numpy
构造numpy数组
import numpy as np
'''linspace()方法:在某个范围内取等差数列参数:start:起始元素值stop:终止元素值num:元素个数
'''
a = np.linspace(0,100,num=101)
print(a)
matplotlib(python中的一个图形化库)
安装:pip install matplotlib -i https://mirrors.aliyun.com/pypi/simple/
我们使用的是matplotlib下的pyplot模块:
pyplot:
plot():绘制折线图
hist():绘制直方图
x:需要显示的数据
bins:直方的个数/桶数
scatter():散点图
可以设置线的特点:
ls:线条风格
'-', '--', '-.', ':',
lw:线条宽度
color:
label:
例子:
import numpy as npimport matplotlib.pyplot as plta = np.linspace(-6,6,100)b = np.sin(a)c = np.cos(a)'''title:设置图形的标题'''plt.title("sin(x)/cos(x)")'''plot:绘制折线图label:被绘制线的标签,一般情况下没有,显示图例时会用lw:线条宽度ls:线条风格'-','--','-.',':'color:线条颜色:"#r(0-FF)gb"'''plt.plot(a,b,label="sin(x)",lw=3,ls="--",color="#ff8900")plt.plot(a,c,label="cos(x)",lw=2,ls="-.")'''grid():显示背景网格lwlscolor同 plot'''plt.grid(lw = 1, ls="-",color="#006678")'''xlabel:显示横坐标的标签'''plt.xlabel("X-aix")'''ylabel:显示纵坐标的标签'''plt.ylabel("Y-aix")'''ylim(下限value,上限value):设置y轴数值显示范围'''plt.ylim(0,1)'''xlim(下限value,上限value):设置x轴数值显示范围'''plt.xlim(-2,4)#显示图例plt.legend()#显示图形,如果没有show,啥都显示不出来plt.show()如何构建一个机器学习问题
->分析问题是不是适合机器学习
->文件复杂,一般就适合
->如果是优化类问题
->不能通过数学推到快速得到结果的问题
->是不是需要数据集,如何构建数据集
->数据集中要收集哪些数据
->数据集带不带标签
->根据问题的描述对问题进行简单的分类,简单去选择和设计机器学习算法
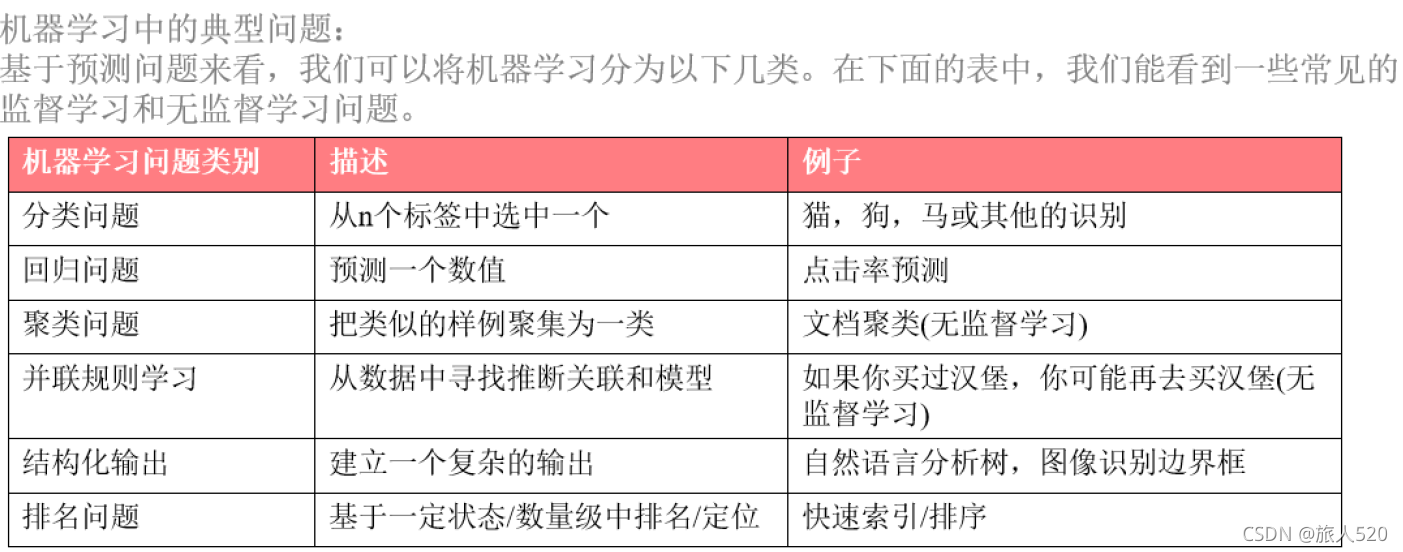
->机器学习问题的分类
问题类型 描述 例子
分类问题 从n个标签中选一个 通用物体识别
回归问题 预测一个数值 点击率预测
聚类问题 把类似的样例聚为一类(输出的是类型) 文档聚类/物品聚类(无监督学习)
并联规则学习问题 从数据中寻找推断关联和模型 如果你买过汉堡,你可能再去买汉堡(无监督学习)
结构化输出 建立一个复杂的输出 翻译
排名问题 基于一定状态/数量级中排名/定位 快速索引/排序
->要想好如何去验证模型的准确型
要设计计算损失率的函数,即要设计好如何求损失率的极值
->确定模型的使用方法
如何让人学会识别猫
这是一个监督学习。
特征值 标签
长度
尾巴和体长的比例
耳朵
叫声 -------------------------------------> 猫
脸型 映射关系
嘴巴
鼻子
从特征值到标签之间的映射关系我们称之为模型
原始数据----------->特征值
提取的过程
我们把提取特征值的过程称之为特征工程。
一般情况下模型的使用:
将原始数据进行特征提取,将提取的特征给模型,得到预测/分类的结果
比较常见的是,特征提取放在模型中。
数据集的收集
如何写一个程序识别猫和猞猁?
