З°СФ
ФЪФД¶ББЛТ»ПөБРActivation FuntionВЫОДЦ®әу,ЖдЦРDynamic ReluөДВЫОДМбөҪБЛ»щУЪЧўТвБҰ»ъЦЖөДНшВз,ТтҙЛПИАҙҝҙҝҙҫӯөдөДSE-NetөДФӯАн
Introduction
¶ФУЪCNN,ҫн»эәЛФЪҫЦІҝёРКЬТ°ЦРҪ«ҝХјдәННЁөАРЕПўИЪәПөГөҪРЕПўЧйәП.НЁ№э¶СөюТ»ПөБР·ЗПЯРФҪ»ҙнөДҫн»эІгәНПВІЙСщ,CNNДЬ№»»сИЎҫЯУРИ«ҫЦёРКЬТ°өД·ЦІгДЈКҪЈ¬ЧчОӘЗҝҙуөДНјПсГиКцЎЈ
ЧоҪьөДСРҫҝұнГчЈ¬НшВзөДРФДЬҝЙТФНЁ№эПФКҪЗ¶ИлС§П°»ъЦЖАҙМбёЯЈ¬ХвУРЦъУЪІ¶»сҝХјдПа№ШРФЈ¬¶шОЮРиРиТӘ¶оНвөДја¶ҪЎЈЖдЦРТ»ЦЦ·Ҫ·ЁКЗУЙInceptionНЖ№гөДЈ¬ХвұнГчНшВзҝЙТФНЁ№эФЪЖдДЈҝйЦРЗ¶Ил¶аіЯ¶И№эіМАҙКөПЦҫЯУРҫәХщБҰөДЧјИ·РФЎЈ
ЧоҪьөД№ӨЧчКФНјёьәГөШДЈДвҝХјдТААө[1,31]Ј¬ІўДЙИлҝХјдЧўТв[19]ЎЈ
ЖдЦРЙПКцІОҝјөДВЫОДИзПВ
- [1]S. Bell, C. L. Zitnick, K. Bala, and R. Girshick. Inside- outside net: Detecting objects in context with skip pooling and
recurrent neural networks. InCVPR, 2016.1- [31]A. Newell, K. Y ang, and J. Deng. Stacked hourglass networks for human pose estimation. InECCV, 2016.1,2
- [19]M. Jaderberg, K. Simonyan, A. Zisserman, and K. Kavukcuoglu. Spatial transformer networks. In NIPS, 2015.1,2
ёГЖӘВЫОДСРҫҝБЛНшВзҪб№№ЙијЖөДТ»ёцІ»Н¬өД·ҪГж-НЁөА№ШПөЈ¬НЁ№эТэИлТ»ёцРВөДҪб№№өҘФӘЈ¬іЖЦ®ОӘЎ°Squeeze-and-
ExcitationЎұ (SE) blockЎЈ
ЧчХЯДҝұкКЗҪ«ҫн»эМШХчНЁөАЦ®јдөДПа»ҘТААөРФПФКҪөШҪЁДЈіцАҙЈ¬ТФМбёЯНшВзөДұнКҫДЬБҰЎЈОӘБЛКөПЦХвТ»өгЈ¬ОТГЗМбіцБЛТ»ЦЦ»ъЦЖЈ¬ФКРнНшВзЦҙРРМШХчЦШРВРЈЧјЈ¬НЁ№эёГ»ъЦЖЈ¬НшВзҝЙТФС§П°К№УГИ«ҫЦРЕПўАҙСЎФсРФөШЗҝөчРЕПўРФМШХчЈ¬ІўТЦЦЖІ»М«УРУГөДМШХчЎЈ

SE-blockөД»щұҫҪб№№ИзЙПНјЛщКҫЎЈУРИзПВ¶ЁТеЈә
¶ФИОәОёш¶ЁөДұд»»
Ftr:XЎъU,XЎКRHЎдЎБWЎдЎБCЎд,UЎКRHЎБWЎБCF_{tr}:X\to U,X\in \mathbb{R}^{H^{'}\times W^{'}\times C^{'}},U\in \mathbb{R}^{H\times W\times C}Ftr?:XЎъU,XЎКRHЎдЎБWЎдЎБCЎд,UЎКRHЎБWЎБC
ТФЙПёш¶ЁөДұд»»Хл¶ФТ»ёцҫн»э»тХЯТ»Чйҫн»э¶шСФЎЈ
ОТГЗҝЙТФ№№ФмТ»ёцПаУҰөДSEҝйАҙЦҙРРМШХчЦШРВРЈЧјЈ¬ИзПВЛщКҫЎЈ
МШХчUUUКЧПИНЁ№эТ»ёцsqueezesqueezesqueezeІЩЧчЈ¬ёГІЩЧчҪ«ҝХјдО¬¶ИЙПөДМШХчУіЙдҫЫәПЈ¬ЙъіЙНЁөАdescriptorЎЈ
ёГdescriptorЗ¶ИлБЛНЁөАМШХчПмУҰөДИ«ҫЦ·ЦІјЈ¬К№АҙЧФНшВзИ«ҫЦёРКЬТ°өДРЕПўДЬ№»ұ»ЖдҪПөНІгАыУГЎЈ
И»әуҫӯ№эТ»ёцexcitationexcitationexcitationІЩЧчЈ¬ФЪёГІЩЧчЦРЈ¬НЁ№э»щУЪНЁөАТААөРФөДself-gating»ъЦЖОӘГҝёцНЁөАС§П°өДСщұҫМШ¶ЁјӨ»оҝШЦЖГҝёцНЁөАөДexcitationexcitationexcitation
И»әу¶ФМШХчУіЙдUUUЦШРВјУИЁТФЙъіЙSE-blockөДКдіцЈ¬И»әуҪ«ЖдЦұҪУКдИләуРшөДlayersЎЈ
