BatchNormЕФЛљБОЫМЯыЃКШУУПИівўВуНкЕуЕФМЄЛюЪфШыЗжВМЙЬЖЈЯТРДЃЌетбљОЭБмУтСЫЁАInternal Covariate ShiftЁБЮЪЬтСЫЁЃ
BNЕФЛљБОЫМЯыЦфЪЕЯрЕБжБЙлЃКвђЮЊЩюВуЩёОЭјТчдкзіЗЧЯпадБфЛЛЧАЕФМЄЛюЪфШыжЕЃЈОЭЪЧФЧИіx=WU+BЃЌUЪЧЪфШыЃЉЫцзХЭјТчЩюЖШМгЩюЛђепдкбЕСЗЙ§ГЬжаЃЌЦфЗжВМж№НЅЗЂЩњЦЋвЦЛђепБфЖЏЃЌжЎЫљвдбЕСЗЪеСВТ§ЃЌвЛАуЪЧећЬхЗжВМж№НЅЭљЗЧЯпадКЏЪ§ЕФШЁжЕЧјМфЕФЩЯЯТЯоСНЖЫППНќЃЈЖдгкSigmoidКЏЪ§РДЫЕЃЌвтЮЖзХМЄЛюЪфШыжЕWU+BЪЧДѓЕФИКжЕЛђе§жЕЃЉЃЌЫљвдетЕМжТЗДЯђДЋВЅЪБЕЭВуЩёОЭјТчЕФЬнЖШЯћЪЇЃЌетЪЧбЕСЗЩюВуЩёОЭјТчЪеСВдНРДдНТ§ЕФБОжЪдвђЃЌЖјBNОЭЪЧЭЈЙ§вЛЖЈЕФЙцЗЖЛЏЪжЖЮЃЌАбУПВуЩёОЭјТчШЮвтЩёОдЊетИіЪфШыжЕЕФЗжВМЧПааРЛиЕНОљжЕЮЊ0ЗНВюЮЊ1ЕФБъзМе§ЬЌЗжВМЃЌЦфЪЕОЭЪЧАбдНРДдНЦЋЕФЗжВМЧПжЦРЛиБШНЯБъзМЕФЗжВМЃЌетбљЪЙЕУМЄЛюЪфШыжЕТфдкЗЧЯпадКЏЪ§ЖдЪфШыБШНЯУєИаЕФЧјгђЃЌетбљЪфШыЕФаЁБфЛЏОЭЛсЕМжТЫ№ЪЇКЏЪ§НЯДѓЕФБфЛЏЃЌвтЫМЪЧетбљШУЬнЖШБфДѓЃЌБмУтЬнЖШЯћЪЇЮЪЬтВњЩњЃЌЖјЧвЬнЖШБфДѓвтЮЖзХбЇЯАЪеСВЫйЖШПьЃЌФмДѓДѓМгПьбЕСЗЫйЖШЁО1ЁПЁЃ
