ǰ��
������������YOLO-V3-SPP��ϸ����
������Ҫ������������YoloV3-SPP�Ĵ����������¼��㣺
- Ԥ��������
- ������NMS����
����map�ļ��㣬ultralytic�汾��Դ�������pycoco�⺯��������map��������ﲻ��map�ļ��㣬����Ȥ����ȥ���������ѹ��ڶ�YOLOV5֮MAP����IJ��ͣ���YOLOV5-5.x Դ������val.py
Դ��
Yolo-V3-SPP�汾��ultralytics�汾,��Ҫ����ϸ����ȥgithub����
NMSԴ��
validation.py����
pred = model(imgs)[0] # only get inference resultpred = non_max_suppression(pred, conf_thres=0.01, iou_thres=0.6, multi_label=False)
predict_test.py����
# �������������tΪʱ��predΪ���ؽ��t1 = torch_utils.time_synchronized()pred = model(img)[0] # only get inference resultt2 = torch_utils.time_synchronized()print(t2 - t1)# �Ǽ���ֵ���ƴ���pred = utils.non_max_suppression(pred, conf_thres=0.1, iou_thres=0.6, multi_label=True)[0]
����predΪmodel�ķ���ֵ������ֵ�Ĵ�������model.py�Ĵ�������������ؼ����ֵĴ��룺
else: # inference �������֤����������# io��shpae(batch_size,anchor_num,grid_cell,grid_cell,xywh+obj_confidence+classes_num)io = p.clone() # inference output# clone����һ�������ĸ���������ԭ�����ijߴ������������ͬ��# ��copy_()��ͬ�����������¼�ڼ���ͼ�С����ݵ���¡�������ݶȽ�������ԭʼ����# grid��shape=[batch_size, na, grid_h, grid_w, wh],��io���һάȡǰ����xy���shapeһ�£����мӷ�io[..., :2] = torch.sigmoid(io[..., :2]) + self.grid# xy ������feature map�ϵ�xy���꣬��Ӧ���ĵ�sigmoid(tx)+cx# anchor_wh��shape��[batch_size, na, grid_h, grid_w, wh]��io���һάȡ��3��4������wh���shapeһ�£����г˷�io[..., 2:4] = torch.exp(io[..., 2:4]) * self.anchor_wh # wh yolo method ������feature map�ϵ�whio[..., :4] *= self.stride # xywh����ӳ���ԭͼ�߶�# obj�����Ԥ�⾭��sigmoidtorch.sigmoid_(io[..., 4:])return io.view(bs, -1, self.no), p # view [1, 3, 13, 13, 85] as [1, 507, 85],3X13X13=507# io��shape(batch_size,...,xywh+obj_confidence+classes_num)# p��shape��(batch_size,anchor_num,grid_cell,grid_cell,xywh+obj_confidence+classes_num)
NMSԴ��
def non_max_suppression(prediction, conf_thres=0.1, iou_thres=0.6,multi_label=True, classes=None, agnostic=False, max_num=100):"""Performs Non-Maximum Suppression on inference resultsparam: prediction[batch, num_anchors X (gird_x X gird_y), (xywh+obj_conf+cls_num)]Returns detections with shape:nx6 (x1, y1, x2, y2, conf, cls)"""# Settingsmerge = False # merge for best mAPmin_wh, max_wh = 2, 4096 # (pixels) minimum and maximum box width and heighttime_limit = 10.0 # seconds to quit aftert = time.time()nc = prediction[0].shape[1] - 5 # number of classesmulti_label &= nc > 1 # multiple labels per boxoutput = [None] * prediction.shape[0]for xi, x in enumerate(prediction): # image index, image inference ����ÿ��ͼƬ# Apply constraintsx = x[x[:, 4] > conf_thres] # confidence ����obj confidence�dz�����Ŀ��x = x[((x[:, 2:4] > min_wh) & (x[:, 2:4] < max_wh)).all(1)] # width-height �dz�СĿ��# If none remain process next imageif not x.shape[0]:continue# Compute confx[..., 5:] *= x[..., 4:5] # conf = obj_conf * cls_conf# Box (center x, center y, width, height) to (x1, y1, x2, y2)box = xywh2xyxy(x[:, :4])# Detections matrix nx6 (xyxy, conf, cls)if multi_label: # ���ÿ�����ִ�зǼ���ֵ����i, j = (x[:, 5:] > conf_thres).nonzero(as_tuple=False).t()x = torch.cat((box[i], x[i, j + 5].unsqueeze(1), j.float().unsqueeze(1)), 1)else: # best class only ֱ�����ÿ������и������������зǼ���ֵ���ƴ���conf, j = x[:, 5:].max(1)x = torch.cat((box, conf.unsqueeze(1), j.float().unsqueeze(1)), 1)[conf > conf_thres]# Filter by classif classes:x = x[(j.view(-1, 1) == torch.tensor(classes, device=j.device)).any(1)]# Apply finite constraint# if not torch.isfinite(x).all():# x = x[torch.isfinite(x).all(1)]# If none remain process next imagen = x.shape[0] # number of boxesif not n:continue# Sort by confidence# x = x[x[:, 4].argsort(descending=True)]# Batched NMSc = x[:, 5] * 0 if agnostic else x[:, 5] # classesboxes, scores = x[:, :4].clone() + c.view(-1, 1) * max_wh, x[:, 4] # boxes (offset by class), scoresi = torchvision.ops.nms(boxes, scores, iou_thres)i = i[:max_num] # ���ֻ����ǰmax_num��Ŀ����Ϣif merge and (1 < n < 3E3): # Merge NMS (boxes merged using weighted mean)try: # update boxes as boxes(i,4) = weights(i,n) * boxes(n,4)iou = box_iou(boxes[i], boxes) > iou_thres # iou matrixweights = iou * scores[None] # box weightsx[i, :4] = torch.mm(weights, x[:, :4]).float() / weights.sum(1, keepdim=True) # merged boxes# i = i[iou.sum(1) > 1] # require redundancyexcept: # possible CUDA error https://github.com/ultralytics/yolov3/issues/1139print(x, i, x.shape, i.shape)passoutput[xi] = x[i]if (time.time() - t) > time_limit:break # time limit exceededreturn output
NMSԴ�����
�ع�NMS
Soft-NMS�㷨

