0. Abstract
提出了与具体应用和网络结构无关的两阶段的loss矫正,并说明如何估计NTM,提出了端到端的框架,用实验证明了框架的鲁棒性。
1. Introduction
将目前的LNL(label noise learning,标签噪声学习)分为两部分:专为问题设计的架构(没有理论框架,需要干净数据辅助),理论研究(但是通常需要噪声率,很难事先可知),本文针对loss,对NN的loss进行校正,将噪声估计和loss校正结合,实现标签噪声下的网络的学习。
Contribution:
- 提出了前后向校正
- 与结构和应用领域无关
- 可用于多类
- 全ReLU的网络的Hessian矩阵独立于噪声。
且在MNIST, CIFAR-10, CIFAR-100,IMDB上测试了算法的有效性;前向矫正会更好一些(可能是从计算量角度出发的,后向矫正需要计算噪声传输矩阵(NTM)的逆);估计噪声率是瓶颈问题。
2. Related work
从4各方面展开:噪声鲁棒性,代理损失,(标签)噪声率估计,带有标签噪声的深度学习。此部分略过。本文受 [28,39] 的启发。
[39](线性层):将NTM estiamtion和loss correction同时进行,本文分别进行。
[28](噪声修正的loss):没有人将噪声修正的loss应用到NN上,本文进行了尝试(主要是针对有限样本训练的网络,因为loss修正对于深层的大容量网络可能不是必须的,因为网络有容量裕量记忆效应提到过[1])
3. Preliminaries
进行符号说明,LNL和NN训练过程的数学抽象。
4. Label noise and loss robustness
本文关注非对称噪声。
1. 后向校正
- 参考文献有[28,Theorem 1], [40, Theorem 3.2]
定理1:
校正之后的loss的期望和干净标签loss的期望相等
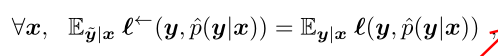
证明看不懂。
2. 前向校正
- 定理2:
参考文献
[33] Section 4
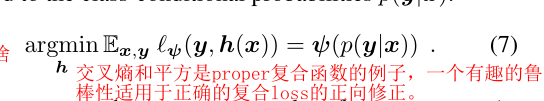
这个看不懂
关键是这个ψ\psiψ看不懂是什么,前向矫正就看不懂了。
前向校正不需要求逆,链接函数是关键。
5. 整体算法
两个假设:
(1)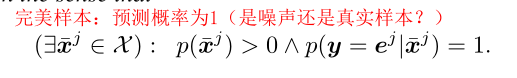
完美样本,意思我理解是p(xˉj)=1p(\bar{x}^j)=1p(xˉj)=1,换言之就是clean样本。
(2)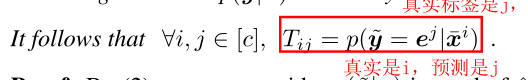
建立在(1)的基础上,如下式所示:
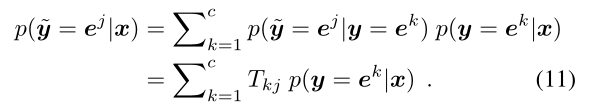
当完美样本xˉi\bar{x}^ixˉi找到时,xˉi\bar{x}^ixˉi的存在本身就代表y=eiy=e^iy=ei,所以(2)就存在。
在实际操作时,TTT可以事先给定,也可以通过网络自己学习,从数据中学习依靠上面两个假设,改写为下面两个公式:
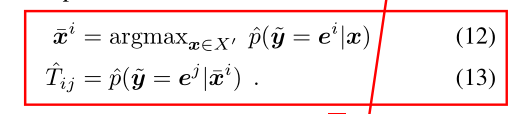
用算法1

思想:从噪声标签训练的网络的softmax中取最大的作为完美样本,取其对于其它各个类的概率作为T^ij\hat T_{ij}T^ij?(感觉这样做不太靠谱啊…)
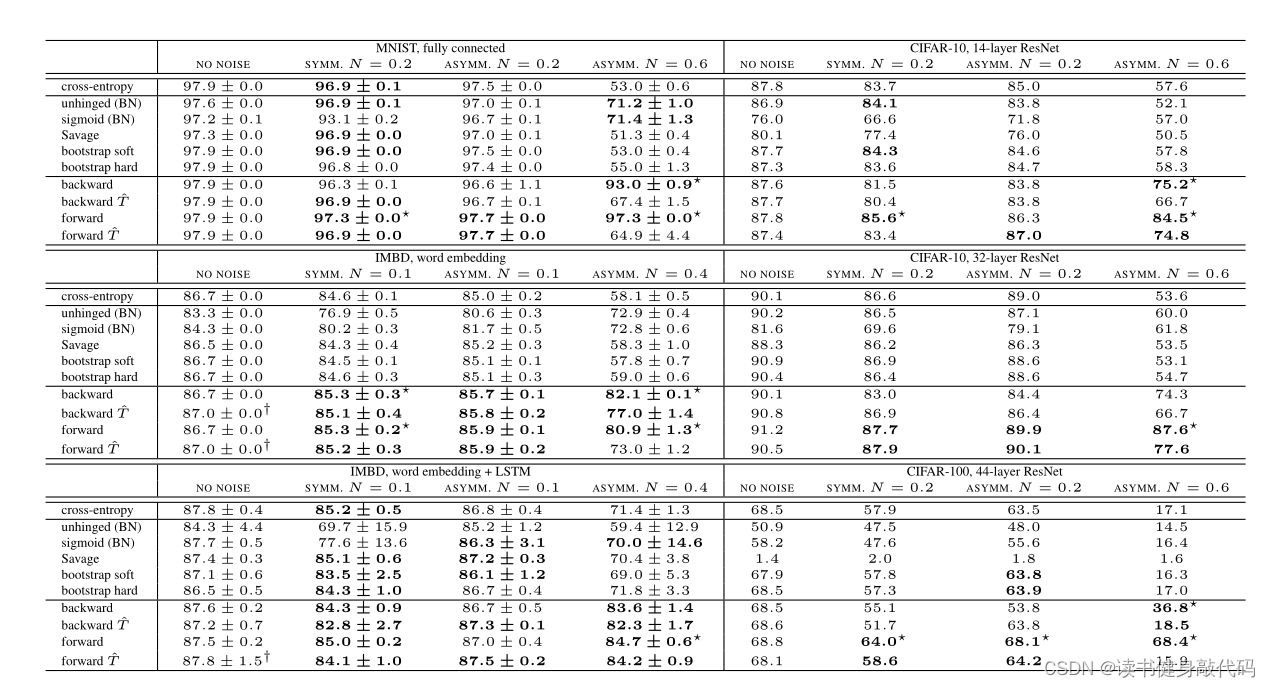
结果上看不太好,等明天再看看[33]等参考文献吧。
Reference for this blog
[1] Arpit, Devansh et al. “A Closer Look at Memorization in Deep Networks.” ArXiv abs/1706.05394
(2017): n. pag.
[2]