本篇文章为scrapy-redis的实例应用,源码已经上传到github:
https://github.com/Voccoo/NewSpider
使用到了:
python 3.x
redis
scrapy-redis
pymysql
Redis-Desktop-Manager(redis可视化工具)
工具安装问题网上有许多,我就不一一赘述了。
这个实例主要是爬取腾讯滚动新闻模块的数据,做了去重,自增量,可以分布爬取,定时关闭爬虫;一键启动,每半个小时自动获取一次数据。(若这些还不满足,可以继续在run方法中新构一个redis-key,保存在redis中,然后做一个slave接收这个key里的url)
如果想做一个时实咨询的app或者网站的话,拿这个实例直接修改下就OK了。
内容截图:
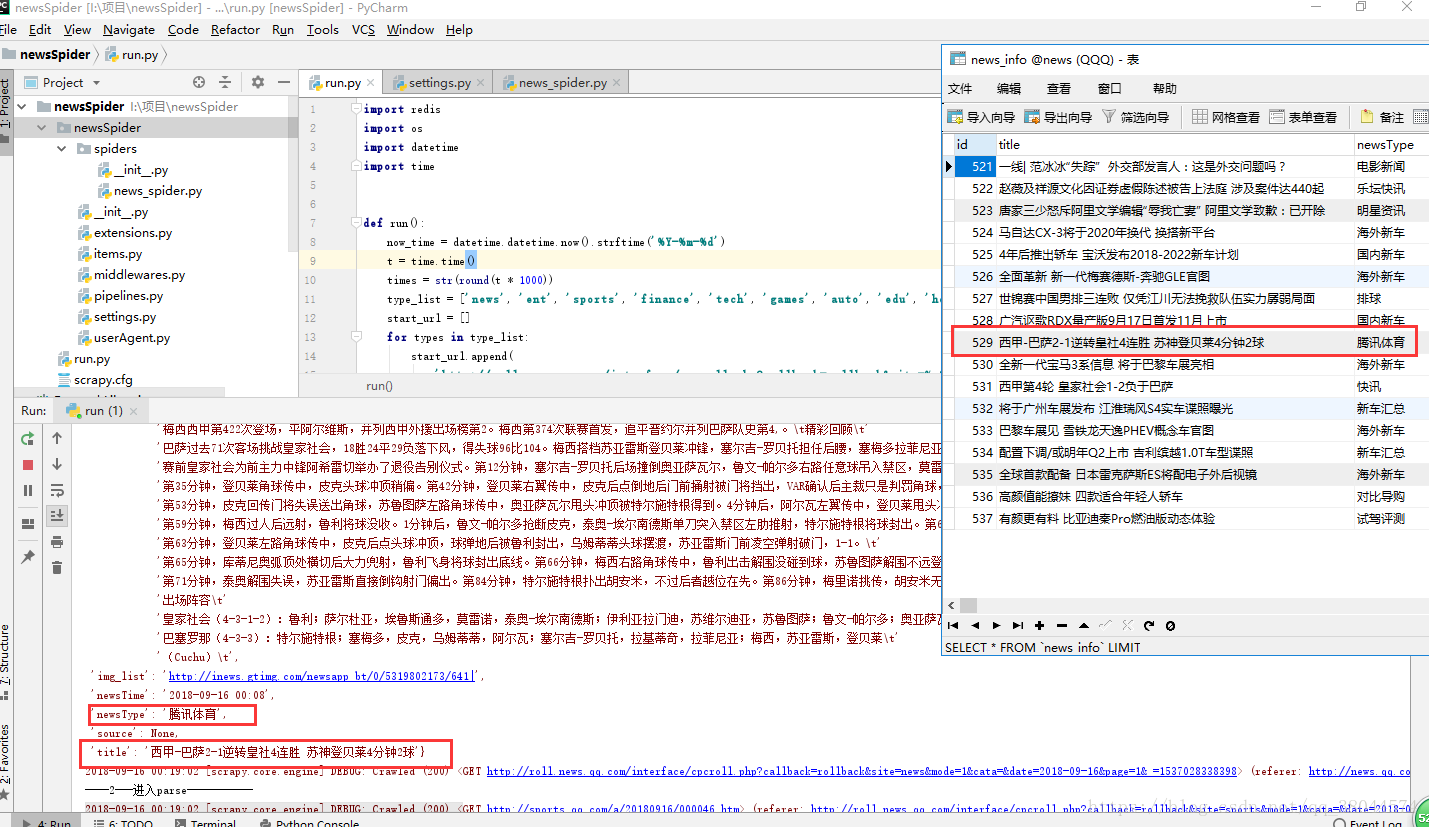
项目结构:
setting
# -*- coding: utf-8 -*-import random
from newsSpider.userAgent import USER_AGENT_LIST
BOT_NAME = 'newsSpider'
SPIDER_MODULES = ['newsSpider.spiders']
NEWSPIDER_MODULE = 'newsSpider.spiders'
ROBOTSTXT_OBEY = FalseCONCURRENT_REQUESTS = 30
DOWNLOAD_DELAY = 0.25
#设置访问头
DEFAULT_REQUEST_HEADERS = {'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8','Accept-Encoding': 'gzip, deflate, br','Accept-Language': 'zh-CN,zh;q=0.9','Referer': 'http://news.qq.com/articleList/rolls/','Upgrade-Insecure-Requests': '1','User_Agent': random.choice(USER_AGENT_LIST)
}
#拓展插件,主要是防止空跑问题
#详细请看:https://my.oschina.net/2devil/blog/1631116#或者:https://blog.csdn.net/xc_zhou/article/details/80907047
EXTENSIONS = {'newsSpider.extensions.RedisSpiderSmartIdleClosedExensions': 500,
}ITEM_PIPELINES = {'newsSpider.pipelines.NewsspiderPipeline': 300,#这个是新建项目自带的'scrapy_redis.pipelines.RedisPipeline': 400#这个是需要加上的,通过scrapy-redis自带的pipelines将item存入redis}
#启用scrapy-redis自带的去重
DUPEFILTER_CLASS = "scrapy_redis.dupefilter.RFPDupeFilter"
##启用调度器
SCHEDULER = "scrapy_redis.scheduler.Scheduler"
#是否在关闭spider的时候保存记录,保存(TRUE),不保存(False)
SCHEDULER_PERSIST = True
#使用优先级调度请求队列 (默认使用)
SCHEDULER_QUEUE_CLASS = 'scrapy_redis.queue.SpiderPriorityQueue'
#REDIS_URL = None #一般可不带
#指定master的redis地址端口,有密码的加上密码
REDIS_HOST = '127.0.0.1'
REDIS_PORT = '6379'
REDIS_PARAMS = {'password': '123456',
}#SCHEDULER_QUEUE_KEY = '%(spider)s:requests' # 调度器中请求存放在redis中的key
#SCHEDULER_SERIALIZER = "scrapy_redis.picklecompat" # 对保存到redis中的数据进行序列化,默认使用pickle#SCHEDULER_FLUSH_ON_START = False # 是否在开始之前清空 调度器和去重记录,True=清空,False=不清空
# SCHEDULER_IDLE_BEFORE_CLOSE = 10 # 去调度器中获取数据时,如果为空,最多等待时间(最后没数据,未获取到)。
#SCHEDULER_DUPEFILTER_KEY = '%(spider)s:dupefilter' # 去重规则,在redis中保存时对应的key chouti:dupefilter
#SCHEDULER_DUPEFILTER_CLASS = 'scrapy_redis.dupefilter.RFPDupeFilter' # 去重规则对应处理的类
#DUPEFILTER_DEBUG = False
#上述的扩展类需要的
MYEXT_ENABLED = True # 开启扩展
IDLE_NUMBER = 10 # 配置空闲持续时间单位为 10个 ,一个时间单位为5s#如果为True,则使用redis的'spop'进行操作。
#因为本次请求每一次带上的都是时间戳,所以就用了lpush
#如果需要避免起始网址列表出现重复,这个选项非常有用。开启此选项urls必须通过sadd添加,否则会出现类型错误。
#REDIS_START_URLS_AS_SET = Truespider:
着重讲下这个,本爬虫其实是slave,只有一个它的话,其实就是个很小的爬虫,但是如果有n个就是超级爬虫系统了。
本次重点在于:这个结构其实我是半年前用简单爬虫就完成的了。后来想完善,变成分布式爬虫,可以多机联合,使用到了scrapy-redis。想着是吧子级的url存入到redis中,然后所有的slave获取url再进行爬取。 这个逻辑用在一开始简单爬虫的时候是对的。但如果用在分布式爬虫上,其实错了。按照一开始的逻辑,就会出现无法去重的问题,和reques与dupefilter也就是这两个东西不会再redis中出现。
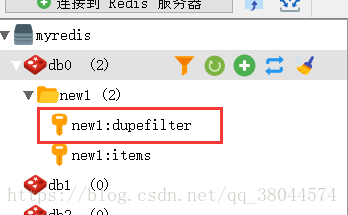
我这个request已经爬取完了,所以不会显示
我就因为这个去重问题纠结了二十多个小时。因为不解决这个问题,这个爬虫就是有错误的。后来经过百度二十多个小时才纠结出来这个结果。
request其实就是从master中接收到的初始url后,不管是网页还是json数据,解析出来你想要的url后,再次发起请求的多个地址,而指纹记录(dupefilter)也是记录的你这些请求的地址。一定要注意!!!
# -*- coding: utf-8 -*-
import scrapy
from scrapy_redis.spiders import RedisSpider
from newsSpider.userAgent import USER_AGENT_LIST as userAgent_list
import json, time, random
from newsSpider.items import NewsspiderItem as nsItem#如果你是一个需要看到分布是爬虫的人员,这个逻辑内容就不需要我解释了吧?
class NewsSpiderSpider(RedisSpider): # scrapy.Spidername = 'new1'allowed_domains = ['qq.com']redis_key = 'new1s:start_urls'def parse(self, response):if response.body_as_unicode() != 'Access denied':# print('----1---进入parse-----------')# print(response.body_as_unicode())#item = newsItem()data = response.body_as_unicode()data_json = json.loads(data[9:len(data) - 1])user_agent = random.choice(userAgent_list)headers = {'Upgrade-Insecure-Requests': '1','User-Agent': user_agent}if data_json['response']['code'] == '0':for i in data_json['data']['article_info']:url = i['url']# item['url'] = urlprint('子级url', url)yield scrapy.Request(url=url, callback=self.chil_url_content, headers=headers)else:print('该url今日没有值:', response.url)else:print('------拒绝连接-------')#这个页面解析还不够完善,因为涉及到9个网站模板,我只是总结了一下大概的规律做的页面解析,更准确的可以自己修改下def chil_url_content(self, response):print('----2-----------')item = nsItem()title = response.css('.qq_article div[class="hd"] h1::text').extract_first()newsType = response.css('div[class="a_Info"] span:nth-child(1) a::text').extract_first()source = response.css('.a_source::text').extract_first()newsTime = response.css('.a_time::text').extract_first()content_list = response.css('.Cnt-Main-Article-QQ p[style="TEXT-INDENT:2em"]::text').extract()content = ''for i in content_list:content += i + '\t'img_url_list = response.css('.Cnt-Main-Article-QQ img::attr(src)').extract()img_list = ''for i in img_url_list:img_list += 'http:' + i + '|'item['title'] = titleitem['newsType'] = newsTypeitem['source'] = sourceitem['newsTime'] = newsTimeitem['content'] = contentitem['img_list'] = img_listyield item