SE-networkҝЙТФНЁ№эјтөҘөШ¶СөюSE building blockөДјҜәПАҙЙъіЙЎЈSE-block ТІҝЙТФЧчОӘјЬ№№ЦРИОәОЙо¶ИЦРoriginal blockөДМжҙъЎЈ
SE-blockФЪјЖЛгЙПКЗЗбБҝј¶өДЈ¬Ц»»бЙФОўФцјУДЈРНөДёҙФУРФәНјЖЛгёәөЈЎЈ
К№УГSENets,ЧчХЯУ®өГБЛ2017ДкILSVRC·ЦАаұИИьөДөЪТ»ГыЎЈ
ұнПЦЧоәГөДДЈРНЧйәПКөПЦБЛ2.251% top-5 errorФЪILSVRCІвКФјҜЙПЎЈұИЗ°Т»ДкөДwinnerМбёЯБЛ25%ЈЁЗ°Т»ДкөДwinnerөДtop-5 errorКЗ2.991%Ј©
Related Work
Attention and gating mechanisms
ҙУ№гТеЙПҪІЈ¬ЧўТвБҰҝЙТФұ»КУОӘТ»ЦЦ№ӨҫЯЈ¬К№ҝЙУГҙҰАнЧКФҙөД·ЦЕдЖ«ПтУЪКдИлРЕәЕЦРРЕПўБҝЧоҙуөДіЙ·ЦЎЈЛьНЁіЈУлgating№ҰДЬ(АэИзsoftmax»тsigmoid)әНsequentialјјКхҪбәПК№УГЎЈЈЁХвАпЦёөДsequentialјјКхГ»УРЙоИлБЛҪвЈ¬УРРЛИӨҝҙИзПВІОҝјОДПЧЈ©
- S. Hochreiter and J. Schmidhuber. Long short-term memory.Neural computation, 1997.2
- M. F. Stollenga, J. Masci, F. Gomez, and J. Schmidhuber.Deep networks with internal selective attention through feedback
connections. In NIPS, 2014.2
ФЪХвР©УҰУГЦРЈ¬ЛьНЁіЈУГУЪұнКҫёьёЯІгҙОійПуөДТ»ёц»т¶аёцІгЦ®ЙПЈ¬ТФұгФЪІ»Н¬өДДЈКҪЦ®јдҪшРРККЕдЎЈ
Related workөДПкПёГиКцОТГ»УРИ«МщіцАҙЈ¬ФӯТтКЗҪІКцөДБмУтУРөг№гЈ¬»тХЯІ»М«ЦШТӘөДГиКцЈ¬ОТГЗЦчТӘ№ШЧўSE-blockКЗФхГҙКөПЦөДЎЈ
Squeeze-and-Excitation Blocks
SE-blockКЗТ»ёцјЖЛгөҘФӘЈ¬ҝЙТФ№№ФмИОәОёш¶Ёұд»»Јә
Ftr:XЎъU,XЎКRHЎдЎБWЎдЎБCЎд,UЎКRHЎБWЎБC\textbf{F}_{tr}:\textbf{X}\to \textbf{U},\textbf{X}\in\mathbb{R}^{H^{'}\times W^{'}\times C^{'}},\textbf{U}\in\mathbb{R}^{H\times W\times C}Ftr?:XЎъU,XЎКRHЎдЎБWЎдЎБCЎд,UЎКRHЎБWЎБC
ЖдЦРЈ¬Ftr\textbf{F}_{tr}Ftr?КЗТ»ёцҫн»эЛгЧУЈ¬БоV=[v1,v2,...,vC]\textbf{V}=[\textbf{v}_1,\textbf{v}_2,...,\textbf{v}_C]V=[v1?,v2?,...,vC?]ұнКҫС§П°өДВЛІЁЖчәЛјҜЈ¬ЖдЦРvcv_cvc?ЦёөДКЗөЪcёцВЛІЁЖчІОКэЎЈ
Ftr\textbf{F}_{tr}Ftr?өДКдіцҝЙТФРҙіЙU=[u1,u2,...,uC]\textbf{U}=[\textbf{u}_1,\textbf{u}_2,...,\textbf{u}_C]U=[u1?,u2?,...,uC?]Ј¬ЖдЦР
uc=vc?X=ЎЖs=1CЎдvcs?xs.???(1)\textbf{u}_c=\textbf{v}_c\ast \textbf{X}=\sum_{s=1}^{C^{'}}\textbf{v}_c^s\ast \textbf{x}^s.---(1)uc?=vc??X=s=1ЎЖCЎд?vcs??xs.???(1)
ХвАп?ұнКҫҫн»эЈ¬vc=[vc1,vc2,...,vcCЎд]\textbf{v}_c=[\textbf{v}_c^1,\textbf{v}_c^2,...,\textbf{v}_c^{C^{'}}]vc?=[vc1?,vc2?,...,vcCЎд?]әНX=[x1,x2,...,xCЎд]\textbf{X}=[\textbf{x}^1,\textbf{x}^2,...,\textbf{x}^{C{'}}]X=[x1,x2,...,xCЎд](јт»Ҝ·ыәЕЈ¬КЎВФЖ«ЦГПо)
ЖдЦРvcsv_c^svcs?КЗТ»ёц¶юО¬өДҫн»эәЛЈ¬ұнКҫvcv_cvc?өДТ»ёцНЁөАЈ¬ЧчУГУЪXXX¶ФУҰөДНЁөАЎЈУЙУЪКдіцКЗНЁ№эЛщУРНЁөАөДЗуәНІъЙъөДЈ¬ТтҙЛНЁөАТААөРФКЗТюКҪЗ¶ИлөҪvcv_cvc?ЦРЈ¬ө«КЗХвР©ТААө№ШПөУлВЛІЁЖчІ¶»сөДҝХјдПа№ШРФҫАІшФЪТ»ЖрЎЈ
ОТГЗөДДҝұкКҪИ·ұЈНшВзДЬ№»МбёЯЖд¶ФРЕПўМШХчөДГфёРРФЈ¬ТФұгЛьГЗҝЙТФұ»әуРшөДЧӘ»»АыУГЈ¬ІўТЦЦЖІ»М«УРУГөДМШХчЎЈ
ОТГЗҪЁТйНЁ№эПФКҪҪЁДЈНЁөАПа»ҘТААөАҙКөПЦХвТ»өгЈ¬ФЪЛьГЗұ»АЎЛНөҪПВТ»ёцұд»»Ц®З°Ј¬ФЪSqueezeәНExcitationБҪёцІҪЦиЦРЦШРВРЈЧјВЛІЁЖчПмУҰЎЈНј1ПФКҫБЛТ»ёцSE№№ҪЁҝйөДКҫТвНјЎЈ
Squeeze: Global Information Embedding
ОӘБЛҪвҫцАыУГНЁөАТААөРФөДОКМвЈ¬ОТГЗКЧПИҝјВЗРЕәЕөҪГҝёцНЁөАКдіцМШХчЎЈГҝёцС§П°№эөДВЛІЁЖч¶јУРТ»ёцҫЦІҝёРКЬТ°Ј¬ТтҙЛГҝТ»ёцЧӘ»»КдіцөДөҘФӘUUUКЗОЮ·ЁАыУГёГёРКЬТ°Ц®НвөДЙППВОДРЕПўЎЈ
ХвАпНЁЛЧөДЛөҝЙТФУРБҪЦЦҪвКНЈә
1.С§П°№эөДВЛІЁЖчЦ®јдОЮ·Ё»ҘПаАыУГЦ®јдөДРЕПўЈ¬јҙИзПВ№«КҪЦРөДvcv_cvc?Ц®јдОЮ·ЁНЁРЕЎЈ
2.ГҝёцЧӘ»»КдіцөДөҘФӘUUUөД№«КҪИзПВЈә
uc=vc?X=ЎЖs=1CЎдvcs?xs.???(1)\textbf{u}_c=\textbf{v}_c\ast \textbf{X}=\sum_{s=1}^{C^{'}}\textbf{v}_c^s\ast \textbf{x}^s.---(1)uc?=vc??X=s=1ЎЖCЎд?vcs??xs.???(1)
¶ФУЪЧӘ»»КдіцөДөҘФӘuc\textbf{u}_cuc?ОЮ·ЁАыУГЖдЛыЧӘ»»КдіцөҘФӘөДЙППВОДЈ¬Ц»ДЬІ¶»сөұЗ°vc\textbf{v}_cvc?ёРКЬТ°өДРЕПўЎЈ
ХвёцОКМвФЪёРКЬТ°ҪПРЎөДНшВзөНІгұдөГёьјУСПЦШЎЈ
ОӘБЛ»әҪвХвёцОКМвЈ¬ОТГЗҪЁТйҪ«И«ҫЦҝХјдРЕПў·ЕИлНЁөАdescriptorЈЁФӯВЫОДОӘchannel descriptorЈ¬ХвАпОТІ»ЦӘөАХҰ·ӯТлЈ¬Ҫ«ФӯөҘҙКcopy№эАҙЈ¬·АЦ№ТэЖрЖзТеЈ©ЦРЎЈХвКЗНЁ№эК№УГИ«ҫЦЖҪҫщіШ»ҜЙъіЙНЁөАНіјЖРЕПўАҙКөПЦөДЎЈ
РОКҪЙПЈ¬НіјЖБҝzЎКRCz\in \mathbb{R}^CzЎКRCКЗУЙС№ЛхКдіцUUUөДҝХјдО¬¶ИHЎБWH\times WHЎБWЙъіЙөДЈ¬ЖдЦРz\textbf{z}zөДөЪcccёцФӘЛШҝЙТФұ»јЖЛгОӘЈә
zc=Fsq(uc)=1HЎБWЎЖi=1HЎЖj=1Wuc(i,j),???(2)z_c=\textbf{F}_{sq}(\textbf{u}_c)=\frac{1}{H\times W}\sum_{i=1}^H\sum_{j=1}^Wu_c(i,j),---(2)zc?=Fsq?(uc?)=HЎБW1?i=1ЎЖH?j=1ЎЖW?uc?(i,j),???(2)
јтҪаөШЛөЈәНіјЖБҝzcz_czc?ҫНКЗөЪcccёцКдіцөҘФӘөДИ«ҫЦЖҪҫщіШ»ҜКдіцЎЈХвёцРЕПўКЗНЁөАНіјЖРЕПўөДТ»Іҝ·ЦЈ¬ЧчОӘГҝёцНЁөАөДНіјЖБҝЎЈ
ЧчХЯөДМЦВЫЈә ұд»»КдіцU\textbf{U}UҝЙТФҪвКНОӘТ»ёцҫЦІҝdescriptorsөДјҜәПЈ¬ХвР©descriptorsөДНіјЖБҝҝЙТФұнҙпХыёцНјПсЎЈФЪМШХч№ӨіМ№ӨЧчЦРЈ¬АыУГХвР©РЕПўКЗәЬЖХұйөД[35,38,49]ЎЈ
[35] J. Sanchez, F. Perronnin, T. Mensink, and J. V erbeek. Image classification with the fisher vector: Theory and practice.RR-8209, INRIA, 2013.3
[38] L. Shen, G. Sun, Q. Huang, S. Wang, Z. Lin, and E. Wu.Multi-level discriminative dictionary learning with application to large scale image classification.IEEE TIP, 2015.3
[49] J. Y ang, K. Y u, Y . Gong, and T. Huang. Linear spatial pyramid matching using sparse coding for image classification.InCVPR, 2009.3
ОТГЗСЎФсБЛЧојтөҘөДИ«ҫЦЖҪҫщіШЈ¬ЧўТвөҪХвАпТІҝЙТФК№УГёьёҙФУөДҫЫәПІЯВФЎЈ
Excitation: Adaptive Recalibration
ОӘБЛАыУГsqueezeІЩЧчЈЁЙПТ»ҪЪМбөҪөДИ«ҫЦЖҪҫщіШ»ҜОӘТ»ЦЦsqueezeЈ©ЦРҫЫјҜөДРЕПўЈ¬ОТГЗЛжәуҪшРРөЪ¶юҙОІЩЧчЈ¬ДҝұкКЗНкИ«І¶»сНЁөАТААөРФЎЈ
ОӘБЛКөПЦХвТ»ДҝұкЈ¬ёГfunctionұШРл·ыәПБҪёцЧјФт:
- КЧПИЈ¬ЛьұШРлКЗБй»оөД(МШұрКЗЈ¬ЛьұШРлДЬ№»С§П°НЁөАЦ®јдөД·ЗПЯРФПа»ҘЧчУГ)
- ЖдҙОЈ¬ЛьұШРлС§»бТ»ЦЦ·З»ҘівөД№ШПөЈ¬ТтОӘОТГЗПлТӘИ·ұЈ¶аёцНЁөАұ»ФКРнұ»ЗҝөчЈ¬¶шІ»КЗТ»ҙОРФјӨ»оЎЈ
ОӘБЛВъЧгХвР©ұкЧјЈ¬ОТГЗСЎФсІЙУГјтөҘөДsigmoidјӨ»оgating»ъЦЖ:
s=Fex(z,W)=ҰТ(g(z,W))=ҰТ(W2ҰД(W1z)),???(3)\textbf{s}=\textbf{F}_{ex}(\textbf{z,W})=\sigma(g(\textbf{z,W}))=\sigma(\textbf{W}_2\delta(\textbf{W}_1\textbf{z})),---(3)s=Fex?(z,W)=ҰТ(g(z,W))=ҰТ(W2?ҰД(W1?z)),???(3)
ЖдЦРҰД\deltaҰДОӘReLUјӨ»оәҜКэЈ¬W1ЎКRCrЎБC\textbf{W}_1\in\mathbb{R}^{\frac{C}{r}\times C}W1?ЎКRrC?ЎБCЈ¬W2ЎКRCЎБCr\textbf{W}_2\in\mathbb{R}^{C\times\frac{C}{r}}W2?ЎКRCЎБrC?
ОӘБЛПЮЦЖДЈРНөДёҙФУРФІўЦъУЪНЖ№гЈ¬ОТГЗНЁ№эО§ИЖ·ЗПЯРФРОіЙБҪёцНкИ«Б¬ҪУ(FC)ІгөДbottleneckАҙІОКэ»Ҝgating»ъЦЖЈ¬»»ҫд»°ЛөЈ¬ҙшУРІОКэW1\textbf{W}_1W1?әНҪөО¬ұИrrrөДҪөО¬ІгЈЁХвёцІОКэөДСЎФсәуРш»бМбөҪЈ©Ј¬ҪУЧЕТ»ёцReLUЈ¬»№УРТ»ёцІОКэОӘW2\textbf{W}_2W2?өДЙэО¬ІгЎЈ
ХвАп»Ш№ЛПВНј1Ј¬ЧўТвКдИлКдіцөДО¬¶Иұд»ҜЈә
- Squeeze-Fsq\textbf{F}_{sq}Fsq?Ц®әуЈ¬U[HЎБWЎБC]U[H\times W\times C]U[HЎБWЎБC]ҫӯ№эИ«ҫЦЖҪҫщіШ»ҜөГөҪМШХчКдіцО¬¶ИОӘ[1ЎБ1ЎБC][1\times 1\times C][1ЎБ1ЎБC]
- Excitation-Fex\textbf{F}_{ex}Fex?өГөҪМШХчКдіцО¬¶ИОӘ[1ЎБ1ЎБC][1\times 1\times C][1ЎБ1ЎБC]Ј¬Fex\textbf{F}_{ex}Fex?өДПкПёІЩЧчЦРЈ¬W1\textbf{W}_1W1?ұнКҫөЪТ»ёцFCІгөДИЁЦШІОКэЈ¬W2\textbf{W}_2W2?ұнКҫөЪ¶юёцFCІгөДИЁЦШІОКэЎЈ
№«КҪЈЁ3Ј©Fex\textbf{F}_{ex}Fex?өДҫЯМеІЩЧчЈәFC+ReLU+FC+Sigmoid
- FCЈәВЫОДАпМбөҪW1\textbf{W}_1W1?КЗҪөО¬өДЈ¬КЧПИНЁ№эТ»ёцИ«Б¬ҪУІг(FC)Ҫ«НіјЖБҝz\textbf{z}zҙУМШХчО¬¶ИCCCҪөО¬өҪМШХчО¬¶ИCr\frac{C}{r}rC?
