head(n):查看前n行
import pandas as pd
import numpy as np
df=pd.read_csv('D:/pandas活用/pandas_for_everyone-master/data/gapminder.tsv',sep='\t')
print(df.head())
print(df.head(10))#print(df.head(n=10))输出结果如下

tail(n):查看后n行
import pandas as pd
import numpy as np
df=pd.read_csv('D:/pandas活用/pandas_for_everyone-master/data/gapminder.tsv',sep='\t')
print(df.tail())
print(df.tail(10))#print(df.tail(n=10))
loc:使用索引标签和列名获取子集
import pandas as pd
import numpy as np
df=pd.read_csv('D:/pandas活用/pandas_for_everyone-master/data/gapminder.tsv',sep='\t')
print(df.loc[0,'year'])#使用中括号选择行列,使用逗号分割
print(df.loc[0:10,['country','year']])#如需要选取多行或多列,需要传入列表作为值,这里的索引标签恰好是索引号,无需使用列表
print(df.loc[1700:,'country'])#使用冒号:选取从第几到第几,如[:10,:]选择从第一行开始到第十行,后面的:两边都没有指定则默认全部列
print(df.loc[1700:,:])
iloc:使用索引号获取子集
import pandas as pd
import numpy as np
df=pd.read_csv('D:/pandas活用/pandas_for_everyone-master/data/gapminder.tsv',sep='\t')
print(df.iloc[0,2])
print(df.iloc[0:10,[0,2]])
print(df.iloc[1700:,0])
print(df.iloc[1700:,:])
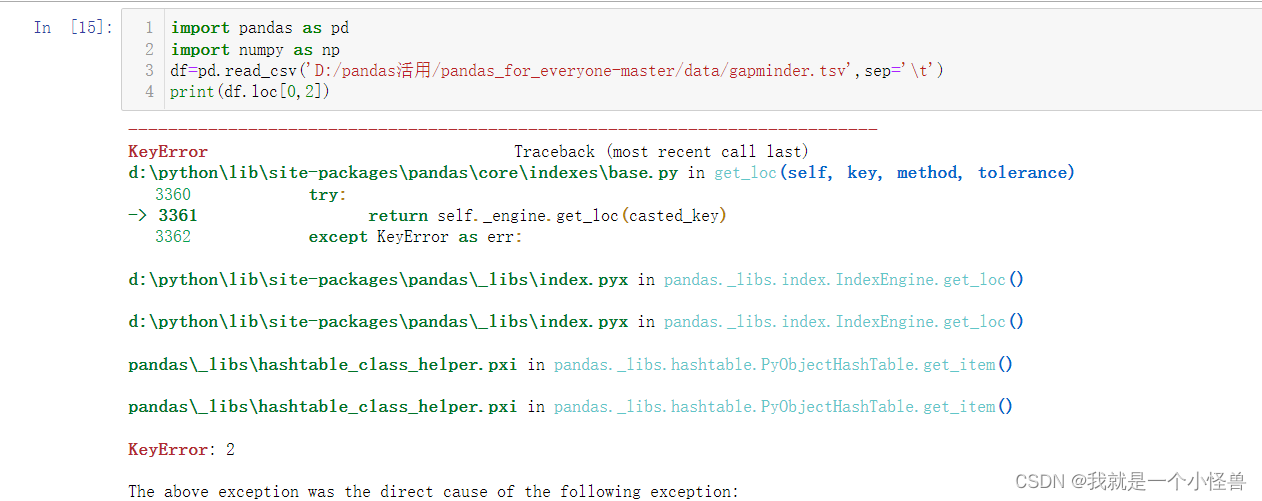
loc和iloc的区别:
通过上面的运行我们可以看出,一个是通过索引标签和列名进行选择,一个是通过行和列确切的索引号即具体第几个的位置来进行索引,这个不能搞混,否则如下报错,因为我们如下使用loc,但是传给了它的列名是2,因此它是找不到名字为2的列的,如果给iloc传入一个列名而非索引号,也会出现错误