论文:https://arxiv.org/pdf/2005.11475.pdf
代码:https://github.com/Caojunxu/AC-FPN
在目标检测中,如何解决高分辨率输入条件下特征图分辨率与感受野之间的矛盾仍然是一个有待解决的问题。为了解决这一问题,作者提出了注意引导的上下文特征金字塔网络(AC- FPN),该网络通过整合注意引导的多路径特征来利用来自不同感受野的判别信息。该模型包含两个模块。第一个是上下文提取模块(CEM),它从多个接受字段中挖掘大量的上下文信息。由于冗余的上下文关系可能会误导定位和识别,作者还设计了第二个模块――注意引导模块(attention -guided module, AM),它可以利用注意机制自适应地捕获对象的显著依赖关系。AM由两个子模块组成,即上下文注意模块(CxAM)和内容注意模块(CnAM),分别侧重于捕获区别语义和定位精确位置。最重要的是,AC-FPN可以很容易地插入现有的基于fpn的模型。
一、文章简介:
由于网络结构的限制,基于fpn的方法不能很好地利用不同大小的接受域。具体来说,这种自下而上的途径只是叠加几层来扩大接受区域来激励信息传播,不同感受野对应的特征映射通过自顶向下路径的元素加法合并。因此,不同的感受野所捕获的语义信息不能很好地相互沟通,导致性能有限。
当前基于FPN的方法存在两个主要问题:
1)高分辨率输入的特征映射分辨率和感受野之间的矛盾;
2)多尺度感受野之间缺乏有效的通信。
上下文提取模块(CEM)。在不显著增加计算开销的情况下,CEM可以使用不同膨胀率的多路径扩展卷积从不同的大小的感受野捕获丰富的上下文信息(如下c)。此外,为了详细地合并多感受野信息,在CEM中引入了不同感受野层之间的密集连接。