- ReLU+FC:Ҫ«1ІҪЦиөГөҪөДМШХчҫӯ№эReLUјӨ»оәуФЩҙ«ИлТ»ёцИ«Б¬ҪУІг(FC)Ј¬ВЫОДАпМбөҪW2\textbf{W}_2W2?КЗЙэО¬өДЈ¬ёГFCҪ«МШХчО¬¶ИCr\frac{C}{r}rC?ЙэО¬өҪМШХчО¬¶ИCCCЈ¬ПаөұУЪ»ЦёҙөҪНіјЖБҝzzzөДМШХчО¬¶И
- SigmoidЈәҪ«1Ј¬2ІҪЦиөГөҪөДМШХчҫӯ№эSigmid№йТ»»ҜіЙ0-1өДИЁЦШ
ЙПКцМбөҪөДFCІгөДҙҰАнПаөұУЪ¶ФНіјЖБҝz\textbf{z}zөДНЁөАРЕПўҫӯ№эИ«Б¬ҪУІгМбИЎНЁөАөДПа№ШРФМШХч
blockөДЧоЦХКдіцКЗНЁ№эК№УГјӨ»оЛх·Еұд»»КдіцUUUАҙөГөҪөДЈә
x~c=Fscale(uc,sc)=sc?uc,???(4)\widetilde{\textbf{x}}_c=\textbf{F}_{scale}(\textbf{u}_c,s_c)=s_c\cdot \textbf{u}_c,---(4)x
c?=Fscale?(uc?,sc?)=sc??uc?,???(4)
ЖдЦРX~=[x~1,x~2,...,x~C]\widetilde{X}=[\widetilde{x}_1,\widetilde{x}_2,...,\widetilde{x}_C]X
=[x
1?,x
2?,...,x
C?]әНFscale(uc,sc)\textbf{F}_{scale}(\textbf{u}_c,s_c)Fscale?(uc?,sc?)КЗЦёМШХчУіЙдucЎКRHЎБW\textbf{u}_c\in \mathbb{R}^{H\times W}uc?ЎКRHЎБWәНұкБҝscs_csc?Ц®јдөДНЁөАіЛ»э
ХвАпscaleІЩЧчЦРөДscs_csc?ЦёFex\textbf{F}_{ex}Fex?өДКдіцЈ¬uc\textbf{u}_cuc?ЦёОҙҫӯsqueezeәНexcitationөДКдіцU\textbf{U}UөДТ»Іҝ·ЦЈ¬УГscs_csc?јУИЁөҪuc\textbf{u}_cuc?өДГҝёцНЁөАМШХчЙПЈ¬ВЫОДЦРУГөҪөДјУИЁКЗіЛ·ЁЈ¬ЦрНЁөАіЛТФИЁЦШПөКэЈ¬НкіЙФЪНЁөАО¬¶ИЙПТэИлattention»ъЦЖ
МЦВЫЈәјӨ»оідөұККУҰУЪМШ¶ЁКдИлГиКцz\textbf{z}zөДНЁөАИЁЦШЎЈФЪХвТ»өгЙПЈ¬SE-blockұҫЦКЙПТэИлБЛ¶ҜМ¬КдИлМхјюЈ¬УРЦъУЪМбёЯМШХчұжұрДЬБҰЎЈ
InceptionәНResNet¶ФУҰөДНшВзҪб№№


НшВзДЈРНәНјЖЛгёҙФУРФ
In aggregate,SE-ResNet-50 requires?3.87GFLOPs, corresponding to a 0.26%relative increase over the original ResNet-50.In practice, with a training mini-batch of256images, a single pass forwards and backwards through ResNet-50 takes190ms, compared to209ms for SE-ResNet-50 (both timings are performed on a server with 8 NVIDIA Titan X GPUs).
ОТГЗИПОӘЈ¬ХвКЗТ»ёцәПАнөДҝӘПъЈ¬МШұрКЗТтОӘФЪПЦУРөДGPUҝвЦРЈ¬И«ҫЦіШәНРЎРНДЪІҝІъЖ·ІЩЧчөДУЕ»ҜіМ¶ИҪПөНЎЈҙЛНвЈ¬УЙУЪЖд¶ФУЪЗ¶ИлКҪЙиұёУҰУГөДЦШТӘРФЈ¬ОТГЗ»№¶ФГҝёцДЈРНөДCPUНЖАнКұјдҪшРРБЛ»щЧјІвКФЈә¶ФУЪ224ЎБ224ПсЛШөДКдИлНјПсЈ¬ResNet-50РиТӘ164әБГлЈ¬¶шSE-ResNet-50Ц»РиТӘ167әБГлЎЈSEҝйЛщРиөДЙЩБҝ¶оНвјЖЛгҝӘПъТтЖд¶ФДЈРНРФДЬөД№ұПЧ¶шұ»ЦӨГчКЗәПАнөДЎЈ
SE-ResNet-50ТэИлБЛ¶а250НтІОКэБҝЈ¬ПаұИФӯАҙ°ьә¬БЛ2500НтІОКэБҝөДResNet-50¶шСФЎЈ
КөСй






і¬ІОКэИЎЦө
Reduction ratioЈә

The role of ExcitationЈә

¶ФУЪЙПНјЈ¬ЧчХЯФЪВЫОДҪшРРБЛҪвКН
- КЧПИЈ¬ФЪҪПөНөДІгЦРЈ¬І»Н¬АаұрөД·ЦІјјёәхПаН¬Ј¬АэИзSE_2_3ЎЈХвұнГчФЪНшВзөДФзЖЪҪЧ¶ОЈ¬НЁөАМШХчөДЦШТӘРФәЬҝЙДЬұ»І»Н¬Ааұр№ІПнЎЈ
- И»¶шЈ¬УРИӨөДКЗЈ¬өЪ¶юёц№ЫІмҪб№ыКЗЈ¬ФЪёьЙоөДЙо¶ИЈ¬ГҝёцНЁөАөДЦөұдөГёьјУМШ¶ЁУЪАаұрЈ¬ТтОӘІ»Н¬өДАаұрұнПЦіц¶ФМШХчөДЗшұрРФЦөөДІ»Н¬Ж«әГЈ¬АэИзSE_4_6әНSE_5_1ЎЈ
- ХвБҪёц№ЫІмҪб№ыУлТФЗ°№ӨЧч[23Ј¬50]ЦРөД·ўПЦКЗТ»ЦВөДЈ¬јҙҪПөНІгөДМШХчНЁіЈёьТ»°г(јҙФЪ·ЦАаөДЙППВОДЦРУлАаұрОЮ№Ш)Ј¬¶шҪПёЯІгөДМШХчҫЯУРёьҙуөДМШТмРФЎЈ
[23] H. Lee, R. Grosse, R. Ranganath, and A. Y . Ng. Convolutional deep belief networks for scalable unsupervised learning of hierarchical representations. InICML, 2009.8
[50] J. Y osinski, J. Clune, Y . Bengio, and H. Lipson. How transferable are features in deep neural networks? InNIPS, 2014.8
- ТтҙЛЈ¬ұнКҫС§П°КЬТжУЪSE-blockУХөјөДЦШРВРЈЧјЈ¬ХвЧФККУҰөШҙЩҪшБЛМШХчМбИЎәНККУҰ»ҜөҪРиТӘөДіМ¶ИЎЈ
- ЧоәуЈ¬ОТГЗФЪНшВзөДЧоәуҪЧ¶О№ЫІмөҪБЛТ»ёцВФУРІ»Н¬өДПЦПуЎЈSE_5_2іКПЦіцТ»ЦЦУРИӨөДЗчПтУЪұҘәНЧҙМ¬Ј¬ФЪХвЦЦЧҙМ¬ПВЈ¬ҙу¶аКэјӨ»оҪУҪьУЪ1Ј¬ЖдУаөДҪУҪьУЪ0ЎЈФЪЛщУРјӨ»оИЎЦө1КұЈ¬ёГҝйҪ«іЙОӘұкЧјІРІоҝйЎЈФЪSE53өДНшВзД©¶Л(ҪфЛжЖдәуөДКЗФЪ·ЦАаЖчЦ®З°өДИ«ҫЦіШ»Ҝ)Ј¬АаЛЖөДДЈКҪіцПЦФЪІ»Н¬өДАаЙПЈ¬ЦұөҪ№жДЈЙПөДОўРЎұд»Ҝ(ХвҝЙТФНЁ№э·ЦАаЖчҪшРРөчХы)ЎЈ
