R-FCN的位置敏感分数图灵感来自Instance-sensitive Fully Convolutional Networks这篇论文,该论文是针对FCN不能对同类型物体分割的缺点的改进,具体说明见下面:
本论文的出发点:
FCN可以用来做segmentation(分割), 做法是把这个分割问题看成是per-pixel的classification问题。如果有C类,那么就在feature map上生成C类分数图(图一(c))。但是这种做法无法做instance segmentation(实例分割),即对同一类型的各个对象是无法区分的。如下图二所示:

图一 (a)图像分类结果,(b)目标检测, (c)语义分割 ,(d)本文所述的对象分割【1】
图二 FCN语义分割
原本的FCN语义分割方法无法区分图二的两个人的原因是因为conv提取的特征具有位置不变性。这两个人虽然位置不一样,但是它们最终产生的feature map差不多。那么如何做instance-level的segmentation呢?这篇paper给出了一种解决方法。
Instance-sensitive Fully Convolutional Networks
想要做Instance Segmentation,就需要像素针对不同的Instance有不同的响应。为了解决这个问题,作者提出了Instance-FCN。该论文是在FCN基础上面做的改进,利用全卷积实现了Instance-Segmentation。具体流程如下:
1)提出了 instance-sensitive score map
在传统的FCN中,每个图像只生成一个score map,每个像素的值表示该像素是否属于目标的概率。
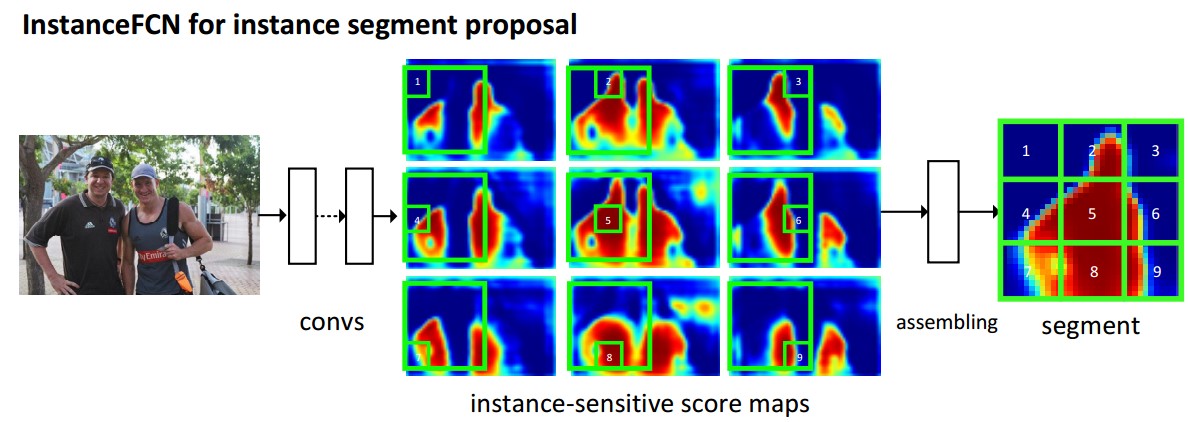
在Instance-FCN中,作者会生成k?k 个score maps,每个像素的值表示该像素是否属于某一类的某个相对位置的概率。
(a)

(b)
图三 Instance FCN 处理流程
instance-sensitive score map其实就是位置敏感图,将FCN中原来输出的一个feature map,换成了k?(9个),这9个feature map 分别对应如上图所示的9个位置(如图三b所示)。如果是FCN产生的feature map,肯定不能将两个人分开,但是如果得到的是两个的头,左手,右手的feature map这种相对位置信息,这样就能很好的将两人分开了。
对于(a)左边那个人,将它分成9份,每个小窗口标记这个个体的不同位置。所以这个个体会产生9个feature map,每个feature map识别是否属于对应的相对位置。需要注意的是,这个paper最终产生的结果是instance level的mask proposal,并没有做分类。类似于RPN的Region proposals, 最终产生一个窗口,由这九个窗口对应的位置拼接而成。窗口中每个像素有两种label, 一种为background, 一种为foreground。
R-FCN的位置敏感分数图就是借鉴的这个思想,输入一张有C类物体的图片,见下图,则会有(C+1)个分类,C类物体,1是背景。用这种方法生成位置敏感分数图后,会生成K*K*(C+1)维的特征,按照图三的原理,每类图都会生成K*K维的敏感分数图来表示该类物体各位置的特征。比如第一维(黄色部分)提取RPN网络中给出的各个Ro(即推荐取域)左上角的特征(因为有(C+1)类物体,所以有C+1维个位置敏感分数图),第二维浅黄区域表示物体左中部的特征...第K^2维表示右下角特征。判断该 instance是不是目标的介绍见下面的“训练过程”,剩下的训练部分见【4】

