文章目录
- 数据重塑图解—Pivot, Pivot-Table, Stack and Unstack
-
- 引言
- Pivot
-
- 常见错误
- Pivot Table
- Stack/Unstack
数据重塑图解—Pivot, Pivot-Table, Stack and Unstack
引言
Pandas是python中常用的数据分析软件库,它提供了DataFrames和Series的工具,这使得numpy和matplotlib可以更加便捷地读取转换数据。
数据重塑表示转换一个表格或者向量的结构,使其适合于进一步的分析。Pandas拥有一些其他软件不具备的重塑功能,这对初学者来说可能会比较棘手。
本文中我将举例说明Pandas中一些常用的重塑函数,并结合图表进行阐述。
Pivot
pivot函数用于创建一个新的派生表,该函数有三个参数:index, columns和values。你需要在原始表中指定这三个参数所对定的列名,接下来pivot函数会创建一个新的表格,其中行索引和列索引都是唯一标示值,表格中的数值由原始表中参数value对应的数据所表示。
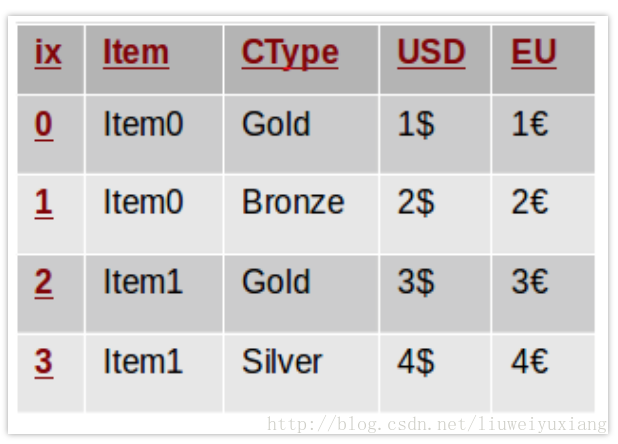
是不是感觉有点难以理解呢?看完下面这个例子你就明白了,假设给定下面这个表格:
其中 item 表示商品名称,USD 表示商品的美元价格,EU 表示欧元价格,CType 表示每个客户对应的类别。
下述代码片段用于创建DataFrame,需要注意的是本文中所有的代码片段均需要导入以下模块:
from collections import OrderedDict
from pandas import DataFrame
import pandas as pd
import numpy as np
table = OrderDict((
("Item",['Item0','Item0','Item1','Item1']),
("CType",['Gold','Bronze','Gold','Silver']),
