Ŀ¼
����WAF�����
��˼ά�����ƹ�
�������������һ��Ҫ�������ù��ߵ�֤��
����һ����·�ƹ�
�������������waf����
��������������
��IP ������
�ھ�̬��Դ
��3������С�Թ����ƹ�������ʼ����
��Ŀ¼αװ�ƹ���url ��������
�������������������Ϊ�ô���Ƚϴ�
�����ƹ�
�Զ�����WAF��ʵ�������ߡ���WAFNinja
burpsuite
sqlmap
ʹ��sqlmap�Դ��Ľű������ƹ�
����Ƿ���waf
����waf���أ���ȫ��Ϊ����
ʹ���Դ��ƹ��ű������ƹ����ԣ���ʵ��һ��ûʲô�ã�
����ʹ�ñ�д��tamper�ű�����ʵ��һ����Ҫ�Լ���д��
Fuzz/����
fuzz�ֵ�
Fuzz-DB/Attack
Other Payloads С��ʹ��

��û�в����ǽ���취�ܱ����Ѷࣩ
ֻҪ�ǻ��ڹ�����ƹ����ڹ�����ʱ���������Ȼ��ȱ���ͣ�������WAF������ǽ�Ȼ�������ģʽ�ķ������õķ��ӣ�ֻҪ������������һ�㣬�����Լ����Զ��������ҵ����ָ������ƹ����ơ�
���簲ȫ��WAF�ƹ�����������ԭ����ע���ƹ�WAF��������

����WAF�����
����ģ�
��ɨ��/���ʵ��ٶ�̫���ˣ�����Ľ���ɨ�裬������õ���Ϣ�Ǽٵģ����ᱻwaf���ء�
��waf����ָ�Ƽ�¼ʶ�𣬣��ر���awvs��һЩ���Ź��ߵĹ���ָ�ơ�
��©��payload�Ĺؼ���Ҳ��waf�������ֵ��
������һ��ħ��һ�ɣ�������ȥ��ԽѧԽ�ࣩ

��˼ά�����ƹ�
�������������һ��Ҫ�������ù��ߵ�֤��
burpsuite�������ְ�ȫ���棺��������������ֹ Firefox ��ȫ������������վ�� �����PortSwigger CA����_��ɫ�ش�(����)�IJ���-CSDN����
����һ����·�ƹ�
WAF���õ�ʱ��������©�����http��80�˿ڣ���httpsЭ�飨443�˿ڣ�û��ȫ�����з�������ˣ���URL�а�http��Ϊhttps�������
�������������waf����
���ҵ���ʵip���ƹ�CDN����������������
Get Site Ip
IP/IPv6��ѯ����������ַ��ѯ - վ������
ip��ַ��ѯ ip��ѯ ��ip ����ip��ַ�����ز�ѯ ��վip��ѯ ͬip��վ��ѯ iP�������� iP������ ͬip����
��վ���ٹ���_����ping _��ص�ping��� - ��վ��
С���ҷ�����������վ
��Ϲ�˾ע��ؽ����ֹ��ж�

