文章目录
- 简介
-
- create index
- viewing indexes
- prefix index
- Full-text indexes
-
- relevance score
- boolean
- composite indexs
-
- order of columns
- 删除index
- when indexes are ingored
- using indexes for sorting
-
- order的多种方式
- covering index
- index的平衡
简介
index形象的来说相当于字典前面用于查词的目录查找页,从程序的角度相当于一张映射表,能帮你快速定位自己要查的东西,但盲目的添加index会增加database的体积,根据自己查找的条件来添加index,index低层实现一般都用树来实现。
create index
- 使用explain可以查看select查询语句的依赖的各种条件
explain select customer_id from customers where state = 'CA'

- 在customers 中为state创建index
create index idx_state on customers (state);

可以观测两次依赖的不同
-
type : 从ALL变为ref,表示查询语句有参考的index,不再查找整张表
-
possible_keys:执行查询语句时可能使用的index
-
key:使用的ndex
-
row:查询的行数从10变为1,在大型数据中尤为明显的效率提升
-
创建一个index依赖于points
create index idx_points on customers (points);
viewing indexes
- 查找一张表中index
show indexes in customers

第一个是主键的index,自动创建的。collation表示排序方式。A表示ascend;B表示descending
prefix index
用查找项的前缀做为index查找的依据
- 对于last_name来说是string类型,所以查找的index也是string类型
//以last_name的前20个作为index的查找依据
create index idx_lastname on customers (last_name(20));
//通过下述方法选择合适的前缀大小,通过数值的变化大小来选择,选择数值变化趋于平缓的拐点
select count(distinct left(last_name 1)),count(distinct left(last_name 5)),count(distinct left(last_name 5)),
from customers;
Full-text indexes
对于full-text indexes来说,要查找的内容只存在于column中的一部分,举个例子,就是百度查找的时候,会返回你查找的关键字相关的部分,但这部分不一定在头部,所以不能使用prefix index。
- 查找一个blog数据,内容关于react 与 redux的东西
use sql_blog;
-- 以posts表的title与body列创建fulltext index 的idx_title_body
create fulltext index idx_title_body on posts(title,body);
select * from posts
-- 以idx_title_body 为依赖进行查找在title,body列中有关键词react或者redux的row。
where match(title,body) against ('react redux');

可以看到在第一行中只有redux关键字,第二行中只有react关键字
relevance score
对于查找到的众多项中,有一个关联值,表明与你查找所期望的相关联的程度,值的区间在0-1,0表示无关联,越趋近1表示越相关联
select * ,match(title,body) against ('react redux')
from posts
where match(title,body) against ('react redux');

boolean
关于Full-text indexes有两种模式,一种是上面那只natural language mode,另外一种是boolean mode,这种模式下可以添加或者去除关键词
- 去除关键词
select * ,match(title,body) against ('react redux')
from posts
-- 查找关键词react但不是redux
where match(title,body) against ('react -redux' in boolean mode );

- 必须包含关键词
-- 此时必须要有关键词from
where match(title,body) against ('react -redux +form' in boolean mode );

- 必须还有精准短语
where match(title,body) against ('"handling a form"' in boolean mode );
composite indexs
对于通常的查询条件来说,一般过滤条件不止1个。列如在sql_store中,要查询点数在1000以上且state在‘CA’的人
explain select customer_id from customers
where state = 'CA' and points > 1000;

可以看到无论有几个index,最后依托的就只有一个index,总共要查询112行。composite indexs所创建的indexs可以依赖于多列。
create index idx_state_points on customers (state,points);
此时在次执行上面的查询语句

可以看到查询的行数变少。
现实情况下composite indexs比signal indexs用的频繁,分开创建index所占用的资源也较大,所以一般都使用composite indexs,且使用其也能加快我们的存储
order of columns
如何对composite indexs所依赖的column进行排序
- put the most frequently used columns first
比如大部分的查询语句都用到了state,将其放在前面 - put the columns with a higher cardinality first

但这个规则不是绝对的,需要根据查询语句来看,查看如下查询语句
select customer_id from customers
where state = 'CA' AND last_name like 'A%';
先使用count来查看cardinality
select count(distinct state),count(distinct last_name),
from customers
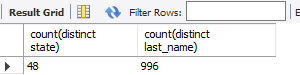
按照第二个规则应该将last_name置前,而事实上,包含A的名字有很多,可能有几百万个,对于state就只有几十个。分别以last_name在前与state 在前进行测试
create index idx_lastname_state on customers (last_name,state);
explain select customer_id
from customers
where state = 'CA' and last_name like 'A%';

一共查询40行,替换last_name与state位置
create index idx_state_lastname on customers (state,last_name);
explain select customer_id
from customers
where state = 'CA' and last_name like 'A%';

共查询7行
删除index
drop index idx_lastname_state on customers;
when indexes are ingored
在某种情况下index会被忽略导致起不到较好的作用,举两个例子。
- 使用or逻辑符
explain select customer_id from customers
where state = 'CA' or points > 1000;

结果为查找整张表,解决方法,使用union或者添加singal index
-- create index idx_points on customers(points)
explain select customer_id from customers
where state = 'CA'
union
select customer_id from customers
where points > 1000;

- 使用表达式
explain select customer_id from customers
where points + 10 > 2010;

解决方法,保持column单一
explain select customer_id from customers
where points > 2000;

create index idx_points on customers(points);
explain select customer_id from customers
where points > 2000;

using indexes for sorting
在排序的时候使用index会大大的减少开销,现存在的index;

explain select customer_id from customers
order by state;

尽管查询rows为全表1010,但是Extra为using index。
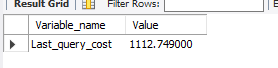
可以使用变量 last_query_cost来查询开销

- 不使用index进行排序
explain select customer_id from customers
order by first_name;

尽管同样查询是全表1010rows,Extra Using filesort。其实质是一个表达式
查看开销是使用index的10倍多。
order的多种方式
index (a,b)
a
b
a,b desc
a desc, b desc
各种方式所执行的效率不同,主要根据Extra中依据的类型来觉定执行效率
covering index
即select后查询的内容都在index内的话即为covering index,此时查询语句执行非常迅速且不需要接触表通过index就可以完成。
- 为covering index的实例
select customer_id ,from customers
order by state;
因此index的创建包考虑下面三点,来提高效率
- where中常涉及的部分
- order中涉及的部分
- select中涉及的部分
index的平衡
尽管index能提高执行的效率,但是太多的index会是一件坏事情
- 避免重复的index,(Mysql会报错)
(a,b,c)
(a,b,c)
- 避免redundant的index
(a,b)
(a) //这个是多余的
在创建新的index前查看现有的index