刚入门hadoop,开发环境的搭建估计能把一部分人逼走。我也差点疯了。
估计能看到这篇文章的小伙伴们都饱受cygwin和各种配置文件的折磨了吧?
如果你不想在linux上搭建,又不想安装cygwin。那就继续往下看啦~
步骤:
1. JDK安装(不会的戳这)
2. 下载hadoop2.5.2.tar.gz,或者自行去百度下载。
3. 下载hadooponwindows-master.zip【**能支持在windows运行hadoop的工具】
一、 安装hadoop2.5.2
下载hadoop2.5.2.tar.gz ,并解压到你想要的目录下,我放在D:\dev\hadoop-2.5.2

二、配置hadoop环境变量
1.windows环境变量配置
右键单击我的电脑 –>属性 –>高级环境变量配置 –>高级选项卡 –>环境变量 –> 单击新建HADOOP_HOME,如下图
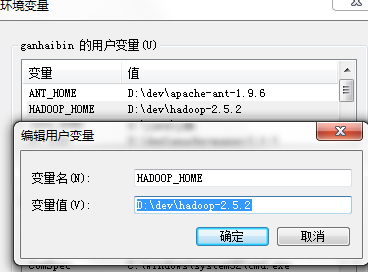
2.接着编辑环境变量path,将hadoop的bin目录加入到后面;
三、修改hadoop配置文件
- 编辑“D:\dev\hadoop-2.5.2\etc\hadoop”下的core-site.xml文件,将下列文本粘贴进去,并保存;
<configuration><property><name>hadoop.tmp.dir</name><value>/D:/dev/hadoop-2.5.2/workplace/tmp</value></property><property><name>dfs.name.dir</name><value>/D:/dev/hadoop-2.5.2/workplace/name</value></property><property><name>fs.default.name</name><value>hdfs://localhost:9000</value></property>
</configuration>2.编辑“D:\dev\hadoop-2.5.2\etc\hadoop”目录下的mapred-site.xml(没有就将mapred-site.xml.template重命名为mapred-site.xml)文件,粘贴一下内容并保存;
