先搭建Hadoop伪分布: Ubuntu + Hadoop2.7.3伪分布搭建
注:以下所有以10.13.7.x 的IP地址均为桥接IP,请先配置各虚拟机的IP地址,并确保能够互Ping,不一定与博主相同,也可以是192.168.x.x,只要能够互ping就OK。
为了省去配置IP的麻烦,写了一篇利用NAT模式自动获取IP的博客:https://blog.csdn.net/qq_38038143/article/details/84592369
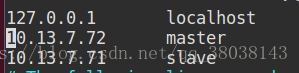
1.修改/etc/hosts文件,IP映射
内容如下:
注:10.13.7.72为master节点IP,10.13.7.71为slave节点IP。(根据自己的IP地址设置)

2.修改master配置文件
修改slaves,内容如下:

slave
修改hdfs-site.xml,内容如下:

<configuration><property><name>dfs.replication</name><value>1</value></property><property><name>dfs.permissions</name><value>false</value></property><property><name>dfs.namenode.name.dir</name><value>file:/usr/local/hadoop/dfs/name</value></property><property><name>dfs.datanode.data.dir</name><value>file:/usr/local/hadoop/dfs/data</value></property><property><name>dfs.namenode.datanode.registration.ip-hostname-check</name><value>false</value></property>
</configuration>3.复制master节点
在VirtualBox中复制master节点:
右键master,选择复制:
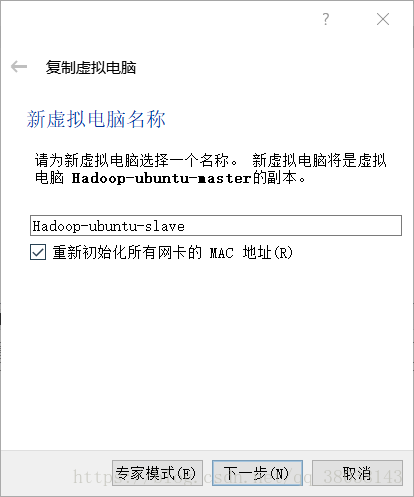
注:复制后需要修改slave节点的桥接IP地址,确保master与slave能够互相ping通。
4.配置slave节点
配置主机名,修改后重启Ubuntu:

5.节点之间免密登录
在master节点执行:
ssh-copy-id -i ~/.ssh/id_rsa.pub slave
测试:
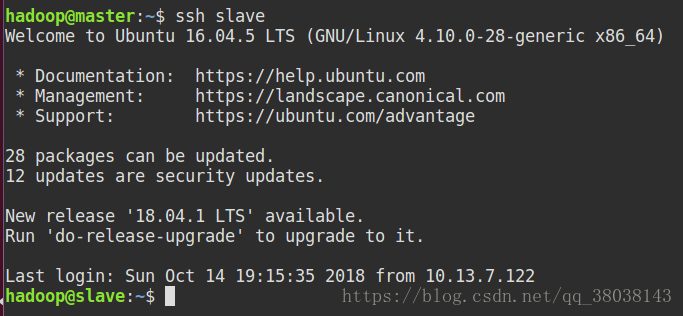
在slave节点执行:
ssh-copy-id -i ~/.ssh/id_rsa.pub master
测试:
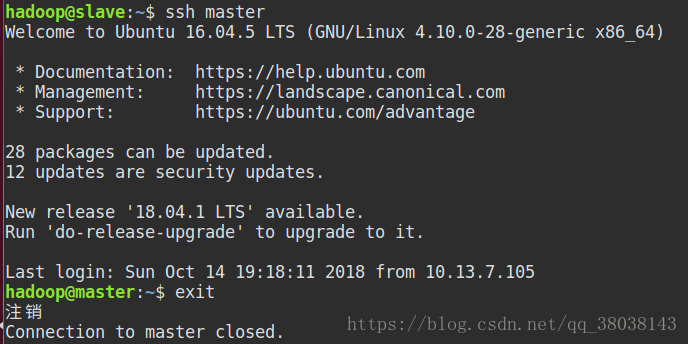
注: 执行 exit 退出。
4.启动集群
在 master 和 slave 节点执行 1和 2:
- 删除已有的 dfs tmp目录和logs日志。
rm -rf dfs tmp logs/*
- 新建 dfs tmp目录:
mkdir -p dfs/{name,data} tmp
格式化master节点(只需要格式化master,注:每次只能格式化一次,若还需第二次格式化则先删除,后创建dfs 和 tmp目录):
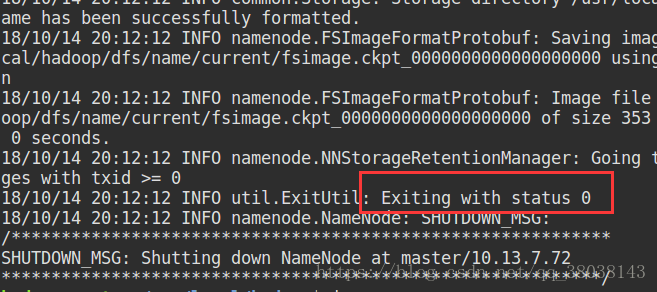
hdfs namenode -format
注:Exiting with status 0则成功, 1则失败。
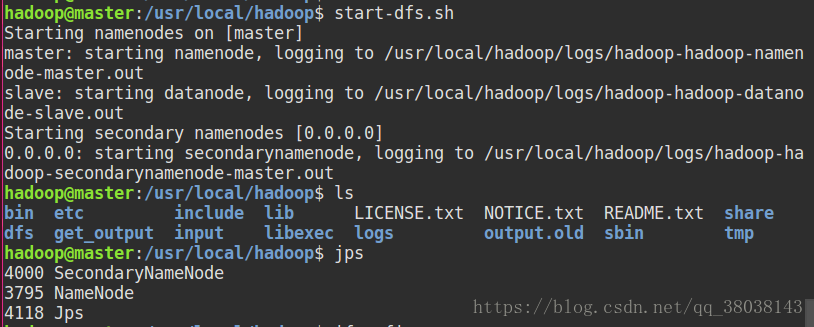
在master执行命令:start-dfs.sh
在slave节点执行:jps

