Tree Indexes I
1 表索引
可以在数据库系统内部使用许多不同的数据结构,例如内部元数据、核心数据存储、临时数据结构或表索引。
对于表索引,可能涉及范围扫描的查询。
表索引是表列子集的副本,这些列被组织和/或排序以使用这些属性的子集进行高效访问。
因此,DBMS 无需执行顺序扫描,而是可以查找表索引的辅助数据结构,可以更快地查找元组。 DBMS 确保表和索引在逻辑上总是同步的。
每个数据库要创建的索引数量之间存在权衡。 尽管更多的索引可以更快地查找查询,但索引也使用存储并需要维护。 找出用于执行查询的最佳索引是 DBMS 的工作。
2 B+Tree
B树与B+树简明扼要的区别
(1) B+树改进了B树, 让内结点只作索引使用, 去掉了其中指向data record的指针, 使得每个结点中能够存放更多的key, 因此能有更大的出度. 这有什么用? 这样就意味着存放同样多的key, 树的层高能进一步被压缩, 使得检索的时间更短.
(2)当然了,由于底部的叶子结点是链表形式, 因此也可以实现更方便的顺序遍历, 但是这是比较次要的, 最主要的的还是第(1)点.
老师:(3)B tree 不会有重复的Key,B+树会有重复的Key,并且B+树删除Key节点是可能仍会保存Key到inner node(方便查找),
所有B tree的好处是更加经济,占用空间也少
B+Tree 是一种自平衡树数据结构,它保持数据排序并允许在 O(log(n)) 中进行搜索、顺序访问、插入和删除。 它针对读/写大数据块的面向磁盘的 DBMS 进行了优化。
几乎所有支持顺序保留索引的现代 DBMS 都使用 B+Tree。 有一种特定的数据结构称为 B 树,但人们也使用该术语来泛指一类数据结构。 原始 B-Tree 和 B+Tree 的主要区别在于 B-Trees 在所有节点中存储键和值,而 B+树仅在叶节点中存储值。 现代 B+Tree 实现结合了其他 B-Tree 变体的特性,例如 Blink-Tree 中使用的兄弟指针。
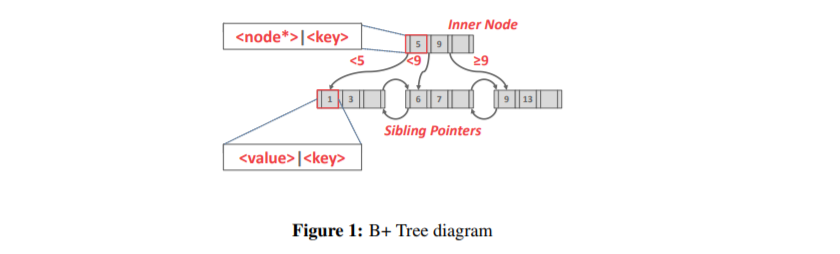
形式上,B+Tree 是具有以下属性的 M 路搜索树:
- 它是完美平衡的(即,每个叶节点都在相同的深度)。
- 除根节点之外的每个内部节点至少是半满的(M/2 ? 1 <= num of keys <= M ? 1)。
- 每个具有 k 个键的内部节点都有 k+1 个非空子节点。 —— 路径的数量始终是一个节点所能保存的key的数量加1
- 例如 Max.degree = 3, key最多有两个,并且最多只有3条向下的路
B+Tree 中的每个节点都包含一个键/值对数组。 这些对中的键源自索引所基于的属性。
这些值将根据节点是内部节点还是叶节点而有所不同。
对于内部节点,值数组将包含指向其他节点的指针。 叶节点值的两种方法是记录 ID 和元组数据。
记录 ID 指的是指向元组位置的指针。 具有元组数据的叶节点在每个节点中存储元组的实际内容。
每个节点上的数组(几乎)都按键排序。
Insertion
要将新条目插入 B+树,必须向下遍历树并使用内部节点找出将键插入到哪个叶节点。
- 找到正确的叶子 L。
- 按排序顺序在 L 中添加新条目:
? 如果L 有足够的空间,则操作完成。
? 否则将L 分成两个节点L 和L2。 均匀地重新分配条目并复制中间键。
将指向 L2 的索引项插入到 L 的父项中。 - 要分裂一个内部节点,重新平均分配条目,但向上推中间键。
Deletion
而在插入中,当树太满时,我们偶尔不得不分裂叶子,如果删除导致树
要小于半满,我们必须合并以重新平衡树。
- 找到正确的叶子 L。
- 删除条目:
? 如果L 至少是半满,则操作完成。
? 否则,您可以尝试重新分配,借用兄弟姐妹。
? 如果重新分配失败,合并L 和兄弟。 - 如果发生合并,则必须删除父项中指向 L 的条目
Others
Selection Conditions
因为 B+Tree 是按顺序排列的,所以查找具有快速遍历并且不需要整个键。 如果查询提供了搜索关键字的任何属性,则 DBMS 可以使用 B+Tree 索引。
这与哈希索引不同,哈希索引需要搜索关键字中的所有属性。
Non-Unique Indexes
与哈希表一样,B+Tree 可以通过复制键或存储值列表来处理非唯一索引。
在重复键方法中,使用相同的叶节点布局,但多次存储重复键。
在值列表方法中,每个键只存储一次并维护一个唯一值的链表。
Duplicate Keys(重复键)
在 B+Tree 中有两种允许重复键的方法
第一种方法是附加记录 ID 作为键的一部分。 由于每个元组的记录 ID 是唯一的,这将确保所有键都是可识别的。
第二种方法是允许叶节点溢出到包含重复键的溢出节点。
虽然没有存储冗余信息,但这种方法的维护和修改更加复杂。
Clustered Indexes 聚集索引
该表按主键指定的排序顺序存储,作为堆或索引组织的存储。
由于一些 DBMS 总是使用聚集索引,它们会自动制作一个隐藏的行 id 主键
如果一张表没有明确的表,但其他人根本无法使用它们。
Heap Clustering 堆聚类
元组使用集群索引指定的顺序在堆的页面中排序。 如果使用集群索引的属性来访问元组,DBMS 可以直接跳转到页面。
Index Scan Page Sorting
索引扫描页面排序
由于直接从非聚集索引中检索元组效率低下,DBMS 可以首先找出它需要的所有元组,然后根据它们的页面 id 对它们进行排序。