体长(cm) 尾巴的长度/体长(0~1) 标签
收集多少条数据?(数据集的大小)
100条
业务不同,收集的数据集大小不同。
没有标准说,解决哪类问题,必须使用多少条记录,但是可以参考别人处理类似问题的数据集大小。
如何提供一个高质量的数据集?
->数据的多样性(要满足正态分布)
->不能有关键数据的丢失(数据的完整性要好)
->特殊的异常数据不能有
->错误的标签不能有
如何获取标签?
->人工贴
优势:
1.贴标签的人对数据很熟悉,对数据的特征很熟悉
2.贴完标签后很容易估计出最优算法
3.可以解决无法从其他数据中生成标签的问题
缺点:
1.效率低下
2.容易出错
->计算机贴
优势:
1.效率高
2.不容易出错
缺点:
1.人对数据不熟悉
2.无法解决原始数据无法生成标签的这种问题
数据集的采样和拆分
->如果数据量较大,且用不了那么大量的数据,如何获取自身需要的数据集
采样:抽样
如何采样?
->采样要遵循什么原则?
->保证数据的多样性
->成比例缩放,然后随机采样
->成比例缩放,使用hash进行采样
->如果数据不均衡,如何保证多样性
如果研究的对象是少数族群,正常采样无法获得足够的数据,此时,可以提高少数族群在整个族群中的占比,
利用新的占比采样,以获取更多的学习数据。(下采样)
要想得到正确的模型,就必须将学到的少数情况还原到原本的比例上,这个过程称之为向上加权。
->拿到采样后的数据,我们有两个用途:
用来训练的数据:训练集
用来测试的数据:测试集
一般训练集 > 测试集
7 3
8 2
200
8 2
160 40
数据集拆分需要满足怎样的条件:
1.测试集和训练集的 2:8
2.满足测试集和训练集的数据多样性,集每个集合尽量满足正态分布
3.测试集不能和训练集雷同
如何拆分数据集:
根据业务拆分
常用的手段:
1.随机拆分
2.基于随机的hash拆分
数据的转换
计算机在处理数据时,对于浮点数,字符串和图片,音频来说,处理速度非常慢,并不适合大量数据处理。
如果需要处理大量以上类型数据,数据转换就是一个不可获取的手段。
->数值数据转换
->正则化
->线性缩放
->数据呈现一定规律性,但是不是整数,或者整数值较大时使用。
x’ = (x - xmin) / (xmax - xmin)
->裁剪
->数据中存在大量异常值,可以将数据特征进行裁剪,将异常的值归为一类
if x > xmax , x' = xmax
if x < xmin , x' = xmin
->对数缩放
->当数据呈现幂律分布时,需要使用对数缩放,将其缩放在一个好表示的范围内
x' = log(x)
->标准分数
当数据中存在异常值,但是异常值没有达到裁剪的程度,就可以使用标准分数。
x' = (x-μ)/σ
μ和σ都是根据数据特点,自己设计出来的
->分桶
数据呈现一种类别性的时候使用
->等距桶
数据分布均匀时
->等量桶
数据分布不均匀
->非数值数据转换
->枚举
将字符串转换为整数,好操作,代表一种类别。(适用于类别较少时)
->符号表
->公共溢出区
字符串较多,但是顺序查找依然较快时(且不在符号表范围内的东西较少,或者说异常值较少时)
->hash
字符串非常多,且顺序查找浪费时间,有大量异常值时使用
案例:
->如何在招聘中获得高薪
BS MS
笔试(分数) 面试(分数) 薪资(整数)
10 10 5000-15000
BS <= 3 || MS <= 3 0
10 <= BS+MS <= 20
(BS + MS - 10) * 1000 + 5000
笔试成绩和哪些数据相关
->知识掌握程度 枚举 权重7% 0.7*a
A:10
B:8
C:6
D:3
->刷题的数目 整数(0-3000) 权重5% 5/3000*b
->刷题的类型种类 整数 权重15% 6/15*c
->刷题的难易程度 枚举 权重3%
A:10 0.3*d
B:6
C:3
->刷题的正确率 小数 权重70% 70*e
Kx + B = BS
K(0.7*a + 5/3000*b + 0.4 * c + 0.3 *d + 70 *e) + B = BS
目的是求K和B