前言
文章很长很长,建议配合右边的目录。。。
博主在学习大数据过程中也写过各种组件的安装步骤,但是比较零散。
最近,在学习Spark Streaming中需要开启很多大数据服务,笔记本搭建虚拟机的集群已经带不动程序。正好,学校配了台高配的主机,所以决定从头开始搭建大数据的集群。并且记录完整、详细的安装过程。
注:学习大数据希望你的电脑配置不要太低,如果太低连虚拟机都运行不起来。如果配置不算高,能够跑起集群,但无法在集群中开启很多服务。
博主在此之前,搭建了三台虚拟机,配置如下:5.5G-Ubuntu、2个1GReadHat。但是一旦开启多个服务后,仍然卡的不行。
如果你是完全的小白,还是建议先掌握单机、伪分布,如果有一些基础,建议分布式。
另外,更加详细的单个组件的安装步骤可参考博主的其他文章。
将安装的大数据组件及软件
- VirtualBox-6.0.6
- Ubuntu-18.04.1
- CentOS-7
- JDK-1.8-152
- Hadoop-2.7.3
- HBase-1.4.8
- Zookeeper-3.4.12
- Spark-2.4.0
- Kafka_2.11-2.1.1
- Flume-1.9.0
- Maven-3.3.9
- ideaIU-2019.1.1
这里使用Ubuntu作为主节点,CentOS作为子节点(字符界面,尽量节省内存)。
还有诸如Hive、Sqoop等,这里先不介绍安装。
百度网盘链接:

链接: https://pan.baidu.com/s/1FU_J4bR67eJoV-2HatnQ1w
提取码: vawv
1. VirtualBox安装
双击安装,默认安装,更改下安装路径即可:

安装完成:

VirtualBox中设置一个类似自动分配IP局域网:
添加一个NatNetWork:

2. Ubuntu的安装
首先你需要下载Ubuntu-18的镜像文件:

在VirtualBox中新建一个虚拟电脑:

分配内存:
如果你是:
伪分布式,建议 >= 3G
完全分布式,并且需要搭建开发环境,建议 >= 6G

虚拟硬盘:

虚拟硬盘文件类型:
VDI:一次性创建出一个n G大小的硬盘。
VHD:给出一个最大值,动态的使用硬盘大小。
(来源网络)
如果你硬盘空间足够,建议 VDI 性能更好,否则 VHD。

硬盘分配类型:
这步也选择动态还是固定,但是VDI、VHD也有这个概念。具体为什么不清楚。。。

硬盘大小:
红箭头地方,建议点击一下。

创建完成:

设置一下Ubuntu的处理器数量:
建议 > Windows的 1/2。

设置网络:
NAT使用VirtualBox自动分配一个IP,集群通信:

联网需要:

创建一个共享目录:(需要增强功能)
Linux可以从该目录直接读取windows下的文件:

粘贴共享:(需要增强功能)

配置大概完成,下面安装Ubuntu:
直接启动Master,选择ISO镜像:

系统安装语言(不是输入法),点击Install Ubuntu:

下面一些简单的安装步骤省略。。。

自定义安装:

得到可用的空间:


空间分配,博主硬盘空间50G(上面截图是40G,这里更改了),如果你的空间较小,可以调整/、/tmp、/home的大小:
/ – 35G
swap – 2G
/boot – 256M
/tmp – 5G
/home – 剩余所有
这个配置不是必须的,完全根据需要和你空间的大小进行调整。
这里主要空间分配到了/ ,因为后面组件的安装将安装到/ 下,如果你要安装到/home,应该将/home的大小调大。
选中free ,点击+:
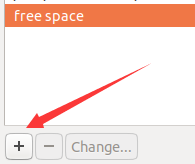
- /

- swap

- /boot

- /tmp

- /home

完成:

点击Install Now。。。
时区选择:


等待安装。。。
如果你是准备安装集群,下面可以接着安装CentOS。
安装完成:
重启之后,窗口不是全屏:

安装增强功能:

安装成功后,窗口变得正常:

注意:安装完成后,重启Ubuntu。。。
测试:

Ubuntu的配置见第4点。。。
3. CentOS的安装
镜像文件:

新建虚拟电脑:


这里省略一些相同的步骤:

同样进行设置:
这里使用2048M内存、1 个处理器。
网络设置依然是:网卡1-NAT网络、网卡2-网络地址转换(NET)
这里用设置共享目录。
启动:
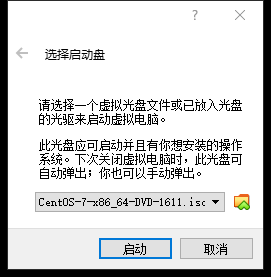
安装:

注意:点击右边方向键左边的Ctrl,可跳出,即鼠标移动到Windows。
系统语言:

默认安装字符界面,分区默认分配即可,

点击网络配置,把两个网卡都点击ON:

点击Begin install:

root密码设置:
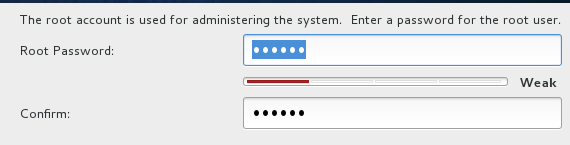
这里再创建一个hadop用户(后面集群的通信都是使用hadoop用户):

安装完成,重启:

登陆测试:
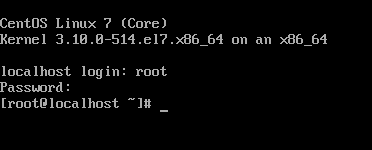

创建目录(该目录用于安装各组件):

CentOS的配置见第4点。
4. Ubuntu 和 CentOS的配置
- Ubuntu
- 共享目录
博主之前已经在Windows下载了相关的安装包,并且以后也会用到Widnows与Linux的数据传输,所以这里创建一个共享目录。
不过,很难受的是,共享目录设置没有成功,具体操作可以参考:https://blog.csdn.net/qq_38038143/article/details/83017877
但是,发现拖拽功能可以实现,可以直接从Windows拖拽文件:
如果,你两个操作都不行,如果能联网,就在Ubuntu下载相应安装包吧。如果不能,就再设置第3个网卡:格式为桥接,将虚拟机桥接网卡的IP 设置与Windows同一个网段,然后使用如fpt、WinScp之类的传输软件传输文件,不过有一个限制是,如果Windows的局域网发生变化,Ununtu的IP也要随之改变,是比较麻烦的。
然后把准备的安装包上传,当然你可以不必一次性全部上传,需要什么上传什么:

5. 开始安装大数据组件
5.1 CentOS的复制
目前已经安装了一个Ubuntu、一个CentOS,不过博主打算使用2个CentOS作为子节点,所以需要再复制一个虚拟机。
将CentOS关机,在VirtualBox中选中Slave1,右键选择复制:



5.2 Hadoop的单机、伪分布安装
这里先从Hadoop的单机、伪分布式安装开始。
后面可能会有防火墙问题:
关闭ununtu :
sudo ufw disable
关闭 centos
systemctl stop firewalld.service
systemctl disable firewalld.service
- JDK的安装
hadoop@master$ cd /app
hadoop@master:/app$ mkdir java
hadoop@master:/app$ tar -zxvf ./soft/jdk-8u152-linux-x64.tar.gz -C ./java/
环境变量配置:
~/.bashrc 末尾添加
# JDK
export JAVA_HOME=/app/java/jdk1.8.0_152
export PATH=$PATH:$JAVA_HOME/bin
使生效:source ~/.bashrc

2. 免密登陆
分别执行命令:第一条命令一直回车
ssh-keygen -t rsa
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
chmod 600 authorized_keys
测试:

解决办法,安装openssh-server:
sudo apt-get install openssh-server
再次测试:

如果第二次不需要输入密码,即成功:
- Hadoop单机模式
解压:
tar -zxvf ./soft/hadoop-2.7.3.tar.gz -C ./
配置环境变量:
# Hadoop
export HADOOP_HOME=/app/hadoop-2.7.3
export HADOOP_INSTALL=$HADOOP_HOME
export HADOOP_MAPRED_HOME=$HADOOP_HOME/etc/hadoop
export HADOOP_COMMON_HOME=$HADOOP_HOME/etc/hadoop
export HADOOP_HDFS_HOME=$HADOOP_HOME/etc/hadoop
export YARN_HOME=$HADOOP_HOME/etc/hadoop
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop/
export PATH=$PATH:$HADOOP_HOME/sbin:$HADOOP_HOME/bin:$HADOOP_HOME/etc/hadoop/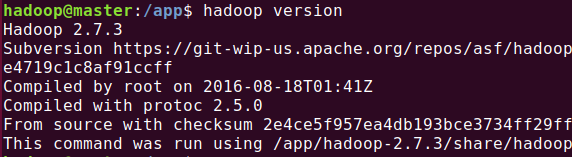
修改Hadoop-env.sh:

单机测试:
在hadoop-2.7.3下创建文件输入目录 input,并复制文件:
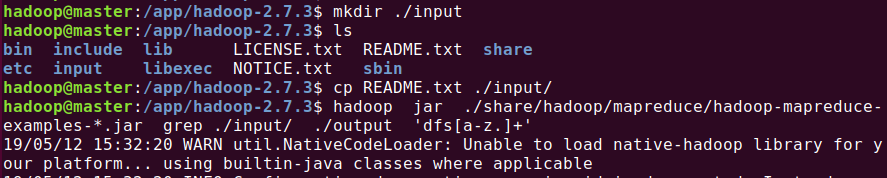
命令:
hadoop jar ./share/hadoop/mapreduce/hadoop-mapreduce-examples-*.jar grep ./input/ ./output 'dfs[a-z.]+'
结果:

4. Hadoop伪分布
配置IP 映射:
vim /etc/hosts

这个IP 从哪里来的,第一个网卡使用了NAT模式,所以会自动分配一个IP:
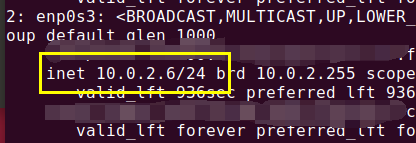
重启网络:
sudo /etc/init.d/networking restart
测试:
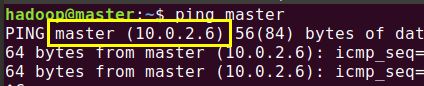
非常重要:
Hadoop 的配置:
cd /app/hadoop-2.7.3/etc/hadoop
core-site.xml
<configuration><property><name>hadoop.tmp.dir</name><value>file:///app/hadoop-2.7.3/tmp</value><description>注释</description></property><property><name>fs.defaultFS</name><value>hdfs://master:9000</value></property>
</configuration>
hdfs-site.xml
<configuration><property><name>dfs.replication</name><value>1</value></property><property><name>dfs.permissions</name><value>false</value></property><property><name>dfs.namenode.name.dir</name><value>file:///app/hadoop-2.7.3/dfs/name</value></property><property><name>dfs.datanode.data.dir</name><value>file:///app/hadoop-2.7.3/dfs/data</value></property>
</configuration>
mapred-site.xml
cp mapred-site.xml.template mapred-site.xml
<configuration><property><name>mapreduce.framework.name</name><value>yarn</value></property><property><name>mapreduce.jobtracker.address</name><value>master:9001</value></property>
</configuration>
yarn-site.xml
<configuration><property><name>yarn.nodemanager.aux-services</name><value>mapreduce_shuffle</value></property><property><name>yarn.resourcemanager.webapp.address</name><value>master:8099</value></property><property> <name>yarn.resourcemanager.address</name> <value>master:8032</value> </property> <property> <name>yarn.resourcemanager.scheduler.address</name> <value>master:8030</value> </property> <property> <name>yarn.resourcemanager.resource-tracker.address</name> <value>master:8031</value> </property>
</configuration>
格式化Hadoop:
创建hdfs-site.xml 中的文件夹:
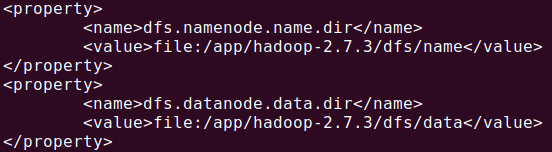
cd /app/hadoop-2.7.3
mkdir -p dfs/{name,data} tmp
格式化命令:
hadoop namenode -format
格式化成功:

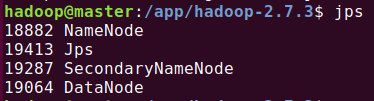
启动hdfs:
第一次启动需要输入两次yes,因为配置了免密,所以后面不用每次输入密码。
start-dfs.sh
启动成功:
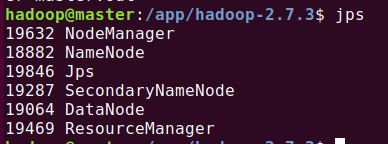
启动yarn:
start-yarn.sh
Web界面查看:
http://master:50070

http://master:8099

创建出用户目录:

web界面也可以查看:


5.3 Hadoop集群安装
- 配置子节点
不出意外,现在两个子节点的主机名都是localhost,现在要改成slave1、slave2:
以salve1 为例,第二个子节点同理。。。
修改/etc/hostname :

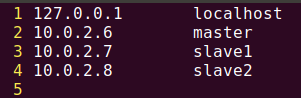
配置IP映射:
这个IP就是使用NAT网卡获得的,使用ip addr 查看机器的IP。。。
10.0.2.6 master
10.0.2.7 slave1
10.0.2.8 slave2
重启机器,测试:

关闭防火墙:
systemctl stop firewalld.service
systemctl disable firewalld.service
按照同样的步骤,配置slave2.。。
- 三台机器之间免密登陆
这时,之前创建的hadoop用户起作用了。。。
slave1 的操作:
从root 用户切换为hadoop 用户:
su hadoop

生成密钥:
# 一直回车
ssh-keygen -t rsa
# 复制密钥到master
ssh-copy-id -i ~/.ssh/id_rsa.pub master

在slave2 中执行上面同样的操作:

在Master节点中查看:

同样,修改Master节点的IP映射:
vi /etc/hosts
重启网络:

将该文件复制到slave1、和slave2:
scp ./authorized_keys slave1:~/.ssh
scp ./authorized_keys slave2:~/.ssh

登陆测试,不需要输入密码即成功:

- Hadoop集群配置
修改hdfs-site.xml
这里设置了集群副本数=2,即上传到HDFS的文件都将有2份数据,并且以block为单位存储在不同的子节点。
<configuration><property><name>dfs.replication</name><value>2</value></property><property><name>dfs.permissions</name><value>false</value></property><property><name>dfs.namenode.name.dir</name><value>file:///app/hadoop-2.7.3/dfs/name</value></property><property><name>dfs.datanode.data.dir</name><value>file:///app/hadoop-2.7.3/dfs/data</value></property><property><name>dfs.namenode.datanode.registration.ip-hostname-check</name><value>false</value></property>
</configuration>
修改slaves:
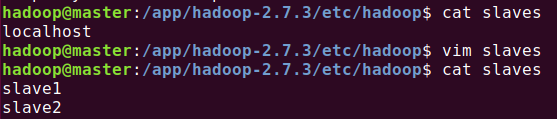
停止伪分布式Hadoop:
stop-all.sh
删除当前伪分布式的数据,并重建目录:

将配置好的Haoop-2.7.3传输到子节点:
为了简化操作,使用shell脚本,:

在sh_file/ 下创建一个文件:
transmitFile.sh
#!/bin/bash
# scp file to other machine# example
# ./transmitFile.sh /home/hadoop/test.txt /home/hadoopclear
for ip in slave1 slave2
doecho "------------------------------[ transmit to $ip ]------------------------"scp -r $1 $ip:$2echo " "
done
给予执行权限:
chmod -R 755 sh_file/*
传输命令:
~/sh_file/transmitFile.sh ./hadoop-2.7.3/ /app/
~/sh_file/transmitFile.sh ./java /app/
查看:

同样需要设置slave1、slave2的环境变量:
复制master 已经配置好的.bashrc 修改slave1、slave2的.bashrc:


格式化Hadoop:
hadoop namenode -format

启动集群:

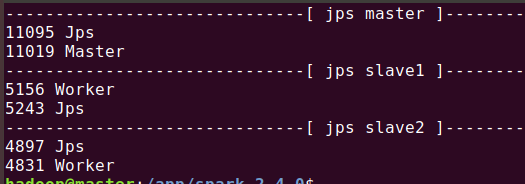
同样,在sh_file中创建脚本查看个机器的进程:
sh_file/watch.sh
#!/bin/bash
# watch machine jpsclear
echo "------------------------------[ jps master ]-------------------------"
jpsfor ip in slave1 slave2
doecho "------------------------------[ jps $ip ]-------------------------"ssh hadoop@$ip "source /etc/profile;jps"给予执行权限:
chmod -R 755 sh_file/*
查看:
~/sh_file/watch.sh

Web中查看:

Hadoop 集群搭建完成。。。
5.4 Hbase集群的搭建
因为博主使用的是Ubuntu 和CentOS,两种机器的时区不同,需要修改:

在子节点赋予hadoop 用户sudo 权限:

添加内容如下:

修改时区:

每台机器的时间相差不能太大,会导致HBase集群无法启动。
使用date -s “2019-05-12 20:30:15” 的格式设置即可,不需要秒数完全相同,相差不大即可。
HBase的进程很容易一开始能够启动,但几秒后进程就死掉,需要仔细检查配置,检查不出来就删除所有的日志文件,重新配置。
- 单机模式
解压:
tar -zxvf soft/hbase-1.4.8-bin.tar.gz -C ./

设置JDK:
vim hbase-1.4.8/conf/hbase-env.sh

注意下面的代码,默认是启动HBase自带zookeeper管理,后面搭建Hbase集群时会更改:

修改pid 保存路径:

配置文件:
vim hbase-1.4.8/conf/hbase-site.xml
<configuration><property><name>hbase.rootdir</name><value>file:///app/hbase-1.4.8/tmp/local-test</value></property><property><name>hbase.zookeeper.property.dataDir</name><value>file:///app/hbase-1.4.8/tmp/local-test/zookeeper-data</value></property>
</configuration>
创建pids目录:

设置环境变量:
vim ~/.bashrc
# HBase
export HBASE_HOME=/app/hbase-1.4.8
export PATH=$PATH:$HBASE_HOME/bin
source ~/.bashrc
后面就不再说明修改文件,source 文件,直接贴代码。。。步骤都是相同的。
启动HBase:


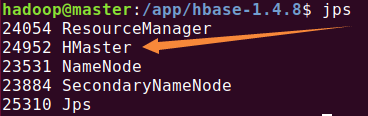
关闭HBase:
stop-hbase.sh
- 伪分布模式
NTP时间同步设置:
使用 date 命令设置时间同步只能解决暂时的问题,随着使用的时间增长,可能会经常调整时间同步。所以需要安装一个时间同步服务。
Ubuntu 下安装:
sudo apt-get install ntp
设置配置文件:
sudo vim /etc/ntp.conf
黄框中都是需要添加的内容:

restrict 10.0.2.0 mask 255.255.255.0 nomodify notrap # support network segment# have network: synchronised time by this
server 210.72.145.44 perfer # China time center
server 202.112.10.36 # 1.cn.pool.ntp.org
server 59.124.196.83 # 0.asia.pool.ntp.org# allow top modify localtime
restrict 210.72.145.44 nomodify notrap noquery
restrict 202.112.10.36 nomodify notrap noquery
restrict 59.124.196.83 nomodify notrap noquery# no network: use local time
server 127.127.1.0 # local clock
fudge 127.127.1.0 stratum 10
重启ntp 服务:
sudo /etc/init.d/ntp restart

CentOS下安装:
sudo yum -y install ntp

修改配置文件:
sudo cp /etc/ntp.conf /etc/ntp.conf.bak
sudo vi /etc/ntp.conf
注释掉红框内容,添加黄框内容:

在启动之后很可能,不能同步到master 的连接,需要禁用IPv6:
sudo vi /etc/sysctl.conf
添加如下内容。。。
# 禁用整个系统所有接口的IPv6
net.ipv6.conf.all.disable_ipv6 = 1
# 禁用某一个指定接口的IPv6(例如:eth0, eth1)
net.ipv6.conf.eth1.disable_ipv6 = 1
net.ipv6.conf.eth0.disable_ipv6 = 1
重启网络:
sudo service netowkr restart
启动服务:
systemctl start ntpd.service
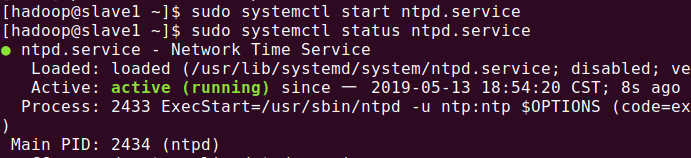
出现master 启动成功:

对slave2进行同样的操作,然后启动查看

对子节点设置开机启动ntp:
sudo systemctl enable ntpd.service
sudo systemctl enable ntpdate.service
HBase设置:
修改 hbase-site.xml
<configuration><property><name>hbase.rootdir</name><value>hdfs://master:9000/hbase</value></property><property><name>hbase.zookeeper.property.dataDir</name><value>file:///app/hbase-1.4.8/tmp/pseudo-distributed/zookeeper-data</value></property><property><name>hbase.cluster.distributed</name><value>true</value></property>
</configuration>
复制core-site.xml 和 hdfs-site.xml 到conf/ 目录下, 启动 start-hbase.sh :

测试Hbase:
hbase shell

- 完全分布式
修改 hbase-site.xml
<configuration><property><name>hbase.rootdir</name><value>hdfs://master:9000/hbase</value></property><property><name>hbase.zookeeper.property.dataDir</name><value>file:///app/hbase-1.4.8/tmp/distributed/zookeeper-data</value></property><property><name>hbase.cluster.distributed</name><value>true</value></property><property><name>hbase.zookeeper.quorum</name><value>master,slave1,slave2</value></property>
</configuration>
修改conf/regionservers(保存数据)和backup-masters(备用HMaster):
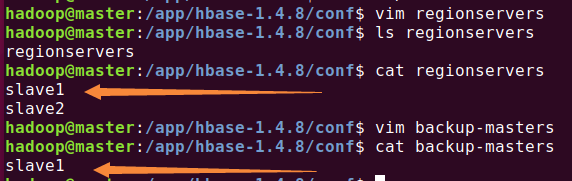
传输到子节点:
~/sh_file/transmitFile.sh hbase-1.4.8/ /app/

同样设置HBase的环境变量:
启动HBase,在Master节点执行:
start-hbase.sh
查看,所有节点的进程:

