����Ŀ¼
- Lec14 File systems
- Lec15 Crash recovery
Lec14 File systems
-
�ļ�ϵͳ����Ļ����йص�����
- ����Ӳ���ij��������ʵ�ֵ�
- ʵ��crash safety
- ����ڴ������Ų��ļ�ϵͳ
- ����
-
�ļ�ϵͳ���е����ƵĽṹ�����շֲ�ķ�ʽ�������⣺
- ����ײ��Ǵ��̣�Ҳ����һЩʵ�ʱ������ݵĴ洢�豸��������Щ�豸�ṩ�˳־û��洢��
- ����֮����buffer cache����˵block cache����Щcache���Ա���Ƶ���Ķ�д���̡��������ǽ������е����ݱ��������ڴ��С�
- Ϊ�˱�֤�־��ԣ�������ͨ������һ��logging�㡣�����ļ�ϵͳ����ij����ʽ��logging�������½ڿλ������ⲿ�����ݣ����Խ����Ҿ��������Ľ��ܡ�
- ��logging��֮�ϣ�XV6��inode cache������Ҫ��Ϊ��ͬ����synchronization���������Ժ����ܡ�inodeͨ��С��һ��disk block�����Զ��inodeͨ�������洢��һ��disk block�С�Ϊ����inode�ṩͬ��������XV6ά����inode cache��
- �����Ͼ���inode�����ˡ���ʵ����read/write��
- �����ϣ������ļ��������ļ�������������
-
How file system uses disk
- SSD/HDD�洢�豸���ӵ��˵�������֮�ϣ�����Ҳ������CPU���ڴ档һ���ļ�ϵͳ������CPU�ϣ����ڲ������ݴ洢���ڴ棬ͬʱҲ���Զ�дblock����ʽ�洢��SSD����HDD������Ľӿڻ���ͦ�ģ�������read/write��Ȼ����block�����Ϊ��������Ȼ�������������Ĺ��ڼ��ˣ�����ʵ�ʵĽӿڴ�ž���������
- **��������ͨ����ʹ��һЩ����Э�飬����PCIE������̽������������¿����������Ľӿڣ��ֵĴ��̿�������һ����������ṩblock��ţ���������ͨ��д�豸�Ŀ��ƼĴ�����Ȼ���豸�ͻ������Ӧ�Ĺ��������Ǵ�һ���ļ�ϵͳ�ĽǶȵ�������**���ܲ�ͬ�Ĵ洢�豸���ŷdz���һ�������ԣ��������ĽǶ�������������Դ�����ͬ�ķ�ʽ�����ǽ��б�̡�
- ���ļ�ϵͳ�Ĺ������ǽ����е����ݽṹ��һ���ܹ�������֮�����¹����ļ�ϵͳ�ķ�ʽ������ڴ����ϡ���Ȼ�в�ͬ�ķ�ʽ������XV6ʹ����һ�ַdz������ǻ�ͦ�����IJ��ֽṹ��
- block0Ҫôû���ã�Ҫô������boot sector����������ϵͳ��
- block1ͨ������Ϊsuper block�����������ļ�ϵͳ�������ܰ����������ж��ٸ�block��ͬ�������ļ�ϵͳ��������Ϣ������֮��ῴ��XV6��������������Ϣ�������ͨ��block1������ֵ��ļ�ϵͳ��Ϣ��
- ��XV6�У�log��block2��ʼ����block32������ʵ����log�Ĵ�С���ܲ�ͬ��������super block�лᶨ��log����30��block��
- **��������block32��block45֮�䣬XV6�洢��inode��**��֮ǰ˵�����inode��������һ��block�У�һ��inode��64�ֽڡ�
- ֮����bitmap block���������ǹ����ļ�ϵͳ��Ĭ�Ϸ�������ֻռ��һ��block������¼������block�Ƿ���С�
- ֮���ȫ������block�ˣ�����block�洢���ļ������ݺ�Ŀ¼�����ݡ�
-
�����ϴ洢��inode
-
һ��64�ֽڵ����ݽṹ��
-
ͨ����˵����һ��type�ֶΣ�����inode���ļ�����Ŀ¼��
-
nlink�ֶΣ�Ҳ����link���������������پ����ж����ļ���ָ���˵�ǰ��inode��
-
size�ֶΣ��������ļ������ж��ٸ��ֽڡ�
-