(�е�ʱ��Ҳ��һ���ɿ���Ҫ���Լ�����Ȼ���Լ��ж�һ��)
��������������
��WAF�������л�ѡ�����Ρ��������ݰ����ⲿ�����ݰ��������ƥ����飬��WAF����һ���������б������ϰ�����Ҫ��ģ�WAF�Ͳ�����м�⡣��������Ƿ��ʵ����ݰ�αװ�ɰ������ϵ����ݰ����Ϳ����ƹ�WAF�ļ��顣
��IP ������
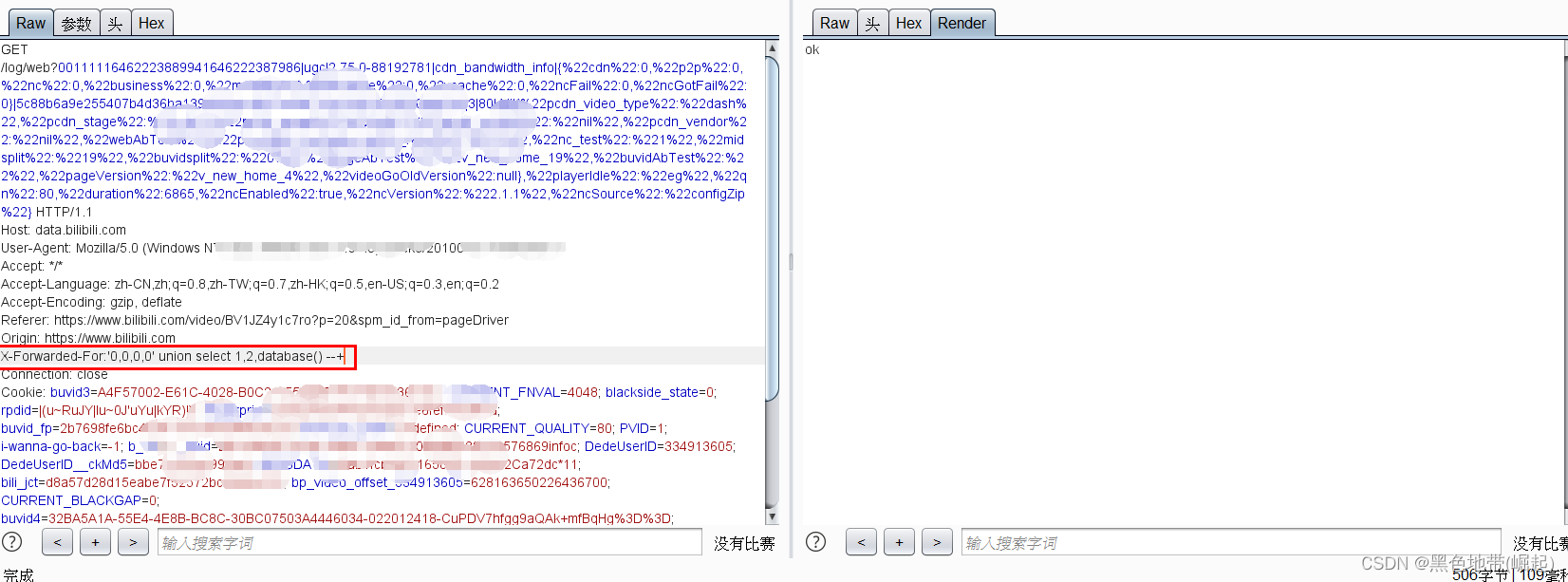
��Щ��վ������Լ������������ϵIJ��������м��飬��ˣ����������ݰ�������X-FARWARDED-FORͷ��������X-Originating-IP������Ϊ127.0.0.1�������ƹ�WAF��
��������ȡ�� ip�����ֺ���α�죬��Ҫ����������Ƚ϶࣬����ʵ�֣���ʹ�����ݰ��������ģ�Ҳ�Dz�����ܵĵ�������ǻ�ȡ�ͻ��˵� IP���ʹ���α�� IP �ƹ��������
�� http �� header
X-Forwarded-For
X-remote-IP
X-originating-IP
x-remote-addr
X-Real-ip
��֮�¼�����ʾһ��ok
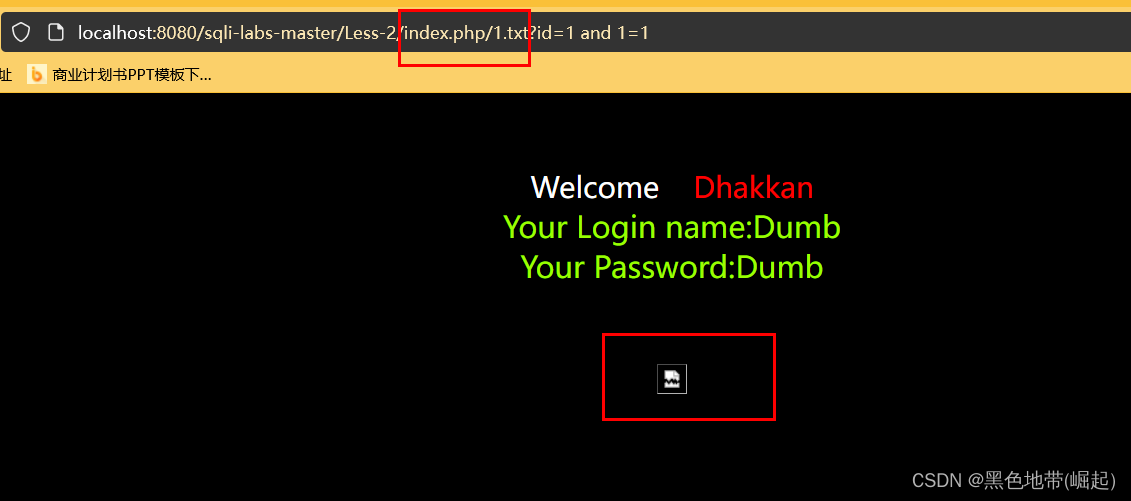
�ھ�̬��Դ
�ض��ľ�̬��Դ���������ľ�̬�ļ�(.js .jpg .swf .css .txt�ȵ�)�����ư��������ƣ�waf Ϊ�˼��Ч�ʣ���ȥ�������һЩ��̬�ļ�����������
URL/sql.php/1.js?id=1 and 1=1
URL/index.php/1.txt?id=1 and 1=1
��Aspx/php ֻʶ��ǰ��� .aspx/.php ���治ʶ��
(������Ϊ�빤�߱���ʽ������ȣ��ֹ�����������˼ά�ز����٣��ٽ�Ϲ���������)
Ҫʵ�ֵ�Ԥ�ڵĽ����Ҫ�и�����-------->��Ԥ�ڽ����Ӱ���waf��ȫ��������֪��֪�ˣ��������з�����-------->����С�Թ����ƹ�������ʼ����
��1��Ҫʵ�ֵ�Ԥ�ڵĽ����
ͨ�����ʾ�̬��Դ�ƹ�waf������ִ��������ݿ����
��2���˽����waf��ȫ��������
��ѯ��ȫ���������ݿ������ؼ�����
���ľ��Ǽ��URL��cookie��post������
����Ȼ���ע������������ƥ�䣬���ƥ�䵽���������------>��Ϲ����ܳ�ʶ���������

������Ĭ�ϵļ��HTTPͷ��û����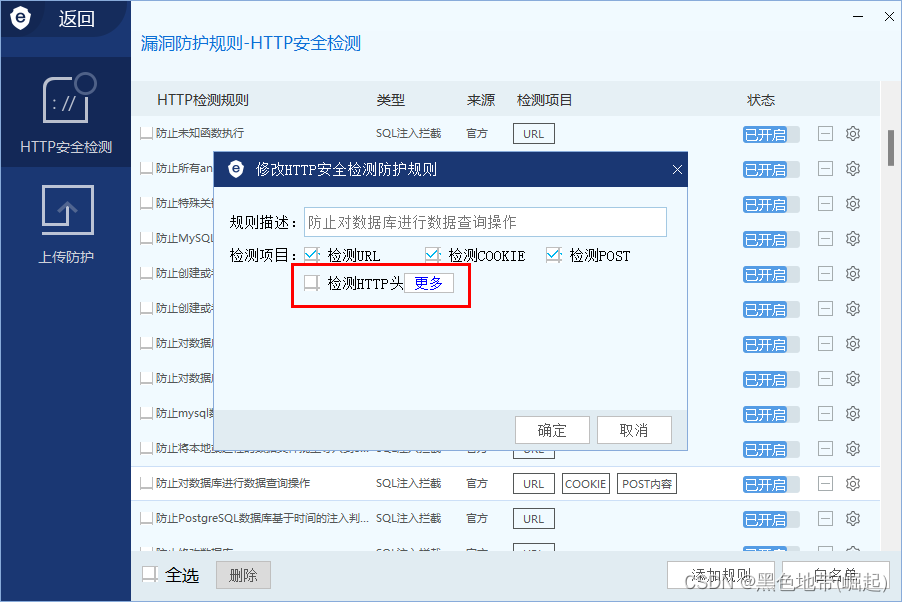
���ƹ�����Ľ��------>������

��3������С�Թ����ƹ�������ʼ����
�ٶ�post���ݽ��м�⣬˵�����Գ��Խ���post���ݽ����ύ
��Ȼû�б����أ�������վ�����յ�post�ύ
GET��POST������ץ��GET��POST��http����ͷ������״̬��_��ɫ�ش�(����)�IJ���-CSDN����
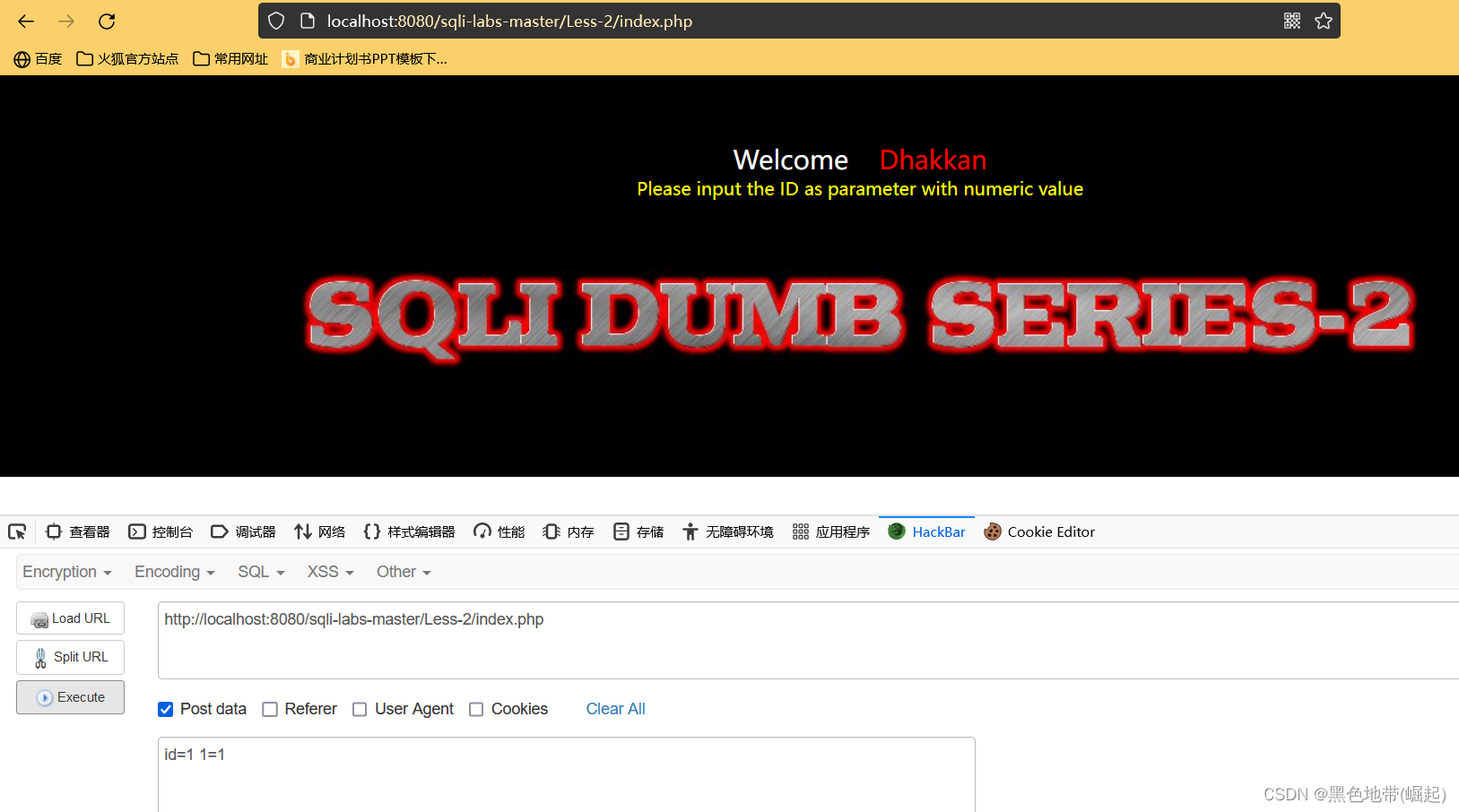
POST�����գ���ôֻ�ܿ��ǻص�GET�����߸�Դ��Ϊrequest
(���ﲻ���ڱ����ύɶ�ģ����п��ܾͲ�����POST�ύ)
���˼���ʵ��״���ٳ���
�ص�GET����ô��Ҫ����ʹ�ø���ע�ͷ����滻�ȵȷ����ƹ������ھͿ����ù��ߴ����ֹ��ˣ�
�������ⷽ�滹�ǽ������ߺͽű�����ɣ�
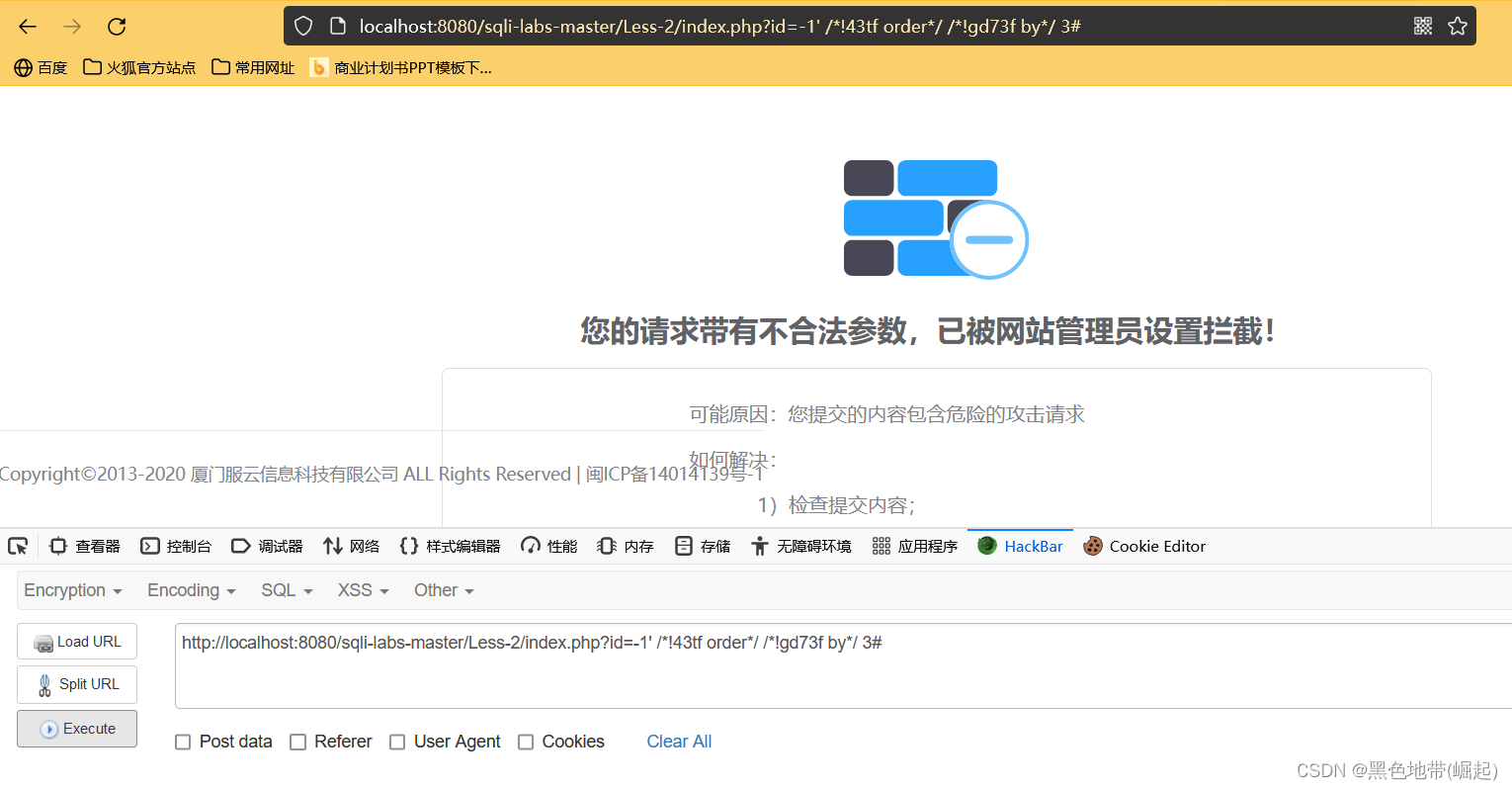
��Ŀ¼αװ�ƹ���url ��������
����ض�Ŀ¼���õİ������б����� admin/manager/system �ȹ�����̨
������ݰ����Ƿ���ָ���Ĺؼ��ַ����ж������Թ��캬����Щָ��Ŀ¼�ַ������Ե����ݰ���
ֻҪurl�д��ڰ��������ַ���������Ϊ�����������м�⡣
������ url �������ƣ�
URL/index.php/admin?id=1
��Ż��û���أ�
URL/index.php?a=/manage/&b=../etc/passwd
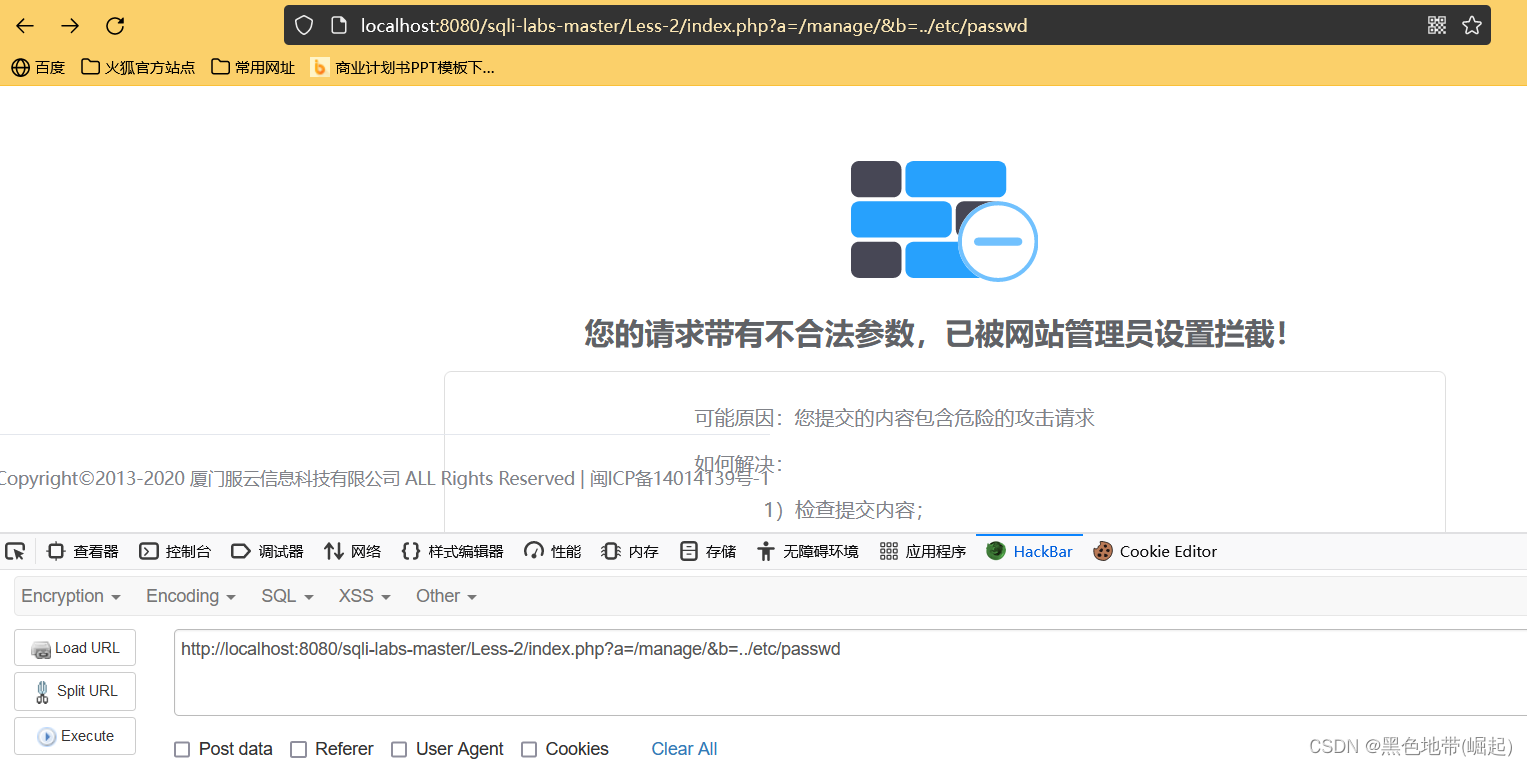
(���ﲻ���ڱ����ύɶ�ģ����п��ܾͲ�����POST�ύ)
URL/../../manage/../sql.asp?id=2
��������ܾ�Ҫ�Ȱ��ļ�Ŀ¼��ͼ��������
�������������������Ϊ�ô���Ƚϴ�
վ��Ϊ�������SEO�ϵ������������öԴ���������������治�����飨�ٶȣ��ȸ�ɶ�ģ�
Ҳ����˵����������ݰ���user-agent�ֶ����滻������������Ϣ���Ϳ����ƹ�WAF�ļ���
����waf���ṩ����������Ĺ��ܣ�ʶ������ļ���һ�������֣�
����UserAgent�����Ժ�������ƭ�����ǿ���αװ�����波������
ͨ����Ϊ�ж�
User Agent Switch��Firefox���������
���������������������������б���������ȥ�����ǵ�user-agent�ֶ�
������һ��baidu��
PC�˵��ǣ�
Mozilla/5.0 (compatible; Baiduspider/2.0;+http://www.baidu.com/search/spider.html��
UA�˵��ǣ�
Mozilla/5.0 (Linux;u;Android 4.2.2;zh-cn;) AppleWebKit/534.46 (KHTML,likeGecko) Version/5.1 Mobile Safari/10600.6.3 (compatible; Baiduspider/2.0;+http://www.baidu.com/search/spider.html)
��Ʒ���� ��Ӧuser-agent
��ҳ���� Baiduspider
�������� Baiduspider
ͼƬ���� Baiduspider-image
��Ƶ���� Baiduspider-video
�������� Baiduspider-news
�ٶ��Ѳ� Baiduspider-favo
�ٶ�����Baiduspider-cpro
����֩��Baiduspider-sfkr
�����ٶȰٿƣ�
��д�ű��ƹ�
����ʹ��pycharm����python�ļ�
python���нű��ļ���3�ַ���_��ɫ�ش�(����)�IJ���-CSDN����
pycharm��No module named ��requests��������������������Ľ�����
import json
import requestsurl='http://localhost:8080/sqli-labs-master/Less-2/'head={'User-Agent':'Mozilla/5.0 (compatible; Baiduspider/2.0;+http://www.baidu.com/search/spider.html��'}for data in open('xxx.txt'):data=data.replace('\n','')urls=url+datacode=requests.get(urls).status_codeprint(urls+'|'+str(code))
�����ƹ�
�Զ�����WAF��ʵ�������ߡ���WAFNinja
�����ィ��������ֵ�����̫�࣬�ͻ����߰ɣ�������·ͨ���������ֹ��ֵ�˵�������ã�
���ص�ַ��
WoLpH/python-progressbar: Progressbar 2 - A progress bar for Python 2 and Python 3 - "pip install progressbar2" (github.com)
�����ȸ���Ұ�����Ŀӱ�һ�£��ҳɹ�����һ��ʱ���������пӣ�
�����ϵİ�װ�̳�һ���ͼ��д�������飬�����Ҹ������������������⣩
��һ���ӣ�����WAFNinja��û���ȥ������

�ڶ����ӣ�sudo pip install processbar

�µ���1.0.7�汾��
�������ӣ��ж���汾python
�ļ�ɶ������python2.7.8���棬������ص�ģ��ֱ�ӵ�python3.9������

���ĸ��ӣ�ImportError��No module named xxxx
����û��xxx��װ����һ��Ҫ��������İ汾��װ��
��Ҫ��3����װ������ͷ��ɾɾ���£�����±���
������ӣ�����python3�����в��У��������˴�ӡ
����Ȼѧ��python��������������滹��Ҫ�ú�ѧѧ����ã�ǰ·������

burpsuite
burpsuite�Դ���ע�빦��

sqlmap
ʹ��sqlmap�Դ��Ľű������ƹ�
ֱ��ʹ��kali Linux����ϵͳ��sqlmap����ʹ������
���ű�λ���ڣ�/usr/share/sqlmap/tamper/��
���õ���kali���Դ���sqlmap

����Ƿ���waf
���C-identify-waf ���WAF���°��sqlmap���棬�Ѿ���ʱ�ˣ�����ʹ���ˣ�
sqlmap -u "URL" --batch
--batch(����Ĭ�����ü��)

is protected by some kinds of WAF/IPS
(�ܵ�ij��WAF/IPS����)
����waf���أ���ȫ��Ϊ����
���ע�빤�߶�����Ϊ���ض����Ҹ���HTTPͷ����������

ʹ���Դ��ƹ��ű������ƹ����ԣ���ʵ��һ��ûʲô�ã�
--random-agent ʹ������HTTPͷ�����ƹ�
--porxy=http//127.0.0.1:8080(������burpsuite�Ƚ��д���)
sqlmap -u "URL" --tamper=ģ��
����ָ�����ģ�飩

all tested parameters do not appear to be injectable.
�����в��ԵIJ��������ǿ�ע��ġ���
����ʹ�ñ�д��tamper�ű�����ʵ��һ����Ҫ�Լ���д��
����Ҫһ���̻�����
��ִ�еĹ����п��ܻ�����������
���Կ��������ӳ١����ô����ء�αװ����ȷ�ʽ
Fuzz/����
�ܶ�߶��DZ�д��python�ű����е��ֹ�����Ҫ���в���
??????python���нű��ļ���3�ַ���
Ҳ��ʹ��pycharm����python�ű��ļ�
pycharm��No module named ��requests��������������������Ľ�����
fuzz�ֵ�
Seclists/Fuzzing
https://github.com/danielmiessler/SecLists/tree/master/Fuzzing
Fuzz-DB/Attack
https://github.com/fuzzdb-project/fuzzdb/tree/master/attack
Other Payloads С��ʹ��
https://github.com/foospidy/payloads