- ХвұнГчSE_5_2әНSE_5_3ФЪПтНшВзМṩЦШРВРЈЧј·ҪГжІ»ИзПИЗ°ҝйЦШТӘЎЈХвТ»·ўПЦУлөЪЛДҪЪөДКөЦӨСРҫҝҪб№ыКЗТ»ЦВөДЈ¬ёГөчІйҪб№ыұнГчЈ¬НЁ№эИҘіэЧоәуТ»ј¶өДSEҝйҝЙТФПФЦшјхЙЩЧЬМеІОКэјЖКэЈ¬¶шРФДЬЦ»»бУРЗбОўөДЛрК§ЎЈ
ҪбВЫ
ФЪұҫОДЦРЈ¬ОТГЗМбіцБЛSEҝйЈ¬ХвКЗТ»ЦЦРВөДҪб№№өҘФӘЈ¬ЦјФЪНЁ№эК№НшВзЦҙРР¶ҜМ¬НЁөАМШХчЦШРВРЈЧјАҙМбёЯНшВзөДұнХчДЬБҰЎЈҙуБҝөДКөСйЦӨГчБЛSENetsөДУРР§РФЈ¬ФЪ¶аёцКэҫЭјҜЙПКөПЦБЛЧоПИҪшөДРФДЬЎЈҙЛНвЈ¬ЛьГЗ»№МṩБЛТ»Р©¶ФПИЗ°МеПөҪб№№ФЪҪЁДЈНЁөАМШХчТААө·ҪГжөДҫЦПЮРФөДјыҪвЈ¬ОТГЗПЈНыХв¶ФЖдЛыРиТӘЗҝЗш·ЦМШХчөДИООсКЗУРУГөДЎЈЧоәуЈ¬SEҝйЛщУХөјөДМШХчЦШТӘРФҝЙДЬУРЦъУЪНшВзјфЦҰС№ЛхөИПа№ШБмУтөДСРҫҝЎЈ
Т»Р©АнҪв
ВЫОДИПОӘФЪExcitationІЩЧчЦРУГБҪёцИ«Б¬ҪУІгұИЦұҪУУГТ»ёцИ«Б¬ҪУІгөДәГҙҰФЪУЪЈә1Ј©ҫЯУРёь¶аөД·ЗПЯРФЈ¬ҝЙТФёьәГөШДвәПНЁөАјдёҙФУөДПа№ШРФЈ»2Ј©ј«ҙуөШјхЙЩБЛІОКэБҝәНјЖЛгБҝЎЈ
ФҙВл
SE-ResNetҙъВлЈә
import torch
from torch import nn
from torchvision.models import resnet
from torchsummary import summary# ХвёцДЈРНКЗҪ«SEДЈҝйјУИлГҝёцResBlockЦРБЛЈ¬»№ҝЙТФЦ»јУФЪДЈРНҝӘН·әНҪбОІЈ¬өҪөЧКЗФхГҙјУИлДЈРН»№КЗТӘҝҙКөСйҪб№ыөДdef conv3x3(in_channel, out_channel, stride=1, padding=1):"""3x3 convolution with padding"""return nn.Conv2d(in_channel, out_channel, kernel_size=3, stride=stride, padding=padding, bias=False)def conv1x1(in_channel, out_channel, stride=1):"""1x1 convolution"""return nn.Conv2d(in_channel, out_channel, kernel_size=1, stride=stride, bias=False)class SELayer(nn.Module):def __init__(self, channel, reduction=16):# https://github.com/moskomule/senet.pytorch/blob/master/senet/se_resnet.pysuper(SELayer, self).__init__()self.avg_pool = nn.AdaptiveAvgPool2d(1)self.fc = nn.Sequential(nn.Linear(channel, channel // reduction, bias=False),nn.ReLU(inplace=True),nn.Linear(channel // reduction, channel, bias=False),nn.Sigmoid())def forward(self, x):b, c, _, _ = x.size() # x=[b,256,56,56]y = self.avg_pool(x).view(b, c) # self.avg_pool(x)=>[b,256,1,1] .view=>[b,256]y = self.fc(y).view(b, c, 1, 1) # self.fc(y)=>[b,256] .view=>[b,256,1,1]return x * y.expand_as(x) # ёҙЦЖ[b,256,1,1] => [b,256,56,56]class SE_BasicBlock(nn.Module):# resnet18 + resnet34(resdual1) КөПЯІРІоҪб№№+РйПЯІРІоҪб№№expansion = 1 # ІРІоҪб№№ЦРЦч·ЦЦ§өДҫн»эәЛёцКэКЗ·с·ўЙъұд»ҜЈЁұ¶КэЈ© өЪ¶юёцҫн»эәЛКдіцКЗ·с·ўЙъұд»Ҝdef __init__(self, in_channel, out_channel, stride=1, downsample=None):""": params: in_channel=өЪТ»ёцconvөДКдИлchannel: params: out_channel=өЪТ»ёцconvөДКдіцchannel: params: stride=ЦРјдconvөДstride: params: downsample=None:КөПЯІРІоҪб№№/Not None:РйПЯІРІоҪб№№"""super(SE_BasicBlock, self).__init__()self.conv1 = conv3x3(in_channel=in_channel, out_channel=out_channel, stride=stride)self.bn1 = nn.BatchNorm2d(out_channel)self.relu = nn.ReLU(inplace=True)self.conv2 = conv3x3(in_channel=out_channel, out_channel=out_channel)self.bn2 = nn.BatchNorm2d(out_channel)self.downsample = downsampleself.se = SELayer(out_channel)def forward(self, x):identity = xif self.downsample is not None:identity = self.downsample(x)out = self.conv1(x)out = self.bn1(out)out = self.relu(out)out = self.conv2(out)out = self.bn2(out)out = self.se(out)out += identityout = self.relu(out)return