
相对于昨天的HDFS,YARN明显难一些。
听过大数据的人最多,听过Hadoop的次之,听过YARN的再次之。
本文参考官方文档以及百度百科,去除了一些跟上一代的资源调度管理系统的对比,只求略懂一二,为后面的MapReduce任务铺路。
YARN,Ye Another Resource Negotiator――Hadoop的集群资源管理系统。
它负责以下事情:
- Resource Management 资源管理
- Job Scheduling / Monitoring 任务调度、监控
YARN本身非常复杂,详细的文档请参考官方:
https://hadoop.apache.org/docs/current/hadoop-yarn/hadoop-yarn-site/YARN.html
开始吧!
“资源”是什么?
内存、CPU、硬盘、网络……
YARN把这些信息封装起来,用一个概念来表示――Container(容器)
一般来说,1个Container可以运行一个任务(task)
日后Container的内容可能会更加丰富,比如显卡或专用处理器也可能会加入(人工智能改变世界)
Conainer是一个动态资源划分单位,根据app的需求动态产生。我理解它更像一台台虚机,可以独立执行代码(task)。
以下是别人的博客:
Container的一些基本概念和工作流程如下:
(1) Container是YARN中资源的抽象,它封装了某个节点上一定量的资源(CPU和内存两类资源)。它跟Linux Container没有任何关系,仅仅是YARN提出的一个概念(从实现上看,可看做一个可序列化/反序列化的Java类)。
(2) Container由ApplicationMaster向ResourceManager申请的,由ResouceManager中的资源调度器异步分配给ApplicationMaster;
(3) Container的运行是由ApplicationMaster向资源所在的NodeManager发起的,Container运行时需提供内部执行的任务命令(可以使任何命令,比如java、Python、C++进程启动命令均可)以及该命令执行所需的环境变量和外部资源(比如词典文件、可执行文件、jar包等)。
另外,一个应用程序所需的Container分为两大类,如下:
(1) 运行ApplicationMaster的Container:这是由ResourceManager(向内部的资源调度器)申请和启动的,用户提交应用程序时,可指定唯一的ApplicationMaster所需的资源;
(2) 运行各类任务的Container:这是由ApplicationMaster向ResourceManager申请的,并由ApplicationMaster与NodeManager通信以启动之。
以上两类Container可能在任意节点上,它们的位置通常而言是随机的,即ApplicationMaster可能与它管理的任务运行在一个节点上。
一般而言,每个Container可用于运行一个任务。ApplicationMaster收到一个或多个Container后,再次将该Container进一步分配给内部的某个任务,一旦确定该任务后,ApplicationMaster需将该任务运行环境(包含运行命令、环境变量、依赖的外部文件等)连同Container中的资源信息封装到ContainerLaunchContext对象中,进而与对应的NodeManager通信,以启动该任务。
来自:
http://dongxicheng.org/mapreduce-nextgen/understand-yarn-container-concept/
没看懂?没关系,略过就好,看完之后,会更容易理解
接下来,我们从上到下地介绍整个框架。
整个系统一个:ResourceManager (RM),负责整个系统的资源管理和分配。由2部分组成:Scheduler(调度器)、ApplicationsManager (ASM)
每个App一个:ApplicationMaster (App Mstr 或者 AM)
每个节点一个:NodeManager (NM)
放图:
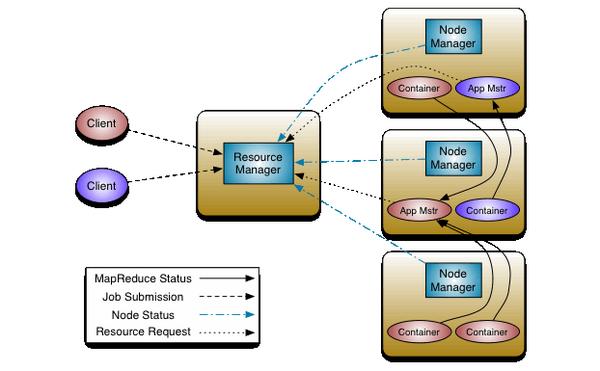
左边2个Client,对应2种颜色,粉色、紫色,每个Client跑了一个App。(右边2个App Mstr)
中间这个是RM,全局唯一。
左边有3个节点,3个NM,每个节点2个Container.从上到下:
- 第一个节点,有2个Container(一组资源),其中一个跑了一个App Mstr,但是箭头可以看出,这2个Container并不属于一个App
- 第二个节点,跟第一个节点刚好反过来
- 第三个节点,有2个粉色App的Container,没有跑第三个App Mstr
再来看看图里面的箭头:
- 每个NM都要向RM发送本节点的情况(Node Status)
- 左边2个Client分别向RM提交Job (Job Submission)
此时RM的ASM会起2个App Mstr,并在它们运行失败时重启它