5.5 Zookeeper 集群的安装
解压:
tar -zxvf soft/zookeeper-3.4.12.tar.gz -C ./
环境变量:
# Zookeeper
export ZOOKEEPER_HOME=/app/zookeeper-3.4.12
export PATH=$PATH:$ZOOKEEPER_HOME/bin/
设置ID:

添加配置文件:
vim conf/zoo.cfg
# The number of milliseconds of each tick
tickTime = 2000
# The number of ticks that the initial
# synchronization phase can take
initLimit=10
# The number of ticks that can pass between
# sending a request and getting ian acknowledgement
syncLimit=5
# the directory where the snapshot is stored.
dataDir=/app/zookeeper-3.4.12/data
# the ort at which the clients will connect
clientPort=2181
# the location of the log file
dataLogDir=/app/zookeeper-3.4.12/log
server.0=master:2888:3888
server.1=slave1:2888:3888
server.2=slave2:2888:3888
传输到子节点:
~/sh_file/transmitFile.sh ./zookeeper-3.4.12/ /app/
修改子节点的myid,对应配置文件:

设置三台机器的环境变量:
# Zookeeper
export ZOOKEEPER_HOME=/app/zookeeper-3.4.12
export PATH=$PATH:$ZOOKEEPER_HOME/bin/
因为要到每台机器启动,所以设置脚本启动:
启动关闭命令:zkServer.sh start zkServer.sh stop
zkServerStart.sh
#!/bin/bash
# start zkclearfor ip in master
doecho "------------------------------[ Zookeeper $ip ]-------------------------"source /etc/profile;zkServer.sh start
donefor ip in slave1 slave2
doecho "------------------------------[ Zookeeper $ip ]-------------------------"ssh hadoop@$ip "source /etc/profile;zkServer.sh start"
done
zkServerStop.sh
#!/bin/bash
# stop zkclearfor ip in master
doecho "------------------------------[ Zookeeper $ip ]-------------------------"source /etc/profile;zkServer.sh stop
donefor ip in slave1 slave2
doecho "------------------------------[ Zookeeper $ip ]-------------------------"ssh hadoop@$ip "source /etc/profile;zkServer.sh stop"
done
启动zookeeper:

登陆zookeeper:
zkCli.sh -server master
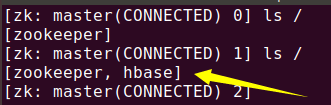
将HBase交由zookeeper管理:
修改 hbase-env.sh:

将修改后的传输到子节点:
~/sh_file/transmitFile.sh conf/hbase-env.sh /app/hbase-1.4.8/conf/
启动Hbase:
5. 6 Scala 的安装
只安装到Master 节点即可。。。
解压
tar -zxvf soft/scala-2.11.8.tgz -C ./
环境变量:
# Scala
export SCALA_HOME=/app/scala-2.11.8
export PATH=$PATH:$SCALA_HOME/bin/
测试:
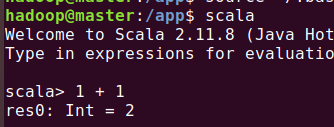
ctrl + d 退出。。。
5.7 Spark 的安装
- 单机
解压、修改名称:
tar -zxvf soft/spark-2.4.0-bin-hadoop2.7.tgz -C ./
mv spark-2.4.0-bin-hadoop2.7/ spark-2.4.0
环境变量:
# Spark
export SPARK_HOME=/app/spark-2.4.0
export PATH=$PATH:$SPARK_HOME/bin/
测试:
启动spark命令:spark-shell

web查看:
http://master:4040

- 集群
修改 conf/slaves

传输到子节点:
~/sh_file/transmitFile.sh ./spark-2.4.0/ /app/
配置环境变量:
# Spark
export SPARK_HOME=/app/spark-2.4.0
export PATH=$PATH:$SPARK_HOME/bin/
测试:
为了更清晰的查看,关闭hbase、zookeeper、hadoop,注意关闭顺序。。。
因为环境变量中没有写 sbin/ 目录,所以需要到spark 安装目录下启动:
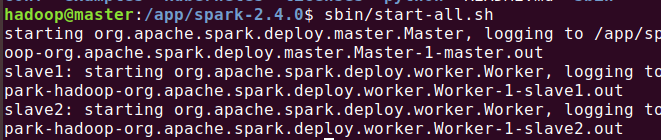
web查看:
http://master:8080

测试:
启动方式:

使用独立集群管理器启动:
spark-shell --master spark://master:7077
测试代码与上面相同,统计单词:
val rdd = sc.textFile("./README.md")
val rdd2 = rdd.flatMap(_.split(" ")).map((_, 1)).reduceByKey(_ + _)
rdd2.take(5)