етРяЗжЮхВПЗжМђЕЅНтЪЭвЛЯТBatch Normalization (BN)ЁО2ЁПЁЃ
1. What is BN?
ЙЫУћЫМвхЃЌbatch normalizationТяЃЌОЭЪЧЁАХњЙцЗЖЛЏЁБПЉЁЃBNБОжЪЩЯНтОіЕФЪЧЗДЯђДЋВЅЙ§ГЬжаЕФЬнЖШЮЪЬтЁЃGoogleдкICMLЮФжаУшЪіЕФЗЧГЃЧхЮњЃЌМДдкУПДЮSGDЃЈЫцЛњЬнЖШЯТНЕЃЉЪБЃЌЭЈЙ§mini-batchРДЖдЯргІЕФactivationзіЙцЗЖЛЏВйзїЃЌЪЙЕУНсЙћЃЈЪфГіаХКХИїИіЮЌЖШЃЉЕФОљжЕЮЊ0ЃЌЗНВюЮЊ1ЁЃетжжЗНЗЈАбЪ§ОнЗжЮЊШєИЩзщЃЌАДзщРДИќаТВЮЪ§ЃЌвЛзщжаЕФЪ§ОнЙВЭЌОіЖЈСЫБОДЮЬнЖШЕФЗНЯђЃЌЯТНЕЪБМѕЩйСЫЫцЛњадЁЃСэвЛЗНУцвђЮЊХњЕФбљБОЪ§гыећИіЪ§ОнМЏЯрБШаЁСЫКмЖрЃЌМЦЫуСПвВЯТНЕСЫКмЖрЁЃ ЖјзюКѓЕФЁАscale and shiftЁБВйзїдђЪЧЮЊСЫШУвђбЕСЗЫљашЖјЁАПЬвтЁБМгШыЕФBNФмЙЛгаПЩФмЛЙдзюГѕЕФЪфШыЃЈМДЕБЃЉЃЌДгЖјБЃжЄећИіnetworkЕФcapacityЁЃЃЈгаЙиcapacityЕФНтЪЭЃКЪЕМЪЩЯBNПЩвдПДзїЪЧдкдФЃаЭЩЯМгШыЕФЁАаТВйзїЁБЃЌетИіаТВйзїКмДѓПЩФмЛсИФБфФГВудРДЕФЪфШыЁЃЕБШЛвВПЩФмВЛИФБфЃЌВЛИФБфЕФЪБКђОЭЪЧЁАЛЙддРДЪфШыЁБЁЃШчДЫвЛРДЃЌМШПЩвдИФБфЭЌЪБвВПЩвдБЃГждЪфШыЃЌФЧУДФЃаЭЕФШнФЩФмСІЃЈcapacityЃЉОЭЬсЩ§СЫЁЃЃЉ
Ъ§ОнОЙ§ЙщвЛЛЏКЭБъзМЛЏКѓПЩвдМгПьЬнЖШЯТНЕЕФЧѓНтЫйЖШЃЌетОЭЪЧBatch NormalizationЕШММЪѕЗЧГЃСїааЕФдвђЃЌЫќЪЙЕУПЩвдЪЙгУИќДѓЕФбЇЯАТЪИќЮШЖЈЕиНјааЬнЖШДЋВЅЃЌЩѕжСдіМгЭјТчЕФЗКЛЏФмСІЁЃ
ЭЈГЃBNЭјТчВугУдкОэЛ§ВуКѓЃЌгУгкжиаТЕїећЪ§ОнЗжВМЁЃМйЩшЩёОЭјТчФГВувЛИіbatchЕФЪфШыЮЊX=[x1,x2,...,xn]ЃЌЦфжаxiДњБэвЛИібљБОЃЌnЮЊbatch sizeЁЃ
ЪзЯШЃЌЮвУЧашвЊЧѓЕУmini-batchРядЊЫиЕФОљжЕЃК

НгЯТРДЃЌЧѓШЁmini-batchЕФЗНВюЃК

етбљЮвУЧОЭПЩвдЖдУПИідЊЫиНјааЙщвЛЛЏЁЃ