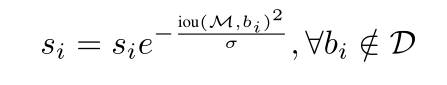
�����iou(M,bi)iou(M,b_i)iou(M,bi?)���õ���GiouGiouGiou
����
def non_max_suppression(prediction, conf_thres=0.1, iou_thres=0.6,multi_label=True, classes=None, agnostic=False, max_num=100):
����
- prediciton:shapeΪ(batch_size,anchor��grid_x��grid_y,xywh+obj_conf+cls_num)(batch\_size,anchor\times grid\_x\times grid\_y,xywh+obj\_conf+cls\_num)(batch_size,anchor��grid_x��grid_y,xywh+obj_conf+cls_num)
- conf_thres:���ŶȺ������ֵ
- Iou_thres:iou��ֵ
- multi_label:����ִ��NMS��־λ,True��ʾ��ÿ�����ִ��NMS,False��ʾֻ���������ִ��NMS��ע�����ﲻ��ָ�����͵����࣬��������NMS�Ĵ�����ʽ��
- classes:Ĭ��ΪNone�������ǿ���ɸѡ��������Ϊָ����classes,��Ϊһ������Ĺ�����չ,��Ԥ�����ʱ��ָ�����ָ������,Ĭ�ϲ�ʹ��
- agnostic:
- max_num:NMS�����ֻ����ǰmax_num��Ŀ����Ϣ
# Settingsmerge = False # merge for best mAPmin_wh, max_wh = 2, 4096 # (pixels) minimum and maximum box width and heighttime_limit = 10.0 # seconds to quit after
Merge�����������Ծ���NMS֮���Ԥ������һ��Ȩ��ƽ��,�������һ��,����ὲ��.
min_wh��max_wh���ã�
- ɸѡ����СԤ���
- ��nmsʱ��max_wh��Բ�ͬ����Ԥ���������֣���������������ϸ˵��
time_limit����ѭ��������ʱ�䲻�ܳ���10s
t = time.time()nc = prediction[0].shape[1] - 5 # number of classesmulti_label &= nc > 1 # multiple labels per box
t = time.time():���ص�ǰʱ���ʱ�����1970��Ԫ���ĸ�����������
nc = prediction[0].shape[1] - 5
����prediction��shapeΪ[batch, num_anchors X (gird_x X gird_y), (xywh+obj_conf+cls_num)]
����prediction[0].shape[1]��ȡprediciton���һά�ij��ȣ�����ǰ5������(xywh+obj)����ȥǰ���ά�ȼ����Եõ�ʣ��cls_num�ij��ȣ�nc��ʾ����Ŀ��
multi_label &= nc > 1
����������&����ʽ�ӷֱ�Ϊ��multi_label��nc>1����������ֵȡ��&��
output = [None] * prediction.shape[0]
prediction.shape[0]ָbatch_size������outputΪlist��list����Ϊ��ǰ�����predict��batch_size,�����Ԥ��δ���һ��ͼƬ����ôbatch_size=1����ô��ʱ��outputΪ1��list����֮output��list����Ϊbatch_size��
forѭ������Ľ���
for xi, x in enumerate(prediction): # image index, image inference ����ÿ��ͼƬ
���ڵ���ͼƬ��nms��������ѭ��ֻ��ִ��һ�Σ���������֤��������һ��batch����nms������ѭ������Ϊbatch_size��
prediciton��shape[batch, num_anchors X (gird_x X gird_y), (xywh+obj_conf+cls_num)]
x��shapeΪ[num_anchors X (gird_x X gird_y), (xywh+obj_conf+cls_num)]
# Apply constraintsx = x[x[:, 4] > conf_thres] # confidence ����obj confidence�dz�����Ŀ��x = x[((x[:, 2:4] > min_wh) & (x[:, 2:4] < max_wh)).all(1)] # width-height �˳�СĿ��
x = x[x[:, 4] > conf_thres]
ɸѡ��Obj_conf > conf_thres��Ԥ���
x = x[((x[:, 2:4] > min_wh) & (x[:, 2:4] < max_wh)).all(1)]
ɸѡ��Ԥ��������[min_wh,max_wh]֮���Ԥ�����Ϣ
# If none remain process next imageif not x.shape[0]:continue
x.shape[0]�ǵ�ǰͼƬɸѡ������Ԥ��������������ǰͼƬ����conf_thres���˳�СĿ���õ���Ԥ���Ϊ0����ô����ͼƬ����Ҫnms��continue��һ��ͼƬ����nms����
# Compute confx[..., 5:] *= x[..., 4:5] # conf = obj_conf * cls_conf
x[��, 5:]��ʾcls_confά�ȣ�x[��, 4:5]��ʾobj_conf
����ع���YOLO-V1������

ÿ��grid cellԤ��cls_num�������������Pr(Classi�OObject)Pr(Class_i\mid Object)Pr(Classi?�OObject)������Ҫ�õ�ʵ����������Ҫ
Pr(Classi)=Pr(Classi�OObject)?Pr(Object)Pr(Class_i)=Pr(Class_i\mid Object)\ast Pr(Object)Pr(Classi?)=Pr(Classi?�OObject)?Pr(Object)
ʵ�ʵȼ���
Pr(Classi)=cls_conf?obj_confPr(Class_i)=cls\_conf\ast obj\_confPr(Classi?)=cls_conf?obj_conf
������������֮��xԭ��cls_conf��λ�õ����ݴ�Pr(Classi�OObject)Pr(Class_i\mid Object)Pr(Classi?�OObject)��ΪPr(Classi)Pr(Class_i)Pr(Classi?)
# Box (center x, center y, width, height) to (x1, y1, x2, y2)box = xywh2xyxy(x[:, :4])
xywh2xyxy��������
def xywh2xyxy(x):# Convert nx4 boxes from [x, y, w, h] to [x1, y1, x2, y2] where xy1=top-left, xy2=bottom-righty = torch.zeros_like(x) if isinstance(x, torch.Tensor) else np.zeros_like(x)y[:, 0] = x[:, 0] - x[:, 2] / 2 # top left xy[:, 1] = x[:, 1] - x[:, 3] / 2 # top left yy[:, 2] = x[:, 0] + x[:, 2] / 2 # bottom right xy[:, 3] = x[:, 1] + x[:, 3] / 2 # bottom right yreturn y
��yolo��ʽ��xywhת��Ϊxyxy������box�������ı�x��ӦΪλ�õ�����
����NMSǰ�Ĵ����͵���NMSǰ�Ĵ���
����NMS
# Detections matrix nx6 (xyxy, conf, cls)if multi_label: # ���ÿ�����ִ�зǼ���ֵ����i, j = (x[:, 5:] > conf_thres).nonzero(as_tuple=False).t()x = torch.cat((box[i], x[i, j + 5].unsqueeze(1), j.float().unsqueeze(1)), 1)else: # best class only ֱ�����ÿ������и������������зǼ���ֵ���ƴ���conf, j = x[:, 5:].max(1)x = torch.cat((box, conf.unsqueeze(1), j.float().unsqueeze(1)), 1)[conf > conf_thres]
multi_label ������NMSΪtrue������NMSΪfalse��
i, j = (x[:, 5:] > conf_thres).nonzero(as_tuple=False).t()
x[:, 5:] > conf_thres��ʾ������Ԥ����cls_conf��conf_thres����ƥ�䣬������������ֵ����cls_conf��Ϊtrue��������Ϊfalse��debug�������£�

����Tensor:(1779,2)��ʾ�ҵ�ǰԤ��ͼƬ��Ԥ�����1779�����������Ϊ2��

������x[:, 5:] > conf_thres��״̬
nonzero(as_tuple=False).t()�����������ķ���ֵ����Trueֵ�ľ���λ�����ݣ�Ԥ���id����𣩱�������������i��j����(��(i,j)�������x[:, 5:]����Ѱַ��ô���conf_thres��������Ŷ�cls_conf�������˵��Ѱַ��tensorΪ(Ԥ���id���������)������i��ʾԤ���id��j��ʾ���)
ע�⣺i��ʾ��Ԥ���id�����п���Ԥ�������ͬһ��id���������ͬ����ʾ��Ԥ��������������Ŷȶ���conf_thres
x = torch.cat((box[i], x[i, j + 5].unsqueeze(1), j.float().unsqueeze(1)), 1)
box[i]��ʾԤ���i��״̬���£�


x[i, j + 5].unsqueeze(1)��ʾ��x�ڵ�2��ά�Ƚ�����չһ��ά�ȣ�ԭ����shape��[Ԥ���������xywh+obj+cls_num]
x[i, j + 5]��״̬���£�

����unsqueeze(1)��״̬���£�

j.float().unsqueeze(1)�����ת��Ϊ�������ͣ�������λ�õ�ά����ά��״̬���£�

���������������ڵ�2��ά����ƴ�ӣ��õ���x��״̬����:


����ѡȡx[0]=[3.02696e+02, 8.21888e+01, 3.32809e+02, 1.57338e+02, 1.08854e-01, 0.00000e+00]
��6����ֵ��ǰ�ĸ�������ʾ(xleft?top,yleft?top,xright?top,yright?top)(x_{left-top},y_{left-top},x_{right-top},y_{right-top})(xleft?top?,yleft?top?,xright?top?,yright?top?)��������������ʾ(cls_conf,j.float())(cls\_conf,j.float())(cls_conf,j.float())
����NMS
else: # best class only ֱ�����ÿ������и������������зǼ���ֵ���ƴ���conf, j = x[:, 5:].max(1)x = torch.cat((box, conf.unsqueeze(1), j.float().unsqueeze(1)), 1)[conf > conf_thres]
max(1)��ʾȡx[:, 5:]�����ά�ȵ����ֵ��������������cls_conf������ʾ�����j
torch.catͬ����NMS������ͬ
����NMS�͵���NMS������
�����������ֶ�����NMSǰ����ɸѡ�IJ�����Ϊ������˵����������ʵ���Ƿ����࣬��ô�ҽ�����ɸѡǰ����Ϊ(box_id,cls_conf1,cls_conf2)(box\_id,cls\_conf1,cls\_conf2)(box_id,cls_conf1,cls_conf2)
����NMS��ֻҪ��Ԥ���Ԥ���Ԥ�����cls_conf1cls\_conf1cls_conf1��cls_conf2cls\_conf2cls_conf2���Ŷȴ���conf_thres����ô��Ԥ����ᱣ�����������ɸѡ�õ�(box_id,cls_conf1)(box\_id,cls\_conf1)(box_id,cls_conf1)��(box_id,cls_conf2)(box\_id,cls\_conf2)(box_id,cls_conf2)
����ע�⣬����ɸѡ����Ԥ����У����в�ͬ��cls_conf1cls\_conf1cls_conf1��cls_conf2cls\_conf2cls_conf2��Ԥ��������ͬһ��box_idbox\_idbox_id�����Ƕ����ܻ��ͽ�NMS����.�������Ԥ�����ͬһ��Ԥ���,ֻ��Ԥ����cls_conf1cls\_conf1cls_conf1��cls_conf2cls\_conf2cls_conf2,�ڽ���NMSʱ,��ʾͬһ��Ԥ���,Ԥ�ⲻͬ�������target��IOU����ȫ�ص��ġ�����ͬһ���������target�������ĸ����õ�����������NMSԭ����֪,������soft-NMSԭ��,��ô���ٻ���һ����õ�����,��˵�������ǵ���ͬһԤ��������target������ͬ��cls_confcls\_confcls_conf����ô��������ܶ��ᱻ������
����NMS:Ԥ���ֻɸѡ������һ������target��ɸѡ����Ϊmax(cls_conf1,cls_conf2)max(cls\_conf1,cls\_conf2)max(cls_conf1,cls_conf2)��ע�ⵥ��NMS����Ҫ����conf_thresɸѡ��ֻȡ���������Ŷȵ�Ԥ�����ô���е�Ԥ��ᱻɸѡ�ϣ�����һ��Ԥ����Ӧһ��target��
classes����������
# Filter by classif classes:x = x[(j.view(-1, 1) == torch.tensor(classes, device=j.device)).any(1)]
�ҵ�ʵ��classes��ΪNone����ζ���������벢û��ִ�У����е���˼��
classes����˵�����ú������
j��״̬�ǣ�

j.view(-1,1)��״̬�ǣ�

classes��һ��list����nparrary������Ϊָ�������list,����NMSָ��ָ����������NMS,�����������,���ָ�������Ԥ�����֤,����Ԥ��ʱʹ�ý϶�,��Ϊһ��������չ,Ĭ�ϲ�ʹ��.
# If none remain process next imagen = x.shape[0] # number of boxesif not n:continue
�����������������ֵɸѡ֮���ж�x�Ƿ��ܼ���NMS
agnostic����������
# Batched NMSc = x[:, 5] * 0 if agnostic else x[:, 5] # classes
agnosticĬ��ʹ��false��c�IJ���Ϊtensor(Ԥ���id��)
x��shapeΪ(xleft?top,yleft?top,xright?top,yright?top,cls_conf,j.float())(x_{left-top},y_{left-top},x_{right-top},y_{right-top},cls\_conf,j.float())(xleft?top?,yleft?top?,xright?top?,yright?top?,cls_conf,j.float())
x[:, 5]��ʾ��6����������Ϣj.float()������ʾ���
c��״̬Ϊ��

agnosticΪTrue��ʹ��õ�������cȫΪ��һ�࣬��Ϊfalse��c��ȡ��������Ԥ���id��Ӧ����
�ñ����ľ�������δ֪������δ�õ������������������á�
boxes, scores = x[:, :4].clone() + c.view(-1, 1) * max_wh, x[:, 4]
x[:, :4]��ʾ(xleft?top,yleft?top,xright?top,yright?top)(x_{left-top},y_{left-top},x_{right-top},y_{right-top})(xleft?top?,yleft?top?,xright?top?,yright?top?)��Ϣ
c.view(-1, 1)��״̬Ϊ��

max_whΪ4096
����agnosticΪfasleʱ��max_wh�ܽ�c�з�0���������Ϣ(xleft?top,yleft?top,xright?top,yright?top)(x_{left-top},y_{left-top},x_{right-top},y_{right-top})(xleft?top?,yleft?top?,xright?top?,yright?top?)����max_wh��
�ڽ���nmsʱ��������boxes����
��agnosticΪTrueʱ��c��ֵ����ȫΪ0��boxes��Ϣ���������ֲ�ͬ���������Ϣ�������������NMS����.
����agnostic�����ľ���ʵ�����ڶ�boxes��ͬ��nms�Ĵ���
boxes��ͬ������������Ϣ���������NMS����
boxes = x[:, :4].clone() + c.view(-1, 1) * max_wh�����ォ��ͬ����������max_wh�����������֣����������뿴����debug���ҵ�0���boxes��Ϣdebug���£�


�������֣���ͬ���boxes��Ϣ��iou��0����ônmsֻ���ͬ��Ԥ��������
scoresΪx�ĵ�5����������cls_conf�������Ŷ�
i = torchvision.ops.nms(boxes, scores, iou_thres)
i = i[:max_num] # ���ֻ����ǰmax_num��Ŀ����Ϣ
����torchvision�Դ���nms�⺯��������giou������NMS
merge����������
if merge and (1 < n < 3E3): # Merge NMS (boxes merged using weighted mean)try: # update boxes as boxes(i,4) = weights(i,n) * boxes(n,4)iou = box_iou(boxes[i], boxes) > iou_thres # iou matrixweights = iou * scores[None] # box weightsx[i, :4] = torch.mm(weights, x[:, :4]).float() / weights.sum(1, keepdim=True) # merged boxes# i = i[iou.sum(1) > 1] # require redundancyexcept: # possible CUDA error https://github.com/ultralytics/yolov3/issues/1139print(x, i, x.shape, i.shape)pass
merge����Ĭ��Ϊfalse��
���Ϊtrue�������ɸѡ��boundingbox��һ��Ȩ�ط�����ߣ�Ȩ�ط����Ե�ǰɸѡ��box��Ϣ���ܵ�box��Ϣ����iou���㣬��iou��Iou_thres��box��������,����ǰ��ѿ�Ŀ��������¹�ʽ���£�
boxi=0[x1,y1,x2,y2]=��i=1targetclsi[x1_i,y1_i,x2_i,y2_i]��i=1targetclsibox_{i=0}[x_1,y_1,x_2,y_2]=\frac{\sum_{i=1}^{target}cls_i[x_{1\_i},y_{1\_i},x_{2\_i},y_{2\_i}]}{\sum_{i=1}^{target}cls_i}boxi=0?[x1?,y1?,x2?,y2?]=��i=1target?clsi?��i=1target?clsi?[x1_i?,y1_i?,x2_i?,y2_i?]?
���У�i=0i=0i=0��ʾcls_confcls\_confcls_conf��ߵ�һ��box��i=1i=1i=1��targettargettarget��boxes������boxmax_confbox_{max\_conf}boxmax_conf?��iou��iou_thresɸѡ�õ���box
����Ĵ�����������������Կ�����汾�Ĵ��룺
ԭ�ģ�nmsԴ����
elif method == 'merge': # weighted mixture boxwhile len(dc): # dc�ǰ����Ŷ��ź����box��Ϣif len(dc) == 1:det_max.append(dc)breaki = bbox_iou(dc[0], dc) > nms_thres # i = True/False�ļ���weights = dc[i, 4:5] # ����i����������Truedc[0, :4] = (weights * dc[i, :4]).sum(0) / weights.sum() # �ص���λ����Ϣ���ƽ��ֵdet_max.append(dc[:1])dc = dc[i == 0]
����NMS�еľ�������DZȽϼ�,��Ҫ���ӵ���NMSǰ��һЩ����.���ϴ����NMS�ǵ���ʹ��,����Դ��ʵ���Ҳ�̫���,������������汾��NMSʵ��,hard-nms,hard-nms-and��soft-nms��diou-nms��ԭ�ģ�nmsԴ����
# ����ʱ�䣺0.0030selif method == 'soft_nms': # soft-NMS https://arxiv.org/abs/1704.04503sigma = 0.5 # soft-nms sigma parameterwhile len(dc):# if len(dc) == 1: ����U���Դ�� �����˸�С�Ķ�# det_max.append(dc)# break# det_max.append(dc[:1])det_max.append(dc[:1]) # append dc�ĵ�һ�� ��targetif len(dc) == 1:breakiou = bbox_iou(dc[0], dc[1:]) # ����target���������iou# ����������ֱ����0��ͬ����0����Ҫ��ά��dc = dc[1:] # dc=target���������Ԥ���# dc���벻����target����ǰ��Ԥ�����Ϊ��Ҫ��ֵ���, ά���ϱ�����ͬdc[:, 4] *= torch.exp(-iou ** 2 / sigma) # �÷�˥��dc = dc[dc[:, 4] > conf_thres]# ����ʱ�䣺0.00299elif method == 'diou_nms': # DIoU NMS https://arxiv.org/pdf/1911.08287.pdfwhile dc.shape[0]: # dc.shape[0]: ��ǰclass��Ԥ�������det_max.append(dc[:1]) # ��score����һ��Ԥ���(�����ĵ�һ��)Ϊtargetif len(dc) == 1: # ���� dc��ֻʣ��һ����ʱ��breakbreak# dc[0] ��target dc[1:] ������Ԥ���diou = bbox_iou(dc[0], dc[1:], DIoU=True) # ���� dioudc = dc[1:][diou < nms_thres] # remove dious > threshold ����True ɾȥFalse