下载
Hadoop-2.7.3 JDK-1.8.152网盘下载:
链接:https://pan.baidu.com/s/1WxOaetwJ49fsouZ01xejlw
提取码:ihb5
1.在virtualbox上设置共享目录
将 JDK 和 hadoop 压缩包上传到Ubuntu:
参考链接:https://blog.csdn.net/qq_38038143/article/details/83017877

2.JDK安装
- 在 /usr/local/ 下创建目录 java,将 JDK 解压到 java 目录,执行命令:
sudo tar -zxvf /usr/local/lib/jdk-8u152-linux-x64.tar.gz -C /usr/local/java/
查看 java目录:

- 配置环境变量:
执行命令:
sudo vim /etc/profile
在文件末尾添加以下内容:
JAVA_HOME=/usr/local/java/jdk1.8.0_152
CLASSPATH=$JAVA_HOME/lib/
PATH=$PATH:$JAVA_HOME/bin
export JAVA_HOME CLASSPATH PATH
使配置生效:
source /etc/profile
- 查看JDK配置是否成功:
JDK安装完成。

3.hadoop安装
3.1. 解压hadoop
执行命令,分别为:解压hadoop、修改目录名称、修改目录拥有者(根据自己linux用户)
sudo tar -zxvf /usr/local/lib/hadoop-2.7.3.tar.gz -C /usr/local/
sudo mv /usr/local/hadoop-2.7.3 /usr/local/hadoop
sudo chown hadoop /usr/local/hadoop
3.2. 配置 JDK 路径
进入目录:

修改文件:hadoop-env.sh
将第25行的 export JAVA_HOME=${JAVA_HOME} 修改为:

3.3. 配置 Hadoop 环境变量:
在文件末尾添加,修改文件:
vim ~/.bashrc
export JAVA_HOME=/usr/local/java/jdk1.8.0_152
export HADOOP_HOME=/usr/local/hadoop
export HADOOP_INSTALL=$HADOOP_HOME
export HADOOP_MAPRED_HOME=$HADOOP_HOME
export HADOOP_COMMON_HOME=$HADOOP_HOME
export HADOOP_HDFS_HOME=$HADOOP_HOME
export YARN_HOME=$HADOOP_HOME
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export PATH=$PATH:$HADOOP_HOME/sbin:$HADOOP_HOME/bin
使生效:
source ~/.bashrc
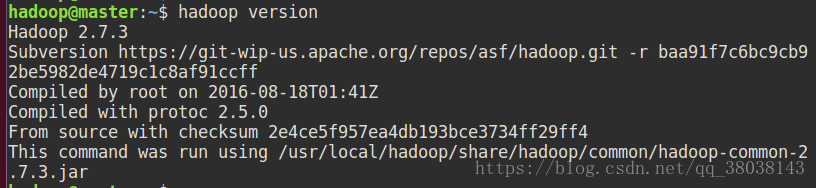
3.4. 查看Hadoop版本
Hadoop安装成功。
3.5. Hadoop单机实例运行:
进入目录:

创建目录,并将配置文件作为输入文件:
mkdir ./input
cp ./etc/hadoop/*.xml ./input
执行运行命令:
bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-*.jar grep input/ ./output 'dfs[a-z.]+'
查看输出结果:
单机模式运行实例成功。

4.Hadoop伪分布
4.1 配置IP映射:
修改文件:sudo vim /etc/hosts
在文件中添加:(master 为主机名,根据自身linux设置)
127.0.0.1 master
重启网路:
sudo /etc/init.d/networking restart
4.2 免密登录:
安装ssh:
sudo apt-get install openssh-server
生成 ~/.ssh目录:
ssh master
# 输入密码登录后,执行exit退出
exit
执行命令,生成公钥、密钥:
ssh-keygen -t rsa #一直回车
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
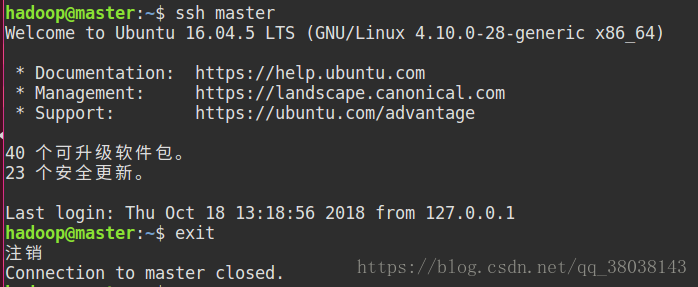
再次执行登录命令:
ssh master
若不再使用命令即可登录,即免密登录成功。
4.3 修改Hadoop配置文件:
注:以下配置文件中的master是根据4.1 IP映射配置的127.0.0.1,将下列所有的master根据4.1中写的主机名修正。
4.3.1 core-site.xml
<configuration><property><name>hadoop.tmp.dir</name><value>file:/usr/local/hadoop/tmp</value><description>注释</description></property><property><name>fs.defaultFS</name><value>hdfs://master:9000</value></property>
</configuration>
4.3.2 hdfs-site.xml
<configuration><property><name>dfs.replication</name><value>1</value></property><property><name>dfs.permissions</name><value>false</value></property><property><name>dfs.namenode.name.dir</name><value>file:/usr/local/hadoop/dfs/name</value></property><property><name>dfs.datanode.data.dir</name><value>file:/usr/local/hadoop/dfs/data</value></property>
</configuration>
4.3.3 mapred-site.xml
由于配置文件只存在mapred-site.xml.template,所以先复制mapred-site.xml:
cp mapred-site.xml.template mapred-site.xml
在mapted-site.xml中添加:
<configuration><property><name>mapreduce.framework.name</name><value>yarn</value></property><property><name>mapreduce.jobtracker.address</name><value>master:9001</value></property>
</configuration>
4.3.4 yarn-site.xml
<configuration><!-- Site specific YARN configuration properties --><property><name>yarn.nodemanager.aux-services</name><value>mapreduce_shuffle</value></property><property><name>yarn.resourcemanager.webapp.address</name><value>master:8099</value></property></configuration>
4.4 启动Hadoop
4.4.1 创建目录:
cd /usr/local/hadoop/
mkdir -p dfs/{name,data} tmp
4.4.2 格式化
hdfs namenode -format
结果:
出现 0 则成功,1则失败。
注:若失败,检查上述配置是否错误,修正后,需要删除 dfs、tmp目录,然后新建dfs、tmp目录,再执行格式化命令。

4.4.3 启动HDFS
start-dfs.sh
jps 查询:
浏览器访问:localhost:50070
4.4.4 启动Yarn



start-yarn.sh
jps 查询:


伪分布实例测试:

执行命令:
cd /usr/local/hadoop/
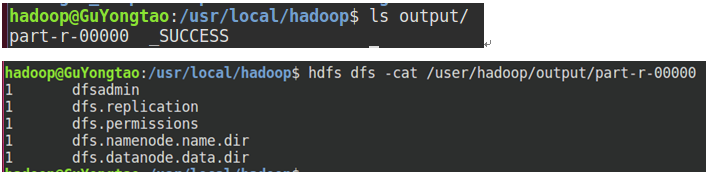
hadoop jar ./share/hadoop/mapreduce/hadoop-mapreduce-examples-*.jar grep input output 'dfs[a-z.]+'

查看输出结果:
浏览器访问:master:8099/cluster
伪分布安装成功。