зюКѓНјааГпЖШЫѕЗХКЭЦЋвЦВйзїЃЌетбљПЩвдБфЛЛЛидЪМЕФЗжВМЃЌЪЕЯжКуЕШБфЛЛЃЌетбљЕФФПЕФЪЧЮЊСЫВЙГЅЭјТчЕФЗЧЯпадБэДяФмСІЃЌвђЮЊОЙ§БъзМЛЏжЎКѓЃЌЦЋвЦСПЖЊЪЇЁЃОпЬхЕФБэДяШчЯТЃЌyiОЭЪЧЭјТчЕФзюжеЪфГіЁЃ
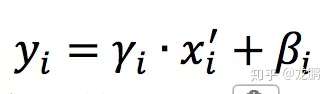
ПЩвдзмНсГЩЯТЭМ;

МйШчgammaЕШгкЗНВюЃЌbetaЕШгкОљжЕЃЌОЭЪЕЯжСЫКуЕШБфЛЛЁЃ
ДгФГжжвтвхЩЯРДЫЕЃЌgammaКЭbetaДњБэЕФЦфЪЕЪЧЪфШыЪ§ОнЗжВМЕФЗНВюКЭЦЋвЦЁЃЖдгкУЛгаBNЕФЭјТчЃЌетСНИіжЕгыЧАвЛВуЭјТчДјРДЕФЗЧЯпададжЪгаЙиЃЌЖјОЙ§БфЛЛКѓЃЌОЭИњЧАУцвЛВуЮоЙиЃЌБфГЩСЫЕБЧАВуЕФвЛИібЇЯАВЮЪ§ЃЌетИќМггаРћгкгХЛЏВЂЧвВЛЛсНЕЕЭЭјТчЕФФмСІЁЃ
ЖдгкCNNЃЌBNЕФВйзїЪЧдкИїИіЬиеїЮЌЖШжЎМфЕЅЖРНјааЃЌвВОЭЪЧЫЕИїИіЭЈЕРЪЧЗжБ№НјааBatch NormalizationВйзїЕФЁЃШчЙћЪфГіЕФblobДѓаЁЮЊ(N,C,H,W)ЃЌФЧУДдкУПвЛВуnormalizationОЭЪЧЛљгкN*H*WИіЪ§жЕНјааЧѓЦНОљвдМАЗНВюЕФВйзїЃЌМЧзЁетРяЮвУЧКѓУцЛсНјааБШНЯЁЃ
ЙигкDNNжаЕФnormalizationЃЌДѓМвЖМжЊЕРАзЛЏЃЈwhiteningЃЉЃЌжЛЪЧдкФЃаЭбЕСЗЙ§ГЬжаНјааАзЛЏВйзїЛсДјРДЙ§ИпЕФМЦЫуДњМлКЭдЫЫуЪБМфЁЃвђДЫБОЮФЬсГіСНжжМђЛЏЗНЪНЃК
- 1ЃЉжБНгЖдЪфШыаХКХЕФУПИіЮЌЖШзіЙцЗЖЛЏЃЈЁАnormalize each scalar feature independentlyЁБЃЉЃЛ
- 2ЃЉдкУПИіmini-batchжаМЦЫуЕУЕНmini-batch meanКЭvarianceРДЬцДњећЬхбЕСЗМЏЕФmeanКЭvariance. етБуЪЧAlgorithm 1.
2. How to Batch Normalize?
дѕбљбЇBNЕФВЮЪ§дкДЫОЭВЛзИЪіСЫЃЌОЭЪЧОЕфЕФchain ruleЃК

3. Where to use BN?
BNПЩвдгІгУгкЭјТчжаШЮвтЕФactivation setЁЃЮФжаЛЙЬиБ№жИГідкCNNжаЃЌBNгІзїгУдкЗЧЯпадгГЩфЧАЃЌМДЖдзіЙцЗЖЛЏЁЃСэЭтЖдCNNЕФЁАШЈжЕЙВЯэЁБВпТдЃЌBNЛЙгаЦфЖдгІЕФзіЗЈЃЈЯъМћЮФжа3.2НкЃЉЁЃ