现在开启Hadoop,使用yarn启动:

复制hdfs-site.xml 和 yarn-site.xml 到spark-2.4.0/conf/,并且传输到子节点的spark/conf 下:
然后在 conf/spark-env.sh 设置参数,spark-site.xml 设置参数,
然后把 spark-2.4.0/lib/* 上传到 hdfs://master:9000/spark_jars(目录名随便,会设置在spark配置文件中)。。。
启动命令: spark-shell --master yarn
每个任务都将在 http://master:8099 中查看。。。
博主设置之后不能使用本地文件,默认的文件路径是HDFS,所以要使用本地文件需要先上传到HDFS。。。
不过,有大佬提醒导入文件时使用 file:// 前缀,不过现在忘了能不能行得通。。。
这里就不详细展示了,如果需要网上搜索详细教程。 也可以发邮箱给我,我将配置文件发送给你。。。
5.8 Kafka 的安装
解压:
tar -zxvf soft/kafka_2.11-2.1.1.tgz -C ./
2.11 代表scala的版本,2.1.1代表kafka的版本:

环境变量:
# Kafka
export KAFKA_HOME=/app/kafka_2.11-2.1.1
export PATH=$PATH:$KAFKA_HOME/bin
单机启动kafka:
先启动zookeeper,再启动kafka:
zkServer.sh start
kafka-server-start.sh -daemon ./config/server.properties
因为,博主现在是zookeeper集群,所以单机就不演式了。
贴上以前测试代码:
hadoop@master:~/kafka-2.1.1$ kafka-server-start.sh -daemon ./config/server.properties
hadoop@master:~/kafka-2.1.1$ jps
5794 Kafka
3641 QuorumPeerMain
5818 Jps
测试命令:
# 创建主题
hadoop@master:~/kafka-2.1.1$ kafka-topics.sh --create --zookeeper master:2181 --replication-factor 1 --partitions 1 --topic test
Created topic "test".# 验证主题
hadoop@master:~/kafka-2.1.1$ kafka-topics.sh --zookeeper master:2181 --describe --topic test
Topic:test PartitionCount:1 ReplicationFactor:1 Configs:Topic: test Partition: 0 Leader: 0 Replicas: 0 Isr: 0
hadoop@master:~/kafka-2.1.1$ # 向主题发布消息
hadoop@master:~/kafka-2.1.1$ kafka-console-producer.sh --broker-list master:9092 --topic test
>hello world!
>hello kafka
# (Ctrl + D结束)# 从主题读取消息
hadoop@master:~/kafka-2.1.1$ kafka-console-consumer.sh --bootstrap-server master:9092 --topic test --from-beginning
hello world!
hello kafka
^CProcessed a total of 2 messages
配置kafka 集群:
vim config/server.properties 修改zoookeeper:

传输到子节点:
~/sh_file/transmitFile.sh kafka_2.11-2.1.1/ /app/
设置broker ,每个机器都需要设置:
vim config/server.properties
master - - 0
slave1 - - 1
slave2 - - 2

配置子节点环境变量:
# Kafka
export KAFKA_HOME=/app/kafka_2.11-2.1.1
export PATH=$PATH:$KAFKA_HOME/bin
同样,设置一个脚本启动kafka:
kafkaStart.sh
#!/bin/bash
# start kafkaclear# kafka
for ip in slave1 slave2
doecho "------------------------------[ Kafka $ip ]-------------------------"ssh hadoop@$ip "source /etc/profile;kafka-server-start.sh -daemon /app/kafka_2.11-2.1.1/config/server.properties"
done
kafkaStop.sh
#!/bin/bash
# stop kafkaclear# kafka
for ip in slave1 slave2
doecho "------------------------------[ Kafka $ip ]-------------------------"ssh hadoop@$ip "source /etc/profile;kafka-server-stop.sh"
done

因为这里设置是子节点存放数据,并且数据位置/tmp/kafka-logs 。。。
5.9 Flume 的安装
解压:
tar -zxvf soft/apache-flume-1.9.0-bin.tar.gz -C ./
mv apache-flume-1.9.0-bin/ flume-1.9.0
配置环境变量:
# Flume
export FLUME_HOME=/app/flume-1.9.0
export PATH=$PATH:$FLUME_HOME/bin
设置flume:

vim flume-env.sh

启动flume:
再 conf 目录下创建 example.conf
# Name the components on this agent
a1.sources = r1
a1.sinks = k1
a1.channels = c1# Describe/configure the source
a1.sources.r1.type = netcat
a1.sources.r1.bind = master
a1.sources.r1.port = 44444# Describe the sink
a1.sinks.k1.type = logger# Use a channel which buffers events in memory
a1.channels.c1.type = memory# Bind the source and sink to the channel
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
启动命令:
flume-ng agent \
--name a1 \
--conf $FLUME_HOME/conf \
--conf-file $FLUME_HOME/conf/example.conf \
-Dflume.root.logger=INFO,console
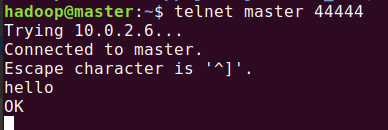

