目录
一、模拟退火算法(Simulated annealing algorithm,SA)
1.SA的基本理论
2.SA求解函数最值
3.SA工具箱
二、遗传算法(Genetic Algorithm,GA)
1.GA的理论基础
2.GA求解函数最值
3.GA工具箱
三、粒子群算法(Particle Swarm Optimization,PSO)
1.PSO算法相关知识
2.PSO算法设计
3.PSO算法
4.particleswarm粒子群函数
5.PSO算法进阶应用
(1)求解方程组
(2)多元函数拟合
(3)拟合微分方程
一、模拟退火算法(Simulated annealing algorithm,SA)
1.SA的基本理论







2.SA求解函数最值
(1)求解函数y = 11*sin(x) + 7*cos(5*x)在[-3,3]内的最大值
%% 绘制函数的图形
x = -3:0.1:3;
y = 11*sin(x) + 7*cos(5*x);
figure
plot(x,y,'b-')
hold on%% 参数初始化
narvs = 1; % 变量个数
T0 = 100; % 初始温度
T = T0; % 迭代中温度会发生改变,第一次迭代时温度就是T0
maxgen = 200; % 最大迭代次数
Lk = 100; % 每个温度下的迭代次数
alfa = 0.95; % 温度衰减系数
x_lb = -3; % x的下界
x_ub = 3; % x的上界%% 随机生成一个初始解
x0 = zeros(1,narvs);
for i = 1: narvsx0(i) = x_lb(i) + (x_ub(i)-x_lb(i))*rand(1);
end
y0 = Obj_fun1(x0); % 计算当前解的函数值
h = scatter(x0,y0,'*r'); % scatter是绘制二维散点图的函数(这里返回h是为了得到图形的句柄,未来我们对其位置进行更新)%% 定义一些保存中间过程的量,方便输出结果和画图
max_y = y0; % 初始化找到的最佳的解对应的函数值为y0
MAXY = zeros(maxgen,1); % 记录每一次外层循环结束后找到的max_y (方便画图)%% 模拟退火过程
for iter = 1 : maxgen % 外循环, 我这里采用的是指定最大迭代次数for i = 1 : Lk % 内循环,在每个温度下开始迭代y = randn(1,narvs); % 生成1行narvs列的N(0,1)随机数z = y / sqrt(sum(y.^2)); % 根据新解的产生规则计算zx_new = x0 + z*T; % 根据新解的产生规则计算x_new的值% 如果这个新解的位置超出了定义域,就对其进行调整for j = 1: narvsif x_new(j) < x_lb(j)r = rand(1);x_new(j) = r*x_lb(j)+(1-r)*x0(j);elseif x_new(j) > x_ub(j)r = rand(1);x_new(j) = r*x_ub(j)+(1-r)*x0(j);endendx1 = x_new; % 将调整后的x_new赋值给新解x1y1 = Obj_fun1(x1); % 计算新解的函数值if y1 > y0 % 如果新解函数值大于当前解的函数值x0 = x1; % 更新当前解为新解y0 = y1;elsep = exp(-(y0 - y1)/T); % 根据Metropolis准则计算一个概率if rand(1) < p % 生成一个随机数和这个概率比较,如果该随机数小于这个概率x0 = x1; % 更新当前解为新解y0 = y1;endend% 判断是否要更新找到的最佳的解if y0 > max_y % 如果当前解更好,则对其进行更新max_y = y0; % 更新最大的ybest_x = x0; % 更新找到的最好的xendendMAXY(iter) = max_y; % 保存本轮外循环结束后找到的最大的yT = alfa*T; % 温度下降pause(0.01) % 暂停一段时间(单位:秒)后再接着画图h.XData = x0; % 更新散点图句柄的x轴的数据(此时解的位置在图上发生了变化)h.YData = Obj_fun1(x0); % 更新散点图句柄的y轴的数据(此时解的位置在图上发生了变化)
enddisp('最佳的位置是:'); disp(best_x)
disp('此时最优值是:'); disp(max_y)pause(0.5)
h.XData = []; h.YData = []; % 将原来的散点删除
scatter(best_x,max_y,'*r'); % 在最大值处重新标上散点
title(['模拟退火找到的最大值为', num2str(max_y)]) % 加上图的标题%% 画出每次迭代后找到的最大y的图形
figure
plot(1:maxgen,MAXY,'b-');
xlabel('迭代次数');
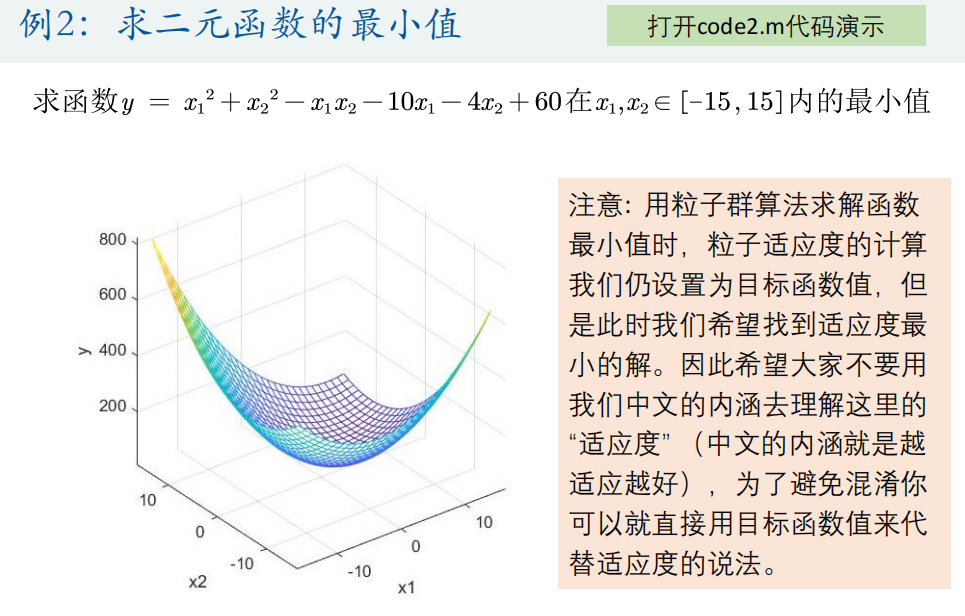
ylabel('y的值');(2)求解函数y = x1^2+x2^2-x1*x2-10*x1-4*x2+60在[-15,15]内的最小值
%% 绘制函数的图形
figure
x1 = -15:1:15;
x2 = -15:1:15;
[x1,x2] = meshgrid(x1,x2);
y = x1.^2 + x2.^2 - x1.*x2 - 10*x1 - 4*x2 + 60;
mesh(x1,x2,y)
xlabel('x1'); ylabel('x2'); zlabel('y'); % 加上坐标轴的标签
axis vis3d % 冻结屏幕高宽比,使得一个三维对象的旋转不会改变坐标轴的刻度显示
hold on %% 参数初始化
narvs = 2; % 变量个数
T0 = 100; % 初始温度
T = T0; % 迭代中温度会发生改变,第一次迭代时温度就是T0
maxgen = 200; % 最大迭代次数
Lk = 100; % 每个温度下的迭代次数
alfa = 0.95; % 温度衰减系数
x_lb = [-15 -15]; % x的下界
x_ub = [15 15]; % x的上界%% 随机生成一个初始解
x0 = zeros(1,narvs);
for i = 1: narvsx0(i) = x_lb(i) + (x_ub(i)-x_lb(i))*rand(1);
end
y0 = Obj_fun2(x0); % 计算当前解的函数值
h = scatter3(x0(1),x0(2),y0,'*r'); % scatter3是绘制三维散点图的函数(这里返回h是为了得到图形的句柄,未来我们对其位置进行更新)%% 定义一些保存中间过程的量,方便输出结果和画图
min_y = y0; % 初始化找到的最佳的解对应的函数值为y0
MINY = zeros(maxgen,1); % 记录每一次外层循环结束后找到的min_y (方便画图)%% 模拟退火过程
for iter = 1 : maxgen % 外循环, 我这里采用的是指定最大迭代次数for i = 1 : Lk % 内循环,在每个温度下开始迭代y = randn(1,narvs); % 生成1行narvs列的N(0,1)随机数z = y / sqrt(sum(y.^2)); % 根据新解的产生规则计算zx_new = x0 + z*T; % 根据新解的产生规则计算x_new的值% 如果这个新解的位置超出了定义域,就对其进行调整for j = 1: narvsif x_new(j) < x_lb(j)r = rand(1);x_new(j) = r*x_lb(j)+(1-r)*x0(j);elseif x_new(j) > x_ub(j)r = rand(1);x_new(j) = r*x_ub(j)+(1-r)*x0(j);endendx1 = x_new; % 将调整后的x_new赋值给新解x1y1 = Obj_fun2(x1); % 计算新解的函数值if y1 < y0 % 如果新解函数值小于当前解的函数值x0 = x1; % 更新当前解为新解y0 = y1;elsep = exp(-(y1 - y0)/T); % 根据Metropolis准则计算一个概率if rand(1) < p % 生成一个随机数和这个概率比较,如果该随机数小于这个概率x0 = x1; % 更新当前解为新解y0 = y1;endend% 判断是否要更新找到的最佳的解if y0 < min_y % 如果当前解更好,则对其进行更新min_y = y0; % 更新最小的ybest_x = x0; % 更新找到的最好的xendendMINY(iter) = min_y; % 保存本轮外循环结束后找到的最小的yT = alfa*T; % 温度下降pause(0.02) % 暂停一段时间后(单位:秒)再接着画图h.XData = x0(1); % 更新散点图句柄的x轴的数据(此时解的位置在图上发生了变化)h.YData = x0(2); % 更新散点图句柄的y轴的数据(此时解的位置在图上发生了变化)h.ZData = Obj_fun2(x0); % 更新散点图句柄的z轴的数据(此时粒子的位置在图上发生了变化)
enddisp('最佳的位置是:'); disp(best_x)
disp('此时最优值是:'); disp(min_y)pause(0.5)
h.XData = []; h.YData = []; h.ZData = []; % 将原来的散点删除
scatter3(best_x(1), best_x(2), min_y,'*r'); % 在最小值处重新标上散点
title(['模拟退火找到的最小值为', num2str(min_y)]) % 加上图的标题%% 画出每次迭代后找到的最小y的图形
figure
plot(1:maxgen,MINY,'b-');
xlabel('迭代次数');
ylabel('y的值');(3)TSP问题
tic
rng('shuffle') % 控制随机数的生成,否则每次打开matlab得到的结果都一样
% https://ww2.mathworks.cn/help/matlab/math/why-do-random-numbers-repeat-after-startup.html
% https://ww2.mathworks.cn/help/matlab/ref/rng.html
clear;clc
% 38个城市,TSP数据集网站(http://www.tsp.gatech.edu/world/djtour.html) 上公测的最优结果6656。
coord = [11003.611100,42102.500000;11108.611100,42373.888900;11133.333300,42885.833300;11155.833300,42712.500000;11183.333300,42933.333300;11297.500000,42853.333300;11310.277800,42929.444400;11416.666700,42983.333300;11423.888900,43000.277800;11438.333300,42057.222200;11461.111100,43252.777800;11485.555600,43187.222200;11503.055600,42855.277800;11511.388900,42106.388900;11522.222200,42841.944400;11569.444400,43136.666700;11583.333300,43150.000000;11595.000000,43148.055600;11600.000000,43150.000000;11690.555600,42686.666700;11715.833300,41836.111100;11751.111100,42814.444400;11770.277800,42651.944400;11785.277800,42884.444400;11822.777800,42673.611100;11846.944400,42660.555600;11963.055600,43290.555600;11973.055600,43026.111100;12058.333300,42195.555600;12149.444400,42477.500000;12286.944400,43355.555600;12300.000000,42433.333300;12355.833300,43156.388900;12363.333300,43189.166700;12372.777800,42711.388900;12386.666700,43334.722200;12421.666700,42895.555600;12645.000000,42973.333300];
n = size(coord,1); % 城市的数目figure % 新建一个图形窗口
plot(coord(:,1),coord(:,2),'o'); % 画出城市的分布散点图
hold on % 等一下要接着在这个图形上画图的d = zeros(n); % 初始化两个城市的距离矩阵全为0
for i = 2:n for j = 1:i coord_i = coord(i,:); x_i = coord_i(1); y_i = coord_i(2); % 城市i的横坐标为x_i,纵坐标为y_icoord_j = coord(j,:); x_j = coord_j(1); y_j = coord_j(2); % 城市j的横坐标为x_j,纵坐标为y_jd(i,j) = sqrt((x_i-x_j)^2 + (y_i-y_j)^2); % 计算城市i和j的距离end
end
d = d+d'; % 生成距离矩阵的对称的一面%% 参数初始化
T0 = 1000; % 初始温度
T = T0; % 迭代中温度会发生改变,第一次迭代时温度就是T0
maxgen = 1000; % 最大迭代次数
Lk = 500; % 每个温度下的迭代次数
alpfa = 0.95; % 温度衰减系数%% 随机生成一个初始解
path0 = randperm(n); % 生成一个1-n的随机打乱的序列作为初始的路径
result0 = calculate_tsp_d(path0,d); % 调用我们自己写的calculate_tsp_d函数计算当前路径的距离%% 定义一些保存中间过程的量,方便输出结果和画图
min_result = result0; % 初始化找到的最佳的解对应的距离为result0
RESULT = zeros(maxgen,1); % 记录每一次外层循环结束后找到的min_result (方便画图)%% 模拟退火过程
for iter = 1 : maxgen % 外循环, 我这里采用的是指定最大迭代次数for i = 1 : Lk % 内循环,在每个温度下开始迭代path1 = gen_new_path(path0); % 调用我们自己写的gen_new_path函数生成新的路径result1 = calculate_tsp_d(path1,d); % 计算新路径的距离%如果新解距离短,则直接把新解的值赋值给原来的解if result1 < result0 path0 = path1; % 更新当前路径为新路径result0 = result1; elsep = exp(-(result1 - result0)/T); % 根据Metropolis准则计算一个概率if rand(1) < p % 生成一个随机数和这个概率比较,如果该随机数小于这个概率path0 = path1; % 更新当前路径为新路径result0 = result1; endend% 判断是否要更新找到的最佳的解if result0 < min_result % 如果当前解更好,则对其进行更新min_result = result0; % 更新最小的距离best_path = path0; % 更新找到的最短路径endendRESULT(iter) = min_result; % 保存本轮外循环结束后找到的最小距离T = alpfa*T; % 温度下降
enddisp('最佳的方案是:'); disp(mat2str(best_path))
disp('此时最优值是:'); disp(min_result)best_path = [best_path,best_path(1)]; % 在最短路径的最后面加上一个元素,即第一个点(我们要生成一个封闭的图形)
n = n+1; % 城市的个数加一个(紧随着上一步)
for i = 1:n-1 j = i+1;coord_i = coord(best_path(i),:); x_i = coord_i(1); y_i = coord_i(2); coord_j = coord(best_path(j),:); x_j = coord_j(1); y_j = coord_j(2);plot([x_i,x_j],[y_i,y_j],'-b') % 每两个点就作出一条线段,直到所有的城市都走完
% pause(0.02) % 暂停0.02s再画下一条线段hold on
end%% 画出每次迭代后找到的最短路径的图形
figure
plot(1:maxgen,RESULT,'b-');
xlabel('迭代次数');
ylabel('最短路径');toc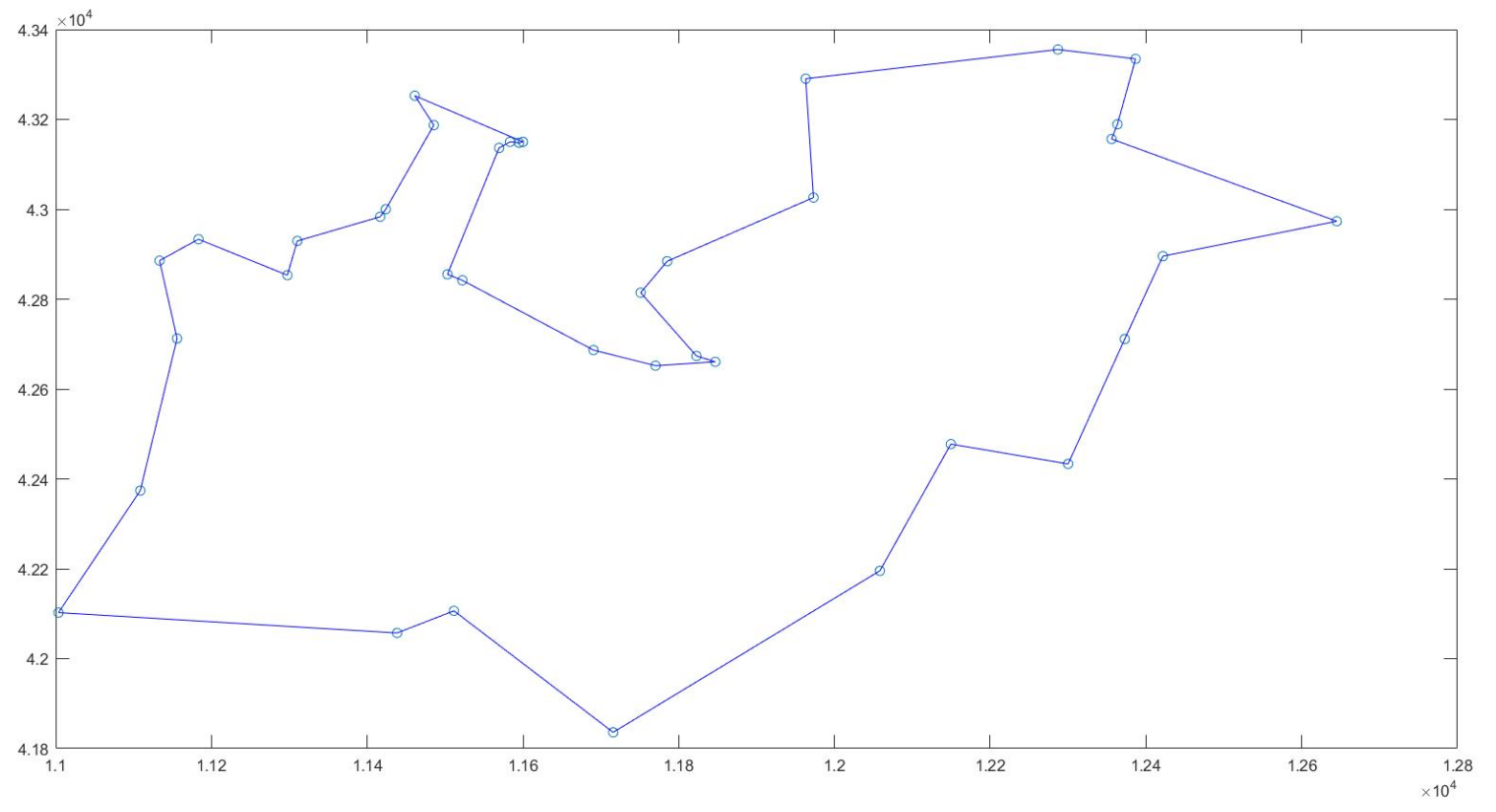
3.SA工具箱
(1)求解一元函数:x = [1,2]范围内 y = sin(10*pi*x) / x 的极值
<fitness.m>
function fitnessVal = fitness( x )% 一元函数优化:fitnessVal = sin(10*pi*x) / x; %求最小值% fitnessVal = -1 * sin(10*pi*x) / x; 用模拟退火求最大值,可以加个负号或者弄个倒数!end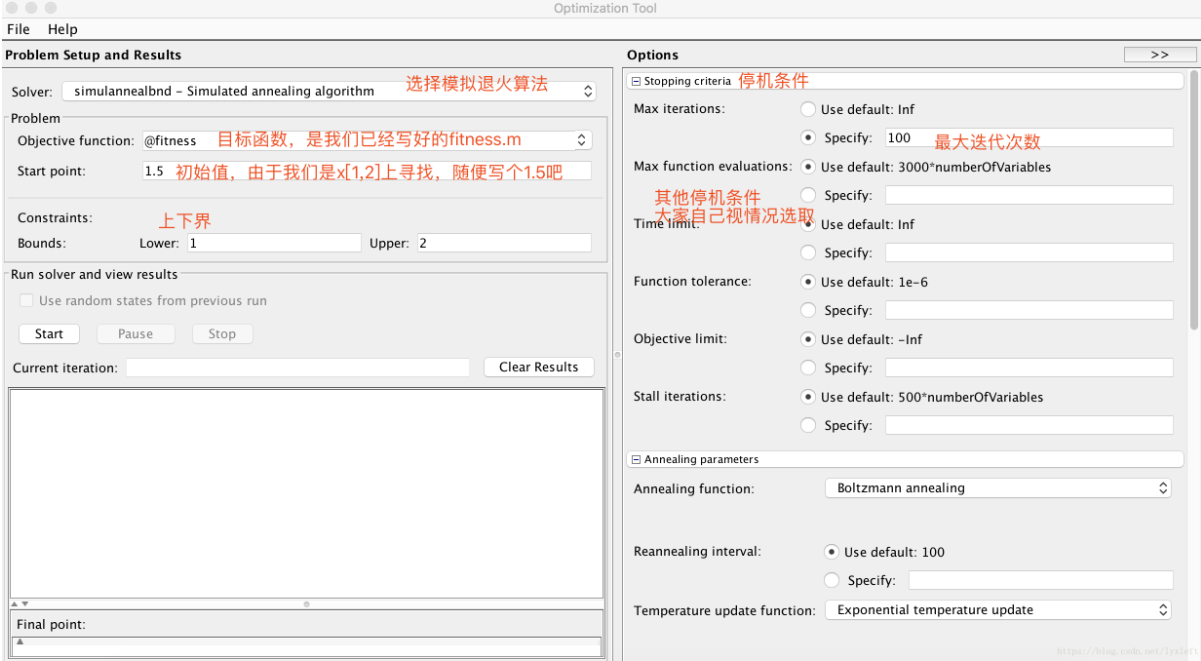


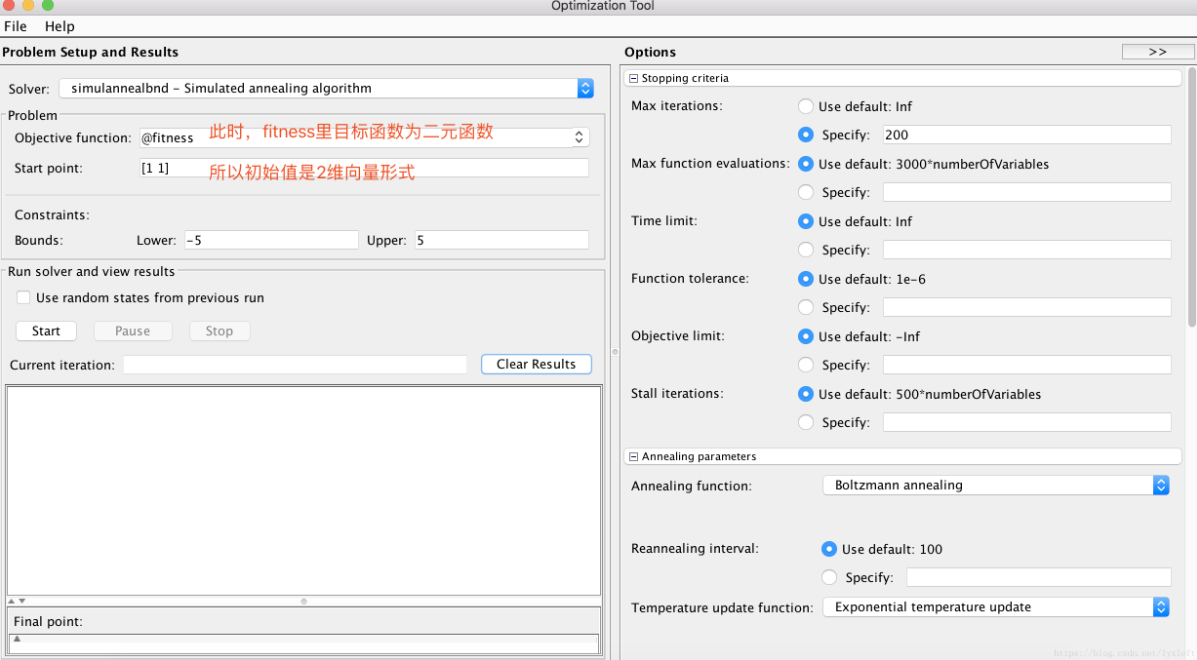
(2)求解二元函数:在x,y都是[-5,5]范围内找z = x.^2 + y.^2 - 10*cos(2*pi*x) - 10*cos(2*pi*y) + 20 的极值
<fitness.m>
function fitnessVal = fitness( x )% 二元函数优化:fitnessVal = -1 * (x(1)^2 + x(2).^2 - 10*cos(2*pi*x(1)) - 10*cos(2*pi*x(2)) + 20);end
二、遗传算法(Genetic Algorithm,GA)
1.GA的理论基础


2.GA求解函数最值
(1)求解一元函数:x在[1,2]范围内 sin(10*pi*X)/X 的最小值
clc
clear all
close all
%% 画出函数图
figure(1);
hold on;
lb=1;ub=2; %函数自变量范围【1,2】
ezplot('sin(10*pi*X)/X',[lb,ub]); %画出函数曲线
xlabel('自变量/X')
ylabel('函数值/Y')
%% 定义遗传算法参数
NIND=40; %个体数目
MAXGEN=20; %最大遗传代数
PRECI=20; %变量的二进制位数
GGAP=0.95; %代沟
px=0.7; %交叉概率
pm=0.01; %变异概率
trace=zeros(2,MAXGEN); %寻优结果的初始值
FieldD=[PRECI;lb;ub;1;0;1;1]; %区域描述器
Chrom=crtbp(NIND,PRECI); %初始种群
%% 优化
gen=0; %代计数器
X=bs2rv(Chrom,FieldD); %计算初始种群的十进制转换
ObjV=sin(10*pi*X)./X; %计算目标函数值
while gen<MAXGENFitnV=ranking(ObjV); %分配适应度值SelCh=select('sus',Chrom,FitnV,GGAP); %选择SelCh=recombin('xovsp',SelCh,px); %重组SelCh=mut(SelCh,pm); %变异X=bs2rv(SelCh,FieldD); %子代个体的十进制转换ObjVSel=sin(10*pi*X)./X; %计算子代的目标函数值[Chrom,ObjV]=reins(Chrom,SelCh,1,1,ObjV,ObjVSel); %重插入子代到父代,得到新种群X=bs2rv(Chrom,FieldD);gen=gen+1; %代计数器增加%获取每代的最优解及其序号,Y为最优解,I为个体的序号[Y,I]=min(ObjV);trace(1,gen)=X(I); %记下每代的最优值trace(2,gen)=Y; %记下每代的最优值
end
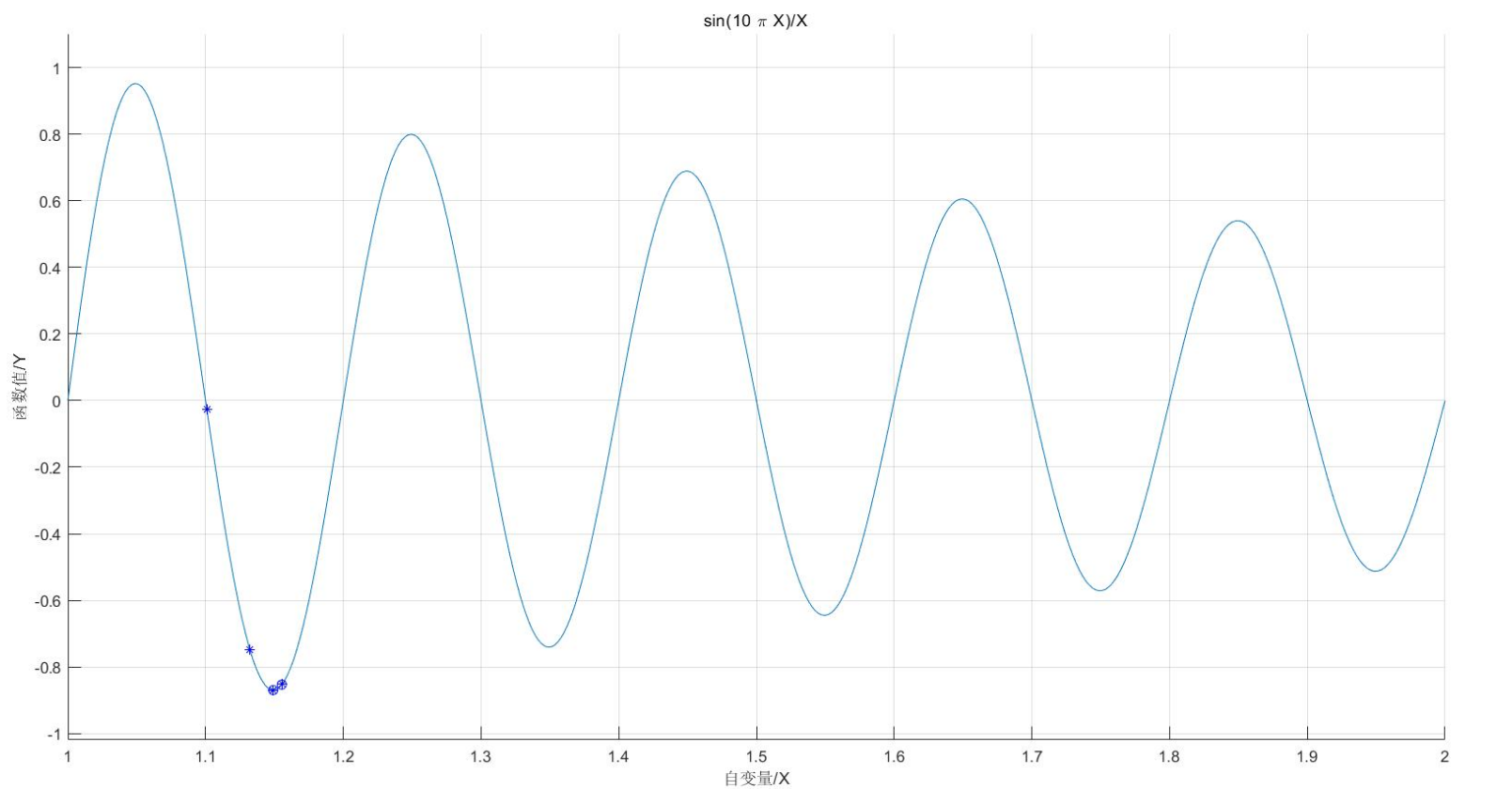
plot(trace(1,:),trace(2,:),'bo'); %画出每代的最优点
grid on;
plot(X,ObjV,'b*'); %画出最后一代的种群
hold off
%% 画进化图
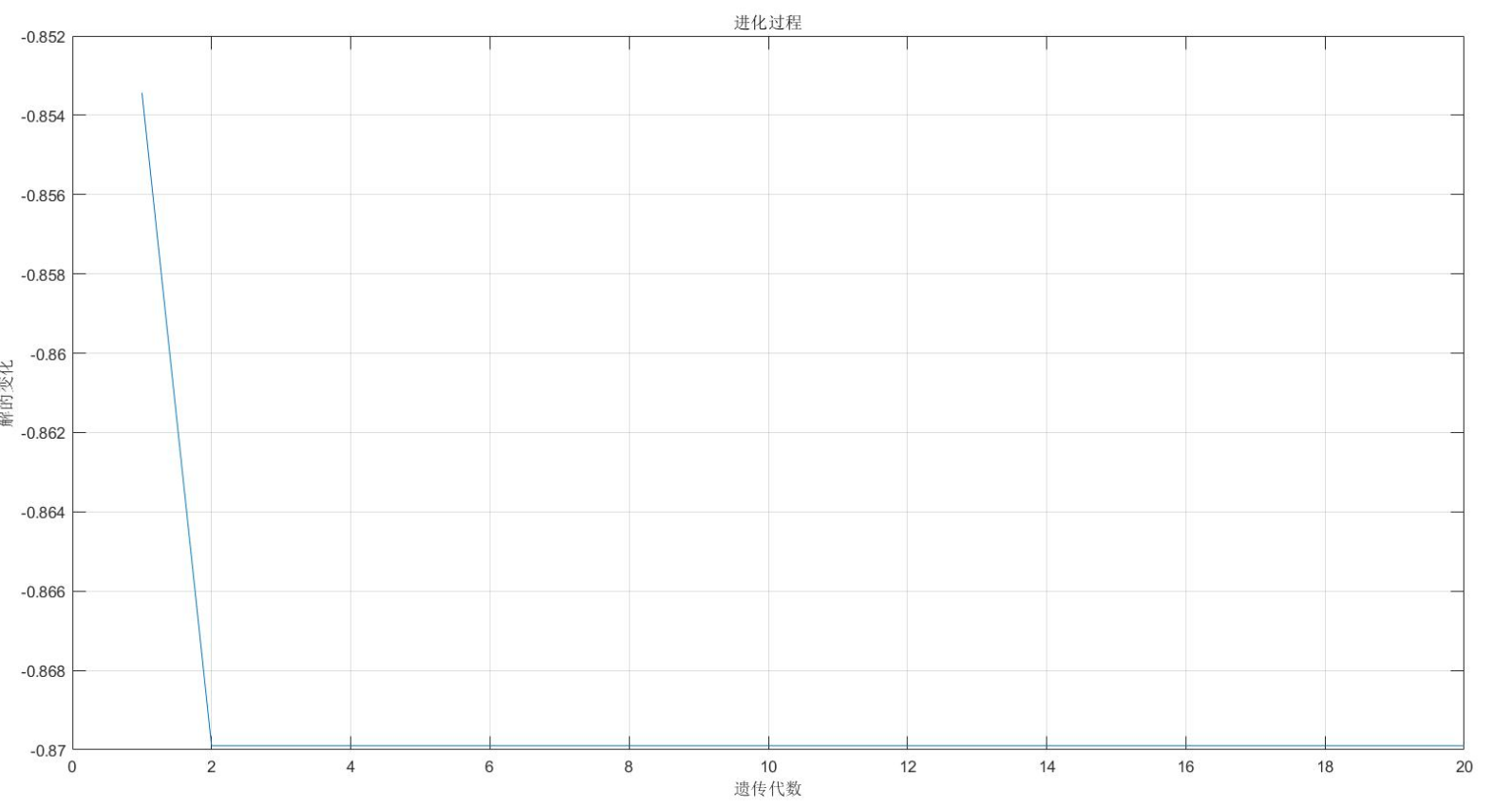
figure(2);
plot(1:MAXGEN,trace(2,:));
grid on
xlabel('遗传代数')
ylabel('解的变化')
title('进化过程')
bestY=trace(2,end);
bestX=trace(1,end);
fprintf(['最优解:\nX=',num2str(bestX),'\nY=',num2str(bestY),'\n'])
(2)求解二元函数:x,y均在[-2,2]范围内 y*sin(2*pi*x)+x*cos(2*pi*y) 的最大值
clc
clear all
close all
%% 画出函数图
figure(1);
lbx=-2;ubx=2; %函数自变量x范围【-2,2】
lby=-2;uby=2; %函数自变量y范围【-2,2】
ezmesh('y*sin(2*pi*x)+x*cos(2*pi*y)',[lbx,ubx,lby,uby],50); %画出函数曲线
hold on;
%% 定义遗传算法参数
NIND=40; %个体数目
MAXGEN=50; %最大遗传代数
PRECI=20; %变量的二进制位数
GGAP=0.95; %代沟
px=0.7; %交叉概率
pm=0.01; %变异概率
trace=zeros(3,MAXGEN); %寻优结果的初始值
FieldD=[PRECI PRECI;lbx lby;ubx uby;1 1;0 0;1 1;1 1]; %区域描述器
Chrom=crtbp(NIND,PRECI*2); %初始种群
%% 优化
gen=0; %代计数器
XY=bs2rv(Chrom,FieldD); %计算初始种群的十进制转换
X=XY(:,1);Y=XY(:,2);
ObjV=Y.*sin(2*pi*X)+X.*cos(2*pi*Y); %计算目标函数值
while gen<MAXGENFitnV=ranking(-ObjV); %分配适应度值SelCh=select('sus',Chrom,FitnV,GGAP); %选择SelCh=recombin('xovsp',SelCh,px); %重组SelCh=mut(SelCh,pm); %变异XY=bs2rv(SelCh,FieldD); %子代个体的十进制转换X=XY(:,1);Y=XY(:,2);ObjVSel=Y.*sin(2*pi*X)+X.*cos(2*pi*Y); %计算子代的目标函数值[Chrom,ObjV]=reins(Chrom,SelCh,1,1,ObjV,ObjVSel); %重插入子代到父代,得到新种群XY=bs2rv(Chrom,FieldD);gen=gen+1; %代计数器增加%获取每代的最优解及其序号,Y为最优解,I为个体的序号[Y,I]=max(ObjV);trace(1:2,gen)=XY(I,:); %记下每代的最优值trace(3,gen)=Y; %记下每代的最优值
end
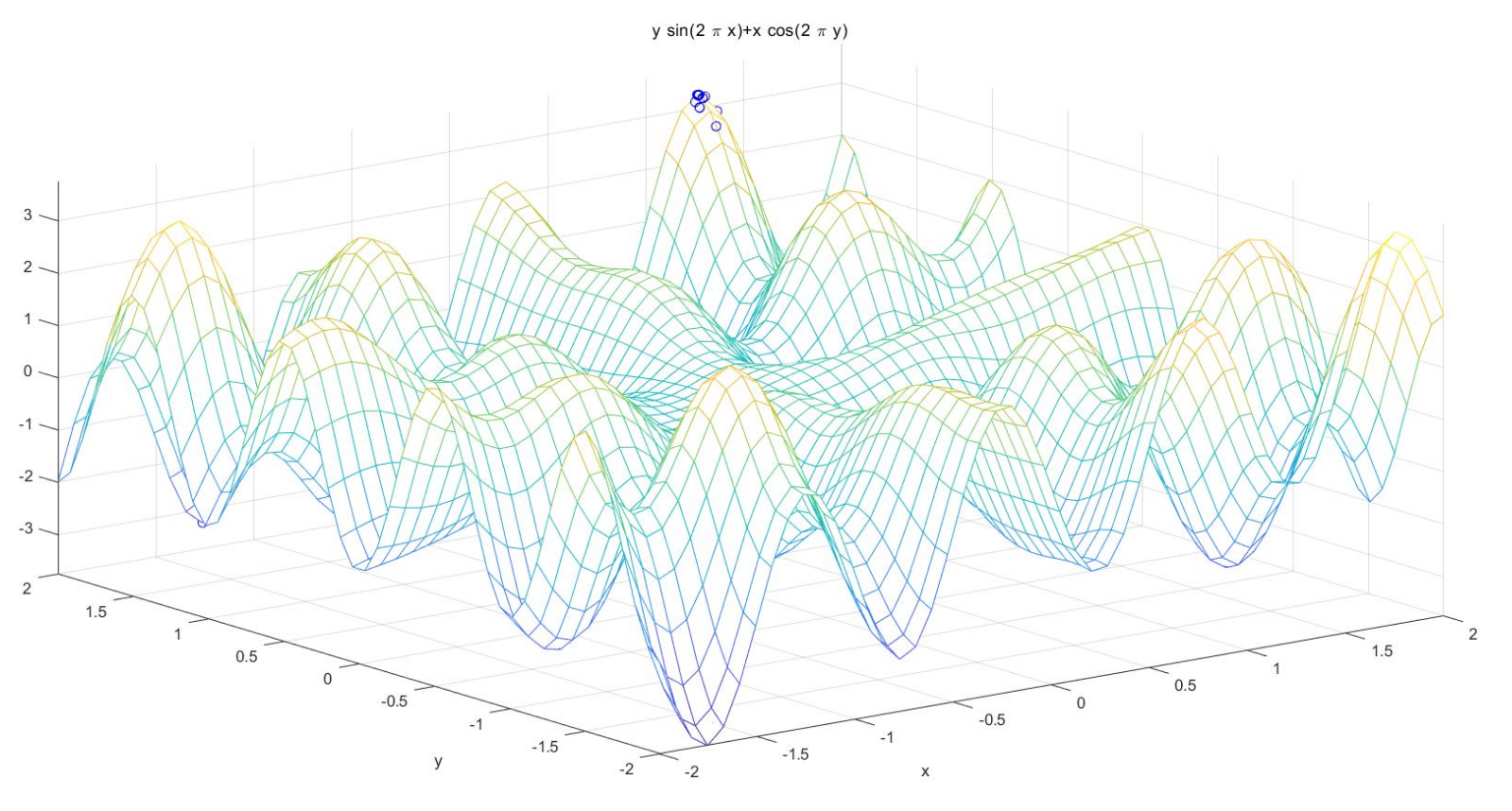
plot3(trace(1,:),trace(2,:),trace(3,:),'bo'); %画出每代的最优点
grid on;
plot3(XY(:,1),XY(:,2),ObjV,'bo'); %画出最后一代的种群
hold off
%% 画进化图
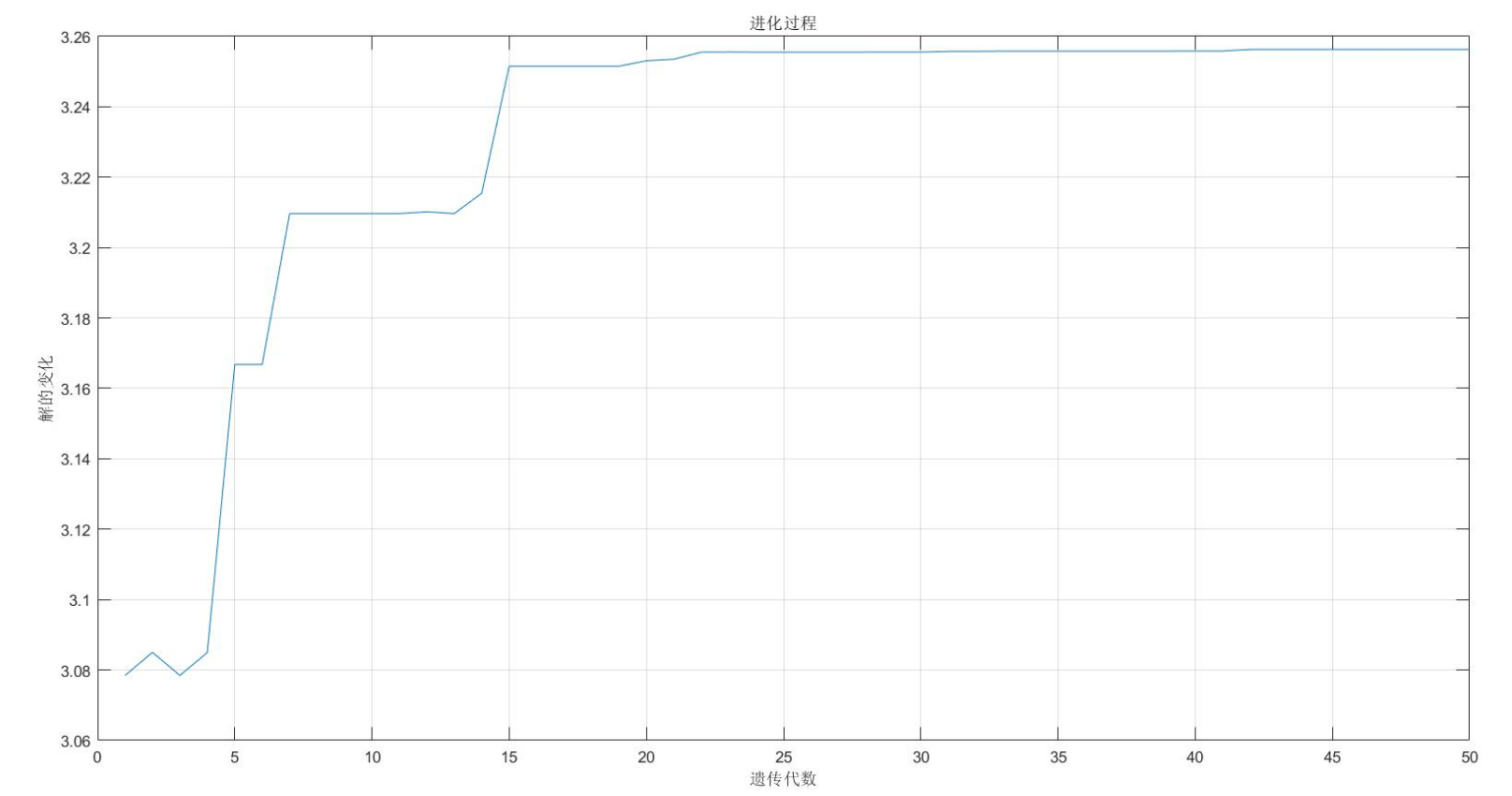
figure(2);
plot(1:MAXGEN,trace(3,:));
grid on
xlabel('遗传代数')
ylabel('解的变化')
title('进化过程')
bestZ=trace(3,end);
bestX=trace(1,end);
bestY=trace(2,end);
fprintf(['最优解:\nX=',num2str(bestX),'\nY=',num2str(bestY),'\nZ=',num2str(bestZ),'\n'])
3.GA工具箱
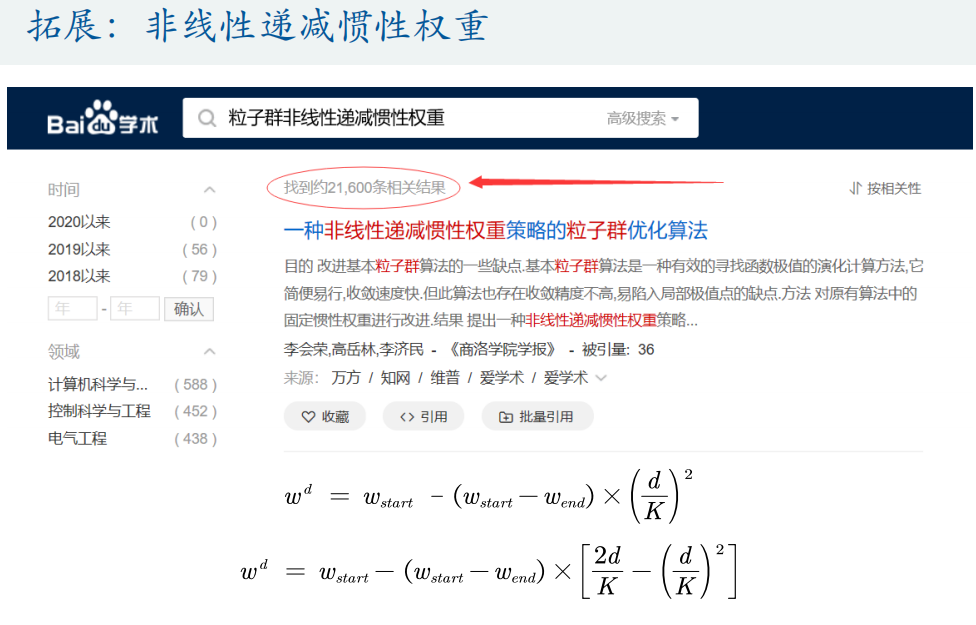
遗传算法是现代优化算法之一,为方便使用Matlab提供了遗传算法工具箱,可以方便我们解决一般的优化问题。

①编写适应度函数(目标函数)
<fun.m>
function y=fun(x)y=-5*sin(x(1))*sin(x(2))*sin(x(3))*sin(x(4))*sin(x(5))...-sin(5*x(1))*sin(5*x(2))*sin(5*x(3))*sin(5*x(4))*sin(5*x(5))+8;
end②输入参数
在Fitness function(适应度函数)处输入@目标函数名(因为此处传递的是函数句柄所以一定要加@,不然会出错),Number of Variables是指待求变量的个数,接下来就是输入约束条件了,以为此处约束条件是xi是0到0.9pi之间的实数,所以只需要在Bound处输入就行了,然后点击Start按钮就会求出结果。

2.求解含线性不等式约束的多元函数最大值(有界)
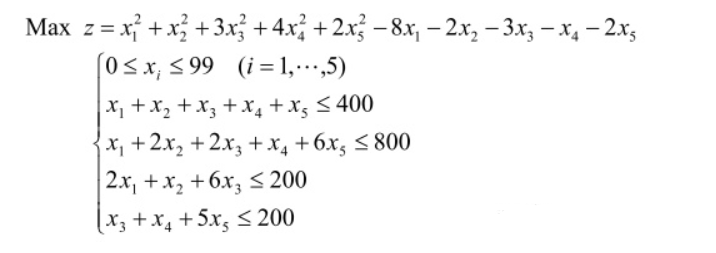
这个是求最大值,但遗传算法工具箱只能求最小值,所以我们编写适应度函数时在目标函数前加个负号就行了(当-z最小时,z也就最大了)。
①编写适应度函数(目标函数)
<fun.m>
function y=fun(x)y=-(x(1)^2+x(2)^2+3*x(3)^2+4*x(4)^2+2*x(5)^2-8*x(1)...-2*x(2)-3*x(3)-x(4)-2*x(5));
end②在Matlab中定义线性不等式约束,其不等式约束表示形式为:
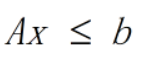
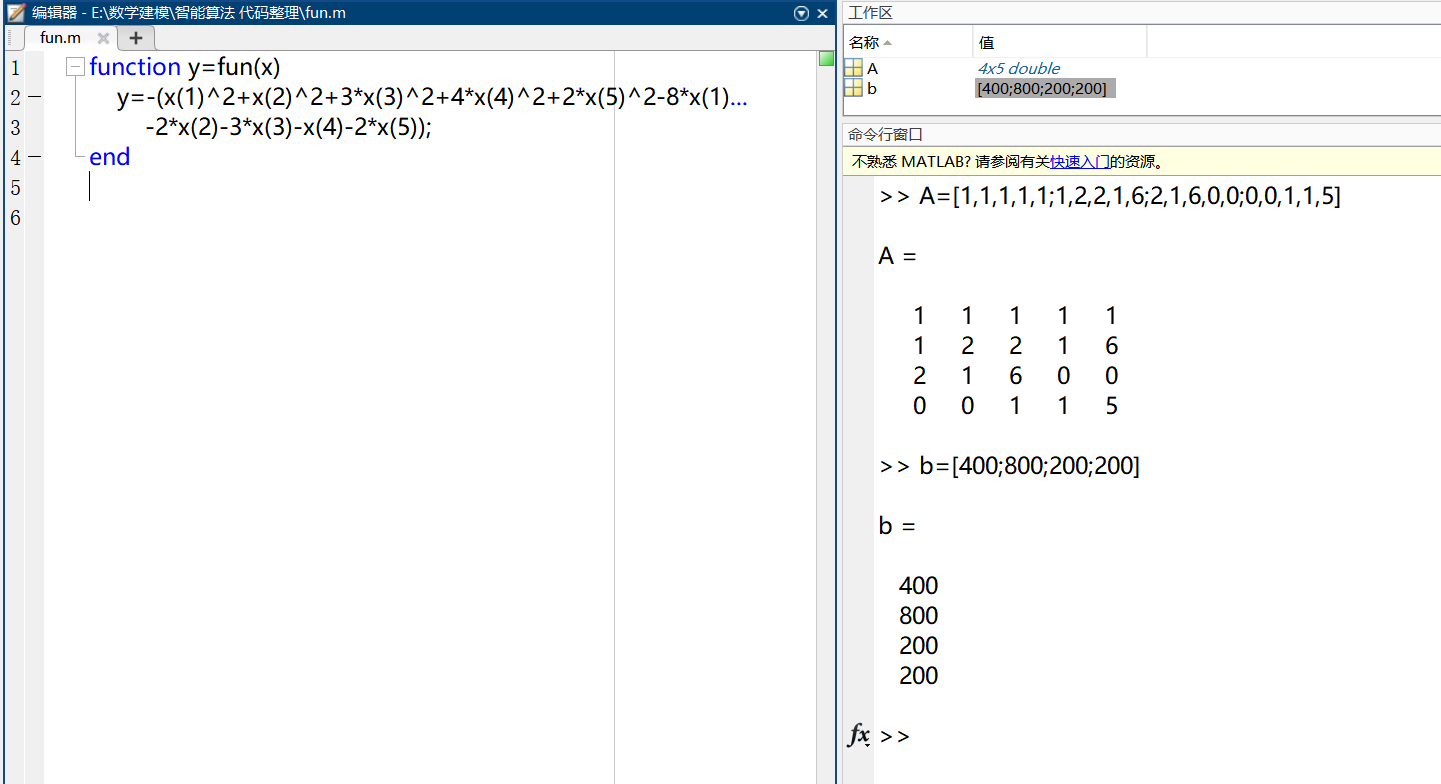
在工作区要有约束条件的矩阵变量,和例1不同的是只需要在约束处添加不等式约束就行了。这求的是最大值的相反数。
③输入参数

3.求解含非线性不等式约束的多元函数最小值
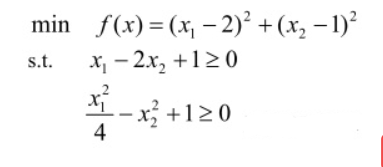
①编写适应度函数(目标函数)
<fun.m>
function y=fun(x)y=(x(1)-2)^2+(x(2)-1)^2;
end②定义线性不等式约束
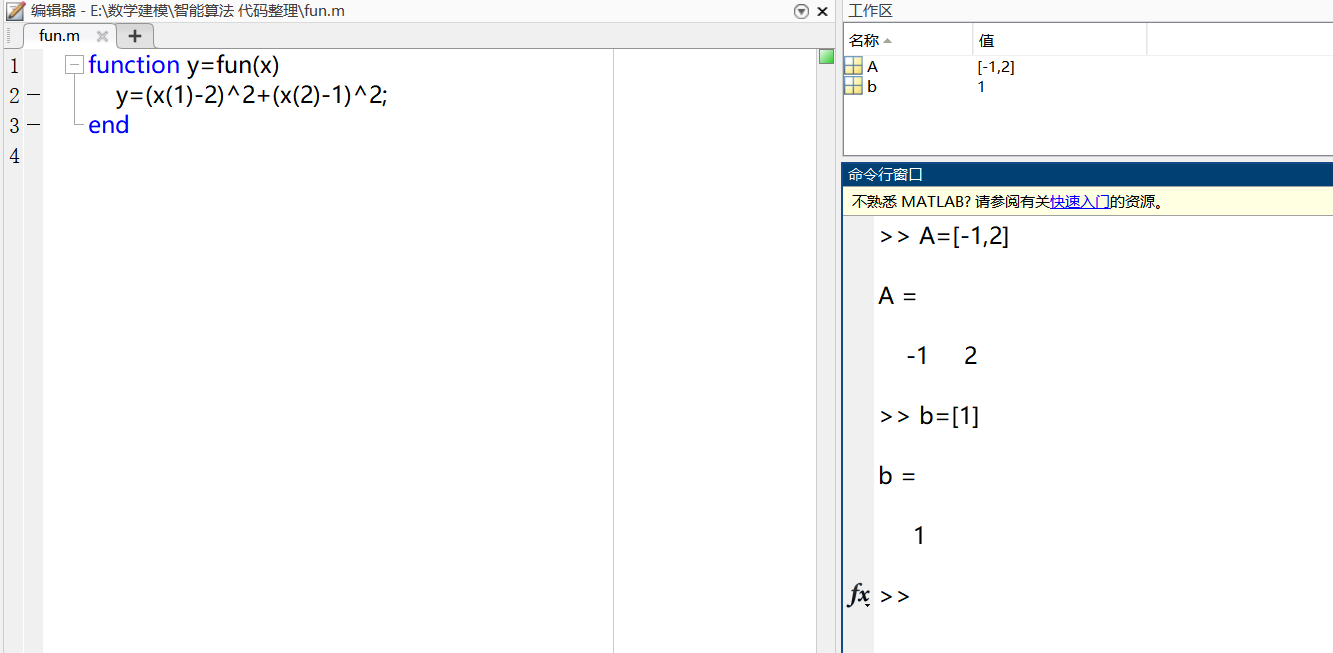
③编写非线性不等式约束条件
<con_fun.m>
function [c,ceq]=con_fun(x)c=-(1/4*x(1)^2-x(2)^2+1);ceq=[]
end
④输入参数
此题相对前面的需要在Constraints中的Nonlinear constraint function处输入非线性约束m文件函数。
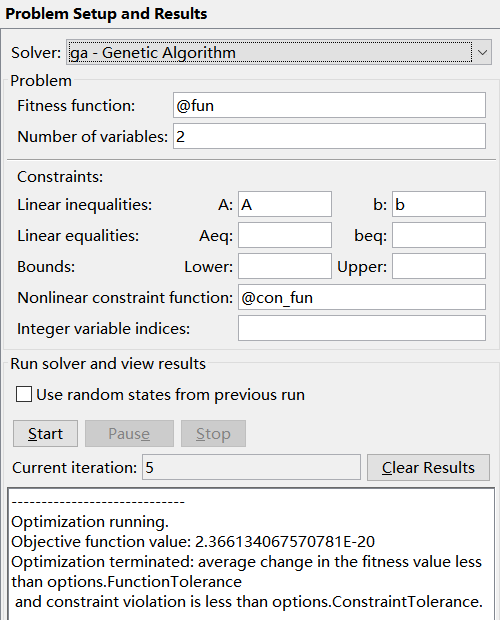
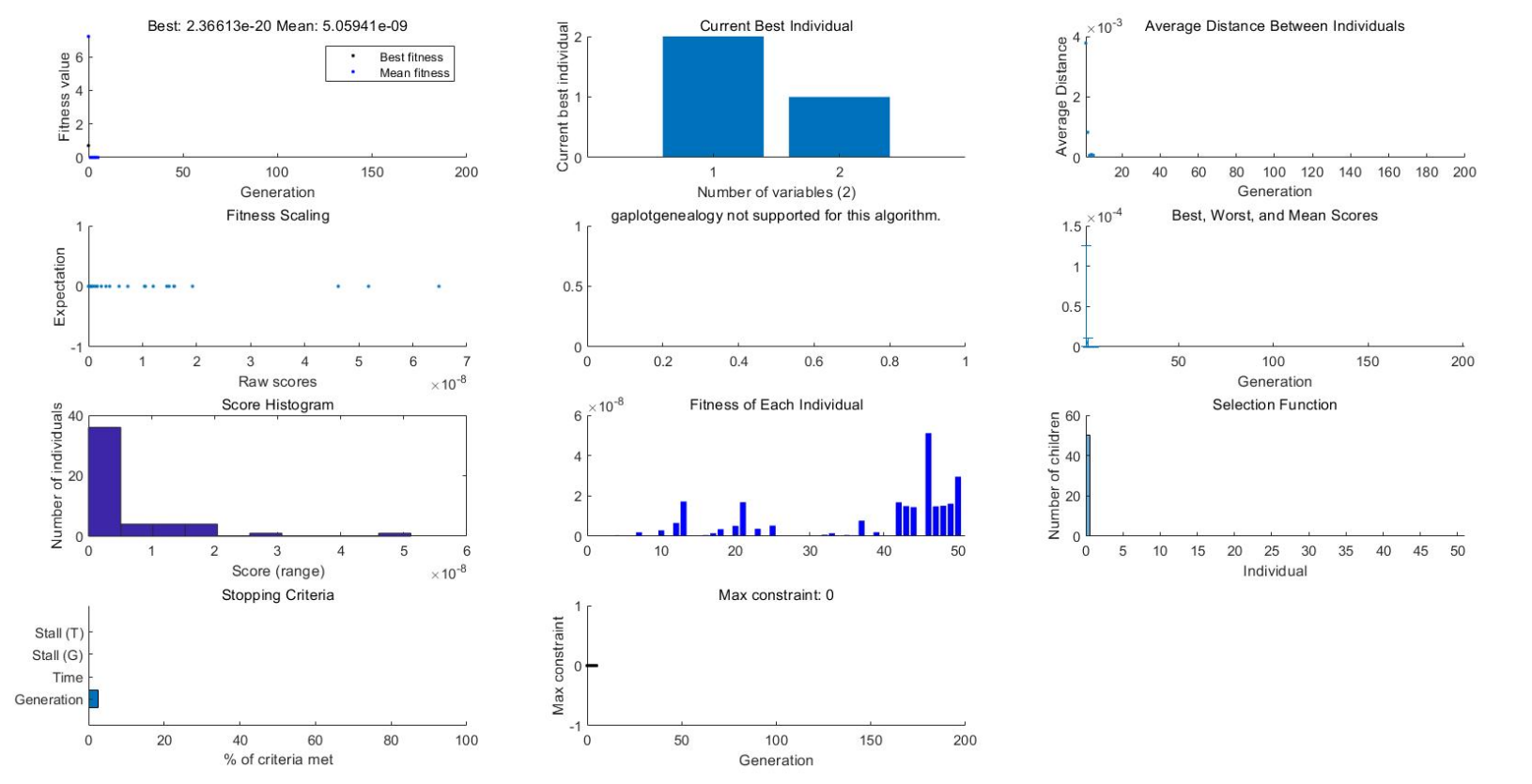
以上例题还没有涉及到的参数由Aeq,beq这是线性等式约束的条件,以及Interger variable indices处的参数(这是指明那个参数是整数),具体说明可参见 Quick Reference。
三、粒子群算法(Particle Swarm Optimization,PSO)
1.PSO算法相关知识

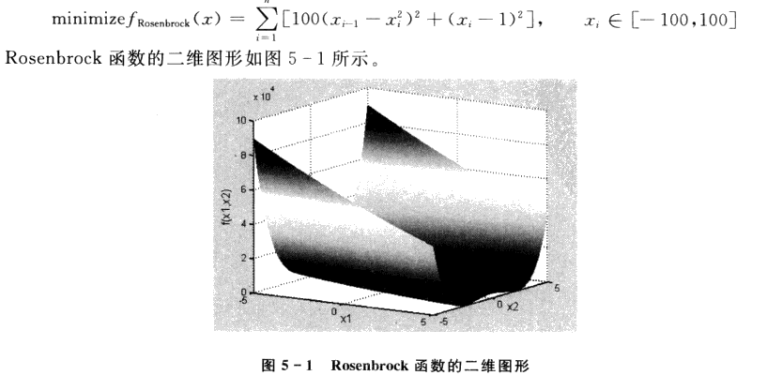







2.PSO算法设计





3.PSO算法

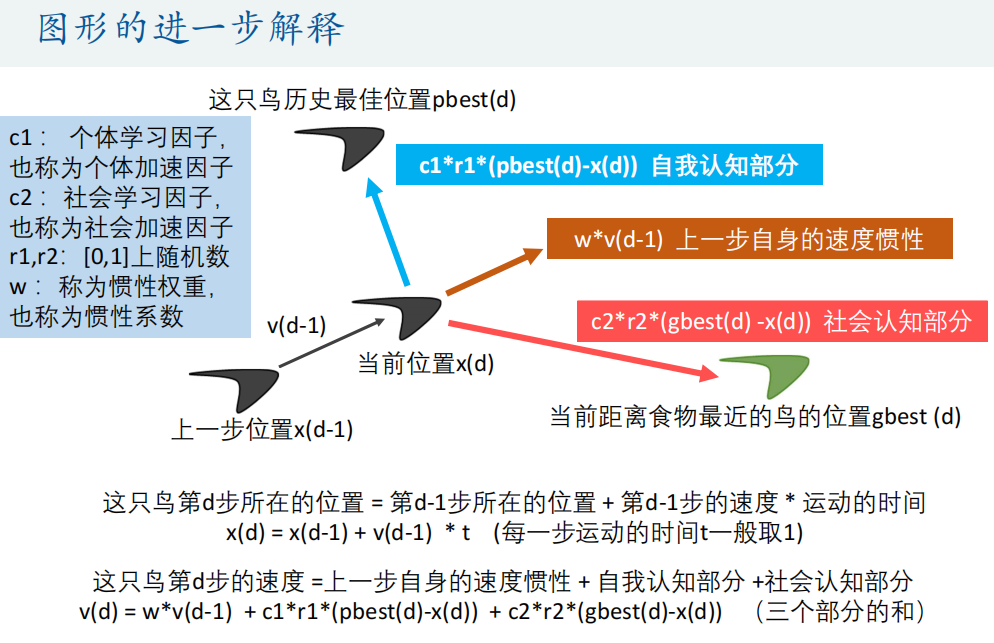

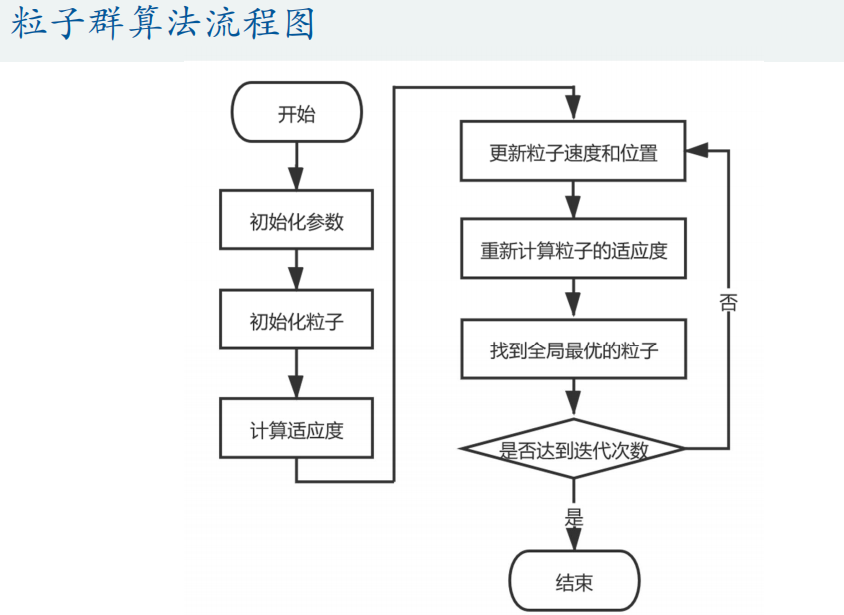



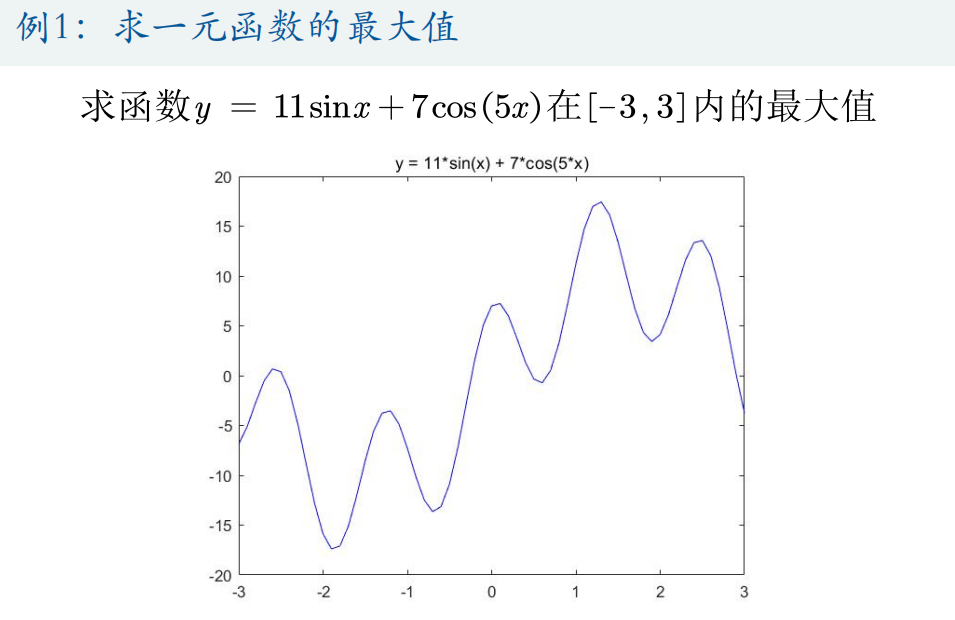
Matlab代码:
%% 绘制函数的图形
x = -3:0.01:3;
y = 11*sin(x) + 7*cos(5*x);
figure(1)
plot(x,y,'b-')
title('y = 11*sin(x) + 7*cos(5*x)')
hold on %% 粒子群算法中的预设参数(参数的设置不是固定的,可以适当修改)
n = 10; % 粒子数量
narvs = 1; % 变量个数
c1 = 2; % 每个粒子的个体学习因子,也称为个体加速常数
c2 = 2; % 每个粒子的社会学习因子,也称为社会加速常数
w = 0.9; % 惯性权重
K = 50; % 迭代的次数
vmax = 1.2; % 粒子的最大速度
x_lb = -3; % x的下界
x_ub = 3; % x的上界%% 初始化粒子的位置和速度
x = zeros(n,narvs);
for i = 1: narvsx(:,i) = x_lb(i) + (x_ub(i)-x_lb(i))*rand(n,1); % 随机初始化粒子所在的位置在定义域内
end
v = -vmax + 2*vmax .* rand(n,narvs); % 随机初始化粒子的速度(这里我们设置为[-vmax,vmax])% 即:v = -repmat(vmax, n, 1) + 2*repmat(vmax, n, 1) .* rand(n,narvs);
% 注意:x的初始化也可以用一行写出来: x = x_lb + (x_ub-x_lb).*rand(n,narvs) ,原理和v的计算一样%% 计算适应度
fit = zeros(n,1); % 初始化这n个粒子的适应度全为0
for i = 1:n % 循环整个粒子群,计算每一个粒子的适应度fit(i) = Obj_fun1(x(i,:)); % 调用Obj_fun1函数来计算适应度(这里写成x(i,:)主要是为了和以后遇到的多元函数互通)
end
pbest = x; % 初始化这n个粒子迄今为止找到的最佳位置(是一个n*narvs的向量)
ind = find(fit == max(fit), 1); % 找到适应度最大的那个粒子的下标
gbest = x(ind,:); % 定义所有粒子迄今为止找到的最佳位置(是一个1*narvs的向量)%% 在图上标上这n个粒子的位置用于演示
h = scatter(x,fit,80,'*r'); % scatter是绘制二维散点图的函数,80是我设置的散点显示的大小(这里返回h是为了得到图形的句柄,未来我们对其位置进行更新)%% 迭代K次来更新速度与位置
fitnessbest = ones(K,1); % 初始化每次迭代得到的最佳的适应度
for d = 1:K % 开始迭代,一共迭代K次for i = 1:n % 依次更新第i个粒子的速度与位置v(i,:) = w*v(i,:) + c1*rand(1)*(pbest(i,:) - x(i,:)) + c2*rand(1)*(gbest - x(i,:)); % 更新第i个粒子的速度% 如果粒子的速度超过了最大速度限制,就对其进行调整for j = 1: narvsif v(i,j) < -vmax(j)v(i,j) = -vmax(j);elseif v(i,j) > vmax(j)v(i,j) = vmax(j);endendx(i,:) = x(i,:) + v(i,:); % 更新第i个粒子的位置% 如果粒子的位置超出了定义域,就对其进行调整for j = 1: narvsif x(i,j) < x_lb(j)x(i,j) = x_lb(j);elseif x(i,j) > x_ub(j)x(i,j) = x_ub(j);endendfit(i) = Obj_fun1(x(i,:)); % 重新计算第i个粒子的适应度if fit(i) > Obj_fun1(pbest(i,:)) % 如果第i个粒子的适应度大于这个粒子迄今为止找到的最佳位置对应的适应度pbest(i,:) = x(i,:); % 那就更新第i个粒子迄今为止找到的最佳位置endif fit(i) > Obj_fun1(gbest) % 如果第i个粒子的适应度大于所有的粒子迄今为止找到的最佳位置对应的适应度gbest = pbest(i,:); % 那就更新所有粒子迄今为止找到的最佳位置endendfitnessbest(d) = Obj_fun1(gbest); % 更新第d次迭代得到的最佳的适应度pause(0.1) % 暂停0.1sh.XData = x; % 更新散点图句柄的x轴的数据(此时粒子的位置在图上发生了变化)h.YData = fit; % 更新散点图句柄的y轴的数据(此时粒子的位置在图上发生了变化)
endfigure(2)
plot(fitnessbest) % 绘制出每次迭代最佳适应度的变化图
xlabel('迭代次数');
disp('最佳的位置是:'); disp(gbest)
disp('此时最优值是:'); disp(Obj_fun1(gbest))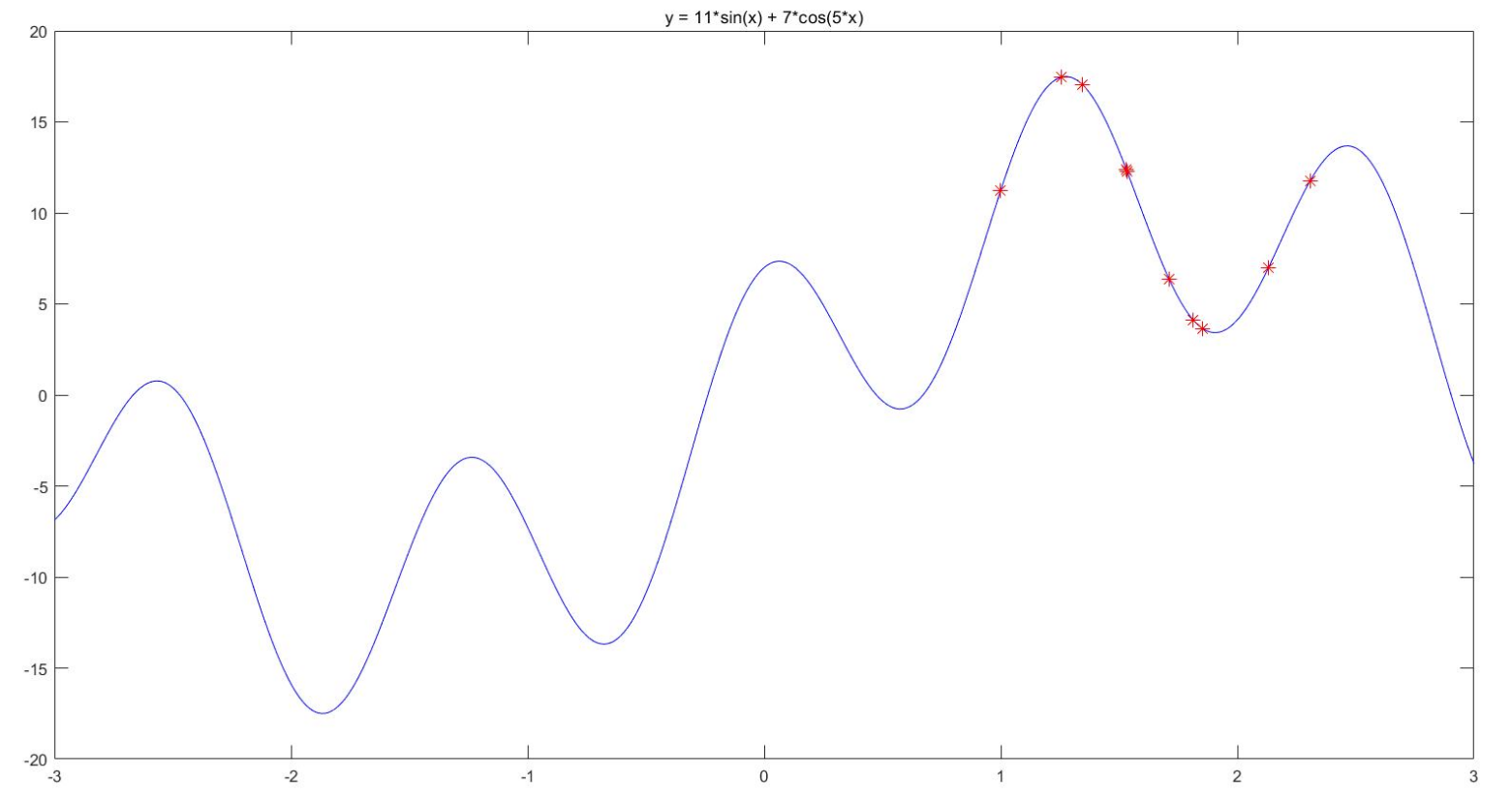
Matlab代码:
%% 绘制函数的图形
x1 = -15:1:15;
x2 = -15:1:15;
[x1,x2] = meshgrid(x1,x2);
y = x1.^2 + x2.^2 - x1.*x2 - 10*x1 - 4*x2 + 60;
mesh(x1,x2,y)
xlabel('x1'); ylabel('x2'); zlabel('y'); % 加上坐标轴的标签
axis vis3d % 冻结屏幕高宽比,使得一个三维对象的旋转不会改变坐标轴的刻度显示
hold on %% 粒子群算法中的预设参数(参数的设置不是固定的,可以适当修改)
n = 30; % 粒子数量
narvs = 2; % 变量个数
c1 = 2; % 每个粒子的个体学习因子,也称为个体加速常数
c2 = 2; % 每个粒子的社会学习因子,也称为社会加速常数
w = 0.9; % 惯性权重
K = 100; % 迭代的次数
vmax = [6 6]; % 粒子的最大速度
x_lb = [-15 -15]; % x的下界
x_ub = [15 15]; % x的上界%% 初始化粒子的位置和速度
x = zeros(n,narvs);
for i = 1: narvsx(:,i) = x_lb(i) + (x_ub(i)-x_lb(i))*rand(n,1); % 随机初始化粒子所在的位置在定义域内
end
v = -vmax + 2*vmax .* rand(n,narvs); % 随机初始化粒子的速度(这里我们设置为[-vmax,vmax])% 即:v = -repmat(vmax, n, 1) + 2*repmat(vmax, n, 1) .* rand(n,narvs);
% 注意:x的初始化也可以用一行写出来: x = x_lb + (x_ub-x_lb).*rand(n,narvs) ,原理和v的计算一样%% 计算适应度(注意,因为是最小化问题,所以适应度越小越好)
fit = zeros(n,1); % 初始化这n个粒子的适应度全为0
for i = 1:n % 循环整个粒子群,计算每一个粒子的适应度fit(i) = Obj_fun2(x(i,:)); % 调用Obj_fun2函数来计算适应度
end
pbest = x; % 初始化这n个粒子迄今为止找到的最佳位置(是一个n*narvs的向量)
ind = find(fit == min(fit), 1); % 找到适应度最小的那个粒子的下标
gbest = x(ind,:); % 定义所有粒子迄今为止找到的最佳位置(是一个1*narvs的向量)%% 在图上标上这n个粒子的位置用于演示
h = scatter3(x(:,1),x(:,2),fit,'*r'); % scatter3是绘制三维散点图的函数(这里返回h是为了得到图形的句柄,未来我们对其位置进行更新)%% 迭代K次来更新速度与位置
fitnessbest = ones(K,1); % 初始化每次迭代得到的最佳的适应度
for d = 1:K % 开始迭代,一共迭代K次for i = 1:n % 依次更新第i个粒子的速度与位置v(i,:) = w*v(i,:) + c1*rand(1)*(pbest(i,:) - x(i,:)) + c2*rand(1)*(gbest - x(i,:)); % 更新第i个粒子的速度% 如果粒子的速度超过了最大速度限制,就对其进行调整for j = 1: narvsif v(i,j) < -vmax(j)v(i,j) = -vmax(j);elseif v(i,j) > vmax(j)v(i,j) = vmax(j);endendx(i,:) = x(i,:) + v(i,:); % 更新第i个粒子的位置% 如果粒子的位置超出了定义域,就对其进行调整for j = 1: narvsif x(i,j) < x_lb(j)x(i,j) = x_lb(j);elseif x(i,j) > x_ub(j)x(i,j) = x_ub(j);endendfit(i) = Obj_fun2(x(i,:)); % 重新计算第i个粒子的适应度if fit(i) < Obj_fun2(pbest(i,:)) % 如果第i个粒子的适应度小于这个粒子迄今为止找到的最佳位置对应的适应度pbest(i,:) = x(i,:); % 那就更新第i个粒子迄今为止找到的最佳位置endif fit(i) < Obj_fun2(gbest) % 如果第i个粒子的适应度小于所有的粒子迄今为止找到的最佳位置对应的适应度gbest = pbest(i,:); % 那就更新所有粒子迄今为止找到的最佳位置endendfitnessbest(d) = Obj_fun2(gbest); % 更新第d次迭代得到的最佳的适应度pause(0.1) % 暂停0.1sh.XData = x(:,1); % 更新散点图句柄的x轴的数据(此时粒子的位置在图上发生了变化)h.YData = x(:,2); % 更新散点图句柄的y轴的数据(此时粒子的位置在图上发生了变化)h.ZData = fit; % 更新散点图句柄的z轴的数据(此时粒子的位置在图上发生了变化)
endfigure(2)
plot(fitnessbest) % 绘制出每次迭代最佳适应度的变化图
xlabel('迭代次数');
disp('最佳的位置是:'); disp(gbest)
disp('此时最优值是:'); disp(Obj_fun2(gbest))











4.particleswarm粒子群函数
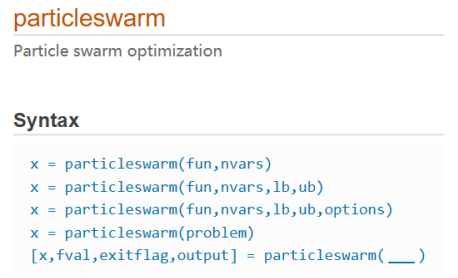
particleswarm函数是求最小值的,如果目标函数是求最大值则需要添加负号从而转换为求最小值。






1.求解函数y = x1^2+x2^2-x1*x2-10*x1-4*x2+60在[-15,15]内的最小值(最小值为8)
①编写目标函数
<Obj_fun2.m>
function y = Obj_fun2(x) y = x(1)^2 + x(2)^2 - x(1)*x(2) - 10*x(1) - 4*x(2) + 60;
end②particleswarm函数求解
% 变量个数
narvs = 2;% x的下界(长度等于变量的个数,每个变量对应一个下界约束)
x_lb = [-15 -15]; % x的上界
x_ub = [15 15]; [x,fval,exitflag,output] = particleswarm(@Obj_fun2, narvs, x_lb, x_ub) 2.调用particleswarm函数进行求解测试函数

①编写目标函数
<Obj_fun3.m>
function y = Obj_fun3(x)
% x是一个向量% Sphere函数
% y = sum(x.^2);% Rosenbrock函数tem1 = x(1:end-1); tem2 = x(2:end);y = sum(100 * (tem2-tem1.^2).^2 + (tem1-1).^2);% Rastrigin函数
% y = sum(x.^2-10*cos(2*pi*x)+10);% Griewank函数
% y = 1/4000*sum(x.*x)-prod(cos(x./sqrt(1:30)))+1;end
②particleswarm函数求解
narvs = 30; % 变量个数
% Sphere函数
% x_lb = -100*ones(1,30); % x的下界
% x_ub = 100*ones(1,30); % x的上界% Rosenbrock函数
x_lb = -30*ones(1,30); % x的下界
x_ub = 30*ones(1,30); % x的上界% Rastrigin函数
% x_lb = -5.12*ones(1,30); % x的下界
% x_ub = 5.12*ones(1,30); % x的上界
% Griewank函数
% x_lb = -600*ones(1,30); % x的下界
% x_ub = 600*ones(1,30); % x的上界[x,fval,exitflag,output] = particleswarm(@Obj_fun3,narvs,x_lb,x_ub) 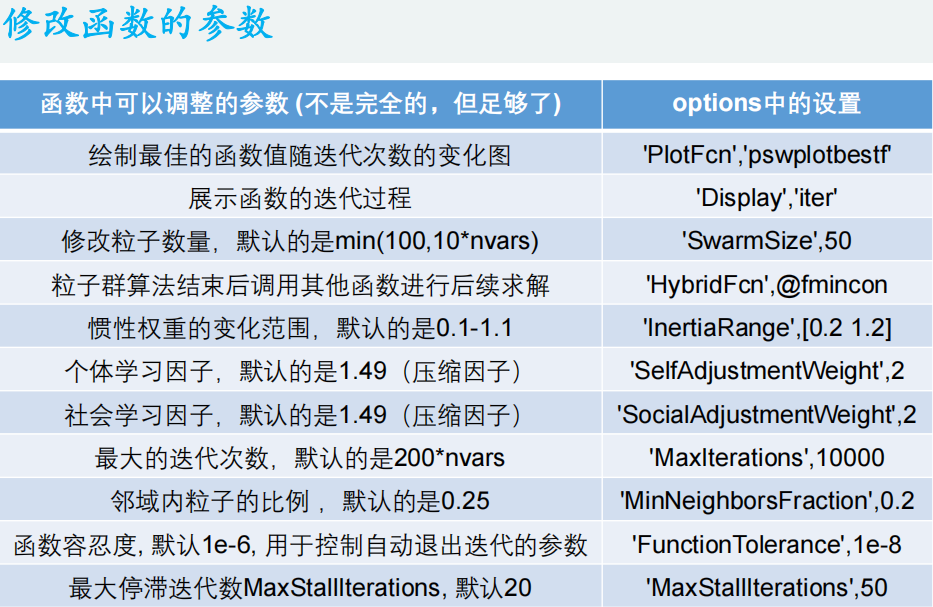
Matlab代码:
%% 绘制最佳的函数值随迭代次数的变化图
options = optimoptions('particleswarm','PlotFcn','pswplotbestf')
[x,fval] = particleswarm(@Obj_fun3,narvs,x_lb,x_ub,options)%% 展示函数的迭代过程
options = optimoptions('particleswarm','Display','iter');
[x,fval] = particleswarm(@Obj_fun3,narvs,x_lb,x_ub,options)%% 修改粒子数量,默认的是:min(100,10*nvars)
options = optimoptions('particleswarm','SwarmSize',50);
[x,fval] = particleswarm(@Obj_fun3,narvs,x_lb,x_ub,options)%% 在粒子群算法结束后继续调用其他函数进行混合求解(hybrid n.混合物合成物; adj.混合的; 杂种的;)
options = optimoptions('particleswarm','HybridFcn',@fmincon);
[x,fval] = particleswarm(@Obj_fun3,narvs,x_lb,x_ub,options)%% 惯性权重的变化范围,默认的是0.1-1.1
options = optimoptions('particleswarm','InertiaRange',[0.2 1.2]);
[x,fval] = particleswarm(@Obj_fun3,narvs,x_lb,x_ub,options)%% 个体学习因子,默认的是1.49(压缩因子)
options = optimoptions('particleswarm','SelfAdjustmentWeight',2);
[x,fval] = particleswarm(@Obj_fun3,narvs,x_lb,x_ub,options)%% 社会学习因子,默认的是1.49(压缩因子)
options = optimoptions('particleswarm','SocialAdjustmentWeight',2);
[x,fval] = particleswarm(@Obj_fun3,narvs,x_lb,x_ub,options)%% 最大的迭代次数,默认的是200*nvars
options = optimoptions('particleswarm','MaxIterations',10000);
[x,fval] = particleswarm(@Obj_fun3,narvs,x_lb,x_ub,options)%% 领域内粒子的比例 MinNeighborsFraction,默认是0.25
options = optimoptions('particleswarm','MinNeighborsFraction',0.2);
[x,fval] = particleswarm(@Obj_fun3,narvs,x_lb,x_ub,options)%% 函数容忍度FunctionTolerance, 默认1e-6, 用于控制自动退出迭代的参数
options = optimoptions('particleswarm','FunctionTolerance',1e-8);
[x,fval] = particleswarm(@Obj_fun3,narvs,x_lb,x_ub,options)%% 最大停滞迭代数MaxStallIterations, 默认20, 用于控制自动退出迭代的参数
options = optimoptions('particleswarm','MaxStallIterations',50);
[x,fval] = particleswarm(@Obj_fun3,narvs,x_lb,x_ub,options)%% 不考虑计算时间,同时修改三个控制迭代退出的参数
tic
options = optimoptions('particleswarm','FunctionTolerance',1e-12,'MaxStallIterations',100,'MaxIterations',100000);
[x,fval] = particleswarm(@Obj_fun3,narvs,x_lb,x_ub,options)
toc%% 在粒子群结束后调用其他函数进行混合求解
tic
options = optimoptions('particleswarm','FunctionTolerance',1e-12,'MaxStallIterations',50,'MaxIterations',20000,'HybridFcn',@fmincon);
[x,fval] = particleswarm(@Obj_fun3,narvs,x_lb,x_ub,options)
toc


5.PSO算法进阶应用
(1)求解方程组


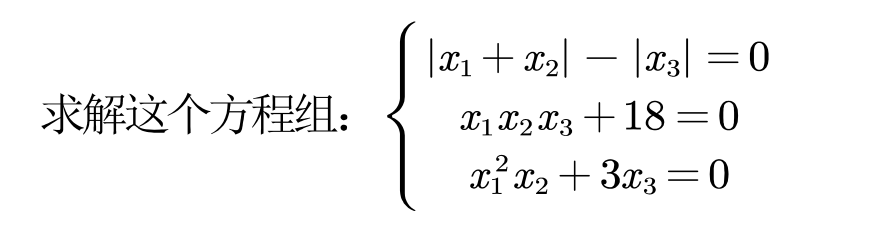
①vpasolve函数
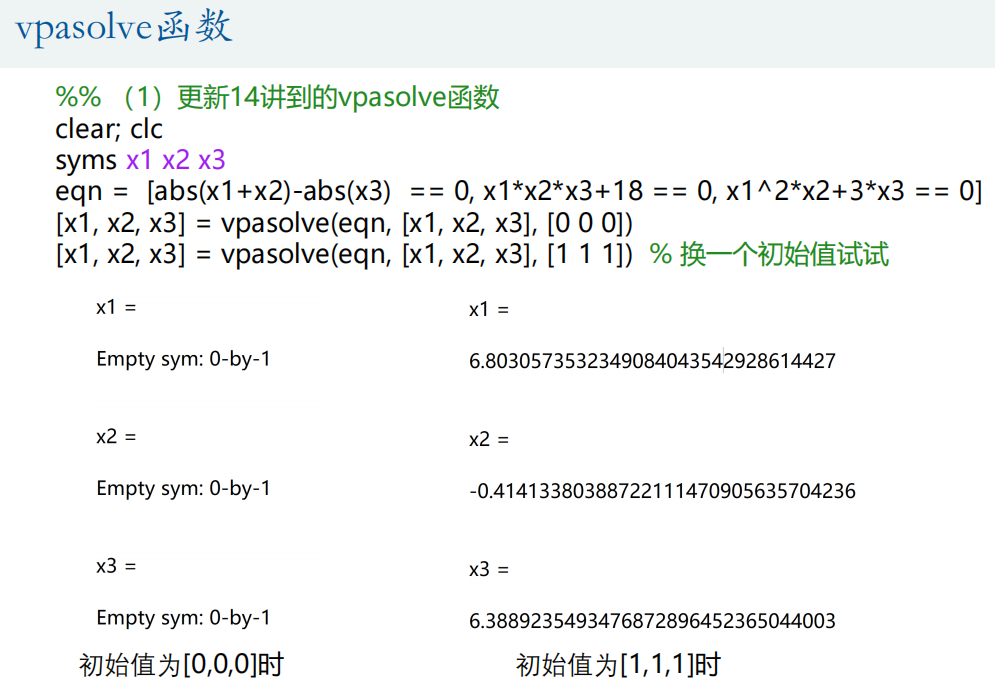
②fsolve函数

③粒子群算法


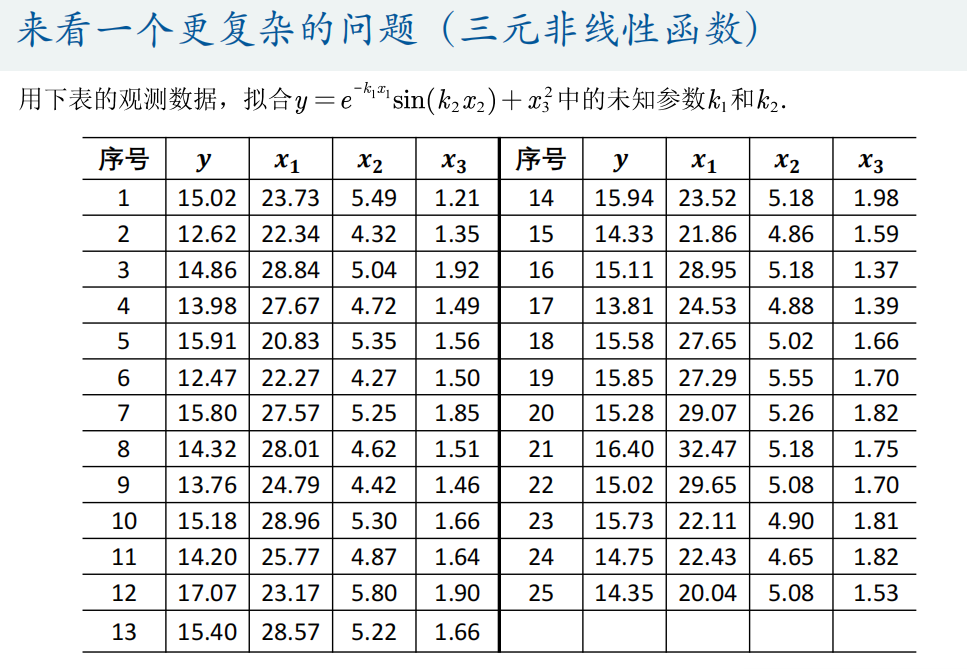
(2)多元函数拟合
Matlab自带的拟合工具箱只能对一元函数和二元函数进行拟合。


①fmincon函数

②fminsearch函数和fminunc函数(无约束)

③lsqcurvefit函数

④粒子群算法

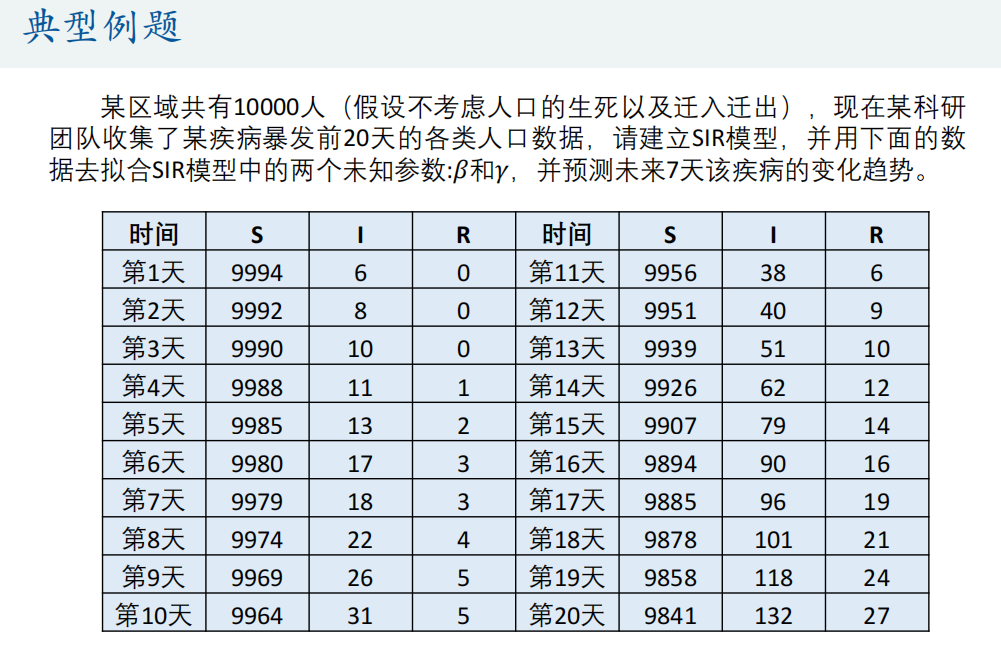
(3)拟合微分方程
如果微分方程或者微分方程组有解析解(dsolve函数能求出来),那么这时候就转换为了函数拟合问题,例如人口预测问题(阻滞增长模型);
我们这里讨论的拟合微分方程指的是只能用ode45这类函数求出数值解的情况。

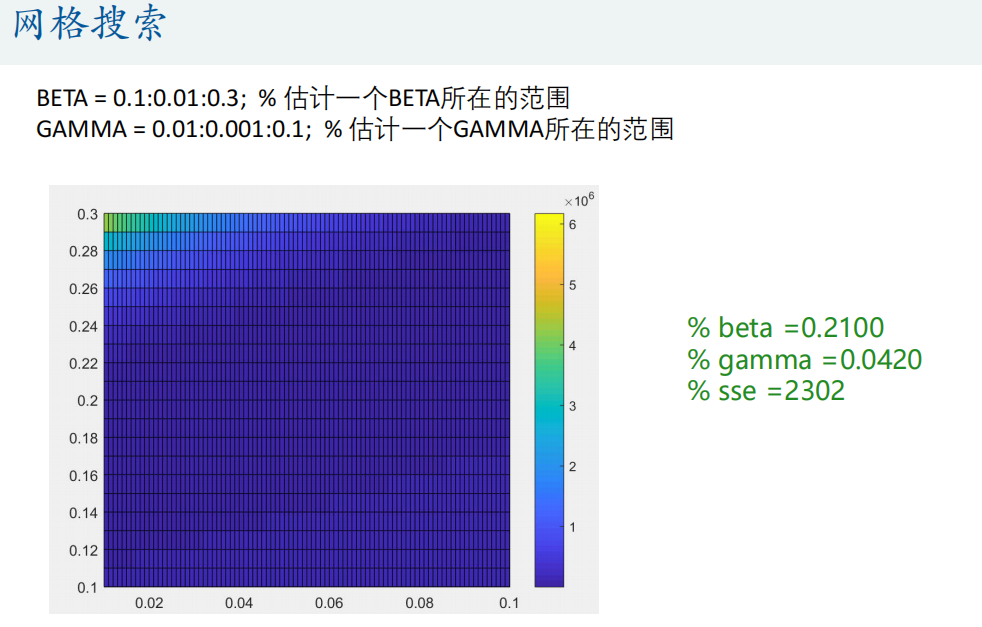
①网格搜索法

<SIR_fun.m>
function dx=SIR_fun(t,x,beta,gamma) % beta: 易感染者与已感染者接触且被传染的强度% gamma: 康复率dx = zeros(3,1); % x(1)表示S x(2)表示I x(3)表示RC = x(1)+x(2); % 传染病系统中的有效人群,也就是N' = S+Idx(1) = - beta*x(1)*x(2)/C; dx(2) = beta*x(1)*x(2)/C - gamma*x(2);dx(3) = gamma*x(2);
end<main.m>
load mydata.mat % 导入数据(共三列,分别是S,I,R的数量)
n = size(mydata,1); % 一共有多少行数据
true_s = mydata(:,1);
true_i = mydata(:,2);
true_r = mydata(:,3);
figure(1)
plot(1:n,true_s,'r-',1:n,true_i,'b-',1:n,true_r,'g-') % S的数量太大了
legend('S','I','R')
plot(1:n,true_i,'b-',1:n,true_r,'g-') % 单独画出真实的I和R的数量
hold on % 等会接着在这个图形上面画图% 随便先给一组参数来计算微分方程的数值解
beta = 0.1; % 易感染者与已感染者接触且被传染的强度
gamma = 0.01; % 康复率
[t,p]=ode45(@(t,x) SIR_fun(t,x,beta,gamma), [1:n],[true_s(1) true_i(1) true_r(1)]);
% p就是计算的数值解,它有三列,分别是S I R的数量
p = round(p); % 对p进行四舍五入(人数为整数)plot(1:n,p(:,2),'b--',1:n,p(:,3),'g--')
legend('I','R','拟合的I','拟合的R')
hold off
% 计算残差平方和
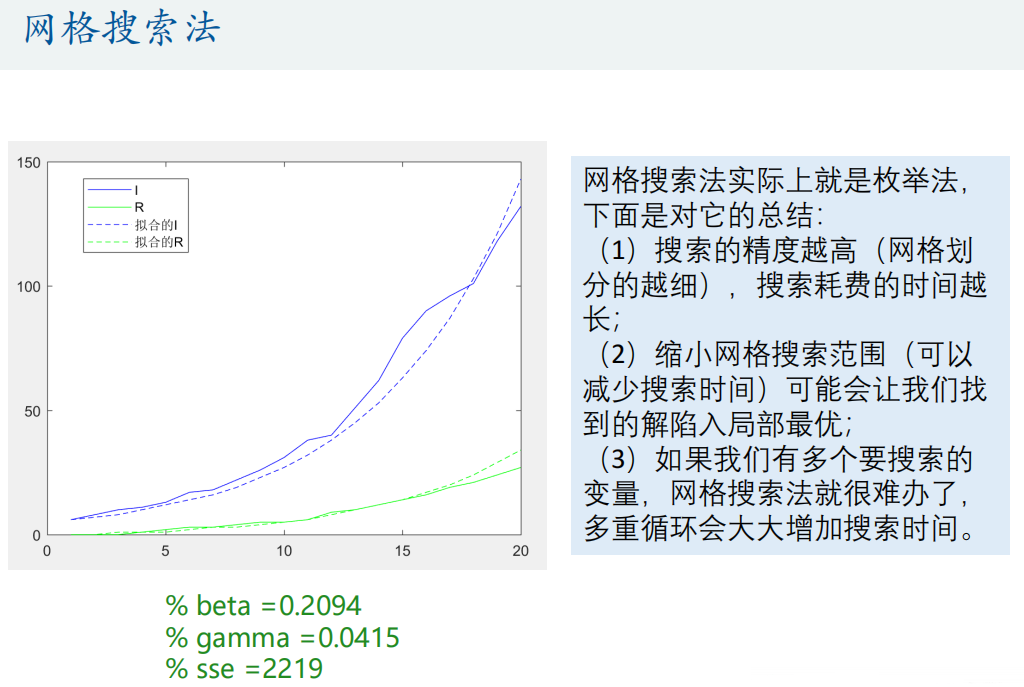
sse = sum((true_s - p(:,1)).^2 + (true_i - p(:,2)).^2 + (true_r - p(:,3)).^2)%% 网格法搜索(枚举法) 地毯式搜索
BETA = 0.1:0.01:0.3; % 估计一个BETA所在的范围
GAMMA = 0.01:0.001:0.1; % 估计一个GAMMA所在的范围
n1 = length(BETA);
n2 = length(GAMMA);
SSE = zeros(n1,n2); % 初始化残差平方和矩阵
for i = 1:n1for j = 1:n2beta = BETA(i);gamma = GAMMA(j);[t,p]=ode45(@(t,x) SIR_fun(t,x,beta,gamma), [1:n],[true_s(1) true_i(1) true_r(1)]);% p就是计算的数值解,它有三列,分别是S I R的数量p = round(p); % 对p进行四舍五入(人数为整数)% 计算残差平方和sse = sum((true_s - p(:,1)).^2 + (true_i - p(:,2)).^2 + (true_r - p(:,3)).^2);SSE(i,j) = sse;end
end
% 画出SSE这个矩阵的热力图,放到论文中显得高大上
figure(2)
pcolor(GAMMA,BETA,SSE) % 注意,这里GAMMA和BETA的顺序不能反了(类似于mesh函数的用法)
colorbar % 加上颜色条
% 找到sse最小的那组参数
min_sse = min(min(SSE)); % min(SSE)是找出每一列的最小值,因此我们还需要再使用一次min函数才能找到整个矩阵里面的最小值
[r,c] = find(SSE == min_sse,1); % find后面加了一个1,表示返回第一个最小值所在的行和列的序号
beta = BETA(r)
gamma = GAMMA(c)figure(3)
plot(1:n,true_i,'b-',1:n,true_r,'g-') % 单独画出真实的I和R的数量
hold on
[t,p]=ode45(@(t,x) SIR_fun(t,x,beta,gamma), [1:n],[true_s(1) true_i(1) true_r(1)]);
% p就是计算的数值解,它有三列,分别是S I R的数量
p = round(p); % 对p进行四舍五入(人数为整数)
plot(1:n,p(:,2),'b--',1:n,p(:,3),'g--')
legend('I','R','拟合的I','拟合的R')
hold off
% 计算残差平方和
sse = sum((true_s - p(:,1)).^2 + (true_i - p(:,2)).^2 + (true_r - p(:,3)).^2)
% beta =0.2100
% gamma =0.0420
% sse =2302%% 思考:能不能再让这个找到的结果更好点?
BETA = 0.2:0.0001:0.22; % 缩小BETA所在的搜索范围
GAMMA = 0.041:0.0001:0.043; % 缩小GAMMA所在的搜索范围
% 这样可能会陷入局部最优解
% beta =0.2094
% gamma =0.0415
% sse =2219
②粒子群算法
<SIR_fun.m>
function dx=SIR_fun(t,x,beta,gamma) % beta: 易感染者与已感染者接触且被传染的强度% gamma: 康复率dx = zeros(3,1); % x(1)表示S x(2)表示I x(3)表示RC = x(1)+x(2); % 传染病系统中的有效人群,也就是N' = S+Idx(1) = - beta*x(1)*x(2)/C; dx(2) = beta*x(1)*x(2)/C - gamma*x(2);dx(3) = gamma*x(2);
end
<Obj_fun.m>
function f = Obj_fun(h) % h就是我们要估计的目标函数里面的参数% h的长度就是我们待估参数的个数global true_s true_i true_r n % 在子函数中使用全局变量前也需要声明下beta = h(1); % 易感染者与已感染者接触且被传染的强度gamma = h(2); % 康复率[t,p]=ode45(@(t,x) SIR_fun(t,x,beta,gamma), [1:n],[true_s(1) true_i(1) true_r(1)]); p = round(p); % 对p进行四舍五入(人数为整数)% p的第一列是易感染者S的数量,p的第二列是患者I的数量,p的第三列是康复者R的数量f = sum((true_s - p(:,1)).^2 + (true_i - p(:,2)).^2 + (true_r - p(:,3)).^2);
end
<main.m>
load mydata.mat % 导入数据(共三列,分别是S,I,R的数量)
global true_s true_i true_r n % 定义全局变量
n = size(mydata,1); % 一共有多少行数据
true_s = mydata(:,1);
true_i = mydata(:,2);
true_r = mydata(:,3);
figure(1)
% plot(1:n,true_s,'r-',1:n,true_i,'b-',1:n,true_r,'g-') % S的数量太大了
% legend('S','I','R')
plot(1:n,true_i,'b-',1:n,true_r,'g-') % 单独画出I和R的数量
legend('I','R')% 粒子群算法来求解
lb = [0 0];
ub = [1 1];
options = optimoptions('particleswarm','Display','iter','SwarmSize',100,'PlotFcn','pswplotbestf');
[h, fval] = particleswarm(@Obj_fun,2,lb,ub,options) % h就是要优化的参数,fval是目标函数值
% options = optimoptions('particleswarm','SwarmSize',100,'FunctionTolerance',1e-12,'MaxStallIterations',100,'MaxIterations',100000);
% [h, fval] = particleswarm(@Obj_fun,2,lb,ub,options) % h是要优化的参数,fval是目标函数值beta = h(1); % 易感染者与已感染者接触且被传染的强度
gamma = h(2); % 康复率
[t,p]=ode45(@(t,x) SIR_fun(t,x,beta,gamma), [1:n],[true_s(1) true_i(1) true_r(1)]);
p = round(p); % 对p进行四舍五入(人数为整数)
sse = sum((true_s - p(:,1)).^2 + (true_i - p(:,2)).^2 + (true_r - p(:,3)).^2) % 计算残差平方和figure(3) % 真实的人数和拟合的人数放到一起看看
plot(1:n,true_i,'b-',1:n,true_r,'g-')
hold on
plot(1:n,p(:,2),'b--',1:n,p(:,3),'g--')
legend('I','R','拟合的I','拟合的R')% 预测未来的趋势
N = 27; % 计算N天
[t,p]=ode45(@(t,x) SIR_fun(t,x,beta,gamma), [1:N],[true_s(1) true_i(1) true_r(1)]);
p = round(p); % 对p进行四舍五入(人数为整数)
figure(4)
plot(1:n,true_i,'b-',1:n,true_r,'g-')
hold on
plot(1:N,p(:,2),'b--',1:N,p(:,3),'g--')
legend('I','R','拟合的I','拟合的R')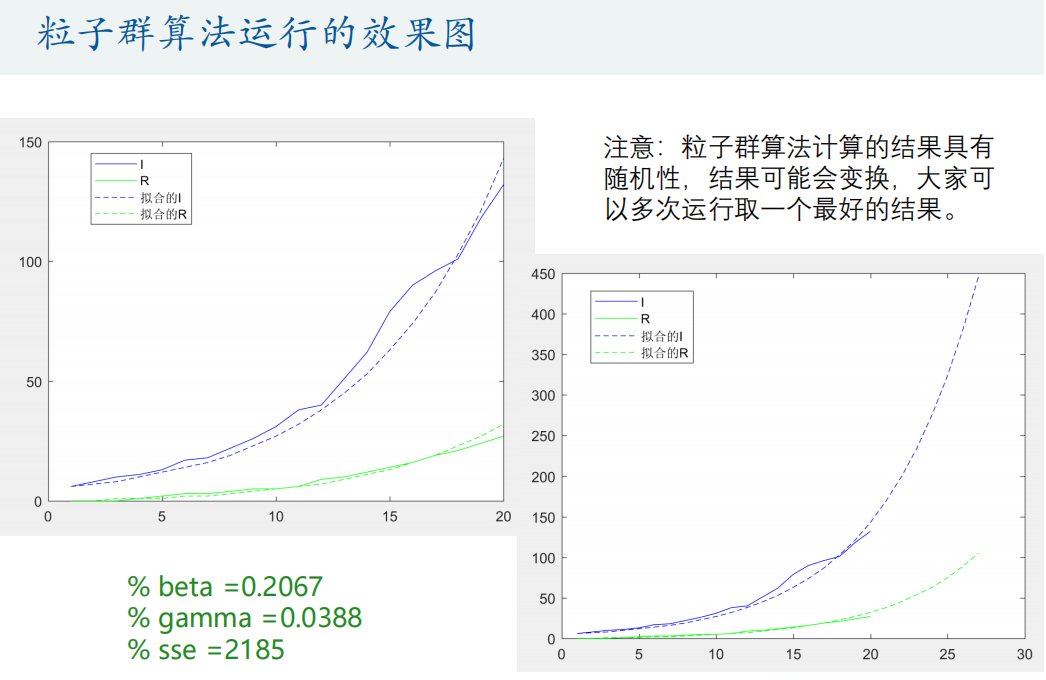
③粒子群算法进阶(参数与自变量相关)

<SIR_fun.m>
function dx=SIR_fun(t,x,beta1,beta2,a,b) % beta1 : t<=15时,易感染者与已感染者接触且被传染的强度% beta2 : t>15时,易感染者与已感染者接触且被传染的强度% a : 康复率gamma = a+bt% b : 康复率gamma = a+btif t <=15beta = beta1;elsebeta = beta2;endgamma = a + b * t; dx = zeros(3,1); % x(1)表示S x(2)表示I x(3)表示RC = x(1)+x(2); % 传染病系统中的有效人群,也就是N' = S+Idx(1) = - beta*x(1)*x(2)/C; dx(2) = beta*x(1)*x(2)/C - gamma*x(2);dx(3) = gamma*x(2);
end<Obj_fun.m>
function f = Obj_fun(h) % h是我们要估计的目标函数里面的参数% h的长度是我们待估参数的个数global true_s true_i true_r n % 在子函数中使用全局变量前也需要声明下beta1 = h(1); % t<=15时,易感染者与已感染者接触且被传染的强度beta2 = h(2); % t>15时,易感染者与已感染者接触且被传染的强度a = h(3); % 康复率gamma = a+btb = h(4); % 康复率gamma = a+bt[t,p]=ode45(@(t,x) SIR_fun(t,x,beta1,beta2,a,b) , [1:n],[true_s(1) true_i(1) true_r(1)]); p = round(p); % 对p进行四舍五入(人数为整数)% p的第一列是易感染者S的数量,p的第二列是患者I的数量,p的第三列是康复者R的数量f = sum((true_s - p(:,1)).^2 + (true_i - p(:,2)).^2 + (true_r - p(:,3)).^2);
end<main.m>
load mydata.mat % 导入数据(共三列,分别是S,I,R的数量)
global true_s true_i true_r n % 定义全局变量
n = size(mydata,1); % 一共有多少行数据
true_s = mydata(:,1);
true_i = mydata(:,2);
true_r = mydata(:,3);
figure(1)
plot(1:n,true_i,'b-',1:n,true_r,'g-') % 单独画出I和R的数量
legend('I','R')% 粒子群算法来求解
% beta1,beta2,a,b
% 给定参数的搜索范围(根据题目来给),后期可缩小范围
lb = [0 0 -1 -1];
ub = [1 1 1 1];
% lb = [0 0 -0.2 -0.2];
% ub = [0.3 0.3 0.2 0.2];
options = optimoptions('particleswarm','Display','iter','SwarmSize',200);
[h, fval] = particleswarm(@Obj_fun, 4, lb, ub, options) % h就是要优化的参数,fval是目标函数值, 第二个输入参数4代表我们有4个变量需要搜索beta1 = h(1); % t<=15时,易感染者与已感染者接触且被传染的强度
beta2 = h(2); % t>15时,易感染者与已感染者接触且被传染的强度
a = h(3); % 康复率gamma = a+bt
b = h(4); % 康复率gamma = a+bt
[t,p]=ode45(@(t,x) SIR_fun(t,x,beta1,beta2,a,b), [1:n],[true_s(1) true_i(1) true_r(1)]);
p = round(p); % 对p进行四舍五入(人数为整数)figure(3) % 真实的人数和拟合的人数对比绘图
plot(1:n,true_i,'b-',1:n,true_r,'g-')
hold on
plot(1:n,p(:,2),'b--',1:n,p(:,3),'g--')
legend('I','R','拟合的I','拟合的R')% 预测未来的趋势
N = 27; % 计算N天
[t,p]=ode45(@(t,x) SIR_fun(t,x,beta1,beta2,a,b), [1:N],[true_s(1) true_i(1) true_r(1)]);
p = round(p); % 对p进行四舍五入(人数为整数)
figure(4)
plot(1:n,true_i,'b-',1:n,true_r,'g-')
hold on
plot(1:N,p(:,2),'b--',1:N,p(:,3),'g--')
legend('I','R','拟合的I','拟合的R')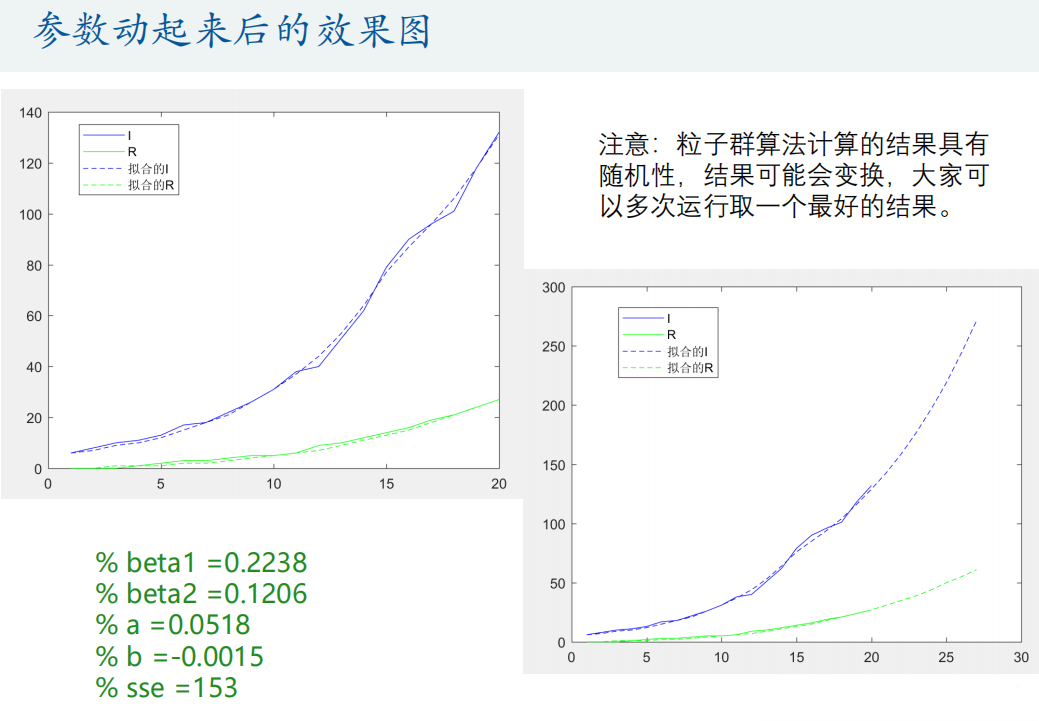
内容原作者:数学建模清风
学习用途,仅作参考。