4. Why BN?
- BNДјРДЕФКУДІЁЃ
- (1) МѕЧсСЫЖдВЮЪ§ГѕЪМЛЏЕФвРРЕЃЌетЪЧРћгкЕїВЮЕФХѓгбУЧЕФЁЃ
- (2) бЕСЗИќПьЃЌПЩвдЪЙгУИќИпЕФбЇЯАТЪЁЃ
- (3) BNвЛЖЈГЬЖШЩЯдіМгСЫЗКЛЏФмСІЃЌdropoutЕШММЪѕПЩвдШЅЕєЁЃ
- BNЕФШБЯн
- ДгЩЯУцПЩвдПДГіЃЌbatch normalizationвРРЕгкbatchЕФДѓаЁЃЌЕБbatchжЕКмаЁЪБЃЌМЦЫуЕФОљжЕКЭЗНВюВЛЮШЖЈЁЃбаОПБэУїЖдгкResNetРрФЃаЭдкImageNetЪ§ОнМЏЩЯЃЌbatchДг16НЕЕЭЕН8ЪБПЊЪМгаЗЧГЃУїЯдЕФадФмЯТНЕЃЌдкбЕСЗЙ§ГЬжаМЦЫуЕФОљжЕКЭЗНВюВЛзМШЗЃЌЖјдкВтЪдЕФЪБКђЪЙгУЕФОЭЪЧбЕСЗЙ§ГЬжаБЃГжЯТРДЕФОљжЕКЭЗНВюЁЃ
- етвЛИіЬиадЃЌЕМжТbatch normalizationВЛЪЪКЯвдЯТЕФМИжжГЁОАЁЃ
- (1)batchЗЧГЃаЁЃЌБШШчбЕСЗзЪдДгаЯоЮоЗЈгІгУНЯДѓЕФbatchЃЌвВБШШчдкЯпбЇЯАЕШЪЙгУЕЅР§НјааФЃаЭВЮЪ§ИќаТЕФГЁОАЁЃ
- (2)rnnЃЌвђЮЊЫќЪЧвЛИіЖЏЬЌЕФЭјТчНсЙЙЃЌЭЌвЛИіbatchжабЕСЗЪЕР§гаГЄгаЖЬЃЌЕМжТУПвЛИіЪБМфВНГЄБиаыЮЌГжИїздЕФЭГМЦСПЃЌетЪЙЕУBNВЂВЛФме§ШЗЕФЪЙгУЁЃдкrnnжаЃЌЖдbnНјааИФНјвВЗЧГЃЕФРЇФбЁЃВЛЙ§ЃЌРЇФбВЂВЛвтЮЖзХУЛШЫзіЃЌЪТЪЕЩЯЯждкШдШЛПЩвдЪЙгУЕФЃЌВЛЙ§етГЌГіСЫдлУЧГѕЪЖОГЕФбЇЯАЗЖЮЇЁЃ
ЪзЯШРДЫЕЫЕЁАInternal Covariate ShiftЁБЁЃЮФеТЕФtitleГ§СЫBNетбљвЛИіЙиМќДЪЃЌЛЙгавЛИіБуЪЧЁАICSЁБЁЃДѓМвЖМжЊЕРдкЭГМЦЛњЦїбЇЯАжаЕФвЛИіОЕфМйЩшЪЧЁАдДПеМфЃЈsource domainЃЉКЭФПБъПеМфЃЈtarget domainЃЉЕФЪ§ОнЗжВМЃЈdistributionЃЉЪЧвЛжТЕФЁБЁЃШчЙћВЛвЛжТЃЌФЧУДОЭГіЯжСЫаТЕФЛњЦїбЇЯАЮЪЬтЃЌШчЃЌtransfer learning/domain adaptationЕШЁЃЖјcovariate shiftОЭЪЧЗжВМВЛвЛжТМйЩшжЎЯТЕФвЛИіЗжжЇЮЪЬтЃЌЫќЪЧжИдДПеМфКЭФПБъПеМфЕФЬѕМўИХТЪЪЧвЛжТЕФЃЌЕЋЪЧЦфБпдЕИХТЪВЛЭЌЃЌМДЃКЖдЫљга,
ЃЌЕЋЪЧ