outclass SE_Bottleneck(nn.Module):# resnet50+resnet101+resnet152ЈЁresdual2Ј© КөПЯІРІоҪб№№+РйПЯІРІоҪб№№expansion = 4 # ІРІоҪб№№ЦРЦч·ЦЦ§өДҫн»эәЛёцКэКЗ·с·ўЙъұд»ҜЈЁұ¶КэЈ© өЪИэёцҫн»эәЛКдіцКЗ·с·ўЙъұд»Ҝdef __init__(self, in_channel, out_channel, stride=1, downsample=None):""": params: in_channel=өЪТ»ёцconvөДКдИлchannel: params: out_channel=өЪТ»ёцconvөДКдіцchannel: params: stride=ЦРјдconvөДstrideresnet50/101/152:conv2_xөДЛщУРІгs=1 conv3_x/conv4_x/conv5_xөДөЪТ»Ігs=2,ЖдЛыІгs=1: params: downsample=None:КөПЯІРІоҪб№№/Not None:РйПЯІРІоҪб№№"""super(SE_Bottleneck, self).__init__()# 1x1ҫн»эТ»°гs=1 p=0 => wЎўhІ»ұд ҫн»эД¬ИППтПВИЎХыself.conv1 = conv1x1(in_channel=in_channel, out_channel=out_channel, stride=1)self.bn1 = nn.BatchNorm2d(out_channel)# ----------------------------------------------------------------------------------# 3x3ҫн»эТ»°гs=2 p=1 => wЎўh /2ЈЁПВІЙСщЈ© 3x3ҫн»эТ»°гs=1 p=1 => wЎўhІ»ұдself.conv2 = conv3x3(in_channel=out_channel, out_channel=out_channel, stride=stride)self.bn2 = nn.BatchNorm2d(out_channel)# ---------------------------------------------------------------------------------self.conv3 = conv1x1(in_channel=out_channel, out_channel=out_channel * self.expansion, stride=1)self.bn3 = nn.BatchNorm2d(out_channel * self.expansion)# ----------------------------------------------------------------------------------self.relu = nn.ReLU(inplace=True)self.downsample = downsampleself.se = SELayer(out_channel * self.expansion)def forward(self, x):identity = xif self.downsample is not None:identity = self.downsample(x)out = self.conv1(x)out = self.bn1(out)out = self.relu(out)out = self.conv2(out)out = self.bn2(out)out = self.relu(out)out = self.conv3(out)out = self.bn3(out)out = self.se(out)out += identityout = self.relu(out)return outclass SE_ResNet(nn.Module):def __init__(self, block, blocks_num, num_classes=1000):""": params: block=BasicBlock/Bottleneck: params: blocks_num=ГҝёцlayerЦРІРІоҪб№№өДёцКэ: params: num_classes=КэҫЭјҜөД·ЦАаёцКэ"""super(SE_ResNet, self).__init__()self.in_channel = 64 # in_channel=ГҝТ»ёцlayerІгөЪТ»ёцҫн»эІгөДКдіцchannel/өЪТ»ёцҫн»эәЛөДКэБҝself.conv1 = nn.Conv2d(3, self.in_channel, kernel_size=7, stride=2, padding=3, bias=False)self.bn1 = nn.BatchNorm2d(self.in_channel)self.relu = nn.ReLU(inplace=True)self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1) # іШ»ҜД¬ИППтПВИЎХы# өЪ1ёцlayerөДРйПЯІРІоҪб№№Ц»РиТӘёДұдchannel,іӨЎўҝнІ»ұд ЛщТФstride=1self.layer1 = self._make_layer(block, blocks_num[0], channel=64, stride=1)# өЪ2/3/4ёцlayerөДРйПЯІРІоҪб№№І»ҪцТӘёДұдchannel»№ТӘҪ«іӨЎўҝнЛхРЎОӘФӯАҙөДТ»°л ЛщТФstride=2self.layer2 = self._make_layer(block, blocks_num[1], channel=128, stride=2)self.layer3 = self._make_layer(block, blocks_num[2], channel=256, stride=2)self.layer4 = self._make_layer(block, blocks_num[3], channel=512, stride=2)self.avgpool = nn.AdaptiveAvgPool2d((1, 1)) # AdaptiveAvgPool2d ЧФККУҰіШ»ҜІг output_size=(1, 1)self.fc = nn.Linear(512 * block.expansion, num_classes)# ҝӯГчіхКј»Ҝfor m in self.modules():if isinstance(m, nn.Conv2d):nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu')elif