���µ�ַ��https://ieeexplore.ieee.org/document/9143165
���������˻������ѧϰ��СĿ����������о����������ȼ�Ҫ������СĿ������Ĵ�֧����������߶ȱ�ʾ����������Ϣ�����ֱ��ʺ������顣Ȼ���г�������СĿ������������ݼ������⣬���Ļ��о������Ƚ���СĿ�������磬�ر��ע������ͨĿ������ϵ�ṹ��ȵIJ���Ľ������������ܡ����СĿ�����δ�����������һЩ��ϣ���ķ��������
һ�����¼�飺

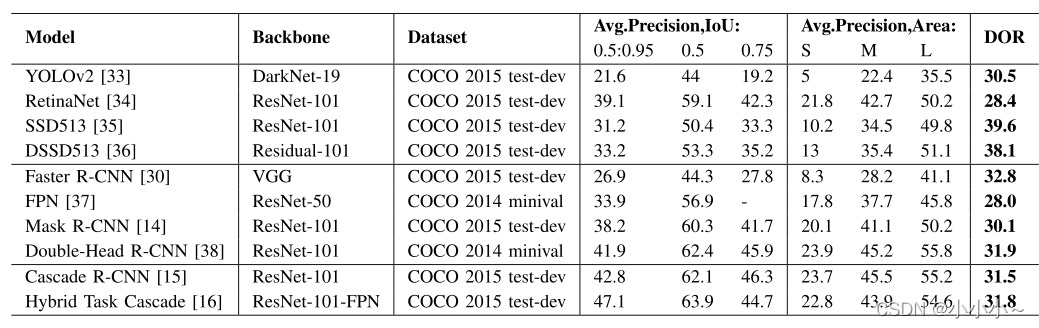
С�������ϸ��������ò�ͬ�ķ������˵�������磬С����߽��ij��ȺͿ�������ӦС��32��С����߽��Ӧ����ԭʼͼ���1%���¡����ڽϵ͵�ͼ���ʡ����ٵ���������ͽϴ�����ݼ���СĿ�������ͨĿ��������ѡ���ͼ�����������С�������һ�������⡣��ͼΪ��ֹ2020����صľ������磬���У�ƽ�����ȣ�IoU 0.5:0.95��ʾIoU��ƽ��APΪ0.5��0.95������Ϊ0.05��ƽ������IoU 0.5��Ӧ��IoU=0.5��AP��ƽ������IoU 0.75��Ӧ��IoU=0.75��AP�����⣬�����С�Ķ������ǣ�С����С�� 3 2 2 32^2 322�����еȶ��� 3 2 2 32^2 322�� 9 6 2 96^2 962���ʹ������ 9 6 2 96^2 962�������±��У�����������һ����Ϊ�����ٳ̶Ƚ��͡���DOR������Ŀ����˵����Ŀ�����СĿ����֮��ľ����ܲ�ࡣ���Կ����������ͻ����������ȣ�С�������ƽ�����ȣ�AP��Ҫ�͵öࡣ���������ڸ����ݼ���ѵ����ͨ�ö���������С�����ϵ����ܶ��ܲ��Ϊ�д��Ͷ��������ԶԶ����С����
���Ż������ѧϰ��Ŀ���⼼���ķ�չ���������СĿ������ͼ�����类������ڱ����У�СĿ���ⷽ����Ҫ��Ϊ�Ĵ�֧�����ĸ�֧���Ļ������������е�Ŀ�����ܣ���mmdetection�еĶ��壬�ÿ�ܽ��������Ϊ����ģ�飬����Backbone, Neck, AnchorHead, RoIExtractor, and RoIHead��ǰ�������ڶ�߶ȱ�ʾ����������Ϣ��֧�����ھ�������������������ɵ�ԭʼ����ͼ����ϸ�����������á���������Ҫ��AnchorHead����йء������ֱ��ʲ�����������һ����ɲ��֣�����baseline detectors�Ļ�����������������֧���磬��������������ͼ��������硣���ǵ����Ѿ���ΪСĿ�����һ�������о���������Ҳ��������Ϊһ��֧����
��������ϸ��
��߶ȱ�ʾ��һ���棬dz��conv���е���ϸ��Ϣ���ڶ���λ�DZ�Ҫ�ġ���һ���棬���conv���е�������Ϣ����شٽ��˶�����ࡣ����С�����С�ߴ�͵ͷֱ��ʣ�λ��ϸ���ڸ�������ͼ����ʧ���������ͨ�ü����ֻ�������һ���������м���������ḻ�ķָ���Ϣ����ȱ����ϸ��Ϣ����߶ȱ�ʾ��һ�ֽ��ͼ�������ͼ�е���ϸλ����Ϣ���������ͼ�еķḻ������Ϣ���ϵIJ��ԡ�
��������Ϣ��������ʵ�����ж������乲�滷��֮��Ĺ�ϵ����������Ϣ�����С�����⾫�ȵ���һ���·��������ͺʹ��������������ͨ̽�������ṩ�㹻��ROI������Ȼ�������ڴ�С��������ȡ�ĸ���Ȥ�����������٣�����б�Ҫ��ȡ�������������Ϣ��Ϊԭʼ����Ȥ���������IJ��䡣
���ֱ�����������������ϸ��ϸ�ڶ��ڶ���ʵ����λ������Ҫ�����ֱ��ʼ�����ͼ��ԭʼ�ͷֱ���ͼ��ָ����ؽ������ߵķֱ��ʣ�����ζ�ſ��Ի��С����ĸ���ϸ�ڡ����磬GAN�ĺ���˼��������������ͼ��������硣������Կ��ԵĹ����У�������������ʵͼ��������ͼ������������ͼ��������ڲ�����ߡ�
����������������һ��ּ��ΪС������Ƹ�����ê��IJ��ԡ�Ŀǰ����̽������ê����Ҫ��������ͨ�����ϣ��������ͨ̽������ʹ�õ�ê��Ĵ�С����״���������ܺܺõ���С������ƥ�䡣�����������������Щê����ֱ��Ӧ����СĿ�꣬�����������Ϣ�����¾�ļ���ɱ��������ͼ�⾫�ȡ�
СĿ����Ŀ����Ҫ��Ϊ���֣�һ���������ֹ�������dz�������������·�ϵ��ϰ����ͨ��־��Ŀ�꣬����������ȡ����������ͨ�����ܽϲ��һ���Dz���DCNN��ȡͼ��������Ȼ���������ͨ��Ŀ������������ģ��Դﵽ���Ⱥͼ���ɱ����������ԡ�Ϊ��������ߴ�ͳ��СĿ�������ܣ���������˸��ָ������·��������Ľ�СĿ������о�������Ϊ���࣬����߶ȱ�ʾ����������Ϣ�����ֱ��ʡ��������������������ϸ������ÿ�������������õ����磬ͬʱ��Ҫ˵�������������磬�Ա��ÿ�������������Ľ��͡�
��һ������߶ȱ�ʾ
СĿ�����������ʾ�Ǽ�����ܲ����Ҫԭ����CNN�ͳػ����ظ��²�����������������ͼ�д��ڵ�С�����������١����⣬������������������ӣ����еIJ�νṹ���ɾ��в�ͬ�ռ�ֱ��ʵ�����ͼ��������˵����Ȼ����IJ��������ĸ���Ұ����ǿ�����塢�Ա��Ρ��ص����ձ仯�ĸ���³���ԣ�������ͼ�ķֱ��ʻή�ͣ����һᶪʧ����ϸ����Ϣ�����֮�£�dz��ĸ���Ұ��С���ֱ��ʽϸߣ���ȱ��������Ϣ��
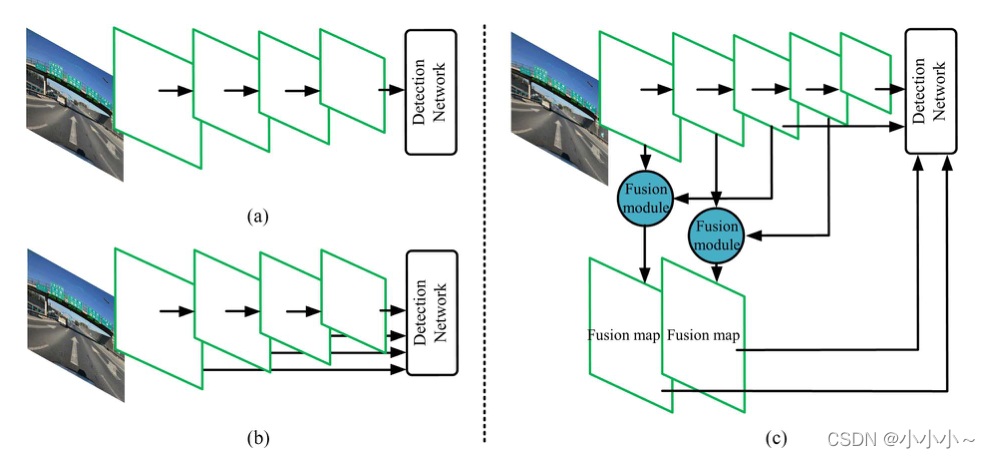
1�� ������ͼ�ںϣ�һЩ���еĶ�����������R-CNN��Fast R-CNN��Faster R-CNN��YOLO��ֻʹ�����һ�������ͼ����λ����Ԥ�����Ŷȷ���������(a)��ʾ������ȱ����ϸ��Ϣ����Щģ����������С���塣SSD��������������������ÿ������ӳ��ӵײ���װ����������㣬���£�b����ʾ���Ӷ��Ľ���С�����⡣Ȼ�����������м�����������ܻ������������Ҫ�ı�ʾ�����ͽϸߵļ��㸴�Ӷȡ�Ϊ�˼����粢����Ч�ʣ�һЩ�о���Ա�����˷����㣬ֻѡ����������ϸ��������Ϣ����Ҫ����ͼ��
MDSSD����������˷������ںϿ飬�ÿ������ת�������ںϸ����������������ڸ�ģ���У����Ƚ�������ͬ�߶ȵĸ���������ͼ��SSD���conv8_2��conv9_2��conv10_2�����뷴���㣬Ȼ��Ԫ�ؽ�����dz�㣨VGG16���conv3_3��conv4_3��conv7����ӡ�Ӧע����ǣ������������ڽ��߲�����ͼ�IJ�����ߵ�����Ӧ�Ͳ���ͬ�ķֱ��ʡ�SSD������ģ�͵����ɣ��ںϹ������ںϿ�����ɡ�����˼�����£�c����ʾ��
DR-CNN����MDSSD���õ�Ԫ�غͲ��Բ�ͬ�����ڷ���������ľ��������磨DR-CNN�����ü����������ں϶�߶�������ͼ������С��ͨ��־��⡣DR-CNN��VGG16��ѡ��conv3��conv4��conv5���γ����ں���RPN�ͼ����ں�����ͼ����ÿ��������ģ��֮��L2��һ����Ҳ������ȷ������ͬ�ij߶������ӵ�����������������һ�������ǹ�����ʧ������Hard negative samples��ѵ�����кܴ�ô���Ȼ������ͨ�Ľ�������ʧ�����������ּ���������Hard negative samples����ˣ�Ϊ�˳������Hard negative samples�Ի�ø��õ����ܣ���RPN��ȫ�������У���һ���µ�������������Ӧ��ʧ����ȡ���˳����Ľ�������ʧ������
MR-CNN�����ڶ�߶�����ľ��������磨MR-CNN�����������С��ͨ��־ʶ�����ж�߶ȷ������������������Ӹ�������������IJ�����������dz��ֱ�����ӣ������ں�����ͼ����ˣ��ںϺ������ͼ�������ɸ��ٵ������飬����ø��ߵ��ٻ��ʡ����⣬���Խ���������÷���������Ч����ǿ������ʾ�����С��ͨ��־�������ܡ�
�������ܵķ��������⣬�ںϵĶ�߶�������ͼ���ڶ�λ����λ�ã���ʹ�������Ϣִ�ж�����ࣻ����������ǿ���磨BFEN�����������������Ϣ�Ӹ߲㴫�䵽�ײ㣻��ϸ�����������ӳɿռ䲼�ֱ������磨SLPN��������ROI�ز�Ŀռ���Ϣ��ʵ�ָ��õĶ�λ���ȣ���ȡ���������ĺ͵�������������ͼ����������ϳ�һά�������з���Ͷ�λ����һ���Ż�ê���ߴ�ķ��������ڵ�·���������ں϶༶����ͼ����Inceptionģ���������һ���µ������ںϻ��ơ�ѡ��YOLOv3��Ϊ������ܣ�ʹ�ö�߶Ⱦ������γɲ�ͬ��С�ĸ���Ұ�����Գ�����õͲ���Ϣ��
����������ͬ�����ص����ӷ�����
��Ȼ��������ڶ�߶ȱ�ʾ����������Ϊ�����СĿ�����Ч�ʶ�����ģ����Ƕ�������ںϸ߲�����ͼ�͵ײ�����ͼ����ع���ȴ���١� CADNet�������ͨ����֪���������磨CADNet���������о���㲻ͬͨ���е�����ͼ֮��Ĺ�ϵ���Ա�������ͼ�ļ��ӡ�ͨ�����ò�ͬ�߶�����֮�������ԣ������ڽϵ͵ļ���ɱ������СĿ����ٻ��ʡ�����ͼ��ʾ���ÿ�ܷ�Ϊ�������裬����scale transfer layer���������Ԫ�����ģ�顣�ر��ǣ�scale transfer�㽫ÿ�ĸ�ͨ�����ĸ�����������֯����άƽ���ϵ���ͬλ�ã��Ի��λ��ϸ�ڲ����������ͼ�ķֱ��ʡ�Ȼ��ͨ��һ��4��4�˴�С�ľ���������������ӳ��ĸ���������Ϣ������ͼ����һ��ͨ��elementwise�������ӡ���ˣ��ںϲ�Ȱ����ײ��ϸ����Ϣ��Ҳ�����߲��������Ϣ�� һ����˵����������ͼ�ں������ڲ�ϸ����Ϣ�ͷḻ��������Ϣ���ֱ�ٽ�Ŀ�궨λ�ͷ��ࡣȻ���������߶ȱ�ʾ�������������ܵ�ͬʱ�����˼��㸺�������⣬������Ϣ�ں���ƿ��ܻᵼ�±������������������½���
��������Ϣ������С����ֻռ��ͼ���һС���֣����ֱ�Ӵ�ϸ���Ⱦֲ������õ���Ϣ�dz����ޡ�ͨ�ö�������ͨ���������Щ�ֲ�����֮�������������������������֪��ÿһ�����嶼�������ض��Ļ����л����������干�档Ȼ�������һЩ������������Ϣ�ļ�ⷽ����������С���������������֮��Ĺ�ϵ��С�������Χ��������ṩ���õ���������Ϣ���������Ŀ�����塣ͨ�����������������ģ�飬�����������⾫�ȡ�����������ϸ�����˼���ʹ����������Ϣ����Ҫ����ģ�͡�
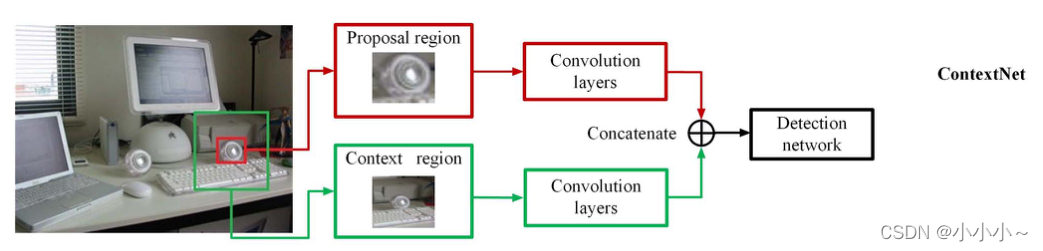
ContextNet����ǿ��R-CNN���Ա���Ϊ�ǵ�һ��רע��СĿ�����̽��������������У������һ���µ������������磨RPN��������С����������Χ����������Ϣ�����ȣ�����С����Ĵ�С����RPNê����С��ԭ���� 12 8 2 128^2 1282�� 25 6 2 256^2 2562�� 51 2 2 512^2 5122�� p i x e l 2 pixel^2 pixel2���ŵ� 1 6 2 16^2 162�� 4 0 2 40^2 402�� 10 0 2 100^2 1002�� p i x e l 2 pixel^2 pixel2������conv4_3����ͼ����ȡС�����飬������VG16��conv5_3���ڶ���������������ɵ�ContextNetģ�鱻������ڻ�ȡ�������Χ����������Ϣ��������ʾ����ͬ������ǰ�������ɼ����������һ��ȫ���Ӳ���ɣ��������������ȫ���Ӳ���ɡ��ɸĽ���RPN��ȡ��������������������������ͬ���ĵ�Ľϴ�����������ֱ𱻴��ݵ�����ǰ�����硣ͬʱ����ǰ�������õ�����4096-D���������ڱ�����������֮ǰ������������ʵ����������������ǿ��R-CNNģ�ͱ�ԭR-CNNģ�͵�СĿ����ͼ�����29.8%��
Inside�COutside Net����Inside�COutside Net��ION���в��ÿռ�ݹ������磨RNN��������Ŀ�����������������Ϣ��Ȼ������ת�ػ�����ȡ�ڲ��Ķ༶����ӳ�䡣�����������ķ���ռ�RNN��Ԫ������ͼ���ÿһ�����ƶ�����ģ�ͽ�����߶Ⱥ���������Ϣ�����������м�⡣��ION�����У�����������ӳ�������綥����IRNNģ�����ɡ�ֵ��ע����ǣ�IRNN��RELU��ɣ����⣬ԭʼVGG16��conv5����ĸ�����ͨ��1��1��������Ϊǰ�ĸ�����RNN�������ҡ����ҵ����ϵ��¡����µ��ϣ������룻Ȼ��ÿ��������������Ϊ��һ��IRNN��Ԫ�����롣����������������
VSSA-NET�������һ����ֱ��������ں����磬���ô���Ծ���ӵķ�������ʹ�ֱ�ռ�����ע��ģ����н�ͨ��־��⡣��������Ҫ��Ϊ�����Ρ���һ���Ƕ�߶�������ȡģ�飬ͨ��Mobile Net�ͷ��������γɶ�ֱ�������ͼ���ڶ����ǹ�����ֱ�ռ�����ע��ģ�顣Ϊ�˳��������������Ϣ������������ͼ��ÿһ����Ϊ�ռ����С�ͨ���ڽ��������ע����ƣ��Դ�ͳ�Ļ���LSTM����ı������ģ�ͽ����˸Ľ����û��ƿ����ڲ���������������¶��������������б��롣
MFFD�����ż�⾫�ȵ���ߣ�����ļ��������ζ�Ÿ��ߵļ���ɱ���һ�ֳ�Ϊģ�黯�����ںϼ������MFFD����ģ�黯����������ģ�ͣ���������СĿ���ⷽ���кܺõ����ܣ����ҿ���Ƕ�뵽��Դ�����豸�У����Ƚ�����ϵͳ��ADASs�����ڸ������������������ӱ��ģ�顣���У�ǰ��ģ���ھ�������ʹ��С�ߴ�������Լ�����Ϣ��ʧ������С��ģ���ڽ��������֮ǰͨ���������㣨1��1�������ı�����ͨ�������������ŵ��������ں������Կ���ģ��Ķ�߶���������Ϣ��������ֱ�����Ե����㣬�Ӷ�ʵ�ָ�Ч���㡣
�������ܵķ������ڶ༶�����ں�ģ����ʹ�ô���ģ���Ԫ�غ�ģ�飬����������Ϣ����SSD��ͬʱ�������һ����ΪCSSD������������ɶ�߶���������Ϣ���ñ����������չ�����ͷ������Ӷ�߶�������ͼ����ȡ������Ϣ����������������洢������Ϣ����������ǰ���������ֲ�����������ǿ�������ӵ������RCNN�����У�Ȼ������Ż������������ࡣPCNN����������ɣ�����ȫ��������SEģ���ã���������������λ���磨PLN����ȡ��Ȼ�ڶ���������������PCN�����ֲ�������ȫ��ͼ���������ӳ�һ�������������������շ��ࡣ ���⣬��������TL-SSD���磬���г�ʼģ�����Ӳ�ͬ��С�ĸ���Ұ������ƴ�ӽ����dz�����������㣻dz��ģ�Ϳ����ṩȷ��λ�ú�״̬��Ϣ�������ģ�Ϳ��Ծ��������Ƿ����ں��̵ơ� ͨ���������ػ��Ķ༶��������Ϣ�����ڹ��������ĸ�֪�������������ں�ģ������ڽ���������Ϣ�ı������ӵ�����ӳ���С�������������ĸ�֪RoI�أ��Ա�����С����Ľṹ��������������Ϣ������һ����ģ�ܼ��;��������类Ӧ���ڳ�����ⳡ����Leng���˽�U-V�Ӳ��㷨�����ڲ�����������Ϣ�ĸ���R-CNN���ϡ�
���߶ȱ�ʾ���ƣ���������ϢҲּ��Ϊ���ռ�������ṩ������Ϣ���������ڣ���������Ϣ��Ҫ�ǻ�ȡ����Ȥ������Χ����Ϣ��ͨ��ѧϰ��������Χ��Ϣ֮��Ĺ�ϵ���Ľ�������ࡣ��ˣ��������������ϢҲ�ᵼ����Ϣ������
�����������ֱ���
���ֱ��ʷ���ּ�ڴ���Ӧ�ĵͷֱ��������лָ��߷ֱ��ʡ��߷ֱ���ͼ���ṩ�˹���ԭʼ�����ĸ���ϸ��ϸ�ڣ����Ժܺõ�Ӧ����С�����⡣����Gan���㷨�ѱ���������ؽ��߷ֱ���ͼ�����ɶԿ�������ͼ�ֱ��ʷ���ȡ���˾����������������������ɣ�һ�������������������磬��һ���������Ǽ��������硣�����������ɳ��ֱ���ͼ������ƭ��������������������ͼ����ʵͼ�������������ɵļ�ͼ�����ֿ�����GAN�������ij�����ʽ������ʾ��

Perceptual GAN��GAN�����״�����СĿ������������һ���µ������������������ײ�������Ϊ���룬�Ի�ø���ϸ�ڣ����ڳ��ֱ��ʱ�ʾ������������������в�飬����ѧϰС��������ƴ����֮��IJв��ʾ����������������֧��ɣ����Կ���֧��֪��֧����һ���Ƕ��������жԷ�֧�����ɵ�С���ֱ����������ƵĴ�������ֿ���������һ���Ƕ������������Ŀ�����������ڸ�֪��֧����ɵġ���������֧����ͼ�����С����ʧ��ͬʱ������������ѵ����������ȵ�����������������жϵĸ��ʡ�
GAN��Ȼ����GAN���ɵĸ߷ֱ���ͼ����Ȼ������������ˣ�������ϸ��ģ�飬�Իָ�����С��������һЩϸ�ڡ����ȣ�ѡ��MB-FCN��Ϊbaseline detector�����ɰ�������������������Щ����ֱݵ��������ͼ������С���Σ��ͷֱ��ʵ����������ϲ���ģ���ϸ��ģ�飬��������ij��ֱ�������������������������Ϊ����������ѵ�����������ü�����ͬʱ�����������������ֳ��ֱ�������߷ֱ������ӷ�������������
SOD-MTGAN��һ���µĶ��������ɶԿ����磨MTGAN������MTGAN�У����ֱ���ͼ���ɷ������������ɣ���������������������������ʵ�ĸ߷ֱ���ͼ��ͼ�ͼ��ͬʱԤ���������ϸ���߽����Ҫ���ǣ�����ͻع���ʧ���������Խ�һ�������������������ɳ��ֱ���ͼ�Ӷ�����������õض�λ��MTGAN������������ʧ���������Կ�����ʧ��Ŀ����ʧ�������ؼ�MSE��ʧ��������ʧ������Ŀ����ʧ���ͱ߽��ع���ʧ���Ӷ�ʹ�ؽ�ͼ���������Ƶϸ�ڵ���ʵ�߷ֱ���ͼ�����ơ���֮ǰ��GANs��ȣ����ɵij��ֱ���ͼ��ķ���ͻع���ʧ�����ӵ���������ʧ�У���ȷ��������������ָ����ֱ���ͼ�����ʹ�öԿ�����ʧ��MSE��ʧ�����Ż��ķ�����ȣ����Ǹ�Ϊ��ʵ��
JCS������רע��С�����˼�⣬JCS�����ɷ���������ͳ��ֱ�����������ɡ�ͨ����Ϸ�����ʧ�ͳ��ֱ�����ʧ������������������Ϊһ��ͳһ�����硣�ڳ��ֱ��������в��������ƵIJв�ṹ����VDSR����̽�����ģ���˺�С��ģ����֮��Ĺ�ϵ���Ӷ��ָ�С��ģ���˵�ϸ�ڡ���ˣ��ؽ���С�߶����˼Ȱ���С�߶����˵�ԭʼ��Ϣ��Ҳ�������ֱ��������������Ϣ����ѵ���Σ����ͨ��������MCF������HOG+LUV����Ӧ��JCS������ѵ������������⣬��߶ȱ�ʾ��MCF��������ǿ���������
���ģ���Region-Proposal
�����ѧϰ��������֮ǰ������������ִ�з�����ѡ���������㷨��Ȼ�������ַ����ļ���Ч�ʷdz����ޡ�Faster R-CNN�״�����RPN��ʶ�����Ȥ������Ȼ�������R-FCN����k��k����C+1������ӳ�䣬�����ǵ�������ӳ�䣬ÿ������ӳ�为��ÿ�����ļ�⡣Ȼ��������ê��ߴ�ϴ�СĿ������Ȼ����ȷ��λ��
��FastMask�Ļ����ϣ�AttentionMaskΪС�������ɶ����������ڻ�����������ڽΣ��������߶ȿռ�������һ������ij߶ȣ�S8�����ر��ǣ�Ϊ�˼��ٲ������ڵ������������˳߶��ض��Ķ�����ע����ƣ�SOAM����ÿ����ͬ�߶ȵ�������ͼ��ѡ������ϣ���Ĵ��ڡ��������г߶ȶ��������ǵ�ע��ֵ�������ϵ��������ҵ��������ڵ����λ�ã����ò���ֻ������ϣ���Ĵ��ڽ������Ȳ����ʹ������Ӷ���ʡ�ڴ��GPUԴ����������С������ij߶ȣ�S8����ê��ĸ���ȷλ��ͨ�����нϵ͵����Ŷȣ������Ǹ��п��ܱ�NMS�ĺ����ܾ�����ˣ������ƽ��NMS��SNMS��9��������Щê������IoUԤ�����ṩ�������֤�ݡ����⣬����ͼ��ļ����������ĸ�������ѭ���ƶ����Ա��ⶪʧλ�ڽ�ê�м�϶�е�С����
����RPN�еIJ�����������֪ʶȷ���ģ������RPN��ѵ��ģ���о������ڲ�������⡣��ˣ�ͨ�����Ӳ����������ǿ��RPN��SRPN�������⣬��������particle swarm optimization and bacterial foraging optimization��Ѱ�����Ų���ֵ��Ȼ���Ի�ø������ļ�ⷽ�����������˰���С����Ĺ�����ͼ���С������ǿ����ʹģ����עС������Ҫע����ǣ�С������ǿ����һ��ͼ���ж�θ���ճ��С��������ճ���Ķ��������ж����ص����������˰���С�������ƥ��ê���������������MS COCO���ݼ��ϵĽ��������ʹ��3������������ճ�����Դ���ͼ�������������棬��ԭʼmask R-CNN��ȣ�����ָ��С���������Ը����ʷֱ������9.7%��7.1%��
���������д�������������Ҫ���Ѵ�����ʱ����ڴ档�����һ�ּ�����ģ���ɿ�ܣ�ʹ�����ٶȺ;���֮��ﵽƽ�⡣ԭʼͼ�����ȱ�����Ϊ��߶ȡ�Ȼ��ÿ������ͨ����RoI����������mask����ģ�飨MGM������������mask�����ÿ���߶ȵ�����ͼ��������������ROI�ͼ�⡣��SSDģ����ѵ��������ͼ�������ͼ���ݿ��Ŷȷ�Ϊģ��Ŀ��������ͻ��Ŀ��������ͻ������������ϸ������ʶ�𣬶�ģ��������������Ҫ��ԶС���壩��ͨ��SSD��⡢�����Сȷ�ϡ��ظ������Ƴ��;��������Ƴ�����֤����ȷ�ϡ��÷���Ҳ��������������ܹ��ĵļ��ģ�͡�����ԭʼͼ�������ٰ���һ�������������вü���Ȼ����Ŵ���ͬ�������Сʱ��Ӧ�����������硣��ʹ��ԭ����С�����ø�������壬�����ױ���ͨSSD̽��������
���壩�������ṹ
����faster R-CNN��KB-RANNרע�ڽ�ͨ��־�ļ�⣬����Ԥѵ����SqueezeNet��������ͼ������ע����Ƶ�RNN�ܹ���LSTM��������������Ϣ�����⣬��������faster R-CNN��ԭʼ���������������ڽ�ͨ��־��˵̫����˼�����VGG-16��pool4�㣬������ResNet����ȡС��־��������֮�������Hartʾ���ھ�OHEM����ʹ������ӽ�׳��