- App Mstr向RM 发送资源申请 (Resource Request)
RM只负责监控App Mstr,并不负责App Mstr内部任务的容错,这是App Mstr的事儿,它会将一个Job分解为多个task,并与RM协调执行所需要的Container,将任务分配给Container。App Mstr将与NM一起安排、执行、监控这些Container
- 每个Container向App Mstr发送 MapReduce Status (MapReduce 任务的状态)
Okay,到这里,你应该已经对整个集群的工作方式,有了大概的了解。
接下来是一些细致的介绍。
RM的Secheduler:
调度器,它会根据一些条件限制,比如capacities(容量), queues(队列)(每个队列分配一定的资源,最多执行一定数量的作业。队列是一个挺重要的概念,我相信以后还会遇到),将系统的资源(Container)分配给 正在运行 的App。
Secheduler的工作是纯粹的,它仅分配Container。不负责对App监控、跟踪、失败重启等等
RM的ApplicationsManager:
ASM,它会做Secheduler不做的事情,负责管理整个系统中,所有的App,包括了:
- Job Submision
- 与Secheduler协商,拿出这个App的第一个Container来运行该App的App Mstr
- 在App Mstr挂掉时,重启它
(但它也只面向App Mstr,不管App Mstr下面Container的情况)
App Mstr:
- 与Secheduler协商合适的Container
- 跟踪他们的状态
- 监控它们的进程
- 与NM通信以启动/停止Container
- (官网原话:ApplicationMaster has the responsibility of negotiating appropriate resource containers from the Scheduler, tracking their status and monitoring for progress.)
NM:
每个节点上的资源和任务管理器,它负责:
- 定时向RM汇报本节点上的Container使用情况、以及各个Container的运行情况
- 接受并处理来自AM的Container启动/停止等各种请求
YARN 的几个概念:
- ResourceManager
- ApplicationMaster
- NodeManager
1、ResourceManager
- 负责接受客户端提交的 job,分配和调度资源
- 启动 ApplicationMaster,判断 job 所需资源
- 监控 ApplicationMaster,在其失败的时候进行重启
- 监控 NodeManager
2、ApplicationMaster
- 为 MapReduce 类型的程序申请资源,并分配任务
- 负责相关数据的切分
- 监控任务的执行及容错
3、NodeManager
- 管理单个节点的资源,向 ResourceManager 进行汇报
- 接收并处理来自 ResourceManager 的命令
- 接收并处理来自 ApplicationMaster 的命令
MapReduce 编程模型
- 场景:输入一个大型文件,通过 split 将其分成多个文件分片
- Map:每个文件分片由单独的机器进行处理,这就是 Map 方法
- Reduce:将各个机器的计算结果进行汇总,得到最终的结果,这就是 Reduce 方法
Map 任务处理
- 读取输入文件的内容,解析成键值对,把文件的每一行解析成键值对,每个键值对调用一次 map 函数;(Input)
- 写自定义的逻辑,对输入的键值对进行处理,转换成新的键值对输出;(Map)
- 对不同分区的数据,按照键(key)进行排序和分组,key 相同的值(value)放到一个集合中;(Sort -> Combine)
- 把输出的键值对(此时只是中间结果)按照 key 的范围进行分区处理;(Partition)
- 分组后的数据进行 reduce 处理。
Reduce 任务处理
- 对多个 map 任务的输出,按照不同分区,通过网络 copy 到不同的 reduce 节点;
- 对多个 map 任务的输出进行合并和排序,自定义 reduce 函数的逻辑,对输入的键(key)和值(value)进行处理,转换成新的键值对输出;(Reduce)
- 把 reduce 的输出保存到文件中。(Output)
MapReduce 的整个工作流程可以归结为:
Input -> Map -> Sort -> Combine -> Partition -> Reduce -> Output
写完以后,觉得Container的概念非常复杂,不过我觉得没有必要纠结于一个点废太多时间,日后自然会懂的。
希望对你有帮助。
转自:知乎 大鱼和葛尧的回答
链接:https://zhuanlan.zhihu.com/p/33198500
链接:https://zhuanlan.zhihu.com/p/31810137