集群的配置很简单,直接复制解压后的flume 到子节点,使用时只需要配置 自定义.conf 文件。。。
5.10 Maven安装
解压:
tar -zxvf soft/apache-maven-3.3.9-bin.tar.gz -C ./
mv apache-maven-3.3.9/ maven-3.3.9
默认的仓库是在/home/hadoop/.m2,因为博主前面设置了所有相关文件存放在/app 下,所以需要修改配置:
settings.xml作了两个修改:修改仓库的存储路径、设置阿里源。
settings.xml 在网盘中给出,在app 下创建 .m2/repository 目录,并且将settings.xml 复制到目录下,同时maven-3.3.9/conf/ 下也需要复制:
备份原来的,并且将新的复制:

5.11 IDEA安装
解压:
tar -zxvf soft/ideaIU-2019.1.1.tar.gz -C ./

固定到启动栏:

第一次启动的配置很简单,不会的话不要安装任何插件,其中有一个创建/usr/bin/idea 点击勾选:
注册码:http://idea.lanyus.com/
因为要导入项目,虽然已经可以拖拽,但是只能推拽一层目录,也就是目录之下的文件并没有被推拽到Linux,所以创建第三个网卡:
关机Ubuntu、设置桥接模式:


查询Windows 的IP、子网掩码、网关:
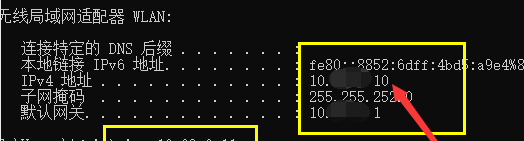

重启网络:sudo /etc/init.d/networking restart
测试:

下载WinSCP:https://winscp.net/download/WinSCP-5.15.1-Setup.exe
使用WinSCP上传文件:



直接拖拽就行了,非常方便。。。
然后启动IDEA:
新建一个项目:


点击Finish,第一次构建Maven项目,需要下载很多东西,等待即可:
完成:

查看本地maven仓库:

删除无用的信息:

现在从刚才上传的sparkstream 中复制源文件:

覆盖poxm.xml:


设置:


导入依赖,第一次会下载很久、好像也不是很久。。。:
这里把能够运行hadoop、hbase、spark、kafka、flume等几乎相关的所有依赖都导入,存储以G为单位,所以需要下载很久。。。
如果不能等待很长时间可以参考:https://blog.csdn.net/qq_38038143/article/details/89926205, 这篇博客只介绍导入了Spark Streaming相关依赖。
终于,依赖导入完毕,但不一定能够运行导入所有的程序代码,如果你运行其中某一个代码发生依赖错误,就需要你进行相关的修正,这些修正不一定通用,需要根据你的报错实际更改。。。
Maven 依赖官网:https://mvnrepository.com/
需要依赖的名称搜索即可:

选择版本:

将代码复制到pom.xml 后再次import changes即可:
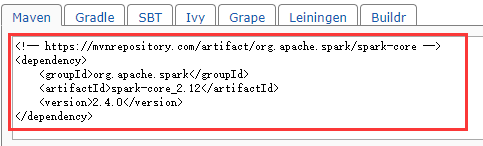
查看导入完成后的项目:
显示maven 依赖窗口:


看下仓库:

现在来运行第一个程序:
右键项目名,设置项目的显示格式,想要什么格式就在前面打勾:

现在的项目显示:

运行,需要设置scala:

等待下载:
如果下载失败,需要设置下使用的方式:

再次尝试,下载完成,需要重启IDEA:
然后,你会发现代码颜色的改变:

build project:

提示设置scala:


选择安装scala 的目录:
运行测试:
在终端开启:
右键运行:

输入数据:

代码已经跑通了。。。
有兴趣可以测试其他代码。。。
开启所有集群

脚本将子节点关机:
先关闭所有服务进程。。。
sh_file/dowDataNode.sh
结语
除了上述的安装,其他的安装你应该已经有一定的套路了吧。也可以参靠博主的其他文章。。。如Hive、Sqoop的安装。