图四 R-FCN处理流程
注:
- 这里生成的feature map是针对整张图提取的,那每类的K*K个分数图标注的目标就是RPN网络输出的推荐框。
- pool及以后的部分都是每个RoI单独进行的
2)Assembling
这一步需要考虑的是如何将9个feature map聚集在一起,这里选用了一种很简单粗暴的模式,就是选取一个m*m大小的滑动窗,滑动窗被分成了9格,直接将滑窗对应位置的像素复制过来。构成一个完整的实例。
说简单粗暴是因为,在feature map 上搞一个固定的滑动窗口(文章中取的是21*21,步长是8(这里为什么是8呢?又涉及到一个local coherence的问题,大概意思就是像素点具有局部连续性,相邻像素点的输出应该是相同的,而逐像素遍历会使参数很多,所有就以一定的步长遍历,减少参数的数量))。
好了,将滑动窗口在9个feature map 上面做一个映射,简单粗暴的把对应位置的值抠出来,拼在一起就能得到一个Instance的mask 图了(我理解的这个mask图应该也只是一个0-1图)。所以你不知道到底0是目标还是1是目标,因此只好再加一个score层来简单分类一下了(是目标or不是目标)。
具体网络结构:
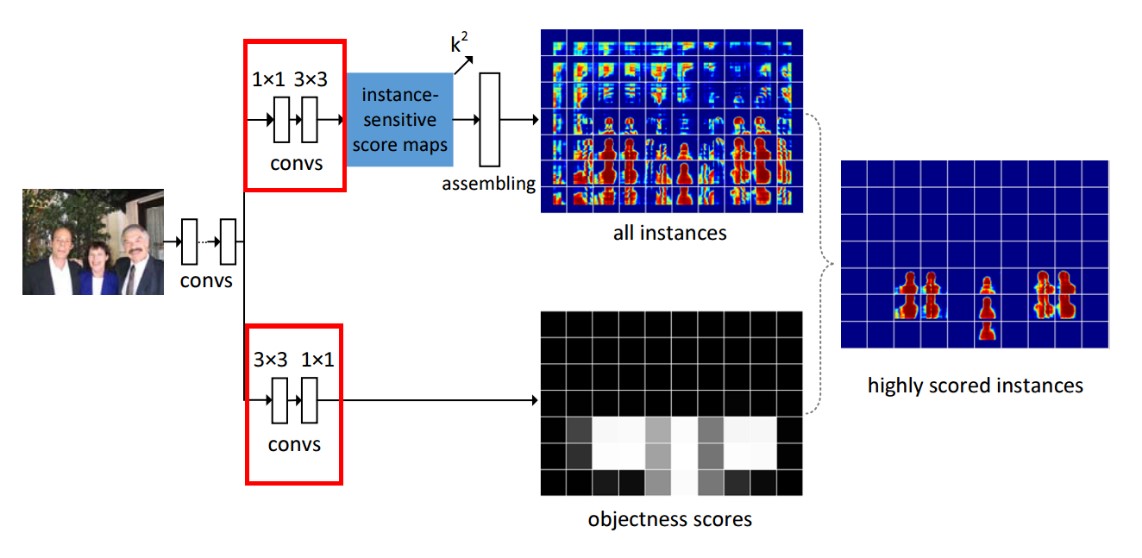
1)基础网络:大家最喜欢的VGG16,前面13个conv层(2+2+3+3+3)【2】。
这里做了改进,将pool4的步长从2换成1(不降维)。然后将conv5_1 到 conv5_3换成空洞卷积,使感受野更大。
2)estimating segment instances。这里先做了一个1*1(目的是通道的融合?),再做了一个3*3(不知道搞啥?),然后得到实例敏感得分图,在做一个assembling,得到所有实例的mask。
3)scoring the instances 这里先做了一个3*3(目的是通道的融合?),再做了一个1*1(不知道搞啥?)然后一个logistic,用于过滤instances,得到某个像素是不是目标。
On the top branch,会生成k2 个Instance score map,也就是每个像素都会有k2个不同的值,即解决了相同像素在不同Instance中有不同的响应。然后经过assembling module就可以生成all Instance map。但是并不是所有的响应都有Instance出现。所以作者在bottom branch,计算了objectness score map。将两者融合就能获得最终的Instance Segmentation。
训练过程
对于输入图片,首先通过一个修改后的vgg16的卷积层,得到一个大小为1/8的feature map。然后分为两支,上面一支生成k*k的feature map, 下面那支生成一个feature map,每个像素表示以这个像素为中心的窗口是否包括一个instance。然后,对每张图片,随机sample 256个窗口,以这256个窗口对应的feature map(包括上下两支)及对应的label信息作为监督信息来进行网络学习。计算的公式如下【3】:

Inference

【1】对象分割--Instance-sensitive Fully Convolutional Networks:https://blog.csdn.net/zhangjunhit/article/details/72271178
【2】实例分割之——Instace-sensitive Fully Convolutional Networks:https://blog.csdn.net/qq_23126625/article/details/80551671
【3】论文笔记: Instance-sensitive Fully Convolutional Network:https://zhuanlan.zhihu.com/p/29488501
【4】R-FCN:基于区域的全卷积网络来检测物体:https://blog.csdn.net/shadow_guo/article/details/51767036
【1】论文阅读:Instance-sensitive Fully Convolutional Networks:https://blog.csdn.net/Ethan_Wuuu/article/details/76944945
【2】论文笔记: Instance-sensitive Fully Convolutional Network:https://zhuanlan.zhihu.com/p/29488501