��ͬ�ļ�ϵͳ�еı��﷽ʽ���ܲ�һ����������XV6�н�������һЩblock�ı�ţ�������0�����1���ȵȡ�XV6��inode���ܹ���12��block��š���Щ����Ϊdirect block number����12��block���ָ���˹����ļ���ǰ12��block���ٸ����ӣ�����ļ�ֻ��2���ֽڣ���ôֻ����һ��block���0���������������Ǵ������ļ�ǰ2���ֽڵ�block��λ�á�
-
**֮����һ��indirect block number������Ӧ�˴�����һ��block�����block������256��block number����256��block number�������ļ������ݡ�**����inode��block number 0��block number 11����direct block number����block number 12�����indirect block numberָ������һ��block��
-
������������ݣ�XV6���ļ����ij����Ƕ����أ�
(256 + 12) *1024�ֽ�
-
-
Ŀ¼��directory��
-
�ļ�ϵͳ�Ŀ������Ծ��Dz�λ��������ռ䣨hierarchical namespace������������ļ�ϵͳ�б�����û��Ѻõ��ļ�������Unix�ļ�ϵͳ��Ȥ�ĵ����ڣ�һ��Ŀ¼��������һ���ļ�����һЩ�ļ�ϵͳ�ܹ�����Ľṹ����XV6�У�����Ľṹ�����ÿһ��Ŀ¼������directory entries��ÿһ��entry���й̶��ĸ�ʽ��
- ǰ2���ֽڰ�����Ŀ¼���ļ�������Ŀ¼��inode��ţ�
- ��������14���ֽڰ������ļ�������Ŀ¼����
-
����ʵ��·�������ң��������Ϣ���㹻�ˡ���������Ҫ����·������/y/x�������Ǹ���ô���أ�
-
��·��������֪����Ӧ�ô�root inode��ʼ���ҡ�ͨ��root inode���й̶���inode��ţ���XV6�У���������1�����Ǹ���θ��ݱ���ҵ�root inode�أ���ǰһ�����ǿ���֪����inode��block 32��ʼ�������inode1����ô��Ȼ��block 32�е�64��128�ֽڵ�λ�� (ƫ�� 1 * 64 )�������ļ�ϵͳ����ֱ�Ӷ���root inode�����ݡ�
-
����·�������ҳ�����������ɨ��root inode����������block�����ҵ���y��������ô�ҵ�root inode���ж�Ӧ��block�أ�����ǰһ�ڵ����ݾ��Ƕ�ȡ���е�direct block number��indirect block number��
-
����������ҵ��ˣ�Ҳ������û���ҵ�������ҵ��ˣ���ôĿ¼yҲ����һ��inode��ţ�������251��
���ǿ��Լ�����inode 251���ң��ȶ�ȡinode 251�����ݣ�֮����ɨ��inode���ж�Ӧ��block���ҵ���x�����õ��ļ�x��Ӧ��inode��ţ��������Ϊ·�������ҵĽ�����ء�
-
-
-
-
sleep lock
-
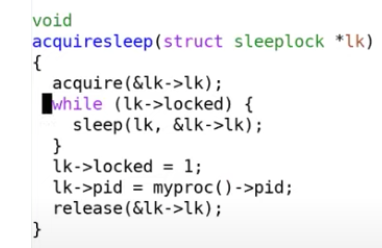
-
��Ȼsleep lock�ǻ���spinlockʵ�ֵģ�Ϊʲô����block cache������ʹ�õ���sleep lock������spinlock��
����spinlock�кܶ����ƣ�����֮һ�Ǽ���ʱ�жϱ���Ҫ�رա��������ʹ��spinlock�Ļ��������Ƕ�block cache��������ʱ����Ҫ����������ô���Ǿ���ԶҲ���ܴӴ����յ����ݡ�������һ��CPU�˿����յ��жϲ������������ݣ���**���������ֻ��һ��CPU�˵Ļ������Ǿ���ԶҲ�����������ˡ�**����ͬ����ԭ��Ҳ�����ڳ���spinlock��ʱ�����sleep״̬��ע�����13.1����������������ʹ��sleep lock��sleep lock�����ƾ��ǣ����ǿ����ڳ�������ʱ�����ر��ж������ǿ����ڴ��̲����Ĺ����г�����������Ҳ���Գ�ʱ����������������ڵȴ�sleep lock��ʱ�����Dz�û����CPUһֱ��ת������ͨ��sleep��CPU���ó�ȥ�ˡ�
-
Lec15 Crash recovery
-
�������ǹ��ĵ�crash���߹��ϰ����ˣ����ļ�ϵͳ���������еĵ������ϣ����ļ�ϵͳ���������е��ں�panic��panic���������ں�bug��������ͻȻ�������ϵͳ���ϣ�������϶������ܹ�������֮����ʹ���ļ�ϵͳ��
���ܶ��ļ�ϵͳ�IJ����������˶�����裬��������ڶ������Ĵ���λ��crash���ߵ��������ˣ��洢�ڴ����ϵ��ļ�ϵͳ���ܻ���һ�ֲ�һ�µ�״̬��֮����ܻᷢ��һЩ�������顣��Ҫ��ע������**��ν����Щ��һ�µ�״̬**�� -
����
-
����һ���ļ��������������˳���ǣ�ע��ʵ�ʲ������ࣩ��
- ����inode�������ڴ����Ͻ�inode���Ϊ�ѷ���
- ֮����°��������ļ���Ŀ¼��data block
���������������֮�䣬����ϵͳcrash�ˡ���ʱ���ܻ�ʹ���ļ�ϵͳ�����Ա��ƻ��������������ָ��ÿһ������blockҪô�ǿ��еģ�Ҫô��ֻ�������һ���ļ�����ʹ���ϳ����ڴ��̲����Ĺ����У������������������Ȼ�ܹ����֡����������Ա��ƻ��ˣ���ô����ϵͳ֮�������ܻ����г��������磺
- ����ϵͳ����������crash�ˣ���Ϊ�ļ�ϵͳ�е�һЩ���ݽṹ���ڿ��ܴ���һ���ļ�ϵͳ��������״̬��
- ���ߣ������ܵ��Dz���ϵͳû��crash���������ݶ�ʧ�˻��߶�д�˴�������ݡ�
��������Ⲣ�����ڲ�����˳���������������ж��д���̵IJ�������Щ����������Ϊһ��ԭ�Ӳ��������ڴ����ϡ�
-
logging
-
�ܺõ�����
- ȷ���ļ�ϵͳ��ϵͳ������ԭ���Ե�
- ֧�ֿ��ٻָ���Fast Recovery��
- ���Էdz��ĸ�Ч
-
logging�Ļ���˼�뻹�Ǻ�ֱ�۵ġ����ȣ��㽫���̷ָ���������֣�����һ��������log����һ���������ļ�ϵͳ���ļ�ϵͳ���ܻ��log��öࡣ
-
����
- ��log write������Ҫ�����ļ�ϵͳʱ�����Dz����Ǹ����ļ�ϵͳ�����������������ڴ��л�����bitmap block��Ҳ����block 45������Ҫ����bitmapʱ�����Dz�����ֱ��дblock 45�����ǽ�����д�뵽log�У�����¼�������Ӧ��д�뵽block 45���������е�д block��������ͬ�IJ������������inode��Ҳ���¼һ��дblock 33��log��
- ��commit op��֮����ij��ʱ�䣬���ļ�ϵͳ�IJ��������ˣ�����˵����ǰһ�ڿ�����4-5��дblock���������������Ҷ�������log�У����ǻ�commit�ļ�ϵͳ�IJ���������ζ��������Ҫ��log��ij��λ�ü�¼����ͬһ���ļ�ϵͳ�IJ����ĸ���������5��
- ��install log����������log�д洢������дblock������ʱ���������Ҫ����ִ����Щ������ֻ��Ҫ��block��log�����Ƶ��ļ�ϵͳ����������֪����һ��������д�뵽block 45�����ǻ�ֱ�ӽ����ݴ�logд��block45���ڶ���������д�뵽block 33�����ǻὫ��д�뵽block 33���������ơ�
- ��clean log��һ������ˣ��Ϳ������log�����logʵ���Ͼ��ǽ�����ͬһ���ļ�ϵͳ�IJ����ĸ�������Ϊ0��
-
ԭ���Ե�ԭ�� ���� log��head�IJ���commitֵҪô�Ƿ�0��ҪôΪ0
- write ahead ruleЭ�飬Ҳ����˵��д��commit��¼֮ǰ������Ҫȷ�����е�д��������log�С�
- ��������ʱ���ļ�ϵͳ��鿴log��commit��¼ֵ�������0�Ļ�����ôʲôҲ�������������0�Ļ������Ǿ�֪��log�д洢��block��Ҫ��д�뵽�ļ�ϵͳ�У�������������crash��ʱ��һ�������install log�����ǿ�������commit֮��clean log֮ǰcrash�ġ��������ʱ��������Ҫ���ľ���reinstall��ע��Ҳ���ǽ�log�е�block�ٴ�д�뵽�ļ�ϵͳ������clean log��
-
XV6��log�ṹ������һ��Ҳ�Ǽ���ļ��������ʼ��һ��header block��Ҳ�������ǵ�commit record����������ˣ�
- ����n��������log block������
- ÿ��log block��ʵ�ʶ�Ӧ��block���
File system challenges
-
��һ����cache eviction���������𣩡�����transaction���ڽ����У����Ǹոո�����block 45����Ҫ������һ��block��������buffer cache�����˲��Ҿ�������block 45����buffer cache�г���block 45��ζ��������Ҫ����д�뵽���̵�block 45λ�ã������������⣿���������ô���˵Ļ������ƻ�ʲô�������ǵģ������block 45д�뵽����֮������crash���ͻ��ƻ�transaction��ԭ���ԡ�
���Զ��ڻ�δд��log�Ļ��棬��Ҫ��pin���ύcommit�����unpin -
�ڶ�����ս�ǣ��ļ�ϵͳ������������log�Ĵ�С�� ִ��һ���ļ�ϵͳ������log������
��XV6�У��ܹ���30��log block��ע�����14.3������Ȼ���ǿ�������log�ijߴ磬����ʵ���ļ�ϵͳ�л��д�ö��log�ռ䡣��������ν��������log����ļ�ϵͳ���������ܷ���log�ռ��С����һ���ļ�ϵͳ��������д�볬��30��block����ô��ζ�Ų���������Ҫֱ��д���ļ�ϵͳ�������Dz��������ģ���Ϊ��Υ����write ahead rule���������е��ļ�ϵͳ��������������log�Ĵ�С��
���д���block��������30����ôһ��д�����ᱻ�ָ�ɶ��СһЩ��д����
ΪʲôXV6��log��С��30����Ϊ��xv6��30���κ�һ���ļ�ϵͳ�����漰��д���������� -
���һ��Ҫ���۵���ս�Dz����ļ�ϵͳ���� ��ֹһ���������ύ��ִ�ж���ļ�ϵͳ������
����������һ��log��������������ִ�е�transaction������transaction t0��log��ǰ��μ�¼��transaction t1��log�ĺ��μ�¼����������������log�ռ䣬�����κ�һ��transaction����û��ɡ���t0��t1��ʾ ��ͬ���ļ�ϵͳ������������������ţ�xv6û��������ţ������������ύ�κ�һ��transaction�����Dz��ܣ���Ϊ�����Ļ����Ǿ��ύ��һ��������ɵ�transaction����Υ����write ahead rule��log����Ҳû����Ӧ�õ����á�**���Ա���Ҫ��֤�������transaction����һ��Ҳ����log�Ĵ�С��**���Ե����ǻ�û�����һ���ļ�ϵͳ����ʱ�����DZ�����ȷ������д����ܵ�log��С��log����Ĵ�С��ǰ���£���������һ���ļ�ϵͳ������ʼ��
**XV6ͨ�����Ʋ����ļ�ϵͳ�����ĸ�����ʵ����һ�㡣**��begin_op�У����ǻ��鵱ǰ�ж��ٸ��ļ�ϵͳ�������ڽ��С������̫�����ڽ��е��ļ�ϵͳ���������ǻ�ͨ��sleepֹͣ��ǰ�ļ�ϵͳ���������У����ȴ������������е��ļ�ϵͳ������ִ���겢commit֮���ٻ��ѡ���������������ļ�ϵͳ��������һ��commit���е�ʱ���ⱻ��Ϊgroup commit����Ϊ���ォ���������һ�����transactionһ���ύ�ˣ�����Ķ������Ҫôȫ�������ˣ�Ҫôȫ��û�з�����