("USD",['1$','2$','3$','4$']),
("EU",['1?','2?','3?','4?'])
))
d = DataFrame(table)
在这个表格中,我们很难观测到商品的美元价格在不同的客户中是如何变化的。此时我们倾向于重塑表格,使得所有的价格信息都按行排列:
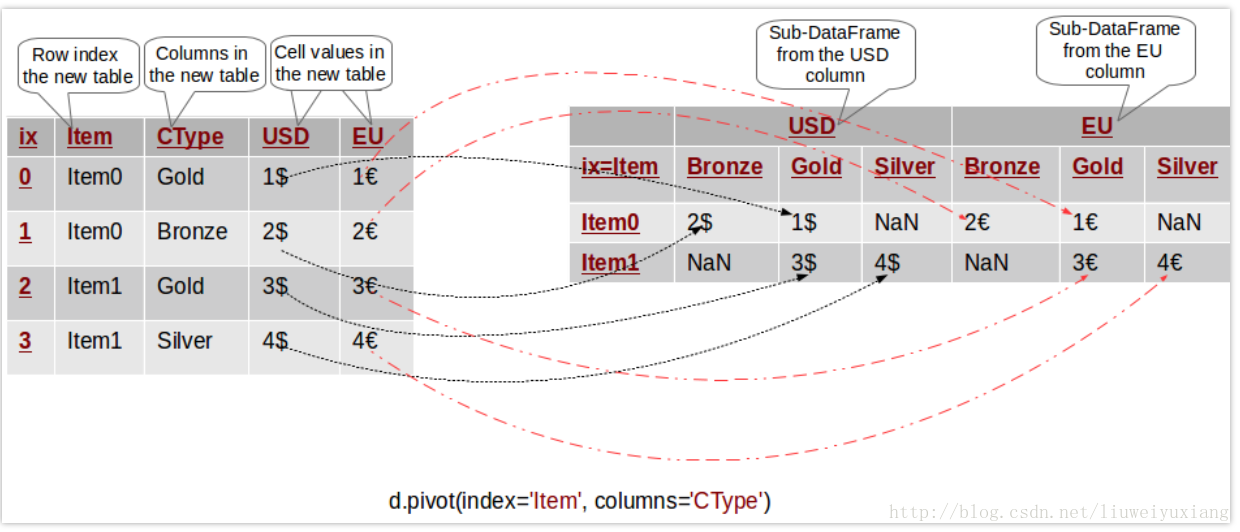
p = d.pivot(index='Item', columns='CType', values='USD')
上述命令创建了一个新的表格,其中列索引是 d.CType 中的唯一值,行索引是 d.Item 中的唯一值,表格中的数值由 d.USD 来填充。下图形象地展示了这个过程:
换句话说,原始表中的 USD 数据已经被转移到新表中,其中行列索引分别由 Item 和 CType 所表示,无法找到原始数据的用 NaN所表示。
下述代码介绍了如何分别从原始表和新表中查询数据:

# Original DataFrame: Access the USD cost of Item0 for Gold customers
print(d[(d.Item=='Item0') & (d.CType=='Gold')].USD.values)
# Pivoted DataFrame: Access the USD cost of Item0 for Gold customers
print(p[p.index=='Item0'].Gold.values)
需要注意的是,该数据透视表中没有包含欧元价格的任何信息。事实上,数据透视表是原始表格的简化版本,它只包含我们所关心的变量信息。
现在我们对上述案例进行拓展,我们想将每个商品的欧元价格信息也纳入数据透视表中(Pivoting By Multiple Columns)。这非常容易实现——我们只需将 values 参数删掉即可:
p = d.pivot(index='Item', columns='CType')
