前言
键值对(pair RDD)是Spark的一部分,与普通RDD具有相同的特性,却又拥有不同于普通RDD的一些特性和操作。
简单来pair RDD就是以key-value形式的RDD。
1 创建pair RDD
根据文本内容,以第一个单词作为键为例:

map()函数需要设置key-value参数,如该例中:key=x.split(" ")[0], value=x。
2 pair RDD的转换操作
pair RDD可以使用所有标准RDD上的可用的转化操作。但是由于pair RDD包含二元组,所以传递的函数操作的是二元组,而不是独立的元素。
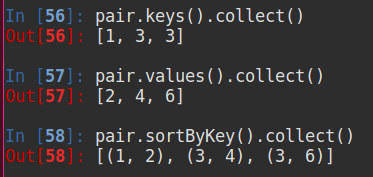
以下测试数据均为键值对列表 [(1,2),(3,4),(3,6)]
2.1 reduceByKey
合并具有相同键的值

2.2 groupByKey
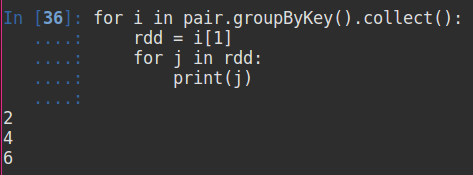
对具有相同键的值进行分组

如上图所示value值并没有直接显示,而显示多个值组成的迭代器,如果需要显示出来,如下:
2.3 mapValues
对RDD中的每个值应用一个函数,并不改变键

2.4 flatMapValues
对pair RDD中的每个值应用一个返回迭代器的函数,然后对返回的每个元素都生成一个对应原键的键值对记录

更多如:
以上操作为单个RDD操作,下面为两个RDD之间的操作:
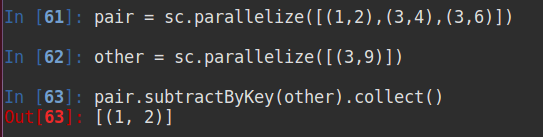
以下RDD为:pair=[(1,2),(3,4),(3,6)],other=[(3,9)]
2.5 subtractByKey
删掉 pair 中与 other 相同键的元素
2.6 join
两个RDD进行内连接

更多如左外连接、右外连接、和将具有相同键的分组到一起:

其中,None表示值不存在。
2.7 filter
筛选 value 值长度大于50的元素

3 聚合操作
3.1 reduceByKey
- 使用 reduceByKey 进行平均值计算
1)分步计算:

其中,rdd.map(lambda x: (x[0], x[1][0] / x[1][1])) 可以将 x 看做一个元素,即 x = (‘spark’, (13, 2)),所以 x[0] = ‘spark’,x[1] = (13, 2),x[1][0] = 13,x[1][1] = 2。
2)一步计算:

- 使用reduceByKey 进行单词统计

更加简单的版本:

只不过两个版本生成结果的数据格式略有不同。
3.2 combineByKey
求各个键对应的平均值

combineByKey() 有三个参数。
combineByKey原理简述:
combineByKey处理数据时,会遍历分区中所有的元素,所以某个元素要么是第一次出现,要么是该值的键以前出现过。
如果这是一个新的元素,combineByKey 会使用createCombiner()的函数创建那个键对应的累加器的初始值。注:该过程会发生在每个分区,而不是整个RDD过程只出现一次。
如果这是一个之前已经遇到的键,它会使用mergeValue()将该键对应的累加器的值与新值合并(求和)。
由于每个分区都是独立处理的,因此对于同一个键可以有多个累加器。如果有两个或以上分区都有同一个键对应的累加器,就需要用户提供mergeCombiners()方法将各个分区的结果进行合并。
因此,根据上述原理可以推断出combineByKey()的三个参数与上述过程一 一对应。(该推测仅为博主个人观点,如有不同欢迎指正)
即:
createCombiner() == lambda x: (x, 1)
mergeValue() == lambda x, y: (x[0]+y, x[1]+1)
mergeCombiners() == lambda x, y: (x[0]+y[0], x[1]+y[1])
并行度调优:
每个RDD都有固定数目的分区,分区数决定了RDD执行操作时的并行度。
在执行聚合或分组操作时,可以要求Spark使用给定的分区数。Spark始终阐释根据集群的大小推断出一个有意义的默认值,但是有时候你可能要对并行度进行调优来获得更好的性能表现。
上述的大部分操作符都能接收第二个参数,这个参数用来指定分组结果或聚合结果的RDD的分区数,如:

getNumPartitions() 即获取RDD的分区数。
4 数据排序
sortByKey
ascending表示是否升序,keyfunc表示自定义排序函数(这里使用将键以字符串形式排序)

5 行动操作
和转化操作一样,所有基础RDD支持的传统行动操作也都在pair RDD上可用。这里还有额外的一些操作:
5.1 countByKey
对每个键对应的元素计数

5.2 collectAsMap
将结果以映射表的形式返回,从结果看,相同的key会覆盖

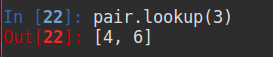
5.3 lookup
返回指定键的所有值
6 分区深入
这里简单描述博主认为关键的地方,至于更加详细的建议还是买本书籍吧。
对于RDD的分区,spark内部会默认选择合适分区方式、分区数。
分区方式如:范围分区、哈希分区。
但是,选择合适的分区方式、分区数是对spark调优的重要手段。
如果一个RDD已经有了分区方式,那么从该RDD转化出来的RDD也将拥有与父RDD相同的分区方式(但并不绝对,如父RDD采用哈希方式,对该RDD进行map()操作可能改变键,所以就没有固定的分区方式)。
以下操作会与父RDD拥有相同的分区方式:cogroup()、groupWith()、join()、leftOuterJoin()等等(并不是所有)。
自定义分区
定义分区能够调优spark的性能。
场景:对一个网站进行PageRank(计算一个网页在另一个网页出现链接的次数,以此排名)算法,在如www.cnn.com/WORLD和www.cnn.com/US,该两个页面可能分配到不同的节点上。但是,具有相同域名的URL相互之间存在链接的可能性更大。所以,最好是将这两个网页分配到同一个节点。
这里,就可以使用自定义分区方式。
import urlparsedef hash_domain(url):return hash(urlparse.urlparse(url).netloc)rdd.partitionBy(20, hash_domain) # 20个分区
partitionBy() 函数为Python中设置分区的函数。