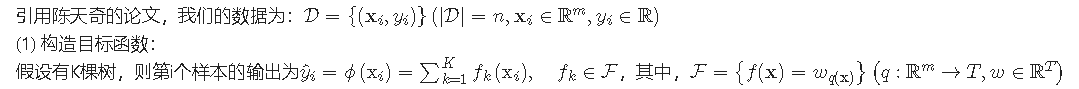- 11-6��һ����ȫ������
#����ȫ�ֳ�����
batch_size=64
lr=4e-5
dropout=0.15
epoch=5
max_length=512 #���ӳ���
sent_hidden_size=512 #���ز�ά��
sent_num_layers=2
lstm_dropout=0.5
-------------------------------
***** Running training epoch 1 *****
Epoch 001 | Step 0562/2813 | Loss 0.3679 | Time 552.0787
Learning rate = 3.733617727218865e-05
Epoch 001 | Step 1124/2813 | Loss 0.2790 | Time 1104.2936
Learning rate = 3.46723545443773e-05
Epoch 001 | Step 1686/2813 | Loss 0.2409 | Time 1656.4097
Learning rate = 3.2008531816565946e-05
Epoch 001 | Step 2248/2813 | Loss 0.2179 | Time 2208.5104
Learning rate = 2.9344709088754594e-05
Epoch 001 | Step 2810/2813 | Loss 0.2030 | Time 2760.7820
Learning rate = 2.6680886360943242e-05
val_accuracy:0.9570
Average val loss: 0.1344
time costed=2877.61446s
***** Running training epoch 2 *****
Epoch 002 | Step 0562/2813 | Loss 0.1144 | Time 552.7953
Learning rate = 2.4002843938855314e-05
Epoch 002 | Step 1124/2813 | Loss 0.1112 | Time 1105.5705
Learning rate = 2.1339021211043965e-05
Epoch 002 | Step 1686/2813 | Loss 0.1079 | Time 1658.3458
Learning rate = 1.8675198483232613e-05
Epoch 002 | Step 2248/2813 | Loss 0.1077 | Time 2211.1175
Learning rate = 1.6011375755421257e-05
Epoch 002 | Step 2810/2813 | Loss 0.1058 | Time 2764.0287
Learning rate = 1.3347553027609907e-05
val_accuracy:0.9638
Average val loss: 0.1112
time costed=2880.78902s -------------------------------
***** Running training epoch 3 *****
Epoch 003 | Step 0562/2813 | Loss 0.0776 | Time 553.5801
Learning rate = 1.0669510605521983e-05
Epoch 003 | Step 1124/2813 | Loss 0.0764 | Time 1106.9812
Learning rate = 8.005687877710629e-06
Epoch 003 | Step 1686/2813 | Loss 0.0753 | Time 1660.3180
Learning rate = 5.341865149899278e-06
Epoch 003 | Step 2248/2813 | Loss 0.0745 | Time 2213.8330
Learning rate = 2.6780424220879254e-06
Epoch 003 | Step 2810/2813 | Loss 0.0733 | Time 2767.0747
Learning rate = 1.4219694276573055e-08
val_accuracy:0.9665
Average val loss: 0.1060
time costed=2883.86751s
�����ύ���0.9602��bert��ģ����0.9612��
- ѧϰ������lr=1e-5����ѵ������epoch
***** Running training epoch 1 *****
/usr/local/lib/python3.7/dist-packages/ipykernel_launcher.py:23: UserWarning: To copy construct from a tensor, it is recommended to use sourceTensor.clone().detach() or sourceTensor.clone().detach().requires_grad_(True), rather than torch.tensor(sourceTensor).
Epoch 001 | Step 0562/2813 | Loss 0.0686 | Time 549.1122
Learning rate = 9.334044318047163e-06
Epoch 001 | Step 1124/2813 | Loss 0.0704 | Time 1098.4061
Learning rate = 8.668088636094325e-06
Epoch 001 | Step 1686/2813 | Loss 0.0705 | Time 1647.6734
Learning rate = 8.002132954141487e-06
Epoch 001 | Step 2248/2813 | Loss 0.0705 | Time 2196.8016
Learning rate = 7.3361772721886485e-06
Epoch 001 | Step 2810/2813 | Loss 0.0698 | Time 2746.1583
Learning rate = 6.6702215902358104e-06
val_accuracy:0.9778
Average val loss: 0.0681
time costed=2863.14666s -------------------------------
***** Running training epoch 2 *****
Epoch 002 | Step 0562/2813 | Loss 0.0551 | Time 550.6488
Learning rate = 6.0007109847138286e-06
Epoch 002 | Step 1124/2813 | Loss 0.0562 | Time 1101.2804
Learning rate = 5.334755302760991e-06
Epoch 002 | Step 1686/2813 | Loss 0.0575 | Time 1651.8084
Learning rate = 4.668799620808153e-06
Epoch 002 | Step 2248/2813 | Loss 0.0578 | Time 2202.4281
Learning rate = 4.002843938855314e-06
Epoch 002 | Step 2810/2813 | Loss 0.0574 | Time 2753.4404
Learning rate = 3.3368882569024767e-06
val_accuracy:0.9774
Average val loss: 0.0663
time costed=2869.31657s -------------------------------
***** Running training epoch 3 *****
Epoch 003 | Step 0562/2813 | Loss 0.0457 | Time 551.8984
Learning rate = 2.6673776513804957e-06
Epoch 003 | Step 1124/2813 | Loss 0.0472 | Time 1104.0534
Learning rate = 2.001421969427657e-06
Epoch 003 | Step 1686/2813 | Loss 0.0471 | Time 1656.2757
Learning rate = 1.3354662874748195e-06
Epoch 003 | Step 2248/2813 | Loss 0.0475 | Time 2208.2137
Learning rate = 6.695106055219813e-07
Epoch 003 | Step 2810/2813 | Loss 0.0476 | Time 2760.1161
Learning rate = 3.5549235691432638e-09
val_accuracy:0.9791
Average val loss: 0.0634
time costed=2876.76017s
�����ύ���0.9615����bert��ģ����0.9612��
- ������ѡ��
#����ȫ�ֳ�����
batch_size=64
lr=4e-5
dropout=0.15
epoch=5
max_length=256 #���ӳ���
sent_hidden_size=256 #���ز�ά��
sent_num_layers=2
lstm_dropout=0.5
ģ���������
***** Running training epoch 1 *****/usr/local/lib/python3.7/dist-packages/ipykernel_launcher.py:23: UserWarning: To copy construct from a tensor, it is recommended to use sourceTensor.clone().detach() or sourceTensor.clone().detach().requires_grad_(True), rather than torch.tensor(sourceTensor).Epoch 001 | Step 0562/2813 | Loss 0.4196 | Time 208.1415Learning rate = 3.840170636331319e-05Epoch 001 | Step 1124/2813 | Loss 0.3100 | Time 416.2209Learning rate = 3.680341272662638e-05Epoch 001 | Step 1686/2813 | Loss 0.2625 | Time 624.3412Learning rate = 3.520511908993957e-05Epoch 001 | Step 2248/2813 | Loss 0.2347 | Time 832.3558Learning rate = 3.360682545325276e-05Epoch 001 | Step 2810/2813 | Loss 0.2172 | Time 1040.4076Learning rate = 3.2008531816565946e-05val_accuracy:0.9538Average val loss: 0.1451time costed=1085.77403s -------------------------------***** Running training epoch 2 *****Epoch 002 | Step 0562/2813 | Loss 0.1188 | Time 207.9437Learning rate = 3.0401706363313194e-05Epoch 002 | Step 1124/2813 | Loss 0.1172 | Time 415.8373Learning rate = 2.880341272662638e-05Epoch 002 | Step 1686/2813 | Loss 0.1156 | Time 623.8603Learning rate = 2.7205119089939568e-05Epoch 002 | Step 2248/2813 | Loss 0.1134 | Time 831.8518Learning rate = 2.5606825453252756e-05Epoch 002 | Step 2810/2813 | Loss 0.1117 | Time 1039.8944Learning rate = 2.4008531816565945e-05val_accuracy:0.9585Average val loss: 0.1339time costed=1085.38992s -------------------------------***** Running training epoch 3 *****Epoch 003 | Step 0562/2813 | Loss 0.0835 | Time 208.6672Learning rate = 2.240170636331319e-05Epoch 003 | Step 1124/2813 | Loss 0.0815 | Time 417.3365Learning rate = 2.0803412726626378e-05Epoch 003 | Step 1686/2813 | Loss 0.0822 | Time 626.0183Learning rate = 1.9205119089939566e-05Epoch 003 | Step 2248/2813 | Loss 0.0827 | Time 834.7226Learning rate = 1.7606825453252755e-05Epoch 003 | Step 2810/2813 | Loss 0.0809 | Time 1043.4659Learning rate = 1.6008531816565944e-05val_accuracy:0.9606Average val loss: 0.1245time costed=1089.08141s -------------------------------***** Running training epoch 4 *****Epoch 004 | Step 0562/2813 | Loss 0.0616 | Time 208.1838Learning rate = 1.440170636331319e-05Epoch 004 | Step 1124/2813 | Loss 0.0611 | Time 416.2914Learning rate = 1.2803412726626378e-05Epoch 004 | Step 1686/2813 | Loss 0.0605 | Time 624.3471Learning rate = 1.1205119089939567e-05Epoch 004 | Step 2248/2813 | Loss 0.0598 | Time 832.3887Learning rate = 9.606825453252755e-06Epoch 004 | Step 2810/2813 | Loss 0.0594 | Time 1040.5442Learning rate = 8.008531816565944e-06val_accuracy:0.9624Average val loss: 0.1255time costed=1085.98783s -------------------------------***** Running training epoch 5 *****Epoch 005 | Step 0562/2813 | Loss 0.0443 | Time 208.2642Learning rate = 6.401706363313189e-06Epoch 005 | Step 1124/2813 | Loss 0.0453 | Time 416.4400Learning rate = 4.803412726626378e-06Epoch 005 | Step 1686/2813 | Loss 0.0451 | Time 624.6992Learning rate = 3.2051190899395668e-06Epoch 005 | Step 2248/2813 | Loss 0.0444 | Time 832.7519Learning rate = 1.6068254532527552e-06Epoch 005 | Step 2810/2813 | Loss 0.0446 | Time 1040.8253Learning rate = 8.531816565943832e-09val_accuracy:0.9630Average val loss: 0.1282time costed=1086.39623s
-
��һ��batch_size=32,bert_lr=5e-5,����lr=2.5e-4��ѵ����lossһֱ�½���0.03�����Լ�loss�ڵڶ���epoch�Ϳ�ʼһֱ��val_loss=0.2���ң�acc��0.9460������
-
�ڶ���batch_size=32,bert_lr=5e-5������lr=2.5e-4��bert�����dropout������0.1����0.3��scheduler����һ��epoch��warmup��������warmup�Dz��ǵڶ���epoch��lr��ߣ���������������͵㣩
- �۲췢�ֵ�һ��epoch��lr��͵����ʱ��epoch��5��loss�������½�(2.54�C>1.02)��
- �ڶ���epoch��loss�½��dz�����0.2623�C>0.2381��
- ��ȵ����bert_lr=5e-5,������2e-5��test_batch_size=32��train_batch_size=4��dropout=0.15��bert��lstm���Σ�,û��warmup��epoch=2
ԭ��һֱ�õ�15000�����ݣ��ѹ�ȷ����ô��
���ݵ��Σ�
-
#����ȫ�ֳ�����
batch_size=64
lr=4e-5
����lr=lr*4
dropout=0.15
epoch=5
max_length=256 #���ӳ���
sent_hidden_size=512 #���ز�ά��
sent_num_layers=2
lstm_dropout=0.5

-
��3epoch��������ȫ��ѵ������һ��epoch���ύ��
�÷�0.9621