Pipeline:
内容很简单,我就不介绍了
# -*- coding: utf-8 -*-# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://doc.scrapy.org/en/latest/topics/item-pipeline.html
import redis
from newsSpider.items import NewsUrlSpiderItem as nuItem
from newsSpider.items import NewsspiderItem as nItem
import time
import pymysqlclass NewsspiderPipeline(object):comments = []def open_spider(self, spider):self.conn = pymysql.connect(host="localhost", user="root", passwd="Cs123456.", db="news", charset="utf8")self.cursor = self.conn.cursor()def process_item(self, item, spider):if isinstance(item, nItem):self.comments.append([item['title'], item['newsType'], item['source'], item['newsTime'], item['content'], item['img_list']])if len(self.comments) == 1:self.insert_to_sql(self.comments)# 清空缓冲区self.comments.clear()elif isinstance(item, nuItem):print('----====写入子级url===-----')r = redis.StrictRedis(host='127.0.0.1', port=6379)r.lpush('new2s:start_urls', item['url'])print('------结束-------')r.connection_pool.disconnect()return itemdef close_spider(self, spider):# print( "closing spider,last commit", len(self.comments))self.insert_to_sql(self.comments)self.conn.commit()self.cursor.close()self.conn.close()def insert_to_sql(self, data):try:sql = "insert into news_info (title,newsType,source,newsTime,content,img_list) values(%s, %s,%s,%s,%s,%s)"# print(data)self.cursor.executemany(sql, data)self.conn.commit()except:print('数据插入有误。。')self.conn.rollback()
item:
# -*- coding: utf-8 -*-import scrapyclass NewsspiderItem(scrapy.Item):# define the fields for your item here like:# name = scrapy.Field()title = scrapy.Field() #标题newsType = scrapy.Field()#类型source = scrapy.Field()#来源newsTime = scrapy.Field()#时间content = scrapy.Field()#内容img_list = scrapy.Field()#图片地址userAgent:
USER_AGENT_LIST = ["Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/22.0.1207.1 Safari/537.1""Mozilla/5.0 (X11; CrOS i686 2268.111.0) AppleWebKit/536.11 (KHTML, like Gecko) Chrome/20.0.1132.57 Safari/536.11","Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.6 (KHTML, like Gecko) Chrome/20.0.1092.0 Safari/536.6","Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.6 (KHTML, like Gecko) Chrome/20.0.1090.0 Safari/536.6","Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/19.77.34.5 Safari/537.1","Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/536.5 (KHTML, like Gecko) Chrome/19.0.1084.9 Safari/536.5","Mozilla/5.0 (Windows NT 6.0) AppleWebKit/536.5 (KHTML, like Gecko) Chrome/19.0.1084.36 Safari/536.5","Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3","Mozilla/5.0 (Windows NT 5.1) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3","Mozilla/5.0 (Macintosh; Intel Mac OS X 10_8_0) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3","Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1062.0 Safari/536.3","Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1062.0 Safari/536.3","Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3","Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3","Mozilla/5.0 (Windows NT 6.1) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3","Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.0 Safari/536.3","Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/535.24 (KHTML, like Gecko) Chrome/19.0.1055.1 Safari/535.24","Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/535.24 (KHTML, like Gecko) Chrome/19.0.1055.1 Safari/535.24"
]run:
import redis
import os
import datetime
import timedef run():
#----------制造url请求参数的-------------now_time = datetime.datetime.now().strftime('%Y-%m-%d')t = time.time()times = str(round(t * 1000))type_list = ['news', 'ent', 'sports', 'finance', 'tech', 'games', 'auto', 'edu', 'house']start_url = []for types in type_list:start_url.append('http://roll.news.qq.com/interface/cpcroll.php?callback=rollback&site=%s&mode=1&cata=&date=%s&page=1&_=%s' % (types, now_time, times))#-------------------------------------#连接上master的redisr = redis.StrictRedis(host='127.0.0.1', port=6379, password='123456')#r.delete('new1s:start_urls')#循环添加#result为lpush添加的结果,返回0或1。0为不成功,1为成功for url in start_url:result=r.lpush('new1s:start_urls', url)#result = r.smembers('redisspider:start_url')if result is 1:print('加入start_urls成功')#关闭连接r.connection_pool.disconnect()#每半小时调用一次
if __name__ == '__main__':while True:run()os.system("scrapy crawl new1")time.sleep(1800)