在master执行命令:start-yarn.sh
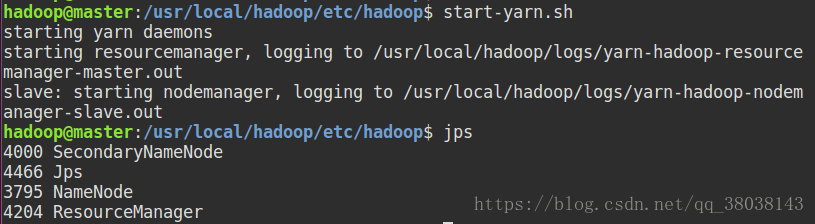
在slave节点执行:jps
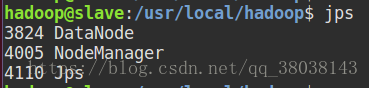
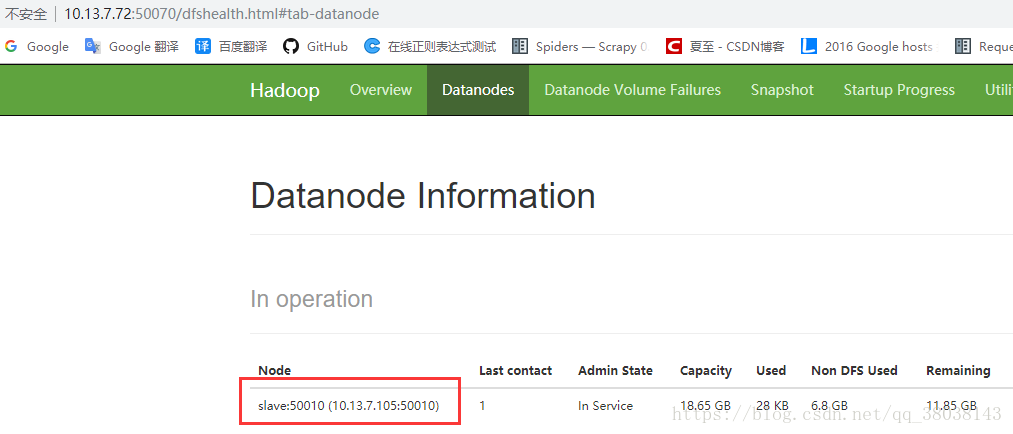
浏览器查看master节点IP + 端口:10.13.7.72:50070,可得到slave节点即搭建成功: