002-���ѧϰ��ѧ����(�����硢�ݶ��½�����ʧ����)
�����ڽ����˹����ܵĽ���֮ǰ�������֪���������ʣ���ʵҲ����Ҫ���˽�һ���˹����ܵ���ѧ��������Ȼ�����û�취���½��ˡ�
����Ŀ¼���£�
- ǰ�ԡ�
- �ලѧϰ���ලѧϰ��
- �����硣
- ��ʧ������
- �ݶ��½���
0. ǰ��
�˹����ܿ��Թ����һ�仰������ض��������ҳ����ʵ���ѧ����ʽ��Ȼ��һֱ�Ż�����ʽ��ֱ���������ʽ��������Ԥ��δ����
����������һ��һ��ķ�����仰��
- ����ض�������
����������Ҫ֪�����ǣ��˹�������ʵ����Ϊ���ü��������������һ�����ܣ�Ϊʲô��ô˵�أ���һ���˹����ܵ����ӣ�
�����˿���һ�������ͼƬ���Ϳ�������֪�����������è�����ǹ������Ǽ����ȴ�����ԣ������������Էֳ������ô��ͻ���һ������ͼ�����ܵ��˹�����С���ӡ�
�����ͼ���������������˵���ض��������������ϣ��д��һ���˹����ܵij������������顣
����һЩ�����ij�������������ʶ��,Ŀ����,ͼ��ָ�,��Ȼ���Դ��� �ȵȡ�
- �ҳ����ʵ���ѧ����ʽ��
ѧ���ߵ���ѧ�����м����˼ά���˶�֪���������м������е����鶼��������ѧ��������������������Ȳ��������ѧ����ʽ����ɢ����������Ҳ�������Ĵ�����ߣ��������ܴﵽ��ʾ�ض������һ��Ŀ�ġ�
����˵�����һ�����������û���Ԥ��������������µı���ʽ��
f(x)=a?x1+b?x22+c?x33+df(x) = a*x_{1} + b*x_{2}^{2} + c*x_{3}^{3} + d f(x)=a?x1?+b?x22?+c?x33?+d
�������£�
1��x1��x2��x3x1��x2��x3x1��x2��x3 ���Կ����ж����Ϻû����ж����ݣ���������ǣ���Ƥ��·���û���������Ƥ��ɫ�ȵȡ�
2��a��b��c��da��b��c��da��b��c��d �����������ʽ��ϵ����һ����ѧ����ʽ�������ˣ���ô��������Ҫ������������ҳ����ʵ�ϵ����ʹ���������ʽ���Ժܺõ��жϳ����������ĺû���
���ԣ���������ᵽ���ض�������������ѧ����ʽ��ʾ��������Ȼ�����ǻᾡ�����Ҽ���Ч�ı���ʽ��
- һֱ�Ż��������ʽ��
�ϱ���������ʽ֮�ᷢ�ֵ�����ʽȷ������֮��ҪѰ�Һ��ʵ�ϵ���ˣ�Ѱ��ϵ���Ĺ��̾ͱ���֮Ϊѵ������Ĺ��̡�
�����Ż�����ʽ����Ҫ˼���ǣ�һֱ����ϵ��ֵ��ʹ��Ԥ��������� �� ��ʵ����֮��IJ�ྡ���ܵ���С��
���磺����Ԥ��������� f1(x)f_{1}(x)f1?(x)����ʵ������yyy������ͨ��һֱ�ı�ϵ����ֵ�����ҳ�����ʹ��Ԥ����������ʵ����֮�������С��һ�飬��С��һ�����ݾ���������Ҫ��ϵ����
���У�������㹫ʽ���������µı���ʽ��
loss=(f1(x)?y)2loss = \sqrt{(f_{1}(x) - y )^2 } loss=(f1?(x)?y)2?
ͨ���������ʽ���õ��� loss ֵ������ʵֵ��Ԥ��ֵ֮��ľ��롣
Ȼ���������Ż�����������loss ����ʽ�����еģ�Ŀ�ľ�����loss��ֵ�ﵽ��С��
��Ϊlossֵ�ﵽ��С��ʱ����ζ�����ǵ�Ԥ��ֵ����ʵֵ����������Ԥ��Խȷ��
����ֵ��һ����ǣ������
loss����ʽ���Ż����̣���ʵ���ǽ�loss��ʽ�Ժ���f(x)��ϵ�������Ե�
loss��С��ʱ����ζ�Ŵ�ʱ��ϵ������ʡ������ϸ�����¿���
- ���Ż��õı���ʽԤ��δ����
�����ϱߵ��Ż�����ʱ������õ�һ����Ժ�һ���ϵ����Ȼ��Ϳ���ʹ�����������Ԥ��δ���������ˡ�
����Ǵﵽ���˹�ֻ�ܵ�Ŀ���ˡ�
���ԣ��±����Ǿ�Ҫ��ϸ���ۣ���ѧ����ʽ�Ĺ��������뺯���Ĺ�����������Ż���
1. ������
�������Ӣ���ǣ�neural network ����ƣ�NN����
��������ʵ���DZ��ε���ѧ����ʽ����ͨ��ƴװ�����������Ԫ����ģ�����ѧ����ʽ��
1.01. ʲô��������
һ˵�����磬��������뵽�ľ�����Ԫ����ʵû����������������ʾ��Ǵ���Ԫ�����ݱ�����ġ�����������һ����ȡ�
1.01.001. ��Ԫ
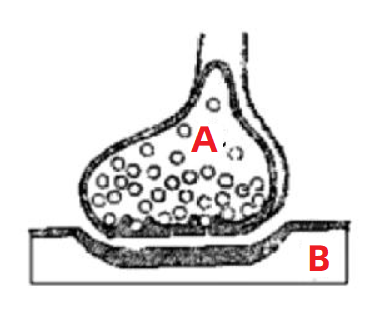
��ͼ��ʾ�����ͼ���������������Ԫ�ķŴ�ͼ��
ͨ����������� A ��λ���������Ҫָ�� B ��λ��Ӧ����Ҫͨ�� A �� B �����źš�����źŵ�ǿ��Ӱ���� B ��Ӧ��ǿ����
���ԣ������������Ĺ�˼���ڣ�
������һ����������Ԫ�Ľṹ����һ���ڵ��������A���Ŀ��ƣ� �Լ�Ȩ�����źŵ�ǿ������ͬ������һ���ڵ�������B���ķ�Ӧ����
��仰�����ڿ�����û��ϵ���и�ӡ��ͺã��������¿��ɡ�
1.01.002. ������
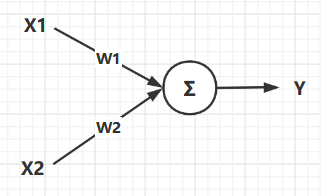
��ͼ��ʾ����һ�����������ṹ������ṹ����ѧ����ʽ�ǣ�Y=X1?W1+X2?W2Y = X1*W1 + X2*W2Y=X1?W1+X2?W2 ��
ͼ�е�ԲȦ���ǾͰ����������Ԫ��ͼ�еĸ����ṹ�������£�
-
����
X1,X2�����������������������൱�ھ���������Է����Ŀ������ -
W1,W2����Ȩ���������������Ʋ�ͬ�����ź�ռ�ȴ�С�����ݣ����磺���ÿ���X1��������һ�㣬��ô��Ӧ��W1�ʹ�һ�㡣 -
Y�������������������������Ȩ������֮������ս��������Ԫ��Ҳ�������ն�����ij����λ�Ŀ����źš�
1.02. ���������ѧԭ��
���������ѧԭ���dz������ܽ���������һ�仰����ͬ���������������Ե�Ȩ��֮���ĺ���Ϊ������Ҫ�Ľ����
��ʵ�Ϳ��Դ�������Ϊ���ǵĺ��� �� f(x)=a?x1+b?x2f(x) = a*x1 + b*x2f(x)=a?x1+b?x2 һ������ν��Ȩ�ؾ������Ƿ��̵�ϵ����
ϸ�ĵ��˹۲��ϱߵĹ�ʽ�ͻᷢ�֣�һ����Ԫ�ڵ��Ϳ��������һ������ʽ������������������������ͼ��������������һ����Ԫ�ڵ�Ĺ�ʽ��
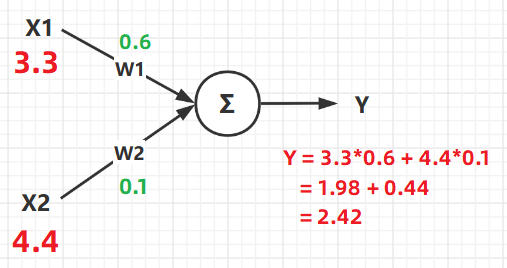
��ͼ�п��Կ��ó��������յ������� Y ���� ���루X�� �Լ� Ȩ�أ�W�� ��ͬ�����ġ�
�������յļ����� Y ��ʵ˵���˾���һ�����㹫ʽ��Y=X1?W1+X2?W2Y = X1*W1 + X2*W2Y=X1?W1+X2?W2 �������ʽ�ĺ�����Ӧ�ö����ף�����ͬ������ ���䲻ͬ��Ȩ�� ���Ӷ��õ���Ҫ�Ľ����
�������������һ����Ԫ����ѧԭ����������Ԫ�ĸ�������֮��ԭ���Դ����ƣ�ֻ������Ҫ����Ȩ��W�Լ�����X�ĸ������ѡ�
�±߾Ϳ��Կ�����һ�������������������ṹ��
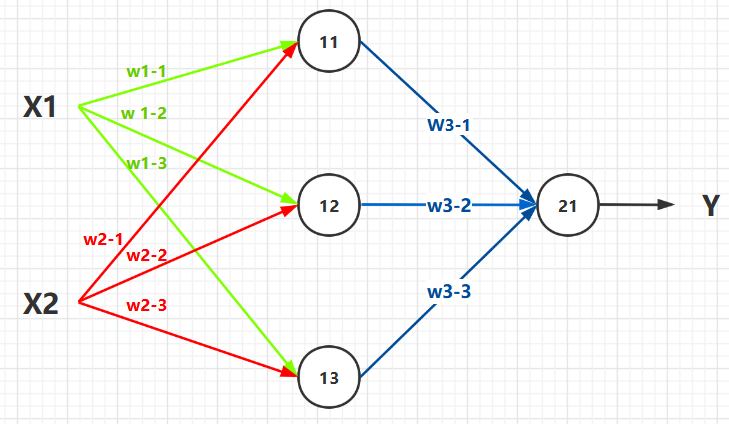
-
��һ��ڵ㣺
11��12��13���ڶ���ڵ㣺21�� -
���룺
X1��X2�� ��� ��Y��
���ǣ����ݹ�ʽ����� ���� ���������� Ȩ���� �ó������Ƶ� ��
-
���룺
X1��X2�� -
�ڵ�
11��ֵ�� Y11=X1?W1?1+X2?W2?1Y_{11} = X_{1} * W_{1-1} + X_{2}*W_{2-1}Y11?=X1??W1?1?+X2??W2?1? . -
�ڵ�
12��ֵ�� Y12=X1?W1?2+X2?W2?2Y_{12} = X_{1} * W_{1-2} + X_{2}*W_{2-2}Y12?=X1??W1?2?+X2??W2?2? . -
�ڵ�
13��ֵ�� Y13=X1?W1?3+X2?W2?3Y_{13} = X_{1} * W_{1-3} + X_{2}*W_{2-3}Y13?=X1??W1?3?+X2??W2?3? . -
�ڵ�
21��ֵ�����������Y�� Y=Y21=Y11?W3?1+Y12?W3?2+Y13?W3?3Y = Y_{21} = Y_{11} * W_{3-1} + Y_{12}*W_{3-2} + Y_{13}*W_{3-3}Y=Y21?=Y11??W3?1?+Y12??W3?2?+Y13??W3?3? .
���ԣ����յ�����ʽ��Ϊ��
Y=Y11?W3?1+Y12?W3?2+Y13?W3?3=(X1?W1?1+X2?W2?1)?W3?1+(X1?W1?2+X2?W2?2)?W3?2+(X1?W1?3+X2?W2?3)?W3?3Y = Y_{11} * W_{3-1} + Y_{12}*W_{3-2} + Y_{13}*W_{3-3} \\ = (X_{1} * W_{1-1} + X_{2}*W_{2-1})*W_{3-1} \\ + (X_{1} * W_{1-2} + X_{2}*W_{2-2})*W_{3-2} \\+ (X_{1} * W_{1-3} + X_{2}*W_{2-3})*W_{3-3} Y=Y11??W3?1?+Y12??W3?2?+Y13??W3?3?=(X1??W1?1?+X2??W2?1?)?W3?1?+(X1??W1?2?+X2??W2?2?)?W3?2?+(X1??W1?3?+X2??W2?3?)?W3?3?
���ǣ����ǿ��Է��֣������������Ķѵ���ʽ�����ǿ�����ϳɺܶ����ѧ������
����������磬����Ŀ�����ڽ���ѧ��ʽ��������������ΪʲôҪ��������������Ϊ�����������������ȽϷ����¡�
1.03 �ܽ�
��ĿǰΪֹ���Ѿ�֪���������������������֪������������ѧ��ʽ֮��Ĺ�ϵ��
��ʱ����Ҫ��ȷ��֪ʶ���ǣ�
- �˹����ܾ���ʹ�����е����ݣ���ϳ�һ����������Ԥ��δ���Ĺ�ʽ��
- �����ʽ��ϵ����Ҫһֱ�������Ӷ��ҳ�һ����Ϊ���ʣ���ȷ�ʽϸߵ�ϵ����
- ��Ϊϵ����Ѱ����Ҫ�����ļ��㣬������Ҫ�������ʽ���������ʾ�����ģ���Ϊ�ڼ������������ʾ��ʱ�������Ϊ���㡣
2. �ලѧϰ���ලѧϰ
���֪ʶ��Ƚϼ���һЩ�����ĸ��
�ලѧϰ�����������ռ������������б�ǩ�ġ�
����˵�������ռ������������Ѿ��ֺ���ġ�
����˵����ǰ��ǰ��һ���������ݣ�
x1, x2, x6, x9, x13�������y1�ࡣx3, x4, x5, x8, x11�������y2�ࡣx7, x10, x12�������y3�ࡣ
Ȼ�����������ʹ����Щ���ݵ�ʱ�Ϳ���ʹ�����б�ǩ�����ݣ�ȥ��ϳ����ߣ�����Ԥ��δ����
�ලѧϰ�������ռ������������ޱ�ǩ�ġ�
����˵���ռ��������ݲ�û�й̶������������Ҫ������������ھ������ڲ�����ϵ�������Ǿ��࣬�ҳ����

��ͼ��ʾ���ھ�������ڲ�����ϵ�������Զ����ࡣ
3. ��ʧ����
�ϱ߽����ˣ���ʧ���������þ��Ǽ��� ��ʵֵ �� Ԥ��ֵ ֮������ ��������ʵ���Լ�����Ϊ��������֮��IJ�ࣩ��
�������һЩ�����ļ�����ʧ�������Թ��������ʹ�á�
3.01. һЩǰ��
�������һЩ��ǰ�ᣬ�±ߵļ�����ʧ����ͨ�õ����֡�
- ��ʵֵ��
y�����������ijһ������x����ʵ��ǩ�� - Ԥ��ֵ��
f(x)���������������x��Ԥ���ǩ�� - ��������
m������������ÿ����������������м��㣬���磺ijһ������5��x���õ�5��Ԥ�����������m=5.
3.02. ����ֵ��ʧ����
��ʵ���Ǽļ��� ��ʵֵ �� Ԥ��ֵ ֮��ľ���ֵ������ѡ�
��ʽ��
J(y,f(x))=J(w,b)=1m��i=1m�Oyi?f(xi)�OJ(y,f(x)) = J(w,b) = \frac{1}{m}\sum^{m}_{i=1}|y_{i}-f(x_{i})| J(y,f(x))=J(w,b)=m1?i=1��m?�Oyi??f(xi?)�O
������
- J(y,f(x))J(y,f(x))J(y,f(x)) ����˼���ǣ������ʧ�����IJ����ǣ����DZ�ǩ
y�� Ԥ������f(x)�� - J(w,b)J(w,b)J(w,b) ����˼�ǣ������ʧ������Ŀ�����Ż�����
w��b�������w��b��ʵ����ϵ���ľ�����ʽ�� - ��߾���ļ��㹫ʽ���ǣ�������
m���������������m�������ľ������ֵ�ͣ�Ȼ�������ֵ��
3.03 ��������ʧ����
���ǽ��ϱ�ʽ�ӵľ���ֵ����ƽ���ͺ��ˡ�
��ʽ��
J(y,f(x))=J(w,b)=12m��i=1m(yi?f(xi))2J(y,f(x)) = J(w,b) = \frac{1}{2m}\sum^{m}_{i=1}(y_{i}-f(x_{i}))^2 J(y,f(x))=J(w,b)=2m1?i=1��m?(yi??f(xi?))2
���ͣ�
- ����ֻ�ǽ�����ֵ������ƽ��������
m�����˳���2m��
3.04 ��������ʧ����
����ͱȽ��鷳�ˣ���������ʧ����һ�����ڽ���������⡣
��ǩ��
��ͨ���ķ��������У���ǩy��ȡֵһ��ֻ�� 0 �� 1 ��
1 ��ʾ�ǵ�ǰ��� 0 ��ʾ���ǵ�ǰ���
��ʽ��
J(y,f(x))=J(w,b)=?1m��i=1m(f(x)?log(y)+(1?f(x))?log(1?y))J(y,f(x)) = J(w,b) = -\frac{1}{m}\sum^{m}_{i=1}(\ f(x)*log(y) + (1-f(x))*log(1-y)\ ) J(y,f(x))=J(w,b)=?m1?i=1��m?( f(x)?log(y)+(1?f(x))?log(1?y) )
���ͣ�
- �ϱ�˵�ˣ�
y��f(x)��ֻ��ȡ1��0�е�һ�ֿ����ԡ����ԣ�������ʽ��Ч�����ǣ� - ��� y�� f(x) ��ͬ���� J = 0.
����� y=1 , f(x)=1 ���Ծ�֪���ˡ�
- ��� y�� f(x) ��ͬ���� J = �����.
����� y=1 , f(x)=0 ���Ծ�֪���ˡ�
3.05 �ܽ�
���������Ѿ�ѧϰ�����ֳ�������ʧ������
��ʱ��Ӧ����һ����ȷ��֪ʶ����ǣ�
- ��ʧ����������������ʵֵ��Ԥ��ֵ֮�����ġ�
- ����ʧ������ֵԽС�ʹ�������ʵֵ��Ԥ��ֵ֮��ľ����ԽС��Ҳ����ζ��Ԥ���Խ��
4. �ݶ��½�
���˺��ˣ��ϱ߹�������֪ʶ��������һ��������������ѧ�����ˣ���ʵ���ѣ���������������
- �ϱ������ᵽ����ѧ�����Ż���ʱ��ֻ�ǽ��������۵�֪ʶ��
����֪������ʧ�������Ǻ���Ԥ��ֵ����ʵֵ֮�����Ĺ�ʽ��
����֪������ʧ������ֵԽС����ʵֵ��Ԥ��ֵ֮��ľ���ԽС��Ҳ����Ԥ���Խ��
- ���Dz�û�д��Ŵ������̽������Ż���
Ҳ����û�и��ߴ����ôʹ����ʧ������ֵԽ��ԽС��
��ʵ������ʹ�õ���ѧ֪ʶ���� ����ƫ��
4.01. ��ѧ����
������һ������ѧ�����������ݶ��½������ݡ�
- ��������
����ѧ�������Ǿ�������һ�����;��ǣ���֪һ������
f(x)�ı���ʽ�����������ʽ�ӵ���Сֵ�㡣
����ѧ�������Ǿ����õķ������ǣ�������f(x)��x��Ȼ�����ʽ��Ϊ0�������ʱ��x��ֵ����Ϊ��Сֵ���λ�á�
- ��������
���� f(x)=2?x2?12?x+20f(x) = 2*x^2-12*x+20f(x)=2?x2?12?x+20 ����Сֵ�㣬���������Сֵ��
�Ժ�����
f(x)��=4?x?12f(x)' = 4*x - 12 f(x)��=4?x?12
�����Ϊ0�������ʱ��x
��f(x)��=0��4?x?12=0�õ�x=3�� \ \ f(x)'=0 \\ �� \ 4*x-12 = 0 \\ �õ�\ x=3 �� f(x)��=0�� 4?x?12=0���� x=3
��ʱ��x = 3 ��Ϊ���� f(x) ����Сֵ�㣬����ԭ���� f(3)= 2*9-12*3+20 = 2.
���������̣���ش�Ҷ�����Ϥ�ɡ�
�±߾ͷ���һ��������̵���ѧԭ����
4.02. ��ѧ����ԭ��
�ݶȾ��ǵ�����
����ϱ��ᵽ�ķ��̵���Сֵ��⣬��ʵ����������ݶȣ�������Ϊ0��λ�ã���������͵��λ�á����忴��ͼ��
- ���� f(x)=2?x2?12?x+20f(x) = 2*x^2-12*x+20f(x)=2?x2?12?x+20 ͼ�����£�
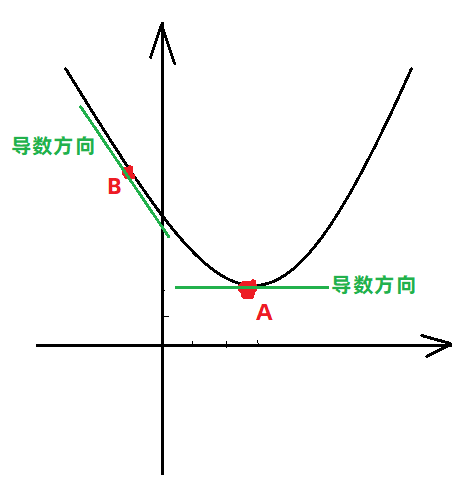
��ͼ�п��Կ����������ڲ�ͬλ�õĵ��������Dz�ͬ�ģ�ֻ������͵��λ�ã�����Ϊ
0�����Կ����õ���Ϊ0��λ�������͵㡣
�ϱ߾ٵ�������һ���Ƚϼ����ӣ�������ֻ��һ��δ֪������������ʵ����У�����һ�������кܶ�δ֪����
- ���磺f(x,y)=2?x2+2?y+4?x?yf(x,y)=2*x^2+2*y+4*x*yf(x,y)=2?x2+2?y+4?x?y
��ʱ��Ҫ��������������ÿһ��������ƫ��������÷������ÿ���������ݶȷ��� ���ݶȷ���������ݱ�С�ķ���
���ǣ��ڷ��̵�ÿ�����ϣ����ж���ݶȷ������ս���������ϲ����γ������������ݶȷ��� �����ݱ�С�ķ���
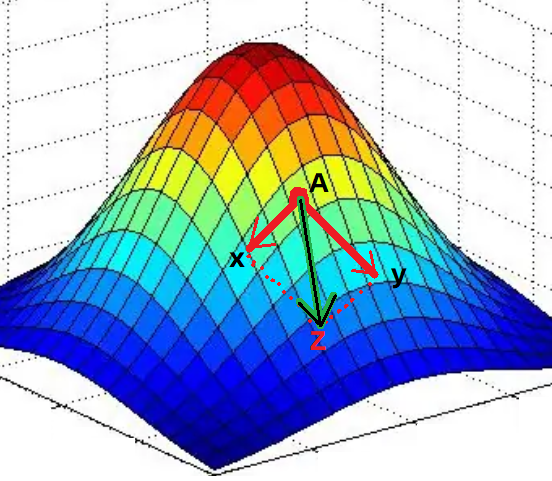
��ͼ����������������
x,y��������A���������������ƫ���Ϳ��Եõ����Ե��ݶȷ���������ɫ��ͷ�ķ���Ȼ�������ݶȽ��кϲ����õ����յ��ݶȷ���
Z��Z������Ƿ�����A�����ݱ�С�ķ�������
4.03. ��������
�ϱ߽���ԭ��������;ٳ�һ�����ӣ����Ŵ����һ���ݶ��½�����Сֵ�Ĺ��̡�
�����ʱ�ķ�����֪�����Ҹ��ݷ��̻��Ƴ���ͼ�����¡�
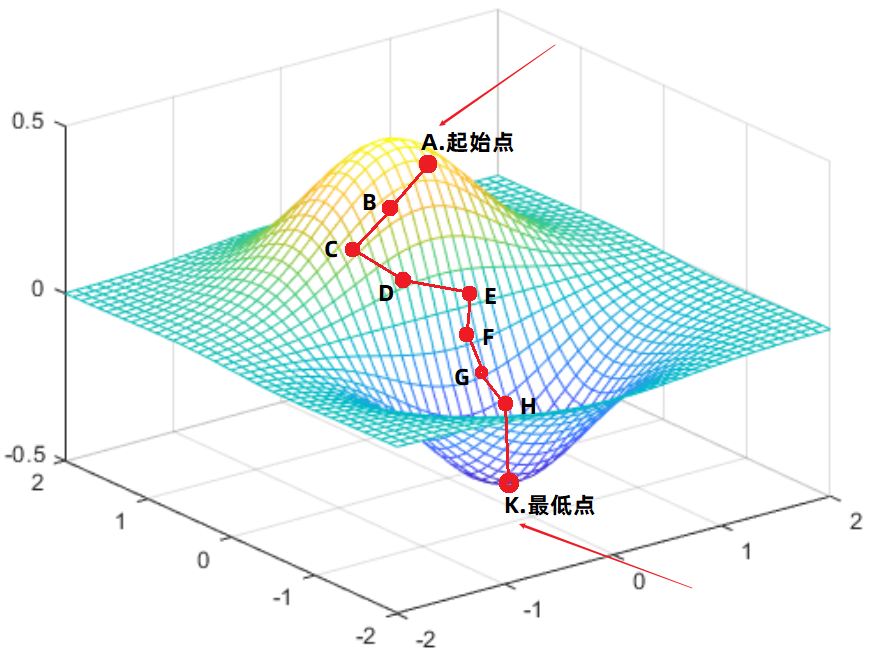
- �տ�ʼ����λ��A�㣺
1����A�㴦��Է��̵ĸ����������ƫ�������DZ���Եõ�������Ը���������ݶȷ���
2����A�㴦����������ݶȷ�����кϲ����γ����յ��ݶȷ���
3�����յ��ݶȷ������AB����
4����������AB�����߳�һ�ξ��룬�ߵ���B�㡣
- ����B�㣺 ��˼·ͬ�ϣ�
1�����B�㴦����������ݶȷ���Ȼ��ϲ������ݶȷ��õ����յ�B�㴦�ݶȷ��� BC��
2����������BC�����߳�һ�ξ��룬����C�㡣
- ���ظ��������̣�
����ij����֮������������ƫ������Ȼ��ϲ��õ����յ��ݶȷ���
Ȼ�����źϲ�����ݶȷ����߳�һ�ξ��뵽����һ���㡣
Ȼ����һֱ�ظ���
- ����K�㣺
K��������յĵ㣬������Ż��õ������ص㡣
�������������С��Ŀ��ӻ����̣����������ᵽ���µ���ѧϸ�ڲ�û���ᵽ�������±���һ���õ�����ѧ���¹�ʽ��
4.04. ���¹�ʽ
һ�������ݶ��½����µ�����ֻ�к�����ϵ����Ȼ������ϵ�����Է�Ϊ���ࣺȨ�أ�W��+ƫ�b��
���ԣ����µ�ʱ��Ҳ����������������ͺ��ˡ�
�������壺
W�� ���̵�Ȩ�ء� �����Լ�����Ϊ���̱���ǰ���ϵ����b�����̵�ƫ� �����Լ�����Ϊ�����еij�����
���磺f(x,y)=2?x2+y2+3f(x,y) = 2*x^2+y^2+3f(x,y)=2?x2+y2+3 �У�
2 , 1����Ȩ�أ�3����ƫ�
��ʽ��
- ����Ȩ��
W��Wnew=Wold?��??L?wW_{new} = W_{old} - \alpha *\frac{\partial L}{\partial w}Wnew?=Wold??��??w?L?.
ԭʼ���Ȩ���� WoldW_{old}Wold?��ԭʼ���ʱ���
W���ݶȷ�����?L?w\frac{\partial L}{\partial w}?w?L?.��\alpha�� ����һ�ξ��볤�ȣ���������������һֱ�ᵽ����һ�ξ��룩��
���� ��??L?w\alpha *\frac{\partial L}{\partial w}��??w?L? �������������
W���ݶ���һ�γ���Ϊ��\alpha�� �ľ��롣Ȼ�� �µ�
W���� �ɵ�W��ȥ��һ��������
- ����ƫ�bnew=bold?��??L?bb_{new} = b_{old} - \alpha *\frac{\partial L}{\partial b}bnew?=bold??��??b?L?.
ԭ��ͬ
W.
����Ǹ��²����������ݶ��½������ˡ�
5. �ܽ�
��ĿǰΪֹ���������˹�����֪ʶ�Ѿ����������ˣ����ʱ������������ϸƷζ��仰��
����ض��������ҳ����ʵ���ѧ����ʽ��Ȼ��һֱ�Ż�����ʽ��ֱ���������ʽ��������Ԥ��δ����
������ͻ��в�һ��������ˡ�
ok����һ�ھͽ�һ��Pytorch�Ļ���ʹ�ã�Ȼ��������յ���д������ʶ�������ˡ