<configuration><property><name>mapreduce.framework.name</name><value>yarn</value></property><property><name>mapred.job.tracker</name><value>hdfs://localhost:9001</value></property>
</configuration>3.编辑“D:\dev\hadoop-2.5.2\etc\hadoop”目录下的hdfs-site.xml文件,粘贴以下内容并保存。请自行创建data目录,在这里我是在HADOOP_HOME目录下创建了workplace/data目录;
<configuration><!-- 这个参数设置为1,因为是单机版hadoop --><property><name>dfs.replication</name><value>1</value></property><property><name>dfs.data.dir</name><value>/D:/dev/hadoop-2.5.2/workplace/data</value></property>
</configuration>4.编辑“D:\dev\hadoop-2.5.2\etc\hadoop”目录下的yarn-site.xml文件,粘贴以下内容并保存;
<configuration><property><name>yarn.nodemanager.aux-services</name><value>mapreduce_shuffle</value></property><property><name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name><value>org.apache.hadoop.mapred.ShuffleHandler</value></property>
</configuration>5.编辑“D:\dev\hadoop-2.5.2\etc\hadoop”目录下的hadoop-env.cmd文件,将JAVA_HOME用 @rem注释掉,编辑为JAVA_HOME的路径,然后保存;
@rem set JAVA_HOME=%JAVA_HOME%set JAVA_HOME=D:\java\jdk四、替换文件
下载到的hadooponwindows-master.zip,解压,将bin目录(包含以下.dll和.exe文件)文件替换原来hadoop目录下的bin目录;
五、运行环境
1.运行cmd窗口,执行“hdfs namenode -format”;
2.运行cmd窗口,切换到hadoop的sbin目录,执行“start-all.cmd”,它将会启动以下进程。
成功后,如图:
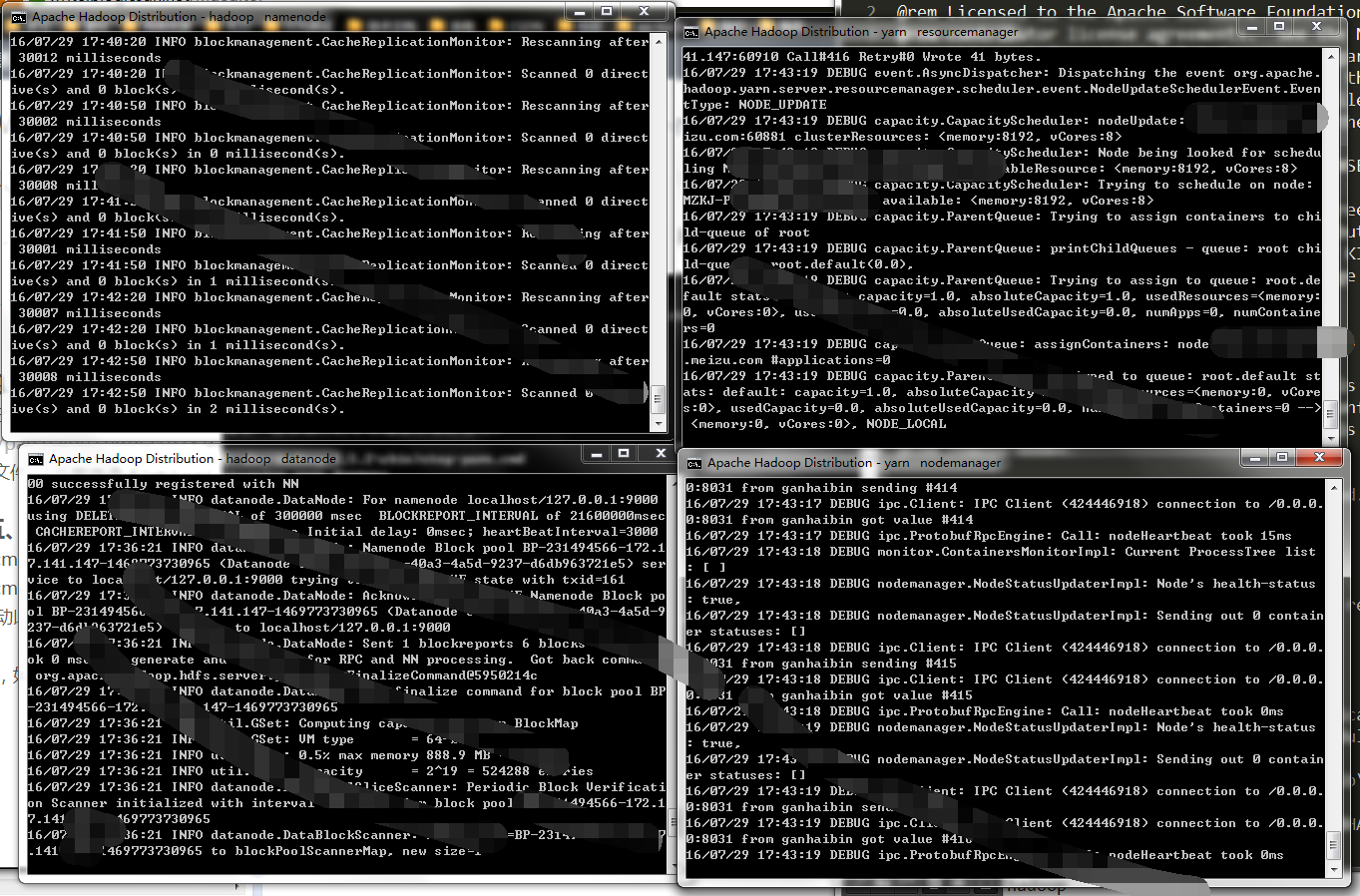
至此,hadoop服务已经搭建完毕。
接下来上传测试,操作HDFS
根据你core-site.xml的配置,接下来你就可以通过:hdfs://localhost:9000来对hdfs进行操作了。
1.创建输入目录
C:\WINDOWS\system32>hadoop fs -mkdir hdfs://localhost:9000/user/C:\WINDOWS\system32>hadoop fs -mkdir hdfs://localhost:9000/user/wcinput2.上传数据到目录
C:\WINDOWS\system32>hadoop fs -put D:\file1.txt hdfs://localhost:9000/user/wcinputC:\WINDOWS\system32>hadoop fs -put D:\file2.txt hdfs://localhost:9000/user/wcinput3.查看文件

大功告成。
附录:hadoop自带的web控制台GUI
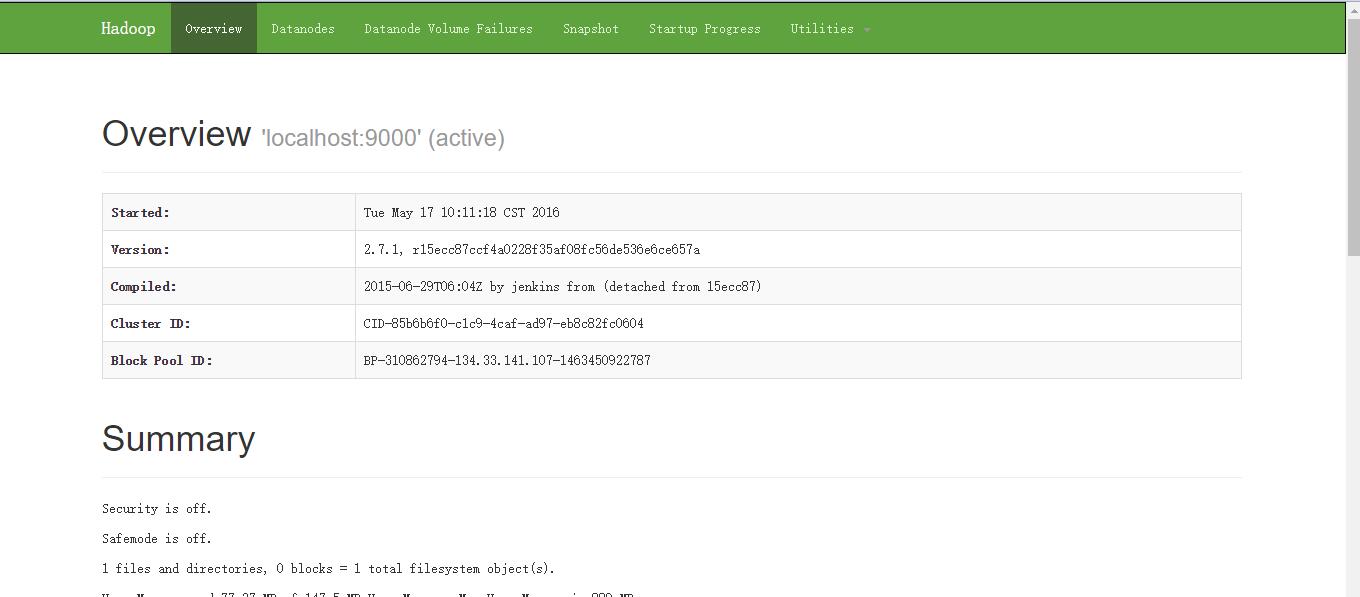
1.资源管理GUI:http://localhost:8088/;
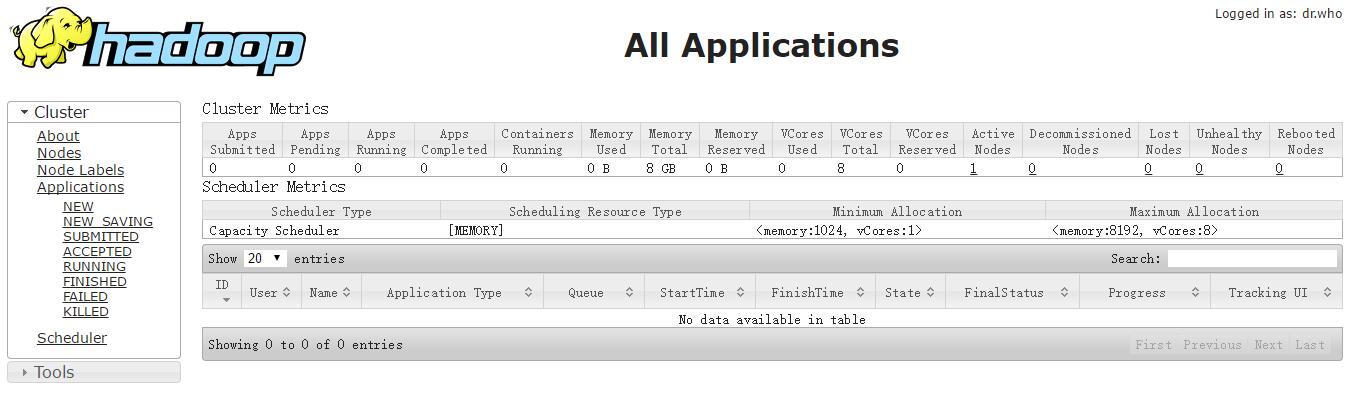
2.节点管理GUI:http://localhost:50070/;