对抗性扰动能提升公平性?!
在arxiv上看到一篇用对抗样本来做公平性提升的论文,fairness-aware Adversarial Perturbation Towards Bias Mitigation for Deployed Deep Models,被CVPR 2022接收。arxiv链接
简介
文章解决的问题: 提升深度学习模型的公平性
现有方案劣势: 现有的深度学习模型公平性提升方案,更多的是讨论如何训练出一个公平的模型,例如做数据增强使得训练集的分布更加均衡,修改损失函数使得模型能够学习到公平的表征,等等
该方案优势: 从对抗样本的角度来思考模型公平性提升,作用于推理阶段,不需要修改模型
文章的贡献: 提出了一种公平性感知的对抗性扰动生成方案,用于提升模型公平性

basic idea
??目前公认的模型偏见的一个重要来源是训练数据,如果训练数据的分布不均衡,部分群体的数据代表性不足(例如收集到的图片里面,男性大部分都是冷漠表情,女性大部分都是微笑的),这种数据的不均衡导致目标任务标签(微笑)和敏感属性标签(性别)存在统计上的关联。训练时,直接用最小化分类损失训练的模型自然会学习到这种虚假的关联,产生了偏见。例如,下图里面,数据中女性正例的比例高于男性,训练出的模型,女性的FPR显著高于男性的FPR。

??文章中提出了一种打破这种关联的方法,就是产生对抗性扰动,让模型分不清数据的敏感属性,分得清目标标签(在特征空间的视角,就是扰动后的样本靠近性别超平面,但是在目标标签超平面上保持可分性,提升公平性同时不牺牲准确率)
FAAP框架
??为了实现上述目的,文中提出了FAAP(Fairness-Aware Adversarial Perturbation)框架,框架十分简洁明了,包含部署模型、生成器和判别器三个部分。其中,可学习的部分是生成器和判别器。FAAP的目标是训练出一个符合要求的生成器,能够在训练完成之后,自适应地为输入图片添加合适的对抗性扰动。在整个FAAP的训练过程中,部署模型的参数是冻结的。判别器则用于从特征提取器的输出中,捕捉敏感属性的信息,不断更新。

??要提升公平性,扰动生成器的目标是欺骗判别器,如果让判别器没法判断扰动后的图片敏感属性z到底是什么,这种对抗性扰动就是符合要求的,可以阻止模型提取出公平性相关的特征。同时,文中提到,希望G能够欺骗D,让D进行尽可能随机的猜测,所以公平性损失还包含让D的熵H最大。
??如果只有负责公平性感知的损失,这种对抗性扰动会使得模型没法正确预测出图片的标签,准确率大大降低,完全不可用。因此,文中提出用部署模型标签预测器的输出来指导G的优化,保持准确率。
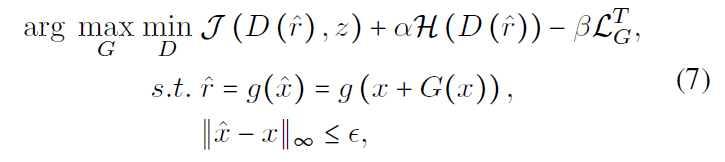
定量实验结果
??文中使用了CelebA和LFW两个数据集,敏感属性选取是Male,目标标签选取了Smiling、Attractive等。为了验证方法在不同公平性程度的模型上的性能表现,采用了三种训练方式来训练了三种不同公平性程度的模型,分别为正常训练(normal training)、公平训练(fair training)和不公平训练(unfair training),公平训练的模型公平性最好,不公平训练的模型公平性最差。选取的公平性指标是DP和DEO,二者都是越接近0表示越公平。
?? 不同敏感属性取值群组二者的预测结果positive rate差值定义为demographic parity(DP),若较小,则分类器比较公平。
DP=∣P(Y^=1∣Z=?1)?P(Y^=1∣Z=1)∣DP = |P(\hat{Y}=1|Z=-1) - P(\hat{Y}=1|Z=1)|DP=∣P(Y^=1∣Z=?1)?P(Y^=1∣Z=1)∣
?? 如果分类器满足下式,则认为其满足predictive equality:
P(Y^=1∣Y=?1,Z=?1)=P(Y^=1∣Y=?1,Z=1)P(\hat{Y}=1|Y=-1, Z=-1) = P(\hat{Y}=1|Y = -1, Z=1) P(Y^=1∣Y=?1,Z=?1)=P(Y^=1∣Y=?1,Z=1)
?? 如果分类器满足下式,则认为其满足equal opportunity:
P(Y^=1∣Y=1,Z=?1)=P(Y^=1∣Y=1,Z=1)P(\hat{Y}=1|Y=1, Z=-1) = P(\hat{Y}=1|Y = 1, Z=1) P(Y^=1∣Y=1,Z=?1)=P(Y^=1∣Y=1,Z=1)
将predictive equality和equal opportunity相交定义equalized odds,equalized odds越大,分类器越不公平,二者的差值为DEO:
DEO=∑y∈{?1,1}∣P(Y^=1∣Y=y,Z=?1)?P(Y^=1∣Y=y,Z=1)∣,DEO = \sum_{y \in\{-1,1\}}|P(\hat{Y}=1|Y=y, Z=-1) - P(\hat{Y}=1|Y = y, Z=1)|, DEO=y∈{
?1,1}∑?∣P(Y^=1∣Y=y,Z=?1)?P(Y^=1∣Y=y,Z=1)∣,

??可以看出,在公平性提升性能上,部署模型原始的公平性越差,可提升的空间越多,用FAAP的公平性提升效果就越明显,甚至在公平模型上都能有一定的提升。
定性实验结果
??文中给出了T-SNE的结果,第一行的图表示数据集中的原始图像经过部署模型特征提取器后的输出,使用降维算法T-SNE进行可视化的结果,结果中距离越接近的点表示在特征空间中越相似,图中不同敏感属性值的样本区分度较高。FAAP对输入数据进行扰动,第二行表示扰动后图像经过特征提取器输出的T-SNE结果,可以看到不同敏感属性值(male与female)的样本发生了混淆,而不同目标标签取值(-1与1)的样本保持了较好的区分度。这说明FAAP能够有效地阻止模型提取敏感属性相关特征,使模型公平对待不同敏感属性值的数据,同时保留了目标标签预测的相关信息。

黑盒测试结果
??文中默认对部署模型是有白盒访问权限的,在最后也进行了黑盒测试,使用的是百度和阿里视觉平台的API,目标标签预测任务是微笑。文中利用CelebA训练的resnet18作为功能相同的替代模型来训练生成器,产生的对抗性扰动具有一定的迁移性,具有黑盒场景下应用的可能性。
