导包
%matplotlib inline
from skmultiflow.data import FileStream
from skmultiflow.trees import RegressionHoeffdingTree
from skmultiflow.evaluation import EvaluatePrequential
import pandas as pd
import sys
sys.setrecursionlimit(100000) # 用来防止内存不足
读取数据
默认最后一列为标签:
stream = FileStream("test.csv")
数据流的初始化
stream.prepare_for_use()
初始化RegressionHoeffdingTree模型
rht = RegressionHoeffdingTree()
初始化评价器
和分类的不同的是参数中metrics设置,具体的值可以在官方文档查看
evaluator = EvaluatePrequential(max_samples=100000, n_wait=1, pretrain_size=1000, max_time=100000,show_plot=True,metrics=['mean_square_error', 'true_vs_predicted'],output_file='results1.csv'
)
运行模型
evaluator.evaluate(stream=stream, model=rht)
于是出现了这样的动态图(这里不动哈哈)

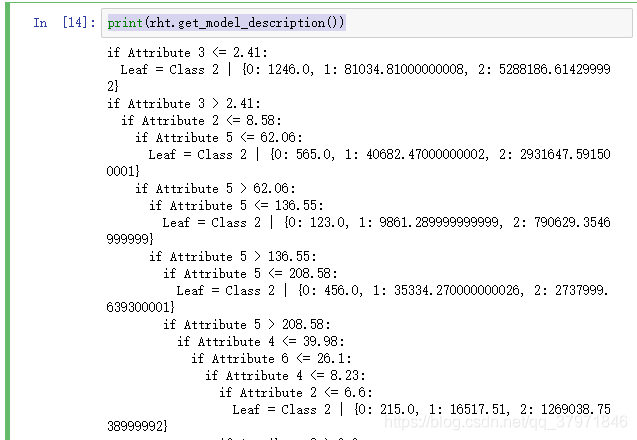
查看训练出来的树的细节
print(rht.get_model_description())
打印出这样的样子(图未截完)
模型的序列化
在scikit multiflow中,支持使用pickle方法(pickle.dumps, pickle.loads)来进行保存和读取模型。
暂不支持joblib方法。
import pickle
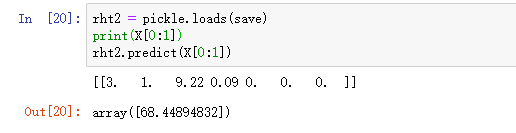
with open('save','wb') as f:pickle.dump(rht,f)加载模型并进行预测
with open('save','rb') as f:rht2 = pickle.loads(save)
print(X[0:1])
rht2.predict(X[0:1])
结果如下: