论文链接:https://arxiv.org/abs/1907.12273
本文是语义分割领域的一篇新作,作者运用interlace机制将密集相似矩阵A分解为两个稀疏相似矩阵AL和AS的乘积。该方法在Cityscapes/ADE20K/LIP/PASCAL VOC 2012/COCO等数据集上与PSPNet/PSANet、以及较新的DANet/CCNet对比,结果表明该网络能够节省大量的内存和计算量,特别是高分辨率特征图的时候,并且在六大数据集上也取得了不错的效果。
Abstract
本文提出了一种基于自注意力机制的称为交叉稀疏自注意力方法(interlaced sparse self-attention)来提升语义分割中的效率。该方法的主要思想是将密集相似矩阵分解为两个稀疏相似矩阵的乘积。用两个连续的注意模块,每个模块估算一个稀疏的相似矩阵。第一个注意模块用来估计有着较长空间间距距离的position子集的相似性,第二个注意模块用来估计有着较短空间间隔距离的position子集的相似性。设计这两个注意模块使得每个位置都能接收到来自其他所有位置的信息。与一些原始的自注意力模型相比,我们的方法减少了计算力和内存复杂度,特别是处理高分辨率特征图时。我们通过实验验证了该方法在六个具有挑战性的语义分割基准上的有效性。
Introduction
长距离依赖(Long-range dependency)在各种计算机视觉任务中都有着基本作用。深度卷积神经网络通过叠加多个卷积层获得长距离依赖。根据Shen等人的工作,我们需要叠加近百个连续的3*3卷积层来获得256*256输入的任意两个位置的依赖关系。由此可见,通过叠加的方式获得依赖关系会导致网络的加深,实际价值不大。
最近的自注意力(或者非局部non-local)机制提出了一种模型用来获得长距离依赖,它通过所有输入位置计算输出位置的上下文信息实现。采用一个简单的自注意力机制层可以获得任意两个输入位置的依赖关系。自注意力机制被用于视频理解、目标检测、语义分割和行人再识别等视觉任务中。假设输入尺寸大小为N,则自注意力机制的计算复杂度大约为O(N^2),若是目标检测或者语义分割等高分辨率的输入那个任务的成本就会很大。
高分辨率的输入在许多视觉任务中是获得较好表现的基础,但是会占用大量的计算和内存成本,阻碍自注意力机制在实际应用中的潜在好处。例如最近的工作DANet/OCNet/CFNet等网络均采用自注意力机制用于语义分割,至少需要64G内存的GPU训练例如8的小batch size。总的来说,我们认为,如何降低自我注意机制的计算和内存成本,对于各种对计算和内存成本敏感的视觉任务具有很大的实用价值。
考虑到计算每个输出位置和所有输入位置的相似性需要大量的计算和内存成本从而得到密集相似矩阵A,我们提出了一种简单而有效的方法将密集相似矩阵A的计算分解为包括AL和AS在内的两个稀疏相似矩阵的乘积。我们从理论上证明了该方法的计算复杂度比传统的自注意机制要小得多,从下图中可以看出GPU内存消耗(MB)、计算成本(GFLOPs)和时间成本(ms)的比较:

我们的方法是受到交错机制的启发。首先,我们将所有的输入位置分为Q个大小相等的子集,每个子集中包含P个位置(N=P*Q)。对于长距离注意模块,我们从每一个子集中采样一个位置构建一个含有Q个位置的新子集(因为原先划分为Q个子集,每个子集拿出一个位置,就有了Q个位置),根据这样采样策略能够获得P个这样的子集。这样每个构造子集中的位置是长空间间隔距离的位置。我们在每个子集上采用自注意力机制计算稀疏相似性矩阵AL。对于短距离注意模块,直接在原始的Q个子集上(相当于在long-range模块permute之后再permute回来)计算稀疏相似性矩阵AS。融合这两个机制,便可以将信息从每个输入位置传播到所有输出位置。

本文的主要贡献如下:
- 提出了交错稀疏自注意力方法更有效的捕获长距离依赖;
- 证明了交错稀疏自注意力方法在语义分割上的有效性,与传统的自注意力机制模型相比得到了类似的或者更好分割效果;
- 与其他机制(如CNGL/RCCA)相比较说明该方法的优点。
Approch
这部分回顾自注意力机制并说明interlaced sparse self-attention方法的细节,并展示了基于PyTorch上的短代码。
Self-attention
自注意力机制可以用下面两个公式来描述:
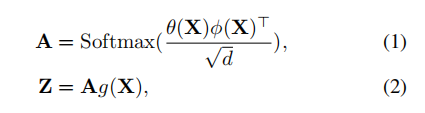
式中X是输入的特征图,A是密集相似性矩阵,Z是输出的特征图。我们将X,Z变量reshape成(N*C),A(N*N),其中N是像元的个数,C是波段数。A中的每个元素就记录了任意两个位置的相似性。自注意力机制用了两个不同的转换函数θ和φ将输入变量转换成低维空间,θ(X)、φ(X)的形状是(N*(C/2)),低维空间的点积用来计算密集相似矩阵A。缩放因子d被用于解决Softmax函数中的小梯度问题并且d=C/2。自注意力机制用g函数学习更好的嵌入,g(X)∈(N*C)。
Interlaced Sparse Self-Attention
本文提出的交错稀疏自注意力的核心是将密集相似矩阵A采用自注意力机制分解为两个稀疏相似矩阵AL和AS的乘积。我们说明如何利用长距离注意模块计算AL和短距离模块计算AS。通过长短距离模块的结合,我们能够所有的输入位置传递信息到每个输出位置。
Long-range Attention 的重点是在具有较长空间距离的子集上应用Self-attention。如Figure3,将输入的特征图X重新排列计算XL=Permute(X)。然后将XL划分为P个块每个块包含Q个相邻的位置(N=P*Q):![]() ,每个
,每个![]() 是XL的(Q*C)大小的子集。在每个
是XL的(Q*C)大小的子集。在每个![]() 上用self-attention:
上用self-attention:

(Q*Q)大小的![]() 是建立在
是建立在![]() 上的小的相似矩阵,(Q*C)大小的
上的小的相似矩阵,(Q*C)大小的![]() 随之更新。其他所有参数与self-attention中保持一致。
随之更新。其他所有参数与self-attention中保持一致。
最后,将所有不同块中的![]() 融合得到输出
融合得到输出![]() 。长距离注意模块的AL如下图所示,可以看到所有对角位置的均为非零。
。长距离注意模块的AL如下图所示,可以看到所有对角位置的均为非零。

Short-range Attention模块与Long-range attention模块相似。
Complexity 假定输入的特征图大小是H*W*C,与self-attention机制对比分析计算、内存成本如下图:

Results
主体网络采用ResNet-50/ResNet-101,与其他self-attention网络一样去掉最后两个下采样层并换成空洞卷积,这样输出的特征图便是输入特征图的1/8大小。并采用3*3卷积对输出特征图减少波段。然后采用interlaced sparse self-attention模块于特征图上得到输出的特征图Z(512*H*W),并直接在Z上预测分割图。
在Cityscapes上的结果:

在ADE20K上的结果:

在Cityscapes和ADE20K数据集上的效果:

实例分割效果:

效率比较:
