created on: 2020-01-20
@author: �������껪����
Feature Scaling
����Ŀ¼
- Feature Scaling
-
-
- WHY��
-
- ΪʲôҪ��һ��/������
- ��Ҫ��һ���Ļ���ѧϰ�㷨
- HOW��
-
- ��һ����normalization��
-
- ��һ����ĺô�
- ������standardization��
-
- �����ĺô�
- ���Ļ���Zero-centered �� Mean-subtraction��
- ��һ���ͱ����ıȽϣ�
- ѡ���������ŷ����ľ���
- ����������������������������Normalization
-
WHY��
��һ��/����ʵ����һ�����Ա任��������XXX���������ţ��ٽ���ƽ����������������������£�XmaxX_{max}Xmax?��XminX_{min}Xmin?����\mu������\sigma�� ���ɿ���������
���Ա任�кܶ����õ����ʣ������˶����ݸı����ɡ�ʧЧ����������������ݵı��֣���Щ�����ǹ�һ��/������ǰ�ᡣ������һ������Ҫ�����ʣ�
- ���Ա任����ı�ԭʼ���ݵ���ֵ�����ı�ԭʼ���ݵķֲ�״̬����
ΪʲôҪ��һ��/������
-
ijЩģ�������Ҫ
- ������뷶Χ��ͬ��ijЩ�㷨�������������������ع飬������
- �ݶ��½��������ٶȷdz�����������ȫ�������Чѵ���� ��һ��/��������Լӿ��ݶ��½�������ٶȣ�������ģ�͵������ٶȡ����ݶ��½���Logistic�ع顢֧����������������ȳ��õ��Ż��㷨����
- һЩ��������Ҫ��������֮��ľ��루��ŷ�Ͼ��룩������KNN�����һ������ֵ��Χ�dz�����ô����������Ҫȡ��������������Ӷ���ʵ�������㣣�������ʱʵ�������ֵ��ΧС����������Ҫ��
��?ע�⡿�����������㷨������Ψһ���������СӰ����㷨
-
Ϊ���������ٻ�
ʹ�ò�ͬ����֮����������пɱ��ԣ�
��Ŀ�꺯����Ӱ�����������ηֲ�(��ɢ���ʷֲ�)�ϣ���������ֵ�� -
������ֵ����
̫�������������ֵ���⡣
��Ҫ��һ���Ļ���ѧϰ�㷨
���ο���Դ��https://blog.csdn.net/pipisorry/article/details/52247379��
-
��Щģ���ڸ���ά�Ƚ��в��������������Ž���ԭ�����ȼۣ�����SVM������ֽ���Զ��Ҳ�����ˣ�֧��������ࣿ��������������ģ�ͣ����DZ�����ά���ݵķֲ���Χ�ͱȽϽӽ������������б���������ģ�Ͳ������ֲ���Χ�ϴ���С������dominate��
-
��Щģ���ڸ���ά�Ƚ��в��������������Ž���ԭ���ȼۣ�����logistic regression����Ϊ�ȵĴ�С��������ѧϰ����ͬ��feature����Ҫ�ɣ���������������ģ�ͣ��Ƿ���������ϲ���ı����Ž⡣���ǣ�����ʵ���������ʹ�õ����㷨�����Ŀ�꺯������״̫���⡱�������㷨���������ú���������������ģ�ͽ������ȷ�������Զ��ھ������������Ե�ģ�ͣ����Ҳ�������ݱ�����
-
��Щģ��/�Ż�������Ч����ǿ�ҵ������������Ƿ��һ������LogisticReg��SVM��NeuralNetwork��SGD�ȡ�
-
����Ҫ��һ����ģ�ͣ�
-
0/1ȡֵ������ͨ������Ҫ��һ������һ�����ƻ�����ϡ���ԡ�
-
��Щģ�����ܹ�һ��Ӱ�죬��DecisionTree��
-
HOW��
��һ����normalization��
-
������ӳ�䵽 [0,1]������ [-1, 1]��������
-
�������ٱ���ʽ��������ٵĴ��������ڲ�ͬ��λ��������ָ���ܹ����бȽϺͼ�Ȩ��
-
���Ž����������Сֵ�IJ���й�
-
����������ǹ�һ����һ��
-
Min-Max Normalization��Ҳ�����������������Χ [0, 1]
Xi?XminXmax?Xmin\frac{X_i - X_{min}}{X_{max} - X_{min}} Xmax??Xmin?Xi??Xmin??

from sklearn import preprocessing
norm_x = preprocessing.MinMaxScaler().fit_transform(x)
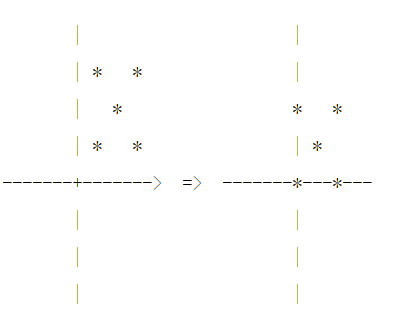
-
�����Թ�һ����
- �����������ݷֻ��Ƚϴ�ij�������Щ��ֵ�ܴ���Щ��С���÷�������log��ָ�������е�
- ��Ҫ�������ݷֲ�����������������Ժ���������
- ���� ��������ת����y=log?(X)y = \log(X)y=log(X)
��һ����ĺô�
- ����ģ�͵������ٶ�
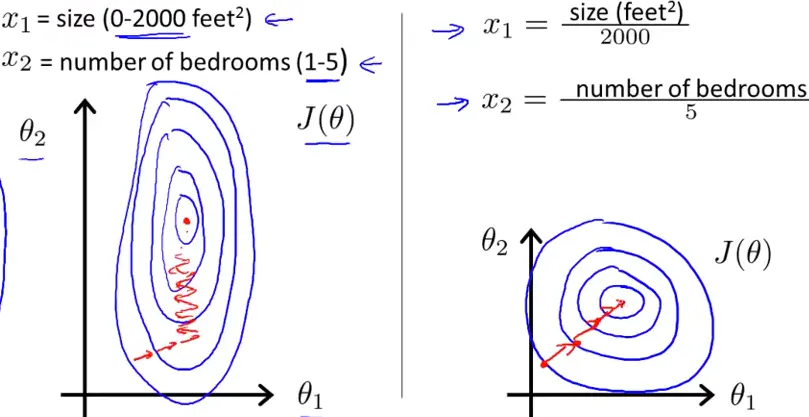
- ����ģ�͵ľ���
���漰��һЩ���������㷨ʱЧ�������������㷨Ҫ����ŷ�Ͼ��룬��һ�������ø��������Խ�������Ĺ�����ͬ��
����ָ����ˮƽ���ܴ�ʱ�����ֱ����ԭʼָ��ֵ���з������ͻ�ͻ����ֵ�ϸߵ�ָ�����ۺϷ����е����ã����������ֵˮƽ�ϵ�ָ������á�
������standardization��
-
Z-score�淶����������� / ���ֵ������
-
ͨ����z-score�ķ�����ת��Ϊ����̬�ֲ�����ֵΪ0������Ϊ1��
-
�����������ֲ���أ�ÿ�������㶼�ܶԱ�������Ӱ�죬ͨ����ֵ����\mu�����ͱ����\sigma�������ֳ�����
-
Ҳ��ȡ���������ٲ�ͬ�������ʹ��ͬ����֮����������пɱ���
-
�������[-��, +��]
Xi?�̦�\frac{X_i - \mu}{\sigma} ��Xi??��?

from sklearn import preprocessing
std_x = preprocessing.StandardScaler().fit_transform(x)
�����ĺô�
���ݱ���Ҳ����ͳ�����ݵ�ָ���������ݱ���������Ҫ��������ͬ���������������ٻ������������档����ͬ����������Ҫ�����ͬ�����������⣬�Բ�ͬ����ָ��ֱ�Ӽ��ܲ�����ȷ��ӳ��ͬ���������ۺϽ�������ȿ��Ǹı���ָ���������ʣ�ʹ����ָ��Բ���������������ͬ�������ټ��ܲ��ܵó���ȷ��������������ٻ�������Ҫ������ݵĿɱ��ԡ�������������������ԭʼ���ݾ�ת��Ϊ�����ٻ�ָ�����ֵ������ָ��ֵ������ͬһ�����������ϣ����Խ����ۺϲ�����������ԭ�����ӣ�https://blog.csdn.net/pipisorry/article/details/52247379��
���Ļ���Zero-centered �� Mean-subtraction��
- �����������ƶ�����0Ϊ���ĵ��λ��
- ƽ��ֵΪ0���Ա�����Ҫ��
- ��ȥƽ��������û�г��Ա���IJ�����ֻ��ƽ�ƣ�û�����ţ�
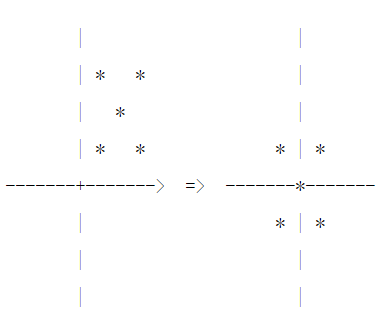
-
PCA��ʱ����Ҫ�����Ļ���centering�����ο���CSDN���ģ�
-
����������𣺣��ο���CSDN���ģ�
- �����ݽ������Ļ�Ԥ��������������Ŀ����Ҫ���ӻ���������������
- �����ݱ�����Ŀ������������֮��IJ����ԡ����ڶ�һ��һ��ѧϰȨ�ء�

��һ���ͱ����ıȽϣ�
- �������������Χ��Ҫ�����ù�һ��
- ������ݽ�Ϊ�ȶ��������ڼ��˵������Сֵ���ù�һ��
- ������������쳣ֵ�ͽ϶��������ñ��������Լ��ͨ�����Ļ������쳣ֵ�ͼ���ֵ��Ӱ��
- �ڷ��ࡢ�����㷨�У���Ҫʹ�þ��������������Ե�ʱ����ʹ��PCA�������н�ά��ʱ�������ָ��á�
���ο���Դ��֪���ش�
-
��һ���ͱ��������ǽ���ƽ��Ȼ�����̾��룬���������ı����ݷֲ������ξ��룩
- ƽ�ƶ��ڹ�һ����һ����СֵΪ���գ������Ծ�ֵΪ���ա�
- ���Ŷ��ڹ�һ��������ֵΪ���գ������Ա���Ϊ���ա�
- �������ı伸�ξ������乫ʽ�����ԭ��
- ��Ҫ����ʵ�ʵ����ݻ�������ʹ�ã������ʵ��䷴���磺��һ������Ȼƽ����Ȩ�أ���Ҳ��������ƻ����ݵĽṹ�� ��ԭ�����ӣ�

ѡ���������ŷ����ľ���
?���²ο���Դ��GitHub��Ŀ��feature-engineering-and-feature-selection
| Method | Definition | Pros | Cons |
|---|---|---|---|
| Normalization - Standardization (Z-score scaling) | removes the mean and scales the data to unit variance. z = (X - X.mean) / std |
feature is rescaled to have a standard normal distribution that centered around 0 with SD of 1 | compress the observations in the narrow range if the variable is skewed or has outliers, thus impair the predictive power. |
| Min-Max scaling | transforms features by scaling each feature to a given range. Default to [0,1]. X_scaled = (X - X.min / (X.max - X.min) |
/ | compress the observations in the narrow range if the variable is skewed or has outliers, thus impair the predictive power. |
| Robust scaling | removes the median and scales the data according to the quantile range (defaults to IQR) X_scaled = (X - X.median) / IQR |
better at preserving the spread of the variable after transformation for skewed variables | / |
from sklearn.preprocessing import RobustScaler
RobustScaler().fit_transform(X)
Z-score �� Min-max�������Ѵ�����ѹ����һ����խ�ķ�Χ��
�� robust scaler �ڱ���������������������ø��ã����������ܴӴ���������Ƴ��쳣ֵ��
���������ס�����/������Ⱥֵ�����������е���һ�����⣬Ӧ��������ɡ���
- ������Բ��Ǹ�˹�͵ģ����磬skewed distribution �����쳣ֵ��Normalization - Standardization ����һ���õ�ѡ����Ϊ�����Ѵ��������ѹ����һ����խ�ķ�Χ��
- ���ǣ�������ת���ɸ�˹�ͣ���ʹ��Normalization - Standardization��������3.4�� Feature Transformation�����ۡ���
- �ڼ�������Э�������ʱ(���ࡢPCA��LDA���㷨)����ò���Normalization - Standardization����Ϊ���������߶ȶԷ����Э�����Ӱ�졣�� Explanation here��
- Min-Max Scaling���ź� Normalization - Standardization һ����ȱ�㣬�����µ����ݿ��ܲ��ᱻ���Ƶ�[0, 1]����Ϊ���ǿ��ܳ�����ԭ���ķ�Χ��һЩ�㷨������ ����������ϲ��������0-1�����룬��������һ���ܺõ�ѡ��
?���Ӳο���Դ��
- A comparison of the three methods when facing skewed variables can be found here��6.3. Preprocessing data ���� sklearn�ٷ��ĵ�
����������������������������Normalization
���⣬��sklearn�ٷ��ĵ� �л��и�Normalization������������Ϊ��the process of scaling individual samples to have unit norm.
from sklearn import preprocessing
preprocessing.Normalizer(norm="l2").fit_transform(x)
# norm: The norm to use to normalize each non zero sample.
# ��l1��, ��l2��, or ��max��, optional (��l2�� by default)
- l1_norm �任��ÿ�������ĸ�ά�����ľ���ֵ��Ϊ������
- l2_norm �任��ÿ�������ĸ�ά������ƽ����Ϊ������
- max_norm �任��ÿ�������ĸ�ά�������Ը����������ֵ��
? �ر�ע������� Normalizer �Ƕ��У������������д�����������ǰ���ᵽ�Ķ��Ƕ��У������������д�����
from sklearn import preprocessing
X = [[ 1., -1., 2.],[ 2., 0., 0.],[ 0., 1., -1.],[ 0., 1., -1.]]
preprocessing.normalize(X, norm='l1', return_norm =True)
Out[1]:
(array([[ 0.25, -0.25, 0.5 ],[ 1. , 0. , 0. ],[ 0. , 0.5 , -0.5 ],[ 0. , 0.5 , -0.5 ]]), array([4., 2., 2., 2.]))
preprocessing.normalize(X, norm='l2', return_norm =True)
Out[2]:
(array([[ 0.40824829, -0.40824829, 0.81649658],[ 1. , 0. , 0. ],[ 0. , 0.70710678, -0.70710678],[ 0. , 0.70710678, -0.70710678]]),array([2.44948974, 2. , 1.41421356, 1.41421356]))
preprocessing.normalize(X, norm='max', return_norm =True)
Out[3]:
(array([[ 0.5, -0.5, 1. ],[ 1. , 0. , 0. ],[ 0. , 1. , -1. ],[ 0. , 1. , -1. ]]), array([2., 2., 1., 1.]))