isinstance(m, (nn.BatchNorm2d, nn.GroupNorm)):nn.init.constant_(m.weight, 1)nn.init.constant_(m.bias, 0)def _make_layer(self, block, block_num, channel, stride=1):""": params: block=BasicBlock/Bottleneck 18/34УГBasicBlock 50/101/152УГBottleneck: params: block_num=өұЗ°layerЦРІРІоҪб№№өДёцКэ: params: channel=Гҝёцconvx_xЦРөЪТ»ёцҫн»эәЛөДКэБҝ ГҝТ»ёцlayerөДХвёцІОКэ¶јКЗ№М¶ЁөД: params: stride=Гҝёцconvx_xЦРөЪТ»ІгЦР3x3ҫн»эІгөДstride=Гҝёцconvx_xЦРdownsample(res)өДstrideresnet50/101/152 conv2_x=>s=1 conv3_x/conv4_x/conv5_x=>s=2"""downsample = None# in_channel:Гҝёцconvx_xЦРөЪТ»ІгөДөЪТ»ёцҫн»эәЛөДКэБҝ# channel*block.expansion:ГҝТ»ёцlayerЧоәуТ»ёцҫн»эәЛөДКэБҝ# res50/101/152өДconv2/3/4/5_xөДin_channel != channel * block.expansionУАФ¶іЙБўЈ¬ЛщТФөЪТ»ІгұШУРdownsampleЈЁРйПЯІРІоҪб№№Ј©# ө«КЗconv2_xөДөЪТ»ІгЦ»ёДұдchannelІ»ёДұдw/hЈЁs=1Ј©Ј¬¶шconv3_x/conv4_x/conv5_xөДөЪТ»ІгІ»ҪцёДұдchannel»№ёДұдw/h(s=2ПВІЙСщ)if stride != 1 or self.in_channel != channel * block.expansion:downsample = nn.Sequential(nn.Conv2d(self.in_channel, channel * block.expansion, kernel_size=1, stride=stride, bias=False),nn.BatchNorm2d(channel * block.expansion))layers = []# өЪТ»ІгЈЁә¬РйПЯІРІоҪб№№Ј©јУИлlayerslayers.append(block(self.in_channel, channel, stride=stride, downsample=downsample))# ҫӯ№эөЪТ»ІгәуchannelұдБЛself.in_channel = channel * block.expansion# res50/101/152өДconv2/3/4/5_xіэБЛөЪТ»ІгУРdownsampleЈЁРйПЯІРІоҪб№№Ј©Ј¬ЖдЛыЛщУРІг¶јКЗКөПЦІРІоҪб№№ЈЁөИІоУіЙдЈ©for _ in range(1, block_num):layers.append(block(self.in_channel, channel)) # channelФЪBottleneckұд»ҜЈә512->128->512return nn.Sequential(*layers)def forward(self, x):out = self.conv1(x)out = self.bn1(out)out = self.relu(out)out = self.maxpool(out)out = self.layer1(out)out = self.layer2(out)out = self.layer3(out)out = self.layer4(out)out = self.avgpool(out)out = torch.flatten(out, 1)out = self.fc(out)return outdef se_resnet18(num_classes=5):return SE_ResNet(SE_BasicBlock, [2, 2, 2, 2], num_classes=num_classes)def se_resnet34(num_classes=5):# ФӨСөБ·ИЁЦШ https://download.pytorch.org/models/resnet34-333f7ec4.pthreturn SE_ResNet(SE_BasicBlock, [3, 4, 6, 3], num_classes=num_classes)def se_resnet50(num_classes=5):# ФӨСөБ·ИЁЦШ https://download.pytorch.org/models/resnet50-19c8e357.pthreturn SE_ResNet(SE_Bottleneck, [3, 4, 6, 3], num_classes=num_classes)def se_resnet101(num_classes=5):# ФӨСөБ·ИЁЦШ https://download.pytorch.org/models/resnet101-5d3b4d8f.pthreturn SE_ResNet(SE_Bottleneck, [3, 4, 23, 3], num_classes=num_classes)def se_resnet152(num_classes=5):return SE_ResNet(SE_Bottleneck, [3, 8, 36, 3], num_classes=num_classes)if __name__ == '__main__':# ИЁЦШІвКФdevice = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")print(device)model = se_resnet50().to(device)print(model)summary(model, (3, 224, 224)) # params:26,033,221 Total Size (MB): 428.90ёцИЛКөСй
КэҫЭјҜІЙУГ»Ё·ЦАаЈ¬ИЎЖдЦР5АаЈ¬3700¶аХЕНјЖ¬Ј¬і¬ІОёъВЫОДІоІ»¶аЈ¬ДЈРНИЎSE2016ResNet50Ј¬SEResNet50әНResNet50¶ФұИ
batch-sizeЙиОӘ32Ј¬epochЙиОӘ50Ј¬КөСйЙиұёRTX3060 12GB
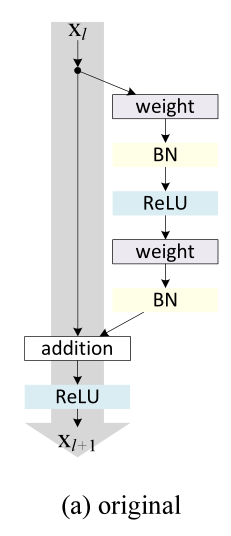
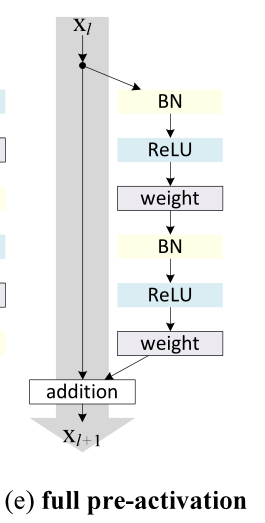
ТФЙПНј(a)ЦёөДКЗФӯКјөД2015ResNetөДҪб№№Ј¬Нј(e)ЦёөДКЗ2016ResNetҪб№№


ІОҝј
ЎҫВЫОДёҙПЦЎҝSENetЈЁ2019Ј©