此时,Pandas会在新表格中创建一个分层列索引。你可以将分层索引想象成一个树形索引,每个行/列索引都由从最顶层的索引到底部索引的路径所组成。最顶层的索引由pivot函数中没有定义的参数所组成——比如本例中的 USD 和 EU,第二层索引表示对应列中的所有唯一值。下图形象地展示了该过程:
我们可以利用分层索引从原始表中过滤出某个变量的数据。比如p.USD将返回只包含 USD 数据的数据透视表,p.USD.Bronze将上述透视表中的第一列筛选出来。
# Original DataFrame: Access the USD cost of Item0 for Gold customers
print(d[(d.Item=='Item0')&(d.CType=='Gold')].USD.values)
# Pivoted DataFrame: p.USD gives a "sub-DataFrame" with the USD values only
print(p.USD[p.USD.index=='Item0'].Gold.values)
常见错误
从上文的描述中我们可以看出:pivot方法至少需要两个参数—— index 和 columns。那么如果原始数据集中存在重复条目时,重塑过程将会发生什么问题呢?pivot函数如何确定数据透视表中的数值呢?下图形象地展示了这个问题:
在这个案例中,原始数据集中存在重复条目,此时pivot函数无法确定数据透视表中的数值,它会返回一个错误信息:ValueError: Index contains duplicate entries, cannot reshape
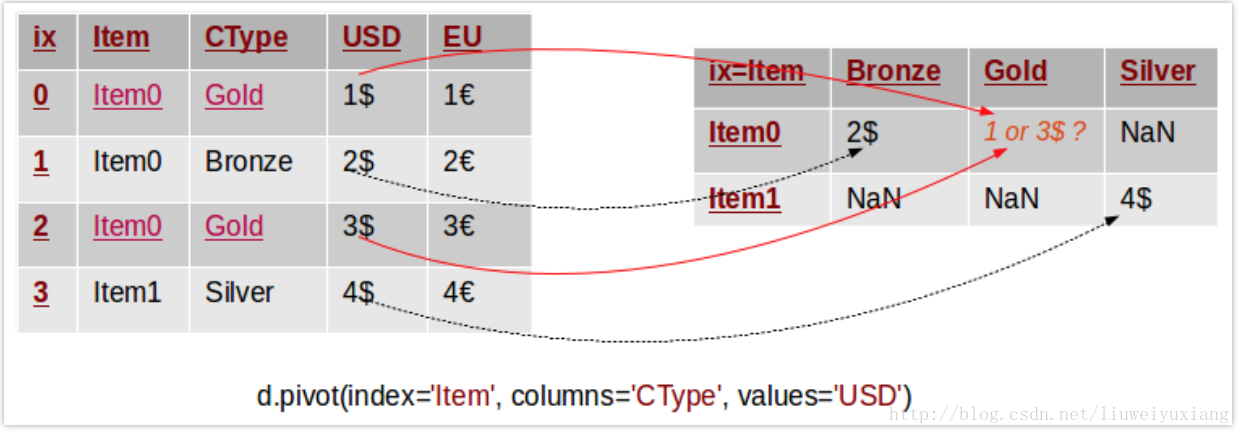
table = OrderDict((
("Item",['Item0','Item0','Item0','Item1']),
('CType',['Gold','Bronze','Gold','Silver']),
('USD',['1$','2$','3$','4$']),
('EU',['1?','2?','3?','4?'])
))
d = DataFrame(table)
