YOLO-V3-SPP
��ǰ��ƪ��YOLO����
- YOLO-V1 �������⡶You Only Look Once: Unified, Real-Time Object Detection��
- YOLO-V2�������⡶YOLO9000: Better, Faster, Stronger��
������ƪ������Ҫ�������ϼ�¼��YOLO�汾����������𣬲�û��ȥʵ��Դ������YOLO-V3-SPP��Ҫ��YOLO-V2�Ļ����ϼ��˺ܶ�tricktricktrick�������漰�˺ܶ����ģ���Щtricktricktrick�dz���Ҫ��ͼ��������絽Ŀ����������о��У�����tricktricktrickһֱ�ڸ��µ����������Ż�ʹģ���ܹ�����ѵ������ø��õĽ����
�����Ҫ�����¼������������YOLO-V3-SPP
- ����tricktricktrick���������YOLO-V2������YOLO-V3-SPP����ṹ����
- YOLO-V3-SPP����ṹ����
- YOLO-V3-SPP��Դ�����
���Ķ�ǰ����YOLO�и����ӡ��,���Ķ����½���
ͼ��YOLO
trick
trick �漰������
- Lin_Feature_Pyramid_Networks_CVPR_2017_paper-����������FPN����
- Lin_Focal_Loss_for_ICCV_2017_paper-Focal-Loss��ʧ����
- Bodla_Soft-NMS_�C_Improving_ICCV_2017_paper-�Ǽ���ֵ����NMS
- Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition-�ռ�������ػ�SPP����
������������������ģ����Խ������������Ӹ��Ƶ�Ѹ�����أ�
FPN����

FPN��ʷ

ͼ��a��ʹ��ͼ�������������������������������ÿ��ͼ���м���������������Ԥ��Ч���Ƿdz����ġ�
ͼ��b������ļ��ϵͳѡ���ʹ�õ��߶��������Ա����ؼ�⡣
ͼ��c�������ɾ������������Ľ�����������νṹ���������Ǿ��й��ܻ�ͼ�������һ��
ͼ��d�����������������FPN����ṹ,Ԥ��Ч����ͼ��b����ͼ��c��һ�����٣�����ȷ�������ͼ�У�feature maps����ɫ����ָ�������Ҹ�����������ʾ�������ϸ�ǿ�������
���߶�RPN��Fast R-CNN��Faster R-CNN���������FPN�ṹ�ͼ��������ṹ�����˶Ա�ʵ��



�����ϱ�����Կ���FPN�ṹ��������ȡ�����dz�ǿ��
����������Ҫ��עFPN�ṹ������ָ�����棬�����ṹ����Ȥ����ԭ�ġ�
YOLO-V3-SPP�Ὣ�ýṹӦ�����������忴��ͼ����ͼ���������ϸ���ͣ���ͼ������BվUP����ž��Wz��

��ͼ��ɫ��Ӧ�õ���FPN����ṹ,����������backbone�ĺ������в�����Concatenate������Ԥ�����С�������Ԥ���������ú���������ͣ�
Forcal Loss

IoU��GIoU��DIoU��CIoU
IoU��GIoU��DIoU��CIoU��ʧ�������ǵ��¶�
������
һ�ĸ㶮������Ȼ����
��������ʧ����������
Focus Loss���one-stageĿ�������������������������
NMS

�����ķǼ���ֵ���Ʒ�����(Hard) NMS��Soft NMS��DIoU NMS
SPP-Net

SPP����ṹ

��ͼ���ͣ�
����������feature maps����SPP����ʱ��������������size��ÿ��feature map���л��֡�
��width,highΪfeature map�Ĵ�С��
��һ��sizeΪ4X4�Ļ��֣���feature map�ֳ�16���飬ÿ���СΪ(width/4, high/4)
�ڶ���sizeΪ2X2�Ļ��֣���feature map�ֳ�4���飬ÿ���СΪ(width/2, high/2)
������sizeΪ1X1�Ļ��֣�������feature map��Ϊһ�飬���СΪ(width, high)
����size������feature mapΪ21�飬����21�����max pooling�����Ļ��õ�21ά��������ͼ�������ұ�ʾ�������ײ�ѵ�������Ĺ��̡������IJ�������������������κδ�С��feature maps���ܵõ��̶���С��������
��ʵ��Ӧ��ʱ��ԭ���IJ���sliding window pooling�ķ�ʽȥʵ�֣���ͼչʾ��3��SPP�ṹ�����Ҹ�����ÿ��pooling��һ������

����Ŀ�Ĵ�С����ɲ�����֮ǰд�ľ�������������ļ��㹫ʽ�Ƶ�֤��
����ע�����һ��͵ڶ���Ļ������������ص��ģ��ص�����Ϊ�������ڵ�һ�У����������ϸ�ͼ�Ľ�����û��������㣬��Ҫ����Ϊ���Ƕ�feature maps���л��ֿ�IJ�����ʵ��Ӧ���Dz���sliding window pooling�������֮���Ƿ��ص�Ҫ��ʵ����Ƶ�poolingΪ��
���߽�SPPӦ����4������ṹ�н��жԱ�ʵ�飬���н������ṹͳһΪ{6x6,3x3,2x2,1x1}�ܹ�50���顣


���п���֪�������ǵ��߶Ȼ��Ƕ�߶ȵ�SPP�ṹ�������no-SPP�ṹ�õ��˷dz����������
�����ʵ�鲿���뿴����ԭ���ġ�
��YOLO-V3-SPP�У�����ṹ��Ӧ���˸�SPP�ṹ��


����SPP�ṹ��û����SPP�����õIJ���stride������strideΪ1��paddingΪfiltersize?12\frac{filtersize-1}{2}2filtersize?1?,��ζ�Ž�����ÿ��Ŀ鶼����ͬ�����ģ���������SPP�����IJ��Ǿ����㣬������ʽ��SPP���IJ�̫��ͬ��SPP�����У�SPP�ṹ�������ŵIJ���ȫ���Ӳ�),���ܺ�SPP�е�ṹ�ϵIJ�𣬵���Ҫ�����˶�߶ȵ������ںϣ����Եó��������ṹΪ{16X16,16X16,16X16,16X16}������Ϊ������16X16X512��Concatenate֮��õ�16X16X2048.
mosaic������ǿ
mosaic������ǿ
YOLO-V3-SPP����ṹ

Դ����
Դ�����IJ��ִֶ����Ҷ�ÿһ���������ļ�������⣬��Щ�Ƚ��ѵIJ��ֻ����൱���ʱ��ȥdebug������������Щ��������������Χ֮�⣬������Ȧ�ӱȽ�С��û���ر�ȫ��ϵͳ��ֻ��һ�����µĽ����
����2021-8-5�����ϣ����ҵ���һ������yolov3��Դ����͵�pdf�ļ�������Դ��Դ��GiantPandaCV���ںţ�����GiantPandaCV��ֹ�κ���ʽ��ת�أ����������ã�����������ǵĹ��ںţ�
������ظ�yolov3���ɻ��Դ����⣬�Ҵ�ſ�����������ļ����ݣ���һ���㽲�ñȽϺã��ǹ���yolov3��forcalloss�������������Ȳ���ƫ�õĴ����������forcalloss��3.3�ڣ�������һֱ�㲻����һ���㣬��������ļ��������ף����������ô���ٵ����

- YOLO-V3-SPP models.py��ϸ�����ultralytic�汾��
- YOLO-V3-SPP ѵ��ʱ������ɸѡԴ�����֮build_targets
- YOLO-V3-SPP ѵ��loss����Դ�����֮compute_loss
- YOLO-V3-SPP �ݶ��ۻ���ʵ�ַ�ʽaccumulate
- Yolo-V3-SPP Ԥ��ģ��
����ģ��Ľ��������
ʵ��
���ݼ�
WiderPerson���ݼ�

���ݼ���ǩ��ʽ��
��һ���Ƕ������
�ӵڶ��п�ʼ����һ�����������ţ������ΪGroundTruth�����꣬xmin,ymin,xmax,ymax

��һ�����ݼ���ǩ��
����YOLOV3-SPP��Ҫ�ı�ǩ����Ϊ���������ţ���xcenter,ycenter,w,h(�����ԭͼ���һ�����ֵ)
�������Լ���д�Ľű�WiderPerson_dataset.py������¼�����ɣ�

ѵ��������7999��ͼƬ����֤������1000��ͼƬ��
����Ԥѵ��Ȩ��yolov3-spp-ultralytics-508
������: https://pan.baidu.com/s/1k5yeTZZNv8Xqf0uBXnUK-g ����: e3k1��
ѵ����ʽ��
- backbone��Darknet53��������ѵ��,����������ѵ��
- ѧϰ�ʲ��������˻��㷨����,��һ��ѵ������warmup����ѵ������
- ����mosaic������ǿ


���
MAP��������

�ɼ�mapһֱ������һ���㣬�ϲ�ȥ��
һ��ʼ�һ�����anchorboxԭ���ǻ���coco64���ɵģ������ҽ�coco64��anchorbox����ΪWiderPerson��anchorbox��ͨ�����༰�Ŵ��㷨���ɣ������ָ�����Ч��һ������������������⡣
���������ݼ����з������������ص����⣬�������£�
�Ҷ�ԭ���ݼ��ı�ǩ��ԭͼ�ϻ����������������⣺
ԭ���ݼ�������5�����
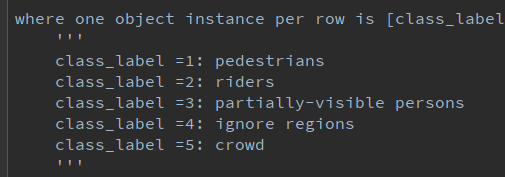
��3��5���������Ŀ���1��2��3���Ŀ������ص�������ģ�͵�map�������롣



�´θ��»�������ݼ�����ѵ��������WiderPerson�������ݼ�yoloȷʵ��̫���ʡ�
�����ݼ�
��������������Ҷ�WiderPerson���ݼ�������������ϴ��ֻ������ǰ�������
- pedestrians
- riders
��ԭ���ݼ��ĵ�partially-visible persons��ignore regions��crowd���ǩ���������
��ϴ��ı�ǩ�ļ���

�½��

�����δ����������ϴ��WiderPerson���ݼ�Ч�����˷dz��࣬map@0.5-0.95�ڵ�133��epoch�ﵽ��ֵ34.23,�����15.93����Լ87%�����棬�ɼ����ݼ���ѡ��dz���Ҫ����������epoch�����������ӣ�map��������������̫����ߣ����ܸ����ݼ��Ĺ�ϵ�кܴ��ϵ��WiderPerson�����ݼ��е������ܼ��ɶ����ߣ�Yolov3-SPP�����ó������ܼ�Ŀ��ļ�⡣
���������
- ��Ŀ���⡿һ��Ŀ�����г���������ָ��
- ����YOLO-V3-SPPͼƬ������ YOLOv3SPPԴ�����(Pytorch��)
- yolo���ۿɲο�yoloϵ�����ۺϼ�
- PASCAL
VOC2012���ݼ������������Լ������ݼ�
��л
��������Wz UP�Ĺ��ף��ò����漰ͼ����ൽĿ����������������о�����˽�ط���ѧϰ���飬�ְ��ֽ������磬��Դ�롣��л���еķ��ף�
