��
�ŵ㣺����[12]������ʵ���У�Winnowing��0 mod p�����������õĽ���������ṩ����ѡָ�Ƶ����ޣ�������ʾ��
N w i n n o w i n g �� 2 w + 1 N k ? g r a m N_{winnowing} �� \frac{2}{w + 1}N_{k?gram} Nwinnowing?��w+12?Nk?gram?
ָ�Ƶķ�ѡ��ʽȡ����ͬһ Winnowing ��chunk �Ĺ�ϣֵ����ˣ���ʹ�����ĵ�����һ����ͬ��k-gram����ѡҲ��һ����ѡ��k-�����ĵ��еĿ�ָ�ơ����Ϊ�ֲ������ԣ��Ƿ�ѡ���˴�״�����ȡ����ͬһ�����еĴ�״�������ȡ����������״������ǣ���������ĵ�����һ���������У��õ��������������ѡ����wһ�������������ĵ��ж�ѡ��������е�����һ���������ʡ�
�����Ĺ��̽�����ѡ����ܶ��hashֵ�����ǿ���Ԥ�����ǣ�����Щhashֵ�У��϶�����ںܶ����ڵ�hashֵ����ͬ�ģ�������Ϊ���ڻ�����Ե�ʡ�Ȼ���ٽ���Щ��ͬ��hashֵ���д��������õ���ԭ�������ٺܶ��hashֵ���ϣ������ʹ��winnowing����ĵ�ָ�ơ�
��Ȼ�������㷨Ҳ��һЩ�ĵ��Ǹ��Dz����õģ�����˵�����ĵ��ж���ͬһ���ַ����ĵ�����Ϊ�����Ļ�������������hashֵֻ��һ�������⽫����ĵ�ָ�ƵĴ����ԡ�
����ο����ӣ�https://hcyue.me/2017/05/11/plagiarism-detection/
���ӣ����ı�����
�ҿ������²�������������
�� 3 Ԫ�������
�ҿ���
������
������
���²�
�²���
������
������
������
������
������
��Ȼ���ڳ���Ϊ N �������� K Ԫ����г�Ϊ N - K + 1��
K Ԫ���Ԫ���Է�ӳ���壬���Զ������ Hash ������洢�ͱȽϡ�
[����ͼƬת��ʧ��,Դվ�����з���������,���齫ͼƬ��������ֱ���ϴ�(img-evd1A2nw-1590548027844)(./pic/Winnow.png)]
��������� 3 Ԫ����У�ȡ b=3b=3��������ȡ unicode ���룬��
�ҿ��� = 310603
������ = 275508
������ = 266354
���²� = 283370
�²��� = 298519
������ = 388904
������ = 386764
������ = 375223
������ = 277132
������ = 312216
�õ� Hash ֵ����
[310603, 275508, 266354, 283370, 298519, 388904, 386764, 375223, 277132, 312216]
ȡ���ڳ� 4 ���õ����µĻ������ڡ����е� 0��2��3��4 ����������Сֵ�����仯��ȡ��Щ�����е���Сֵ��Ϊ����ֵ
([275508, 266354, 283370, 298519]) => 266354
([266354, 283370, 298519, 388904])
([283370, 298519, 388904, 386764]) => 283370
([298519, 388904, 386764, 375223]) => 298519
([388904, 386764, 375223, 277132]) => 277132
([386764, 375223, 277132, 312216])
�õ���������ֵ������Ϊ����ı���ָ��
266354, 283370, 298519, 277132
Hailstorm
Hailstorm ������winnowing �Ľ�����ĵ��ĸ�ȫ�渲�����ϡ��ڽ�hailstorm ָ��Ӧ�����ĵ�֮ǰ���ȶ��ĵ��еĵ��ʽ��й�ϣ������Ȼ�������ϣֵ�����������ࣨ�����Ҳࣩ��token ʱ���Ų��Ժ�ѡ���ĵ��е�k����������/token �����е�ÿ����������[13]������hailstorm ָ�Ʊ�֤�˾ֲ��ԣ�Ҳ����˵��������ͬһ�����ڵĹ�ϣ���ж����������κδ��ڵĹ�ϣ������ѡ��ָ�ƣ���hailstorm ָ�Ʊ�֤�˳�Ϊ���������Եĸ�ǿ���ԡ�Ҳ����˵��ѡ��shingles ��Ϊָ�ƽ�ȡ����shingles ����������ȡ�����ĵ��е��κ�����shingles ��Hailstorm ָ�ƻ��ṩ��һ���ܸ��Ƿ�Χ������ζ���ĵ��е�ÿ��token ������������һ��ѡ����ָ����[13]��
��û���� = =��
D.���ص�ָ�Ʒ��� Non-Overlap Fingerprinting Methods
�ڷ��ص������У��ĵ���Ϊ���ص��ı��Σ������ı��εĹ��̳�Ϊ�жϣ��������жϵĵ���λ�ó�Ϊ�ϵ㡣
Hash-breaking
Hash-breaking ������ 0 mod p��������û���ص������ĵ��еĵ��ʽ��й�ϣ���������ڸ�������p�ɽ����ʵĹ�ϣֵ������λ�ô����ϵ㡣Ȼ�����õ��ı�����й�ϣ�������������ĵ���ָ��[1]��
ʹ��Hash-breaking �������ĵ�D��Ԥ��ָ����ΪL��D��/ p������ı��ε�ƽ������Ϊp��
ȱ�㣺
- �ڶ�������£��ı��εij��ȿ��ܱ�Ԥ�ڵĶ̺ܶ�ö࣬��ȡ������ϣֵ�ķֲ������������£��ÿ���ܻ�̣ܶ����ҽ��������ٵij��ôʡ�����������£����ü����ܵ�����Ӱ�졣Ϊ�˼������ӵ�ָ�ƣ���[4]�������һ�ָĽ���Hash-breaking �����������Hash-breaking �����Գ���С��p���ı��Ρ�
- Hash-breaking ��������һ������������С���ķdz����С�chunk ��һ���ַ��ĸ��Ľ����¸ÿ�Ĺ�ϣֵ��ͬ������ĵ�������ָ��Ҳ����ͬ����ɢ���ұ任��DCT����ʹ������hash-breaking ���˷��������⣬���Ҷ��ڽ�С�ı仯����׳[4]��
��ɢ���ұ任��DCT��
DCTָ��ʶ������hash-breaking ���������������⡣ DCT���ڲ�ͬƵ���������Һ���֮�ͱ�ʾһ���������ݵ�����[14]�� ������Ҫ����ʹ��㷺���ڿ�ѧ�����е�����Ӧ���У�������Ƶ��ͼ�������ѹ������Ϊ��С�ĸ�Ƶ�����ȵ�Ƶ��������Ҫ����˿��Խ��䶪���� DCT���ڿ��ٸ���Ҷ�任��FFT���������÷�����ʱ���ź�ת��ΪƵ�ʷ�����ϵ����
DCTָ��ʶ�����ĵ��е��ʵĹ�ϣֵ��Ϊ��ɢ��ʱ���ź����С� ����������ϣֵ����ת��ΪƵ�ʷ�����ϵ����
DCTָ��ʶ���Ĺ�����ʽ���£��ĺ�� ����p ��ϣɢ�����������ĵ�x0��x1����xN-1��ע��N���ı��εij��ȣ����ı��Ρ� Ȼ��ͨ��words ������ϣֵ���ı����е�words ���й�ϣ������normalized�� ִ��DCT���ܣ���������ϵ��������������Ӧ������bits�� ��Щ����ϵ���γ��ı��ε�ָ�ơ� ����DCT�ڽ�С�ĸ��ķ����Hash-breaking ��ǿ�� ���ǣ������ֻ�����̵������ʵ��滻[4]��
E. Other Approaches
�����˾������涼�ǽ�ά������
���ָ�ƣ�LSH��
�ֲ����й�ϣ��LSH��ʹ��ɢ�к����ϵ�����ֲ���ʾ�ĵ�֮��������ԡ�
���https://statusrank.xyz/articles/84288273.html
min-hash:
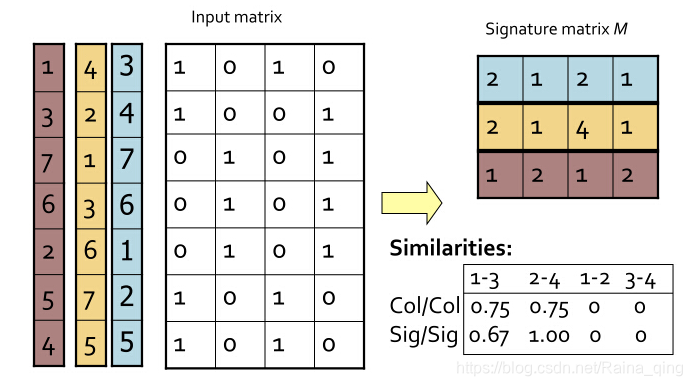 LSH:
LSH:
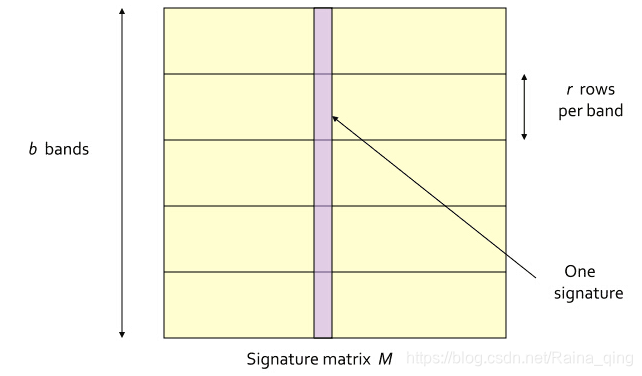
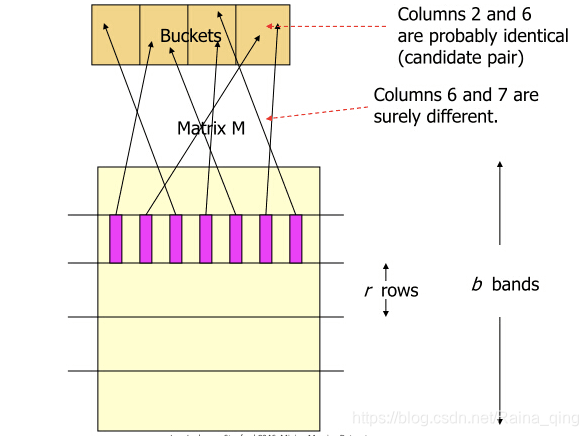
�����ĵ���ӳ�䵽ͬһ��hash bucket�еĸ��ʣ�
b��band������һ����ͬ�ĸ����� 1 ? ( 1 ? s r ) b 1?(1?s^r)^b 1?(1?sr)b
�������ķ�����ΪAND then OR��������Ҫ��ÿ��band�����ж�ӦԪ�ر��붼��ͬ����Ҫ����band��������һ����ͬ�����������������ܷ���hash��ײ��
ģ��ָ��
�����˾��þ����������ĵ��ij���������ʾ��������tfidf��ʾ������ȡ������Ϊ����������
��ģ��ָ�Ʒ���������£�Ϊ�����ĵ�d�������������ռ��Ľ����ĵ�ģ��d����ִ��d�뼯�������������ĵ���ָ��֮����������͵����ƶȱȽ�[9]������[17]������ģ��ָ�Ƶ��㷨�������²��裺
1��ͨ�������ĵ������ռ�ģ��d����ȡ�ĵ�d��һ�����飩��
2�������ĵ������ʵ�ǰ������Ƶ��pf��������
3����һ������pf�����������������ǰ���ֲ������ƫ�pf�������� 4��ͨ������ȷƫ�����Ϊһ��ģ��ƫ�����Ȼ�����ÿ�����ʵ�ģ����ϣֵ�����Ԧ�pf����ģ������ʹ��ģ��ָ��ʶ���������������ٶȣ��������IJ�ȫ��ȴ���١�
����SVD�ļ��
����ֵ�ֽ⣨SVD�������Դ����о��ξ����������֪�ķֽ⡣����DZ�����������LSA���ƶ�������ͬʵ��֮���DZ����������Ĺ��ߡ�Ҳ����˵��LSA�����SVD������һ���ĵ���������֮��Ĺ�ϵ��
SVD��������M���ɼ�������[M1��M2���� �� �� ��Mn]����������Mi�������ĵ�i�г��ֵ����Ƶ�ʡ���Щ������Ҫ��k-gram�Ķ����k�����ʵ����У����������ʶ���ĵ�֮����ص������ǣ�����ÿ���ĵ����������ж����һС���֣������ʹ�þ���M�dz�ϡ�衣��ˣ��������ռ�̫����SVD�зֽ�ļ���ɱ����dz��ߡ�
3 �ı����ü���ļ�
����ָ�Ƽ������ѹ������������Ͽ⣬������������ͬ��ָ�Ʒ��������磺
- METER corpus [19]
- TREC newswire collection or Reuters Corpus Volume 1[20]
- Co-derivatives corpus [21]
- PAN-PC [22]
4 ָ�Ƽ�������������
ָ�꣺precision, recall, and F-measure��
���ݼ���Wikipedia 600��ƪ���¼������档
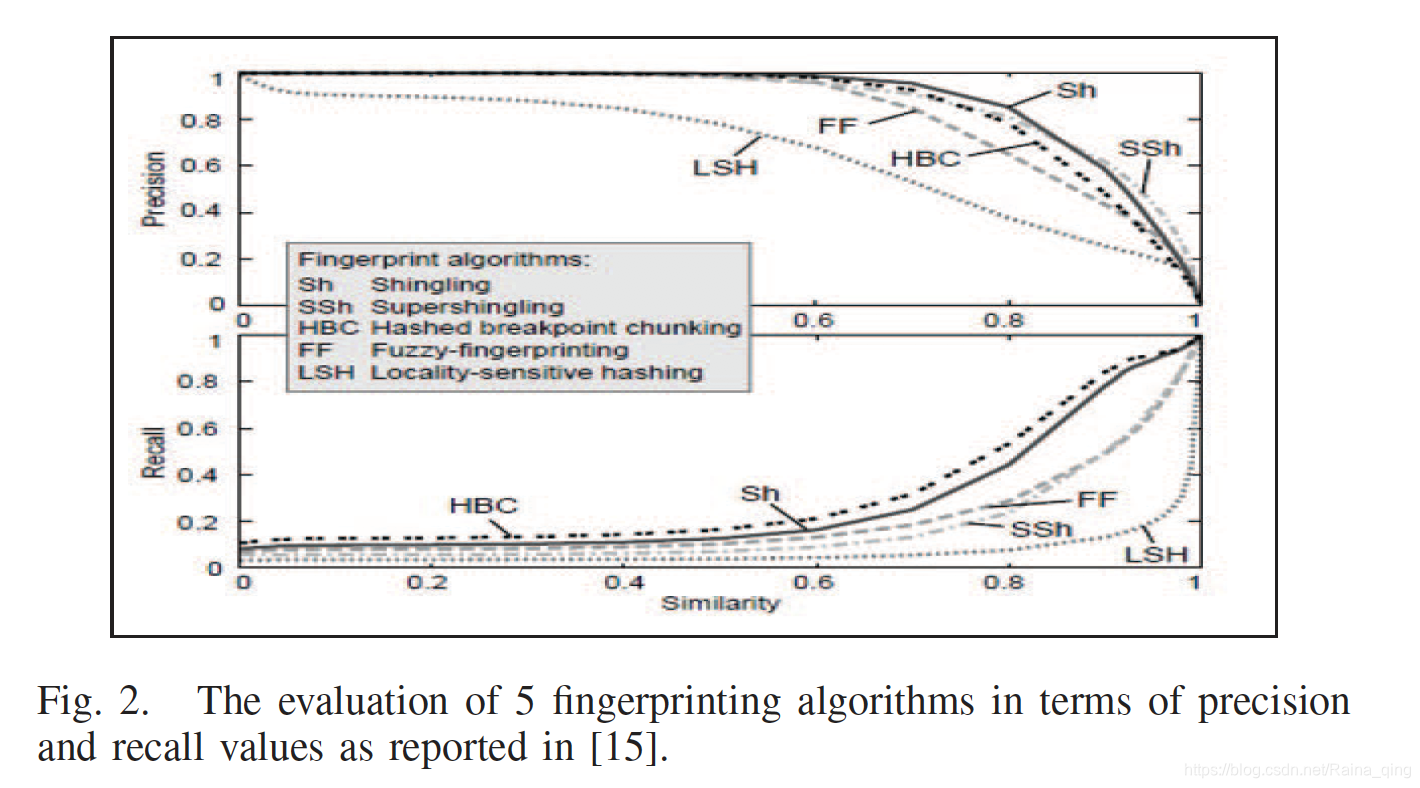
ͼ2��ʾ��ȷ�ԺͲ�ȫ�ʷ���������Խ��[15]��
�о�����������k-gram��ָ�Ƽ���������������ָ��ã�����Hash-breaking ����������á�Ȼ������ģ�������ָ�Ƽ�����ȣ�k-gram��ɢ�����뷽��������ָ��Ҫ��ö࣬���Դ���һ���ĵ�[15]����������һ�������Զ����ʵ�飬���������ڱ����ı����ü��Ķ���ָ�Ƽ�������TREC����ר���ϲ�����ָ��ʶ����k-gram��0 mod p��Winnowing��Hailstorm �� DCTָ��ʶ�𣬲��Ƚ���ÿ�ַ����м����ĵ��ԡ�ʹ������������F-measure��������������еľ�ȷ��ֵ�Ͳ�ȫ�ʣ�������������Ч��[4]����ѡָ��ʶ��������������ͼ3��ʾ��
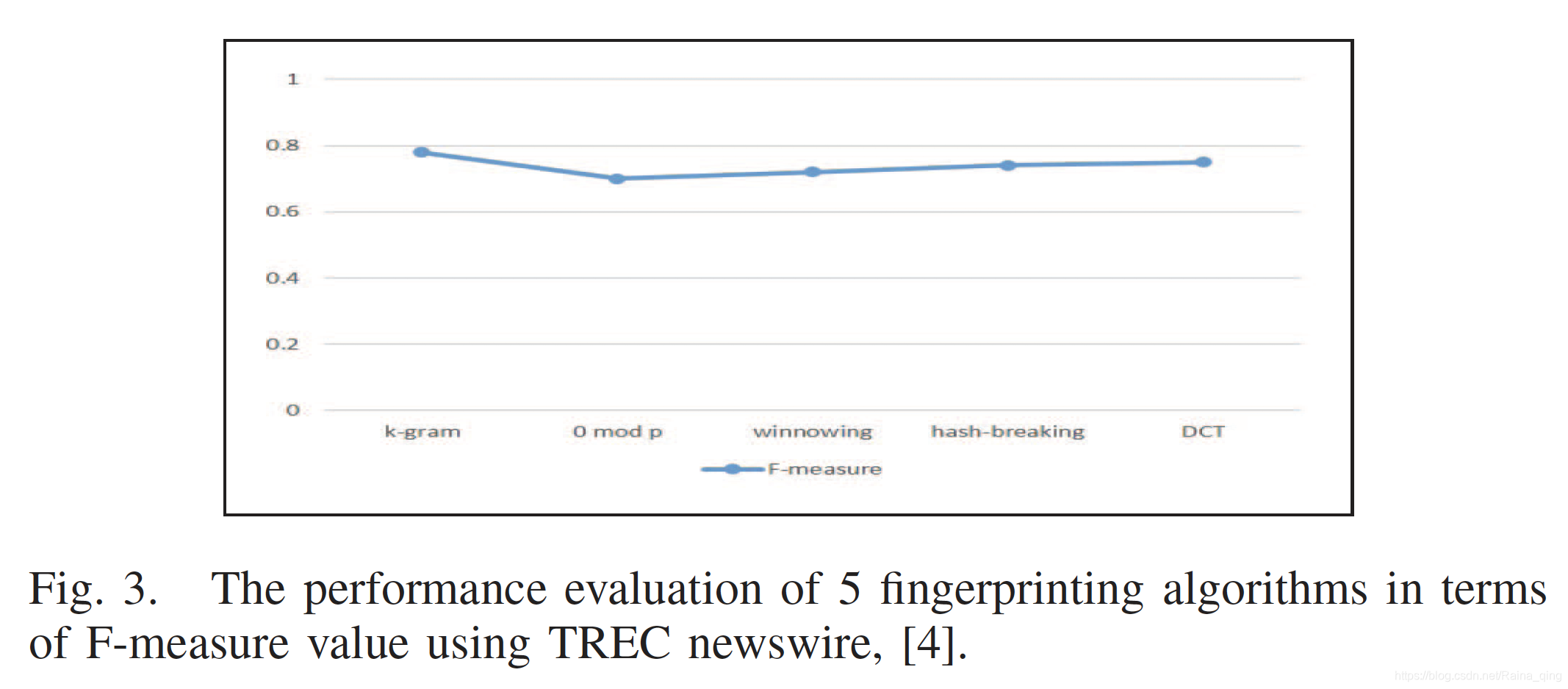
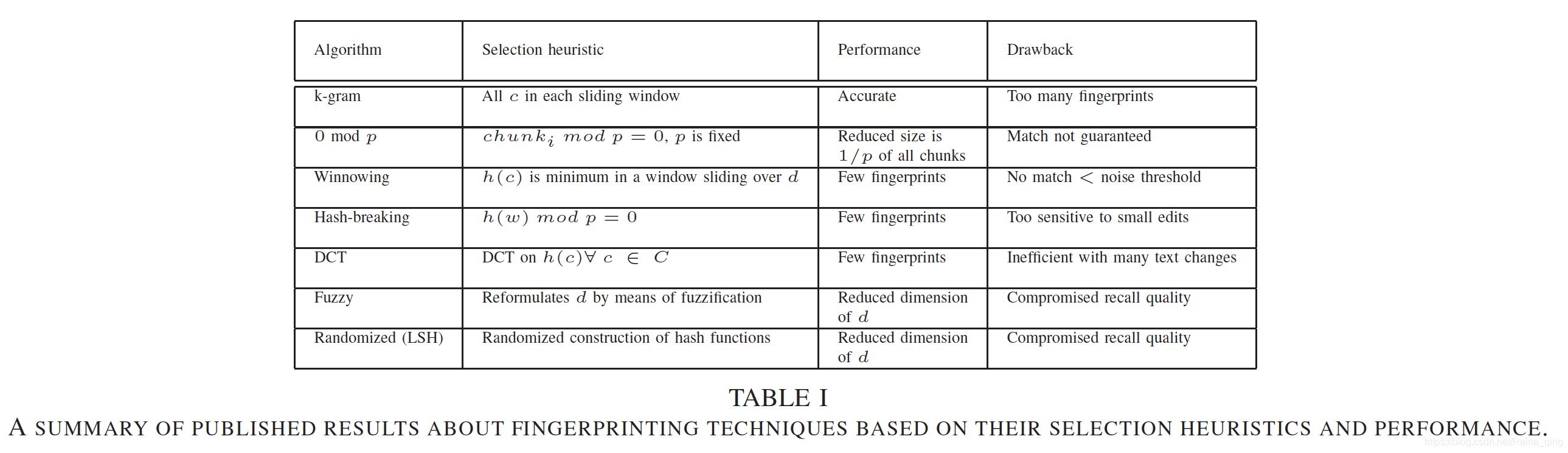
��ֱ���Ͻ���k-gram������ȷ�Է���ʤ���������������ǣ������ɵ�ָ������������ DCTָ��ʶ����ȷ�Է��������ڶ���ָ���������١�������Խ�С�Ĵ��ڴ�С��Winnowing �㷨��ʾ���dz��õ�����[4]����I�ܽ����йر�����������ָ�Ƽ�������Ҫ���������ܣ�������ָ����������ȱ����ѷ��������ע�⣬�ڱ��У�d��ʾ�ĵ���c��C�ֱ��ǵ�����Ϳ鼯��
5 ����
�ֲ��ı����ü���������ھ����Ϣ��������Ҫ���� ָ�Ƽ�����������ɴ�����ĸ��ַ���֮һ��
���ĵ�����������Ҫ��ָ�Ʒ��࣬���ص������ص�������������� ����Щ�����е�ÿһ������������㷨������k-gram��0 mod p��Winnowing ��Hailstorm ѡ���㷨�� ������������Щ�㷨���ܽ������ǵ����ܡ� �����ǵ�ȱ����ܽ�������ź�������Ȼ��һ�����⣬������Զ��ֲ��ı����ü����Ҫ����Ч���ӵ��㷨��