图1.(a)检测到的物体。 (b)相同模型在不同尺寸图像上的感受野。 (c)从各个感受野获得的上下文信息。 (d)确定的尺度关系。 虚线表示对图像的依赖性,线宽表示相关度
尽管CEM的特征包含丰富的上下文信息,在很大程度上有助于检测不同尺度的目标,但它有些杂,因此可能会混淆定位和识别任务。因此,如上 (d)所示,为了减少冗余上下文的误导,进一步增强特征的识别能力,设计了另一个模块Attention-guided module (AM),该模块引入了一种自注意机制来捕获有效的上下文依赖。具体来说,它包括两个部分:
1)上下文注意模块(CxAM),其目标是捕获特征映射任意两个位置之间的语义关系;
2)内容注意模块(CnAM),其目标是发现空间依赖性。
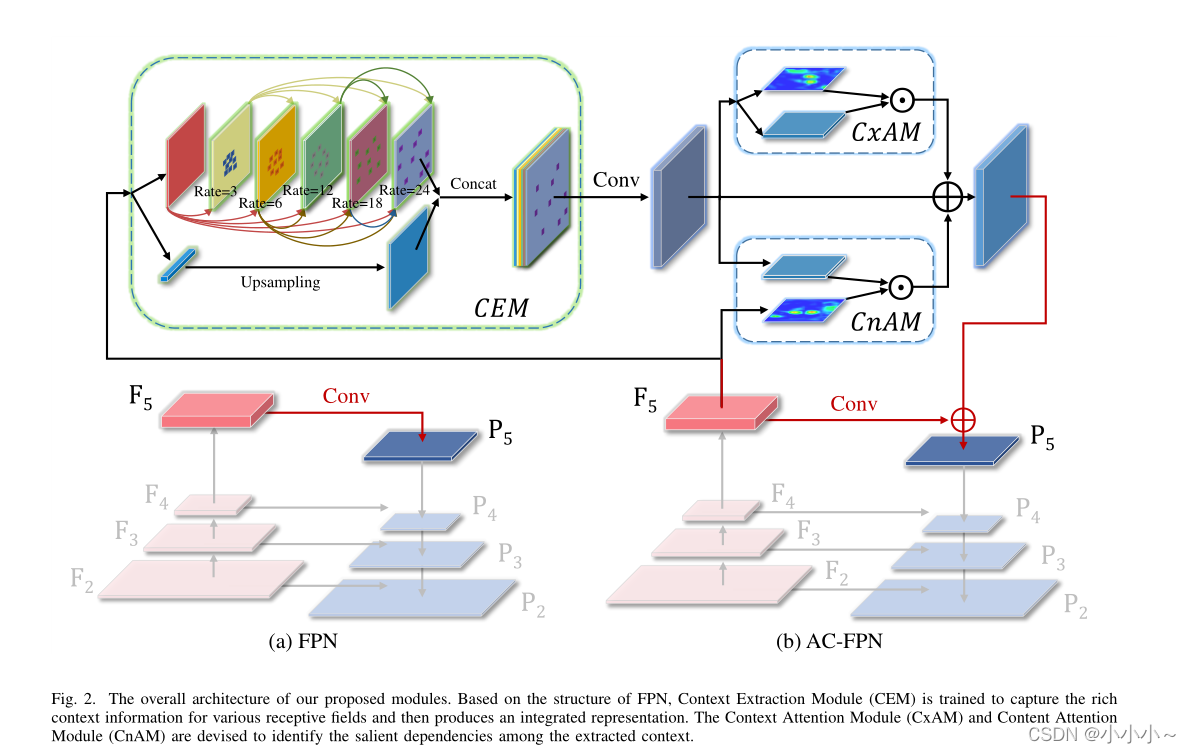
为了解决这些问题,作者提出了一种新的注意引导的上下文特征金字塔网络(AC-FCN),该网络从不同大小的接受域中捕获上下文信息,并生成具有较强识别能力的客观特征。如上所示,在FPN基本架构的基础上,模型有两个新的组件:
1)上下文提取模块(Context Extraction Module, CEM),它从不同大小的接受域中挖掘丰富的上下文信息;
2)增强显著上下文依赖的注意引导模块(AM)。
如上所示,对于自底向上的路径,将每个尺度下卷积层的输出表示为{F2, F3, F4, F5}。同样的自上而下的路径和横向连接都遵循原始文件中的官方设置。
(一)、Context Extraction Module
在获取了前一层(即F5)的特征图后,为了挖掘丰富的上下文信息,将其输入到CEM中,CEM由不同比率的多路径扩展卷积层组成,如rate = 3,6,12。这些分离的卷积层可以在不同的感受野中获取多个特征图。此外,为了增强几何变换的建模能力,在每条路径中引入了可变形的卷积层。它保证了CEM能够从给定的数据中学习到转换不变的特征。
此外,为了精细化地合并多尺度信息,在CEM中采用密集连接,将每个膨胀层的输出与输入的特征图连接,然后送到下一个膨胀层。DenseNet利用密集连接来解决梯度消失的问题,并在CNN模型越深入时加强特征传播。相比之下,使用密集方式来实现具有不同接受域的特征的更好的尺度多样性。最后,为了保持初始输入的粗粒度信息,将扩展层的输出与上采样的输入连接起来,并将它们送入一个1×1卷积层以融合粗粒度和细粒度特征。
(二)、Attention-guided Module
虽然来自CEM的特征包含丰富的接受域信息,但并不是所有的特征都有助于提高对象检测的性能。由于边界框或区域建议被冗余信息误导,精度可能会降低。因此,为了消除冗余的负面影响,进一步提高特征映射的表示能力,提出了一种注意引导模块(Attention-guided Module, AM),该模块能够捕获具有强语义和精确位置的显著依赖。如下所示,注意模块由两部分组成:
1)上下文注意模块(CxAM)
2)内容注意模块(CnAM)。
CxAM关注给定特征映射(即来自CEM的特征)的子区域之间的语义。然而,由于可变形卷积的影响每个物体的位置都被极大地破坏了。为了缓解这个问题,引入了CnAM,它更注重保证空间信息,但由于较浅层(即F5)的关注,牺牲了一些语义。最后,将CxAM和CnAM提炼的特征与输入特征进行合并,获得更全面的表示。
(1)、上下文注意模块
为了主动捕获子区域之间的语义依赖关系,引入了一个基于自注意机制的上下文注意模块(Context Attention Module, CxAM)。将上述由CEM产生并包含多尺度接收域信息的特性输入到CxAM模块中。基于这些信息特征,CxAM自适应地更加关注相关性更强的子区域之间的关系。因此,来自CxAM的输出特性将具有明确的语义,并在周围对象中包含上下文依赖关系。
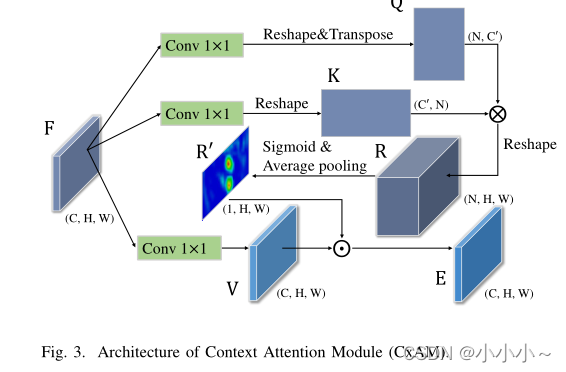
从上图中可以看出,给定判别特征映射 F ∈ R C × H × W F∈R^{C×H×W} F∈RC×H×W,分别使用卷积层 W q W_q Wq?和 W k W_k Wk?将其转换为一个潜空间。

