文章目录
- 1.介绍
- 2.server端部署流程
-
- 2.1安装
- 2.2运行
-
- 2.1本地建立模型仓库
- 2.2启动容器并运行
- 2.3验证
- 3.client端开发部署流程
-
- 3.1安装
- 3.2运行
-
- 3.2.1图像分类demo分析
- 3.2.2yolo demo分析
- 3.3高级特性
- 4.模型仓库
-
- 4.1 仓库结构
- 4.2 版本控制
- 5.模型设置
- 6.模型调度程序
- 7.模型管理
-
- 7.1 NONE 模式
- 7.2 POLL 模式
-
- 7.2.1 版本改动
- 7.2.2 模型删除和增加
- 7.2.3 模型配置文件以及标签文件的改动
- 7.3 ECPLICIT 模式
- 8.优化
- 9.性能指标
1.介绍
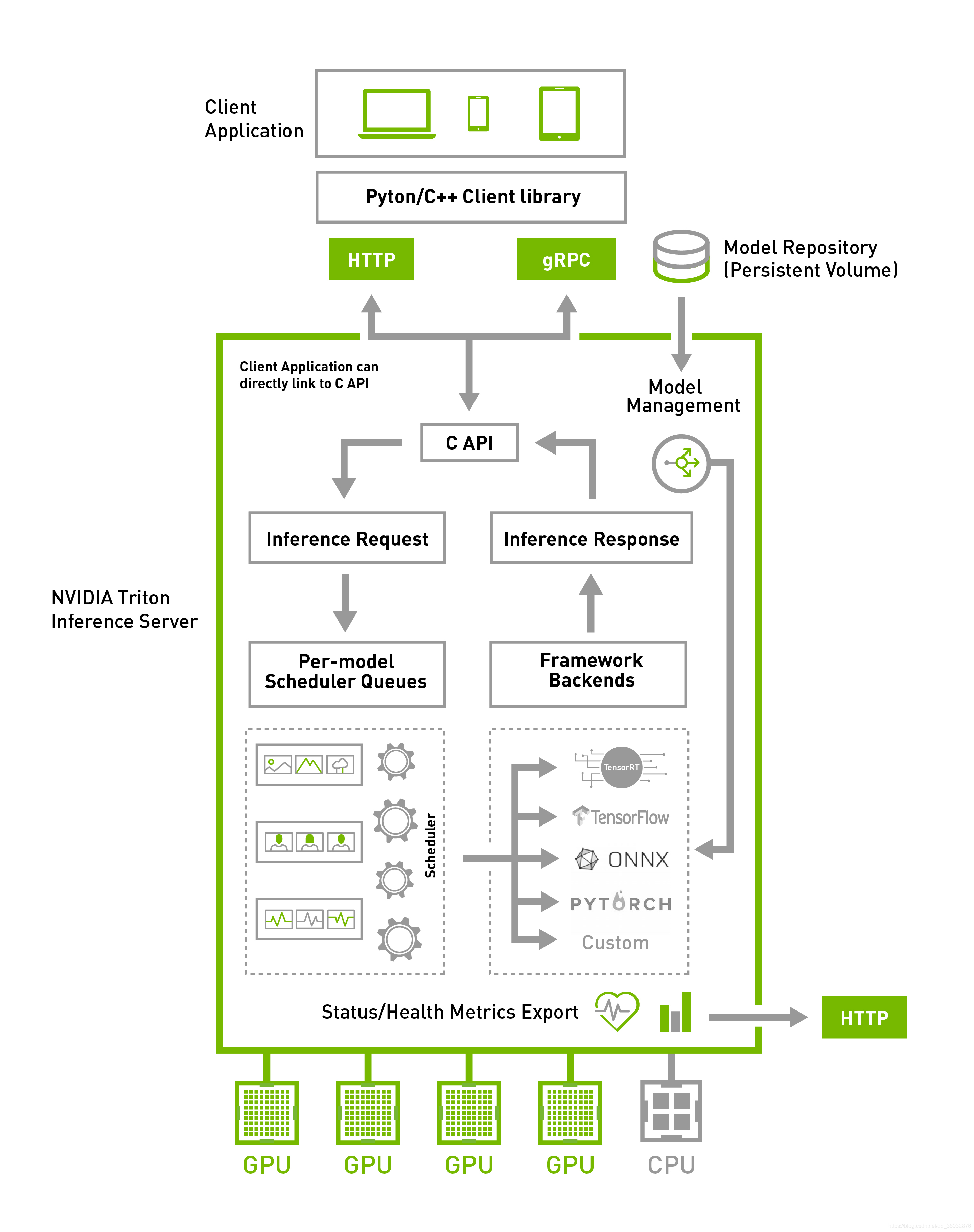
公司项目中需要做AI云平台的部署,一开始尝试Paddle serving做云端部署,发现很不稳定,QPS也比较低,准备换英伟达平台尝试一下,这篇旨在上手使用,更多需求请查看官方文档.
推荐上手项目:yolov4-triton-tensorrt
如何生成tensorrt引擎
本篇只介绍docker安装,GPU版本
2.server端部署流程
2.1安装
推荐使用docker安装,去nvidia-NGC中搜索Triton Inference Server下载,注意,需要先安装docker和nvidia-docker(有空会补教程)
docker pull nvcr.io/nvidia/tritonserver:20.10-py3 #截止目前最新版本
2.2运行
2.1本地建立模型仓库
官方推荐本地建一个文件夹,里面分别放置已经生成好的tensorrt引擎以及自己写的模型插件(libXXX.so,只有一些特殊模型会用到如果用不到插件就不放)
eg:
Create model repository
cd yourworkingdirectoryhere
mkdir -p triton-deploy/models/yolov4/1/
mkdir triton-deploy/plugins
Copy engine and plugins
这里是将tenosrrt生成的推理引擎和自己写的自定义插件放到自己建立的模型仓库里面,至于如何生成这些引擎,另一篇文章会讲
cp yolov4-triton-tensorrt/build/yolov4.engine triton-deploy/models/yolov4/1/model.plan
cp yolov4-triton-tensorrt/build/liblayerplugin.so triton-deploy/plugins/
2.2启动容器并运行
$ docker run --gpus=1 --rm -p8000:8000 -p8001:8001 -p8002:8002 -v/path/to/model/repository:/models <tritonserver image name> tritonserver --model-repository=/models
替换成自己拉取的镜像名称,比如nvcr.io/nvidia/tritonserver:20.10-py3,
-v 选项的意思是挂载外部文件夹到docker容器里面,这里是将2.1建立的模型仓库挂载到里面了。
-p 选项的意思是将容器内外网络端口打通,比如我请求主机的8000端口,就相当于请求容器中的8000端口
–shm-size --ulimit 可以用来调整服务器性能,可以查一查docker文档,不设置也可以
eg:
docker run --gpus all --rm --shm-size=1g --ipc=host --ulimit memlock=-1 --ulimit stack=67108864 -p8000:8000 -p8001:8001 -p8002:8002 -v$(pwd)/triton-deploy/models:/models -v$(pwd)/triton-deploy/plugins:/plugins --env LD_PRELOAD=/plugins/liblayerplugin.so nvcr.io/nvidia/tritonserver:20.08-py3 tritonserver --model-repository=/models --strict-model-config=false --grpc-infer-allocation-pool-size=16 --log-verbose 1
metrics可以查看服务器资源使用情况
2.3验证
本机部署好服务器后,可以新起一个终端
curl -v localhost:8000/v2/health/ready
如果返回有这个
...
< HTTP/1.1 200 OK
< Content-Length: 0
< Content-Type: text/plain
说明服务器已经正常启动了,这里的 8000端口是默认的,如果你自定义了端口,就请求你自定义的端口,至此,你就可以使用HTTP/REST or GRPC protocols等多种协议去请求你的推理服务了。
3.client端开发部署流程
nvidia提供了client libraries来加速客户端程序的开发,这里使用python来构建,官方提供了很多DEMO,还有C++DEMO
3.1安装
推荐安装方式有两种,python可以直接pip下载安装包,支持http协议和grpc协议
pip install nvidia-pyindex
pip install tritonclient
去NGC查看dockertag,直接下载docker也是可以的
docker pull nvcr.io/nvidia/tritonserver:20.10-py3-clientsdk
3.2运行
这里有一个简单的官方demo,是图像分类模型的。
3.2.1图像分类demo分析
3.2.2yolo demo分析
核心代码:
#IMAGE MODE
if FLAGS.mode == 'image':print("Running in 'image' mode")if not FLAGS.input:print("FAILED: no input image")sys.exit(1)inputs = []outputs = []inputs.append(grpcclienrent version of the documentat.InferInput('data', [1, 3, 640, 640], "FP32"))outputs.append(grpcclient.InferRequestedOutput('prob'))print("Creating buffer from image file...")input_image = cv2.imread(str(FLAGS.input))if input_image is None:print(f"FAILED: could not load input image {str(FLAGS.input)}")sys.exit(1)input_image_buffer = preprocess(input_image)input_image_buffer = np.expand_dims(input_image_buffer, axis=0)inputs[0].set_data_from_numpy(input_image_buffer)print("Invoking inference...")results = triton_client.infer(model_name=FLAGS.model,inputs=inputs,outputs=outputs,client_timeout=FLAGS.client_timeout)if FLAGS.model_info:statistics = triton_client.get_inference_statistics(model_name=FLAGS.model)if len(statistics.model_stats) != 1:print("FAILED: get_inference_statistics")sys.exit(1)print(statistics)print("Done")result = results.as_numpy('prob')print(f"Received result buffer of size {result.shape}")print(f"Naive buffer sum: {np.sum(result)}")detected_objects = postprocess(result, input_image.shape[1], input_image.shape[0], FLAGS.confidence, FLAGS.nms)print(f"Raw boxes: {int(result[0, 0, 0, 0])}")print(f"Detected objects: {len(detected_objects)}")for box in detected_objects:print(f"{COCOLabels(box.classID).name}: {box.confidence}")input_image = render_box(input_image, box.box(), color=tuple(RAND_COLORS[box.classID % 64].tolist()))size = get_text_size(input_image, f"{COCOLabels(box.classID).name}: {box.confidence:.2f}", normalised_scaling=0.6)input_image = render_filled_box(input_image, (box.x1 - 3, box.y1 - 3, box.x1 + size[0], box.y1 + size[1]), color=(220, 220, 220))input_image = render_text(input_image, f"{COCOLabels(box.classID).name}: {box.confidence:.2f}", (box.x1, box.y1), color=(30, 30, 30), normalised_scaling=0.5)if FLAGS.out:cv2.imwrite(FLAGS.out, input_image)print(f"Saved result to {FLAGS.out}")else:cv2.imshow('image', input_image)cv2.waitKey(0)cv2.destroyAllWindows()
3.3高级特性
4.模型仓库
4.1 仓库结构
组成模型库的目录和文件必须遵循所需的文件路径大小。 假设存储库路径指定为:
$ tritonserver --model-repository=<model-repository-path>
相应的仓库布局必须为:
<model-repository-path>/<model-name>/[config.pbtxt] #(可选)[<output-labels-file> ...] #(可选)<version>/<model-definition-file> #tensorrt eg: model.plan<version>/<model-definition-file>...<model-name>/[config.pbtxt][<output-labels-file> ...]<version>/<model-definition-file><version>/<model-definition-file>......
4.2 版本控制
每个模型在模型存储库中可以具有一个或多个可用版本。 每个版本都存储在其自己的数字命名子目录中,该子目录的名称与模型的版本号相对应。 没有数字命名或名称以零(0)开头的子目录将被忽略。 每个模型配置都指定一个版本策略,该策略控制Triton在任何给定时间提供模型存储库中的哪个版本。
5.模型设置
6.模型调度程序
7.模型管理
Trition server 有三种模型控制模式,分别叫做:NONE.POLL,EXPLICIT
7.1 NONE 模式
此模式为默认控制模式,它在启动时会尝试加载模型储存库中的所有模型,无法加载的模型会被标记为不可用,并且不能用于推断。当服务器开始运行时,模型库的更改将被忽略。
使用 model control endpoint来对服务进行控制是无效的,而且会收到一个错误的回复
可以通过 --model-control-mode=none 这个设置开启NONE模式
7.2 POLL 模式
它在启动时会尝试加载模型储存库中的所有模型,无法加载的模型会被标记为不可用,并且不能用于推断。
当服务器运行的时候,模型库的改动将会被检测到,然后Trition就会尝试去加载和卸载这些改动。但是这些改动不会被立即检测到,因为这个检测是定期轮询的(–repository-poll-secs 这个选项可以控制轮询的时间间隔)。可以通过控制台日志和状态AIP来确认改动是不是真正生效。
使用 model control endpoint也可以确定模型改动是否生效。
可以通过 --model-control-mode=poll 这个设置开启poll模式,同时设置 --repository-poll-secs 为一个非零值。
在Triton运行时更改模型存储库必须谨慎进行,如修改模型存储库中所述。
POLL可以接受如下的模型库改动:
7.2.1 版本改动
通过添加和删除相应的版本子目录,可以从模型中添加和删除版本。 如果有正在进行的请求还没有处理完,Triton将先处理未完成的请求,再进行删除模型。 对删除模型版本的新请求将失败。
7.2.2 模型删除和增加
可以通过删除相应的模型目录从存储库中删除现有模型。 Triton将允许对已删除模型的任何版本进行动态请求。如果有正在进行的请求还没有处理完,Triton将先处理未完成的请求,再进行删除模型。 对删除模型版本的新请求将失败。通过添加新的模型目录,可以将新模型添加到存储库中。
7.2.3 模型配置文件以及标签文件的改动
可以更改模型配置(config.pbtxt),Triton将卸载并重新加载模型以获取新的模型配置。
可以添加,删除或修改为表示分类的输出提供标签的标签文件,Triton会卸载并重新加载模型以拾取新标签。 如果添加或删除了标签文件,则必须同时在模型配置中对输出对应的label_filename属性进行相应的编辑。
7.3 ECPLICIT 模式
启动后,必须使用模型控制协议显式启动所有模型加载和卸载操作。 通过查看模型控制请求的返回值来判断加载或卸载操作的成功或失败。 尝试重新加载已加载的模型时,如果由于任何原因重新加载失败,则已加载的模型将保持不变并保持加载状态。 如果重新加载成功,则新加载的模型将替换已经加载的模型,而该模型的可用性不会受到任何损失。
通过指定–model-control-mode = explicit启用此模型控制模式。 必须在Triton运行时更改模型存储库,如修改模型存储库中所述。