. ДѓМвЯИЯыБуЛсЗЂЯжЃЌЕФШЗЃЌЖдгкЩёОЭјТчЕФИїВуЪфГіЃЌгЩгкЫќУЧОЙ§СЫВуФкВйзїзїгУЃЌЦфЗжВМЯдШЛгыИїВуЖдгІЕФЪфШыаХКХЗжВМВЛЭЌЃЌЖјЧвВювьЛсЫцзХЭјТчЩюЖШдіДѓЖјдіДѓЃЌПЩЪЧЫќУЧЫљФмЁАжИЪОЁБЕФбљБОБъМЧЃЈlabelЃЉШдШЛЪЧВЛБфЕФЃЌетБуЗћКЯСЫcovariate shiftЕФЖЈвхЁЃгЩгкЪЧЖдВуМфаХКХЕФЗжЮіЃЌвВМДЪЧЁАinternalЁБЕФРДгЩЁЃ
ФЧУДКУЃЌЮЊЪВУДЧАУцЮвЫЕGoogleНЋЦфИДдгЛЏСЫЁЃЦфЪЕШчЙћбЯИёАДееНтОіcovariate shiftЕФТЗзгРДзіЕФЛАЃЌДѓИХОЭЪЧЩЯЁАimportance weightЁБЃЈrefЃЉжЎРрЕФЛњЦїбЇЯАЗНЗЈЁЃПЩЪЧетРяGoogleНіНіЫЕЁАЭЈЙ§mini-batchРДЙцЗЖЛЏФГаЉВу/ЫљгаВуЕФЪфШыЃЌДгЖјПЩвдЙЬЖЈУПВуЪфШыаХКХЕФОљжЕгыЗНВюЁБОЭПЩвдНтОіЮЪЬтЁЃШчЙћcovariate shiftПЩвдгУетУДМђЕЅЕФЗНЗЈНтОіЃЌФЧЧАШЫЖдЦфЕФбаОПвВецецЪЧАззіСЫЁЃДЫЭтЃЌЪдЯыЃЌОљжЕЗНВювЛжТЕФЗжВМОЭЪЧЭЌбљЕФЗжВМТ№ЃПЕБШЛВЛЪЧЁЃЯдШЛЃЌICSжЛЪЧетИіЮЪЬтЕФЁААќзАжНЁБТяЃЌНіНіЪЧвЛжжhigh-level demonstrationЁЃ
ФЧBNЕНЕзЪЧЪВУДдРэФиЃПЫЕЕНЕзЛЙЪЧЮЊСЫЗРжЙЁАЬнЖШУжЩЂЁБЁЃЙигкЬнЖШУжЩЂЃЌДѓМвЖМжЊЕРвЛИіМђЕЅЕФРѕзгЃКЁЃдкBNжаЃЌЪЧЭЈЙ§НЋactivationЙцЗЖЮЊОљжЕКЭЗНВювЛжТЕФЪжЖЮЪЙЕУдБОЛсМѕаЁЕФactivationЕФscaleБфДѓЁЃПЩвдЫЕЪЧвЛжжИќгааЇЕФlocal response normalizationЗНЗЈЃЈМћ4.2.1НкЃЉЁЃ
5. When to use BN?
OKЃЌЫЕЭъBNЕФгХЪЦЃЌздШЛПЩвджЊЕРЪВУДЪБКђгУBNБШНЯКУЁЃР§ШчЃЌдкЩёОЭјТчбЕСЗЪБгіЕНЪеСВЫйЖШКмТ§ЃЌЛђЬнЖШБЌеЈЕШЮоЗЈбЕСЗЕФзДПіЪБПЩвдГЂЪдBNРДНтОіЁЃСэЭтЃЌдквЛАуЪЙгУЧщПіЯТвВПЩвдМгШыBNРДМгПьбЕСЗЫйЖШЃЌЬсИпФЃаЭОЋЖШЁЃ
ВЮПМЃК
ЁО1ЁПЁОЩюЖШбЇЯАЁПЩюШыРэНтBatch NormalizationХњБъзМЛЏ
ЁО2ЁПЩюЖШбЇЯАжа Batch NormalizationЮЊЪВУДаЇЙћКУЃПЃКhttps://www.zhihu.com/question/38102762