其中,{Q, K} ∈ R C ’ × H × W ∈ R^{C^’×H×W} ∈RC’×H×W, 然后,将Q和K reshape为 R C ’ × N R^{C^’×N} RC’×N,其中N = H×W。为了捕获每个子区域之间的关系,计算一个相关矩阵为

其中 R ∈ R N × N R∈R^{N×N} R∈RN×N,然后被reshape为 R ∈ R N × H × W R∈R^{N×H×W} R∈RN×H×W。通过sigmoid激活函数和平均池化将R归一化后,建立了一个注意力矩阵 R ’ R^’ R’,其中 R ’ ∈ R 1 × H × W R^’∈R^{1×H×W} R’∈R1×H×W。同时,利用卷积层 W v W_v Wv?将feature map F转换为另一种表示V

其中 V ∈ R C × H × W V∈R^{C×H×W} V∈RC×H×W。
最后,对 R ’ R^’ R’和特征V进行逐元素乘法,得到注意力表示e。将函数表示为

其中 E i E_i Ei?为第i个特征图,通道维数为C。
(2)、Content Attention Module
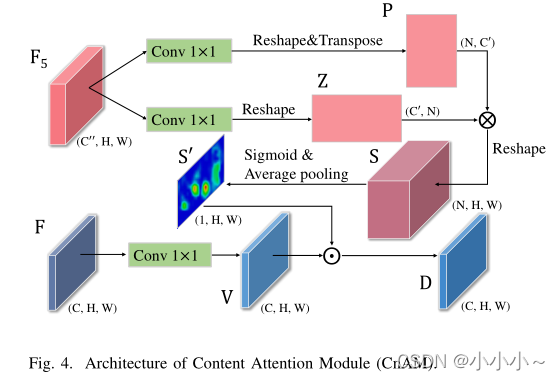
由于可变形卷积的影响,给定图像的几何性质被极大地破坏,导致了位置偏移。为了解决这一问题,我们设计了一种新的关注模块,即内容关注模块(Content attention module, CnAM),以保持每个对象的精确位置信息。如下所示,CxAM使用卷积层对给定的feature map进行转换。但是,没有使用feature maps F来生成注意力矩阵,而是采用feature maps F 5 ∈ R C ′ ′ × H × W F_5∈R^{C''×H×W} F5?∈RC′′×H×W,可以更精确地捕捉到每个对象的位置。
为了得到注意矩阵,首先应用两个卷积层 W p 和 W z W_p和W_z Wp?和Wz?,将 F 5 F_5 F5?转换为潜空间,分别为:

其中{P, Z} ∈ R C ’ × H × W ∈R^{C^’×H×W} ∈RC’×H×W。然后,将P和Z的维数reshape为 R C ′ × N R^{C'×N} RC′×N,得到相关矩阵为:

其中 S ∈ R N × N S∈R^{N×N} S∈RN×N。将S reshape为 R N × N R^{N×N} RN×N后,利用sigmoid和平均池化得到一个注意矩阵 S ’ ∈ R 1 × H × W S^’ ∈R^{1×H×W} S’∈R1×H×W。为了得到一个突出的表示,将提取的特征V与S0通过逐元素乘法结合起来