p = d.pivot(index='Item', columns='CType', values='USD')
因此,我们在调用pivot方法前需要保证数据集中不存在重复条目,否则我们需要调用另外一个方法——pivot_table。
Pivot Table
pivot_table方法可以用来解决上述问题,与pivot相比,该方法可以汇总多个重复条目的数据。换句话说,在前面的例子中,我们可以用均值、中位数或者其他汇总函数来计算重复条目的数值。下图形象地展示了这个过程:
注意,在这个例子中,我们移除了数据集中的美元和欧元符号。原始数据集中存在两行重复条目,我们利用样本均值来填充数据透视表中的数据。pivot_table方法需要传递一个新的参数 aggfunc,该参数用于指明转换时所需的汇总函数。
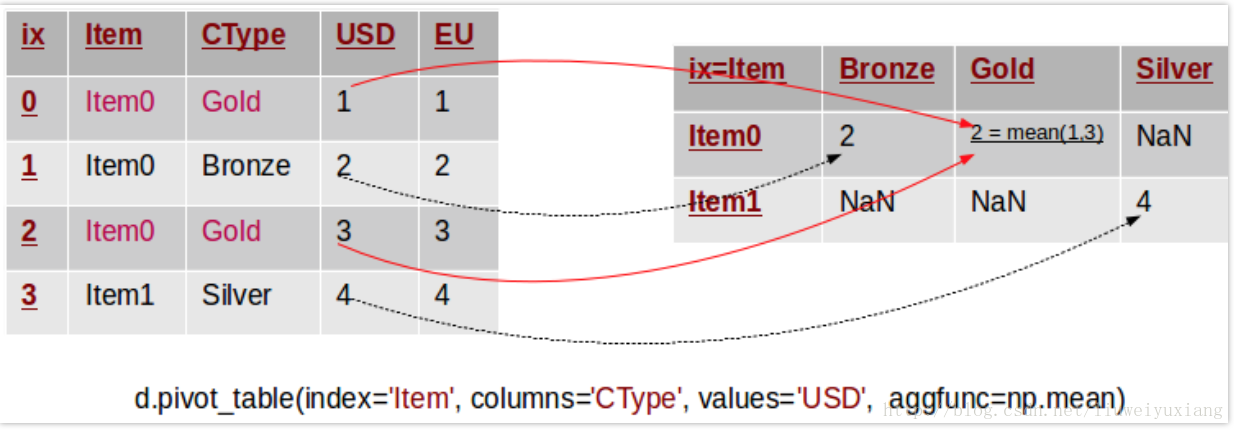
table = OrderDict((
('Item',['Item0','Item0','Item0','Item1']),
('CType',['Gold','Bronze','Gold','Silver']),
('USD',[1,2,3,4]),
('EU',[1.1,2.2,3.3,4.4])
))
d = DataFrame(table)
p=d.pivot_table(index='Item',columns='CType',values='USD', aggfunc=np.mean)
从本质上来说,pivot_table方法是pivot的通用版,该方法可以汇总重复条目的数据。
Stack/Unstack
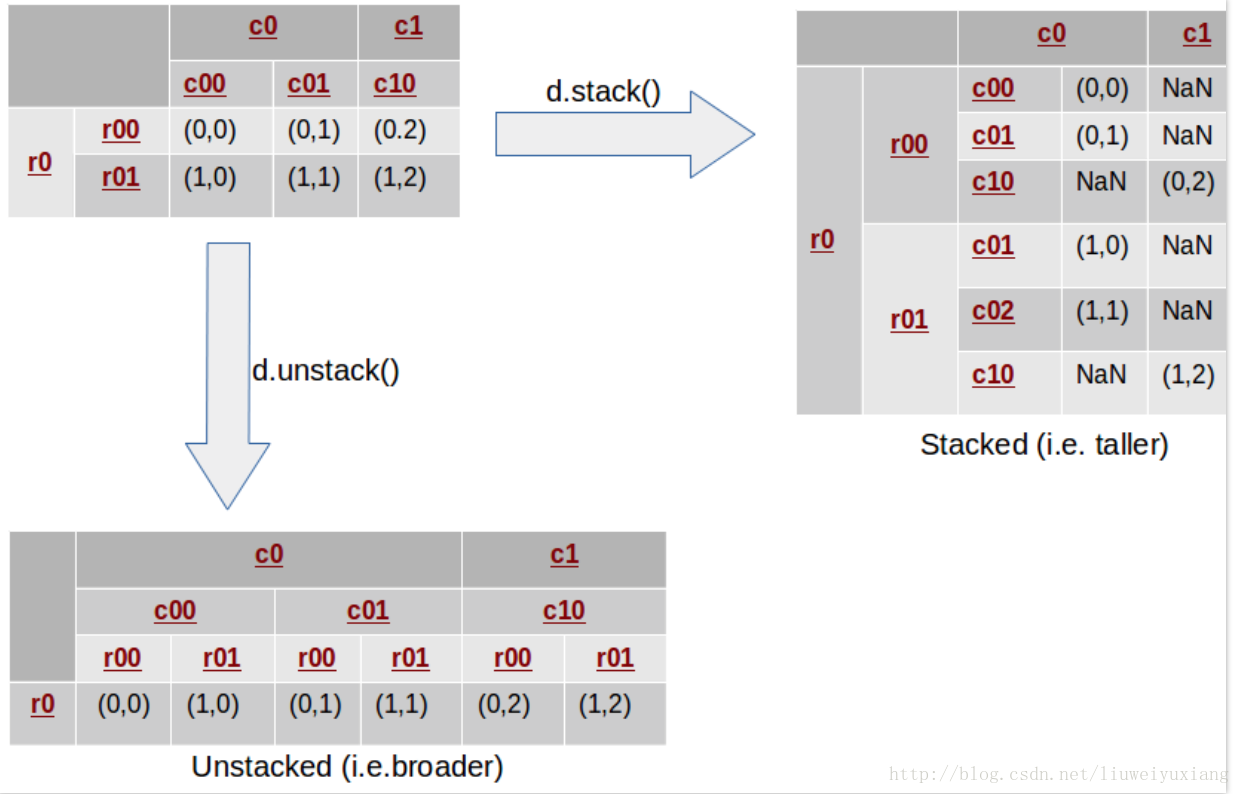
实际上,轴向旋转(pivot)运算是堆叠(stack)过程的特例。首先假设原始数据集中的行列索引中均为层次索引。stack 过程表示将数据集的列旋转为行,同理 unstack 过程表示将数据的行旋转为列。下图形象地展示了该过程:
在这个例子中,我们看到原始数据集中的行列索引都由二级分层索引组成。堆叠过程主要是将最内层的列索引转换成最内层的行索引,然后再重新安排单元格中的数据。相反地,unstack 过程是讲最内层的行索引移到最内层的列索引中。
因此,我们可以发现 stack 使得数据集变得更长,unstack 使得数据集变得更宽。
# Row Multi-Index
row_idx_arr = list(zip(['r0','r0'],['r-00','r-01']))
row_idx = pd.MultiIndex.from_tuples(row_idx_arr)
# Column Multi-Index
col_idx_arr = lis(zip(['c0','c0','c1'], ['c-00','c-01','c-10']))
col_idx = pd.MultiIndex.from_tuples(col_idx_arr)
# Create the DataFrame
d = DataFrame(np.arange(6).reshape(2,3),index=row_idx, columns=col_idx)
d = d.applymap(lambda x: (x // 3, x % 3))
# Stack/Unstack
s = d.stack()
u = d.unstack()
事实上,Pandas允许我们利用 stack/unstack 处理任一等级的索引。因此虽然默认设定处理最内层的索引,但是在上述的例子中,我们也可以处理最外层的索引。
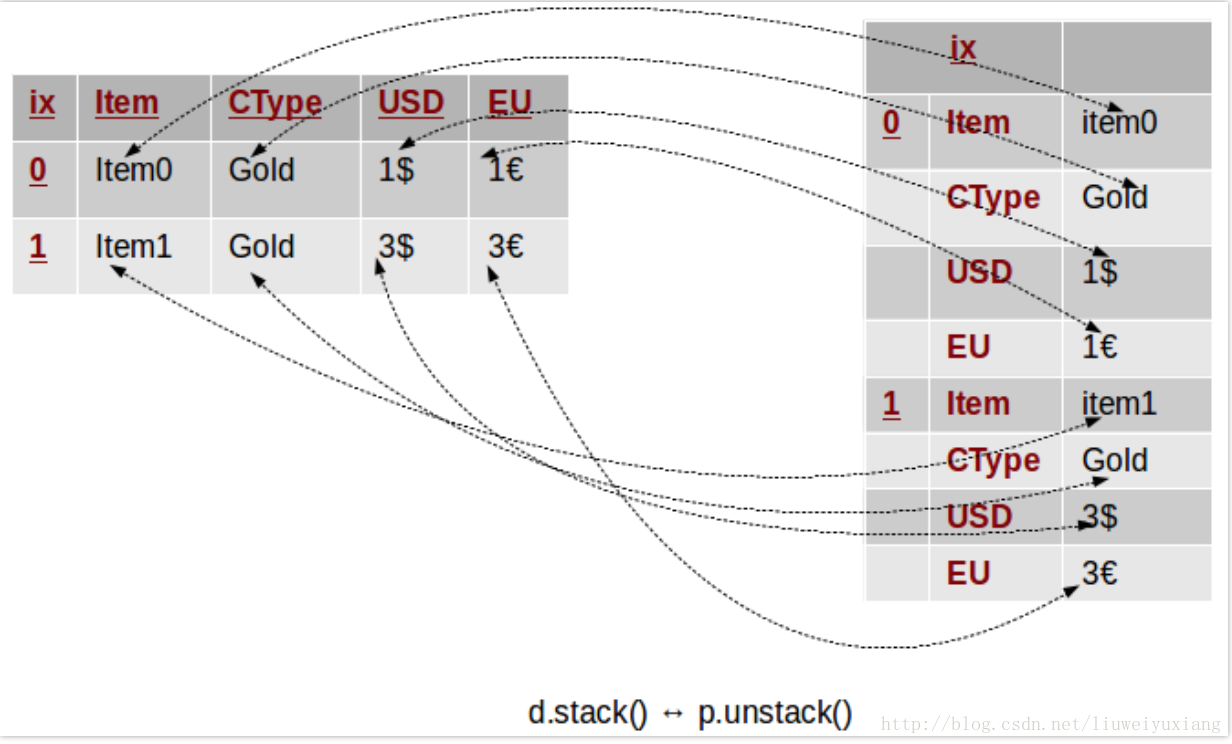
Stacking 和 Unstacking 也可以运用到单层索引的数据集中,如下图所示:
参考文献
1 Pandas中的数据重塑(reshape)功能
2 Reshaping in Pandas - Pivot, Pivot-Table, Stack and Unstack explained with Pictures
3. python pandas stack和unstack函数 stack和unstack这篇的讲解不错