其中 D ∈ R C × H × W D∈R^{C×H×W} D∈RC×H×W, D i D_i Di?表示第i个输出特征图。
对于AC-FPN,与原始FPN不同的是,本文通过max pooling对F5和子样本P5进行扩张卷积,以保持与FPN相同的步幅。更具体地说,在CEM中,首先将F5减少到512个通道作为输入,然后是几个具有不同膨胀率的可变形卷积层,例如,3,6,9。然后将输出减少到256个通道,再利用自顶向下的FPN结构。使用1 ×1卷积,将CnAM的输入减少到256个通道,CxAM的输入减少到128个通道。
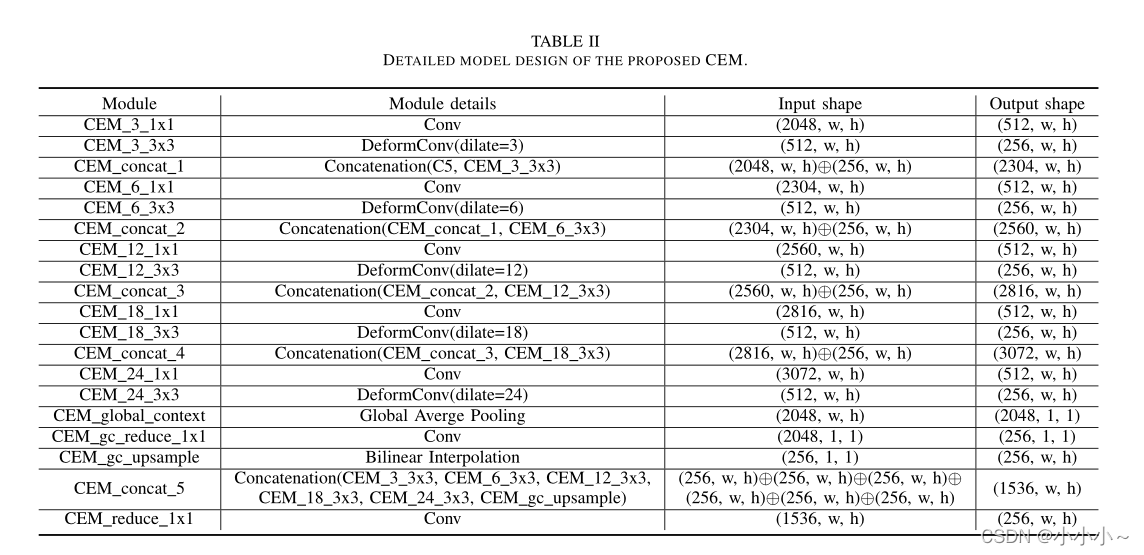
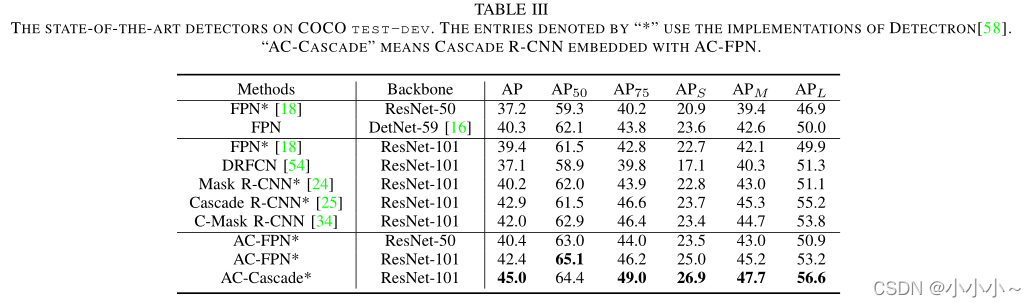
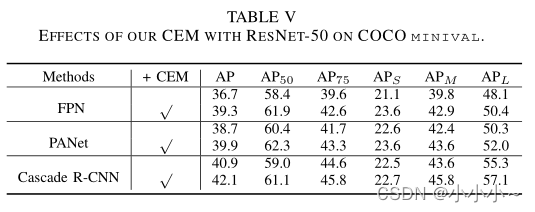
CEM的影响